Cet article a été publié dans le cadre du Blogathon sur la science des données
Vue d'ensemble
Cet article discutera brièvement de CNN, une variante spéciale de réseaux de neurones conçue spécifiquement pour les tâches liées à l'image. L'article se concentrera principalement sur la partie mise en œuvre de CNN. Tous les efforts ont été faits pour rendre cet article interactif et simple.. J'espère que vous l'apprécierez Bon apprentissage !!

introduction
Les réseaux de neurones convolutifs ont été introduits par Yann LeCun et Yoshua Bengio dans l'année 1995 qui s'est avéré plus tard montrer des résultats exceptionnels dans le domaine des images. Ensuite, Qu'est-ce qui les rendait spéciaux par rapport aux réseaux de neurones ordinaires lorsqu'ils sont appliqués dans le domaine de l'image? Je vais expliquer une des raisons avec un exemple simple. Veuillez noter que vous avez été chargé de classer les images de chiffres manuscrites et que quelques exemples d'ensembles de formation sont présentés ci-dessous..

Si vous observez correctement, vous pouvez constater que tous les chiffres apparaissent au centre des images respectives. L'entraînement d'un modèle de réseau de neurones normal avec ces images peut donner un bon résultat si l'image de test est d'un type similaire. Mais, Que faire si l'image de test est comme ci-dessous?

Ici le chiffre neuf apparaît dans le coin de l'image. Si nous utilisons un simple modèle de réseau de neurones pour classer cette image, notre modèle peut échouer brusquement. Mais si la même image de test est donnée à un modèle CNN, il est très probable qu'il soit correctement classé. La raison de la meilleure performance est qu'il recherche des caractéristiques spatiales dans l'image. Pour le cas ci-dessus lui-même, même si le chiffre neuf est dans le coin gauche du cadre, le modèle CNN entraîné capture les caractéristiques de l'image et prédit probablement que le nombre est le chiffre neuf. Un réseau de neurones normal ne peut pas faire ce genre de magie. Discutons maintenant brièvement des principaux éléments constitutifs de CNN.
Principaux composants de l'architecture d'un modèle CNN
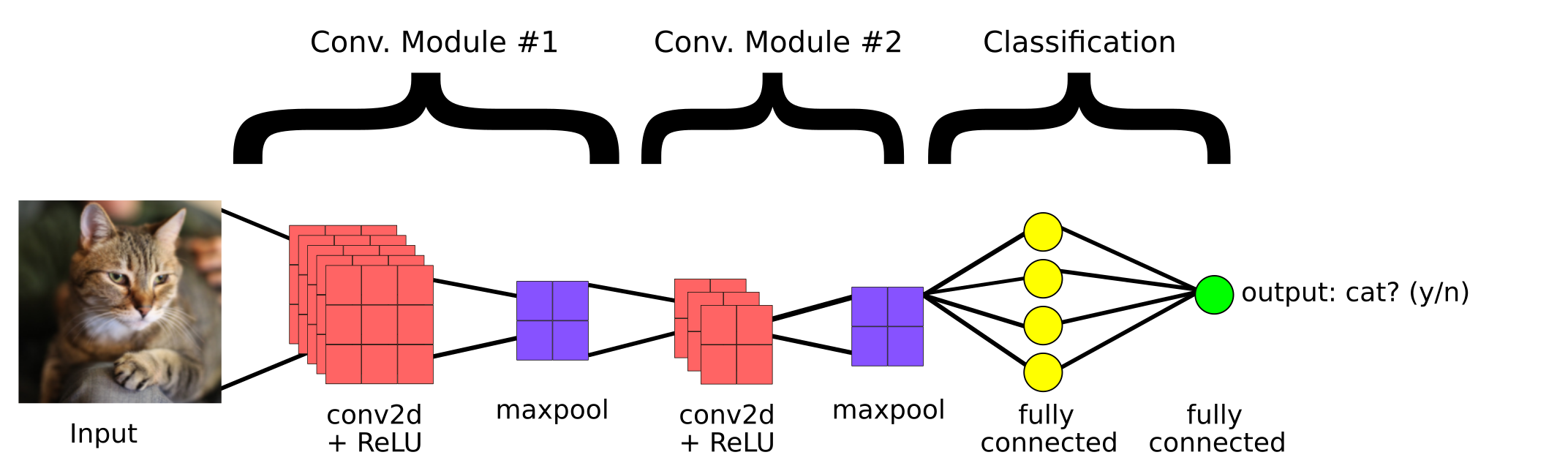
Il s'agit d'un modèle CNN simple créé pour classer si l'image contient un chat ou non. Ensuite, les principaux composants d'un CNN sont:
1. couverture convolutive
2. Couche de regroupement
3.Couche entièrement connectée
couverture convolutive
Les couches convolutives nous aident à extraire les caractéristiques présentes dans l'image. Cette extraction est réalisée à l'aide de filtres. Observer l'opération suivante.
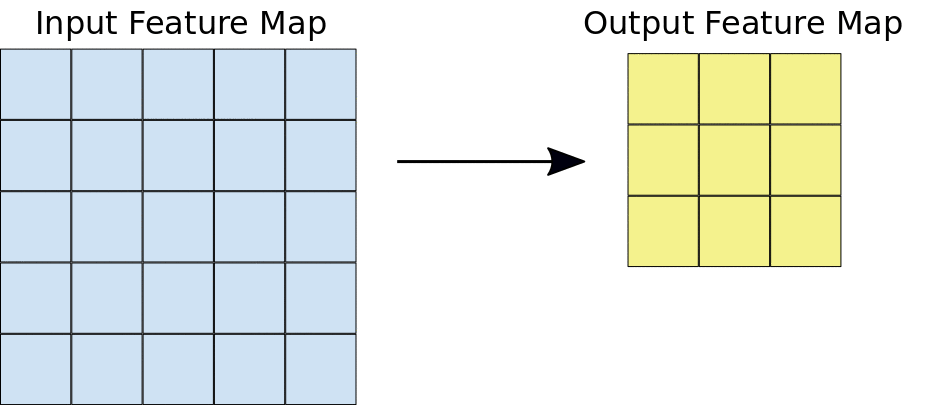
Ici, nous pouvons voir qu'une fenêtre glisse sur toute l'image où l'image est rendue sous forme de grille (C'est ainsi que l'ordinateur voit les images où les grilles sont remplies de nombres !!). Voyons maintenant comment les calculs sont effectués dans l'opération de convolution.
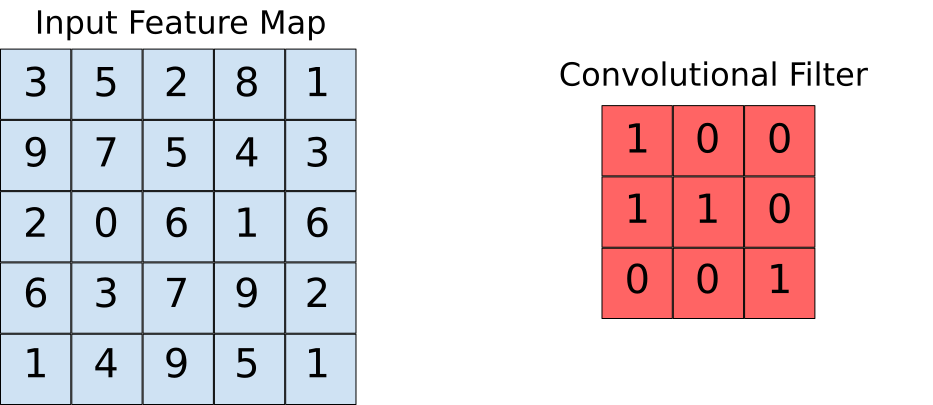
Supposons que la carte des caractéristiques d'entrée soit notre image et que le filtre convolutif soit la fenêtre sur laquelle nous allons glisser. Regardons maintenant l'une des instances de l'opération de convolution.
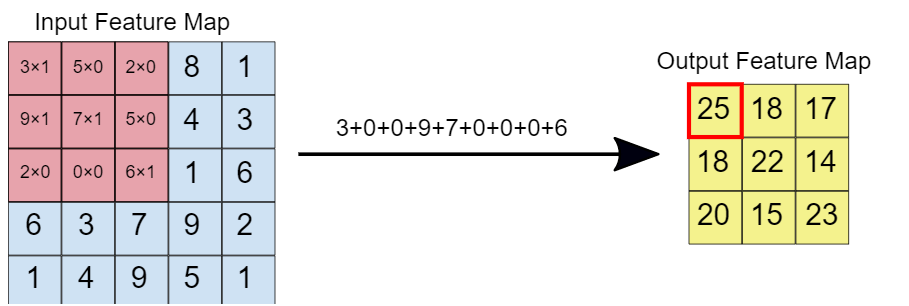
Lorsque le filtre de convolution est superposé à l'image, les éléments respectifs sont multipliés. Alors, les valeurs multipliées sont ajoutées pour obtenir une valeur unique qui est renseignée sur la carte des caractéristiques en sortie. Cette opération se poursuit jusqu'à ce que nous fassions glisser la fenêtre sur la carte des caractéristiques d'entrée., remplissant ainsi la carte des caractéristiques de sortie.
Couche de regroupement
L'idée derrière l'utilisation d'une couche de regroupement est de réduire la dimension de la carte des caractéristiques. Pour la représentation donnée ci-dessous, nous avons utilisé une couche de regroupement maximale de 2 * 2. Chaque fois que la fenêtre glisse sur l'image, on prend la valeur maximale présente dans la fenêtre.
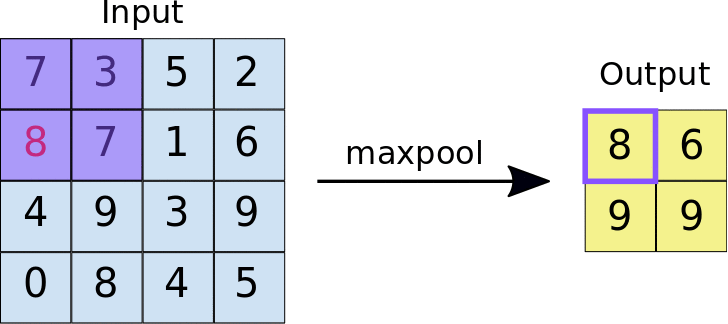
Finalement, après fonctionnement maximal du groupe, on voit ici que la dimension de l'entrée, c'est-à-dire, 4 * 4, a été réduit à 2 * 2.
Couche entièrement connectée
Cette couche est présente dans la section de queue de l'architecture du modèle CNN comme vu précédemment. L'entrée de la couche entièrement connectée est constituée des caractéristiques riches qui ont été extraites par des filtres convolutifs. Cela se propage ensuite vers la couche de sortie, où l'on obtient la probabilité que l'image d'entrée appartienne à différentes classes. Le résultat prédit est la classe avec la plus grande probabilité que le modèle ait prédit.
Implémentation du code
Ici, nous prenons le Fashion MNIST comme ensemble de données de problème. L'ensemble de données contient des t-shirts, pantalons, pull, Robes, manteaux, tongs, chemises, des chaussures, sacs et chaussons. La tâche consiste à classer une certaine image dans les classes susmentionnées après avoir entraîné le modèle.
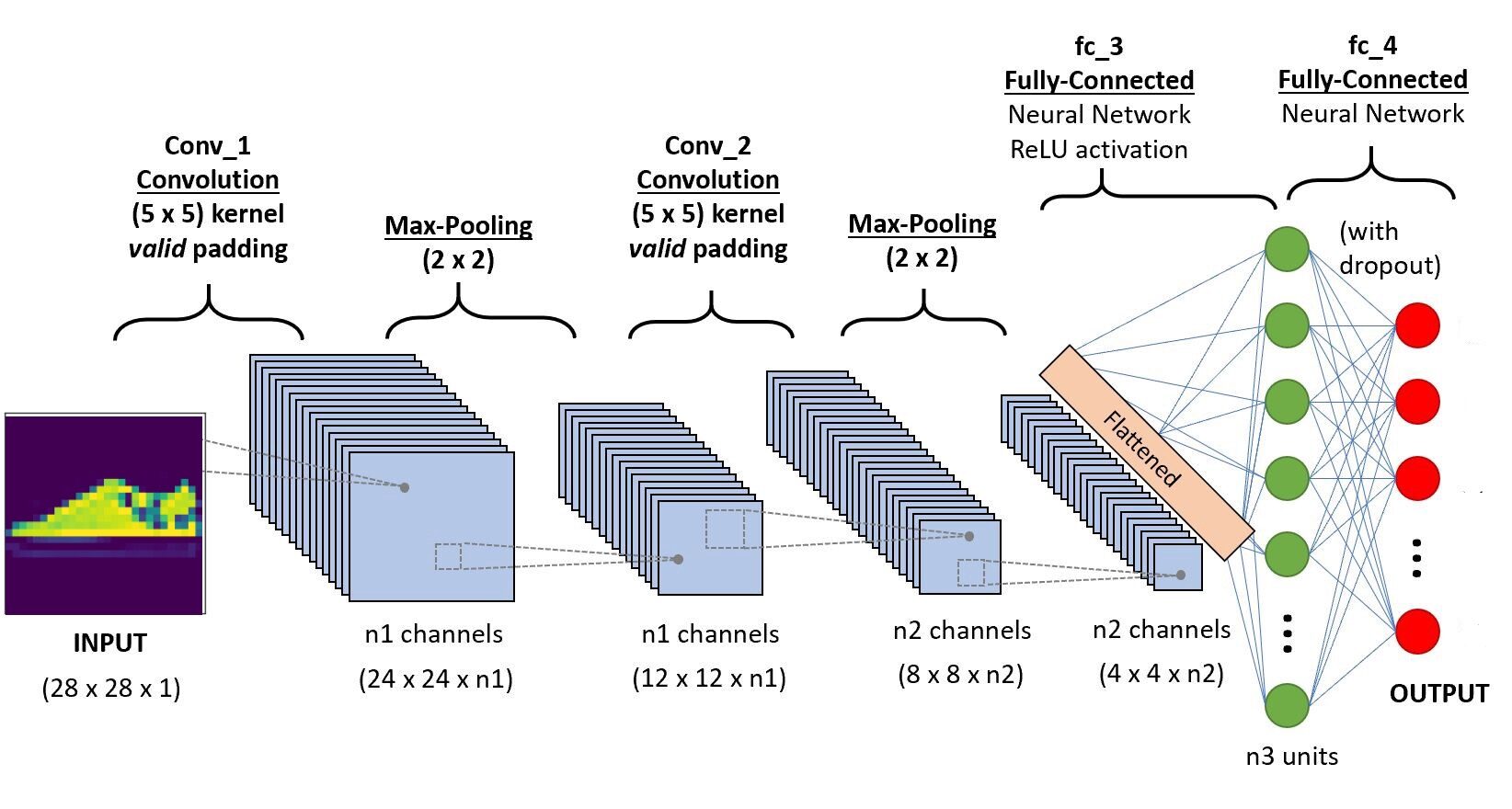
Nous allons implémenter le code dans Google Colab, car ils fournissent l'utilisation de ressources GPU gratuites pendant une période de temps fixe. Si vous débutez dans l'environnement Colab et les GPU, consultez ce blog pour vous faire une meilleure idée. Ci-dessous l'architecture CNN que nous allons construire.
Paso 1: Importez les bibliothèques requises
importer le système d'exploitation torche d'importation importer torchvision importer le fichier tar à partir des transformations d'importation de torchvision de torch.utils.data importer random_split de torch.utils.data.dataloader importer DataLoader importer torch.nn en tant que nn de torch.nn import fonctionnel comme F de la chaîne d'importation itertools
Paso -2: Téléchargement du jeu de données de test et d'entraînement
train_set = torchvision.datasets.FashionMNIST("/usr", download=Vrai, transformer=
transforme.Composer([transforme.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./Les données", download=Vrai, train=Faux, transformer=
transforme.Composer([transforme.ToTensor()]))
Paso 3 Division de l'ensemble de formation pour la formation et la validation
taille_train = 48000 val_size = 60000 - taille_train train_ds,val_ds = random_split(train_set,[taille_train,val_size])
Paso 4 Charger l'ensemble de données en mémoire à l'aide de Dataloader
train_dl = DataLoader(train_ds,batch_size=20,shuffle=True) val_dl = DataLoader(val_ds,batch_size=20,shuffle=True) classes = train_set.classes
Visualisons maintenant les données chargées,
pour les img,étiquettes dans train_dl:
pour img dans imgs:
arr_ = np.squeeze(img)
plt.show()
Pause
Pause
Paso -5 Définir l'architecture
importer torch.nn en tant que nn
importer torch.nn.fonctionnel comme F
#définir l'architecture CNN
classe Net(nn.Module):
def __init__(soi):
super(Rapporter, soi).__init__()
#couche convolutive-1
self.conv1 = nn.Conv2d(1,6,5, remplissage=0)
#couche convolutive-2
self.conv2 = nn.Conv2d(6,10,5,remplissage=0)
# couche de mise en commun maximale
self.pool = nn.MaxPool2d(2, 2)
# Couche entièrement connectée 1
self.ff1 = nn.Linéaire(4*4*10,56)
# Couche entièrement connectée 2
self.ff2 = nn.Linéaire(56,10)
def vers l'avant(soi, X):
# ajout d'une séquence de couches convolutives et de pooling max
#entrée dim-28*28*1
x = self.conv1(X)
# Après opération de convolution, faible sortie - 24*24*6
x = self.pool(X)
# Après le fonctionnement de la piscine Max dim - 12*12*6
x = self.conv2(X)
# Après opération de convolution sortie dim - 8*8*10
x = self.pool(X)
# dim max de sortie de piscine 4*4*10
x = x.vue(-1,4*4*10) # Remodeler les valeurs à une forme appropriée à l'entrée de la couche entièrement connectée
x = F.relu(soi.ff1(X)) # Application de Relu à la sortie de la première couche
x = F.sigmoïde(self.ff2(X)) # Application du sigmoïde à la sortie de la deuxième couche
retourner x
# créer un CNN complet model_scratch = Net() imprimer(maquette)
# déplacer les tenseurs vers le GPU si CUDA est disponible
si use_cuda:
model_scratch.cuda()
Paso 6: définition de la fonction de perte
# Fonction de perte
importer torch.nn en tant que nn
importer torch.optim en tant qu'optim
critère_scratch = nn.CrossEntropyLoss()
def get_optimizer_scratch(maquette):
optimiseur = optim.SGD(model.paramètres(),lr = 0.04)
optimiseur de retour
Paso 7: mise en place de l'algorithme d'apprentissage et de validation
# Implémentation de l'algorithme d'entraînement
train def(n_époques, chargeurs, maquette, optimiseur, critère, use_cuda, Enregistrer le chemin):
"""renvoie le modèle entraîné"""
# initialiser le tracker pour une perte de validation minimale
valid_loss_min = np.Inf
pour l'époque dans la gamme(1, n_époques+1):
# initialiser les variables pour surveiller la perte de formation et de validation
train_loss = 0.0
valid_loss = 0.0
# phase de train #
# mettre le module en mode formation
modèle.train()
pour batch_idx, (Les données, cible) en énumérer(chargeurs['former']):
# passer au GPU
si use_cuda:
Les données, cible = data.cuda(), cible.cuda()
optimiseur.zero_grad()
sortie = modèle(Les données)
perte = critère(sortir, cible)
perte.en arrière()
optimiseur.étape()
train_loss = train_loss + ((1 / (batch_idx + 1)) * (perte.de.données.élément() - train_loss))
# valider le modèle #
# mettre le modèle en mode évaluation
modèle.eval()
pour batch_idx, (Les données, cible) en énumérer(chargeurs['valide']):
# passer au GPU
si use_cuda:
Les données, cible = data.cuda(), cible.cuda()
sortie = modèle(Les données)
perte = critère(sortir, cible)
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (perte.de.données.élément() - valid_loss))
# imprimer les statistiques de formation/validation
imprimer('Époque: {} tPerte d'entraînement: {:.6F} tPerte de validation: {:.6F}'.format(
époque,
train_loss,
valid_loss
))
## Si la perte de valorisation a diminué, puis sauvegarde du modèle
si valid_loss <= valid_loss_min:
imprimer('La perte de validation a diminué ({:.6F} --> {:.6F}). Enregistrement du modèle ...'.format(
valid_loss_min,
valid_loss))
torche.sauvegarder(model.state_dict(), Enregistrer le chemin)
valid_loss_min = valid_loss
modèle de retour
Paso 8: Phase de formation et d'évaluation
nombre_époques = 15
model_scratch = train(nombre_époques, chargeurs_scratch, model_scratch, get_optimizer_scratch(model_scratch),
critère_scratch, use_cuda, 'model_scratch.pt')
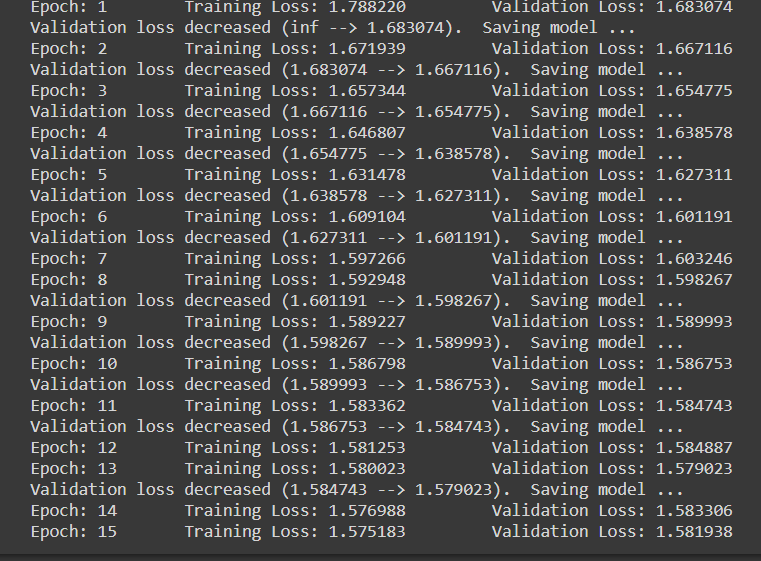
Notez que quand à chaque fois la perte de validation diminue, nous sauvegardons l'état du modèle.
Paso 9 Phase d'essai
test de définition(chargeurs, maquette, critère, use_cuda):
# surveiller la perte et la précision des tests
test_loss = 0.
correct = 0.
total = 0.
# mettre le module en mode évaluation
modèle.eval()
pour batch_idx, (Les données, cible) en énumérer(chargeurs['test']):
# passer au GPU
si use_cuda:
Les données, cible = data.cuda(), cible.cuda()
# Passe avant: calculer les sorties prévues en passant des entrées au modèle
sortie = modèle(Les données)
# calculer la perte
perte = critère(sortir, cible)
# mettre à jour la perte de test moyenne
test_loss = test_loss + ((1 / (batch_idx + 1)) * (perte.de.données.élément() - test_loss))
# convertir les probabilités de sortie en classe prédite
pred = sortie.données.max(1, keepdim=Vrai)[1]
# comparer les prédictions à la vraie étiquette
correct += np.sum(np.squeeze(pred.eq(target.data.view_as(pred)),axe=1).CPU().numpy())
total += data.size(0)
imprimer(« Perte d'essai: {:.6F}n'.format(test_loss))
imprimer('nTest Précision: %2ré%% (%2d/-)' % (
100. * correct / le total, correct, le total))
# charger le modèle qui a obtenu la meilleure précision de validation
model_scratch.load_state_dict(torche.charge('model_scratch.pt'))
test(chargeurs_scratch, model_scratch, critère_scratch, use_cuda)

Paso 10 Tester avec un échantillon
La fonction définie pour tester le modèle avec une seule image.
def prédire_image(img, maquette):
# Convertir en un lot de 1
xb = img.unsqueeze(0)
# Obtenir des prédictions à partir du modèle
yb = modèle(xb)
# Choisissez l'indice avec la probabilité la plus élevée
_, preds = torche.max(yb, faible=1)
# impression de l'image
plt.imshow(img.squeeze( ))
#retour de l'étiquette de classe liée à l'image
retourner train_set.classes[preds[0].Objet()]
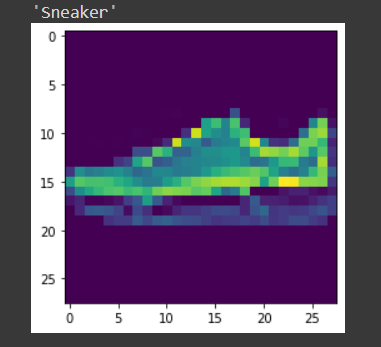
img,étiquette = test_set[9] prédire_image(img,model_scratch)
conclusion
Ici, nous avions brièvement discuté des principales opérations dans un réseau de neurones convolutifs et de son architecture. Un modèle de réseau de neurones convolutif simple a également été implémenté pour donner une meilleure idée du cas d'utilisation pratique. Vous pouvez trouver le code implémenté dans mon Dépôt GitHub. En outre, vous pouvez améliorer les performances du modèle déployé en augmentant l'ensemble de données, en utilisant des techniques de régularisation telles que la normalisation par lots et l'abandon au niveau des couches entièrement connectées de l'architecture. En outre, notez que des modèles CNN pré-entraînés sont également disponibles, qui ont été formés à l'aide de grands ensembles de données. En utilisant ces modèles de dernière génération, vous obtiendrez sans aucun doute les meilleurs scores métriques pour un problème donné.
Les références
- https://www.youtube.com/watch?v = EHuACSjijbI – jovien
- https://www.youtube.com/watch?v = 2-Ol7ZB0MmU&t=1503s- Une introduction conviviale aux réseaux de neurones convolutifs et à la reconnaissance d'images
A propos de l'auteur
Je m'appelle Adwait Dathan, Je poursuis actuellement mon master en Intelligence Artificielle et Data Science. N'hésitez pas à me contacter via Linkedin.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.





