Cet article a été publié dans le cadre du Blogathon sur la science des données
Cet article se concentre sur Apache Pig. C'est une plateforme de haut niveau pour traiter et analyser une grande quantité de données.
VUE D'ENSEMBLE
Si nous regardons l'aperçu de haut niveau de Pig, Pig est une abstraction de MapReduce. Le cochon court sur Hadoop. Donc, utilise à la fois le système de fichiers distribué Hadoop (HDFS) comme le système de traitement Hadoop, CarteRéduire. Les flux de données s'exécutent
par un moteur. Utilisé pour analyser les ensembles de données en tant que flux de données. Comprend un langage de haut niveau appelé Pig Latin pour exprimer ces flux de données.
L'entrée pour Pig est Pig Latin, qui deviendront les jobs MapReduce. Pig utilise les astuces de MapReduce pour effectuer tout le traitement des données. Combine les scripts Pig Latin en une série d'un ou plusieurs travaux MapReduce qui sont exécutés.
Apache Pig a été conçu par Yahoo car il est facile à apprendre et à utiliser.. Ensuite, Pig rend Hadoop assez facile. Apache Pig a été développé parce que la programmation MapReduce devenait assez difficile et que de nombreux utilisateurs de MapReduce ne sont pas à l'aise avec les langages déclaratifs. À présent, Pig est un projet open source sous Apache.
TABLE DES MATIÈRES
- Caractéristiques du porc
- Cerdo vs MapReduce
- Architecture de porc
- Options d'élevage de porcs
- Commandes d'exécution Pig de base
- Types de données de porc
- Opérateurs porcins
- Exemple d'écriture latine de porc
1. CARACTÉRISTIQUES DU PORC
Regardons quelques-unes des caractéristiques de Pig.
- Possède un riche ensemble d'opérateurs comme join, ordonner, etc.
- Il est facile à programmer car il est similaire à SQL.
- Les tâches dans Apache Pig ont été converties automatiquement en tâches MapReduce. Les programmeurs doivent se concentrer uniquement sur la sémantique du langage et non sur MapReduce.
- Vous pouvez créer vos propres fonctions en utilisant Pig.
- Des fonctions dans d'autres langages de programmation comme Java peuvent être intégrées dans des scripts Pig Latin.
- Apache Pig peut gérer
toutes sortes de données, en tant que données structurées, non structuré et semi-structuré et
stocke le résultat dans HDFS.
2. CERDO VS MAPRÉDUCE
Voyons la différence entre Pig et MapReduce.
Pig a plusieurs avantages par rapport à MapReduce.
Apache Pig est un langage de flux de données. Cela signifie qu'il permet aux utilisateurs de décrire comment ils doivent être lus, traiter puis stocker les données d'une ou plusieurs entrées vers une ou plusieurs sorties en parallèle. Tandis que MapReduce, d'un autre côté, est un style de programmation.
Apache Pig est un langage de haut niveau, tandis que MapReduce est du code java compilé.
La syntaxe Pig pour effectuer des jointures et plusieurs fichiers est très intuitive et assez simple comme SQL. Code MapReduce
devient complexe si vous voulez écrire des opérations de jointure.
La courbe d'apprentissage d'Apache Pig est très petite. Une expérience dans les bibliothèques Java et MapReduce est indispensable
pour exécuter le code MapReduce.
Les scripts Apache Pig peuvent faire l'équivalent de plusieurs lignes de code MapReduce et le code MapReduce a besoin de plus de lignes de code pour effectuer les mêmes opérations.
Apache Pig est facile à déboguer et à tester, alors que les programmes MapReduce prennent beaucoup de temps à coder, tester, etc. Pig Latin est moins cher que MapReduce.
3. ARCHITECTURE PORCINE
Regardons maintenant l'architecture de Pig.
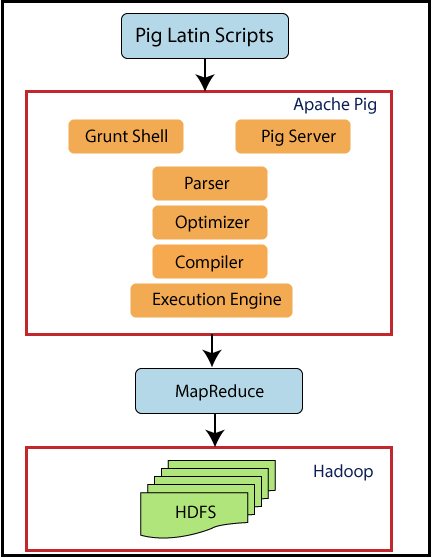
Le cochon est assis sur Hadoop. Les scripts Pig peuvent être exécutés dans le shell Grunt ou le serveur Pig. Le moteur d'exécution Pig the Pass optimise et compile le script et le convertit finalement en tâches MapReduce. Utilise HDFS pour stocker des données intermédiaires entre les tâches MapReduce, puis écrit sa sortie sur HDFS.
4. OPTIONS D'EXÉCUTION DE PORCS
Apache Pig peut exécuter deux modes d'exécution. Les deux produisent les mêmes résultats.
4.1. mode local
Commande dans les podiums
cochon -x local
4.2. Modo Hadoop
Commande dans les podiums
pig -exectype mapreduce
Apache Pig peut être exécuté de trois manières dans les deux modes ci-dessus.
- Temps différé / Fichier de script: placez les commandes Pig dans un fichier de script et exécutez le script
- Programme embarqué / FDU: intégrer les commandes Pig dans Java et exécuter les scripts
5. COMMANDES DE COQUILLE DE PORC GRUNT
Les shells Grunt peuvent être utilisés pour écrire des scripts Pig Latin. Les commandes shell peuvent être invoquées à l'aide des commandes fs et sh. Voyons quelques bases
Commandes de cochon.
5.1. commande fs
La commande fs vous permet d'exécuter des commandes HDFS à partir de Pig
5.1.1 Pour lister tous les répertoires dans HDFS
grognement> fs -ls;
À présent, tous les fichiers dans HDFS seront affichés.
5.1.2. Pour créer un nouveau répertoire mydir dans HDFS
grognement> fs -mkdir monrép/;
La commande ci-dessus créera un nouveau répertoire appelé mydir dans HDFS.
5.1.3. Pour supprimer un répertoire
grognement> fs -rmdir monrép;
La commande ci-dessus supprimera le répertoire créé mydir.
5.1.4. Pour copier un fichier sur HDFS
accorder> fs -put sales.txt ventes/;
Ici, le fichier appelé sales.txt est le fichier source qui sera copié dans le répertoire de destination dans HDFS, c'est-à-dire, Ventes.
5.1.5. Pour quitter Grunt Shell
grognement> quitter;
La commande ci-dessus quittera le shell grunt.
5.2. commande sh
La commande sh vous permet d'exécuter une instruction Unix depuis Pig
5.2.1. Pour afficher la date actuelle
grognement> rendez-vous;
Cette commande affichera la date actuelle.
5.2.2. Pour lister les fichiers locaux
grognement> sh ls;
Cette commande affichera tous les fichiers sur le système local.
5.2.3. Pour exécuter Pig Latin à partir de grunt shell
grognement> exécuter salesreport.pig;
La commande ci-dessus exécutera un fichier de script Pig Latin “rapport de vente.cochon” de la coquille de grognement.
5.2.4. Pour exécuter Pig Latin à partir de l'invite Unix
$rapport de vente de porc.pig;
La commande ci-dessus exécutera un fichier de script Pig Latin "salesreport.pig" à partir de l'invite Unix.
6. P
Pig Latin se compose des types de données suivants.
6.1. Atome de données
C'est une valeur unique. Il peut s'agir d'une chaîne ou d'un nombre. Ils sont de types scalaires comme int, flotter, double, etc.
Par exemple, “John”, 9.0
6.2. Double
Un tuple est similaire à un enregistrement avec une séquence de champs. Il peut s'agir de tout type de données.
Par exemple, ('John', 'James') est un tuple.
6.3. Sac de données
Il se compose d'une collection de tuples qui équivaut à un “tableau” et SQL. Les tuples ne sont pas uniques et peuvent avoir un nombre arbitraire de champs, chacun peut être de n'importe quel type.
Par exemple, {('John', 'James), (‘ roi ',’ marque ')} est un sac de données équivalent au tableau suivant en SQL.
6.4. Carte de données
Ce type de données
contient une collection de paires clé-valeur. Ici, la clé doit être un seul caractère. Les valeurs peuvent être de tout type.
Par exemple, [Nom#('John', 'James'), âge#22] est une carte de données où nom, l'âge est la clé et ('John,’ James '), 22 sont des valeurs.
7. OPÉRATEURS DE PORCS
Ci-dessous le contenu du fichier student.txt.
John,23,Hyderabad James,45,Hyderabad Sam,33,Chennai ,56,Delhi ,43,Bombay
7.1. CHARGE
Charge les données du système de fichiers donné.
A = CHARGER 'student.txt' AS (Nom: chararray, âge: entier, ville: chararray);
Données du fichier étudiant avec des noms de colonnes comme « nom », 'âge', 'ville’ sera chargé dans une variable A.
7.2. DÉCHARGER
L'opérateur DUMP permet d'afficher le contenu d'une relation. Ici, le contenu de A sera affiché.
VIDANGE A //résultats (John,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai) (,56,Delhi) (,43,Bombay)
7.3. BOUTIQUE
La fonction Enregistrer enregistre les résultats dans le système de fichiers.
STOCKEZ A dans « myoutput » à l'aide de PigStorage('*');
Ici, les données présentes en A seront stockées dans myoutput séparées par '*'.
DUMP ma sortie;
//results
John*23*Hyderabad
James*45*Hyderabad
Sam*33*Chennai
*56*Delhi
*43*Mumbai
7.4. FILTRE
B = FILTRE A par nom n'est pas nul;
L'opérateur FILTER filtrera une table avec certaines conditions. Ici, le nom est la colonne en A. Les valeurs non vides dans le nom seront stockées dans la variable B.
BENNE B; //résultats (John,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai)
7.5. POUR CHACUN DE GÉNÉRER
C = FOREACH A GENERATE name, ville;
L'opérateur FOREACH est utilisé pour accéder aux enregistrements individuels. Ici, les lignes présentes dans le nom et la ville seront obtenues à partir de A et stockées dans C.
BENNE C //résultats (John,Hyderabad) (James,Hyderabad) (Sam,Chennai) (,Delhi) (,Bombay)
8. EXEMPLE D'ÉCRITURE LATINE DE COCHON
Nous avons un fichier de personnes dont les champs sont l'identification de l'employé, le nom et les heures.
001,Rajiv,21 002,siddarth,12 003,Rajesh,22
Premier, charger ces données dans un clerc variable. Filtrez-le pendant des heures moins de 20 et stocker à temps partiel. Triez le temps partiel par ordre décroissant et enregistrez-le dans un autre fichier appelé part_time. Afficher le contenu.
Le scénario sera
employé = Charger « personnes » comme (vide, Nom, les heures); temps partiel = FILTRE employé PAR Heures < 20; trié = ORDRE à temps partiel par heures DESC; MAGASIN trié EN 'part_time'; VIDÉO trié; DÉCRIRE trié; //résultats (003,Rajesh,22) (001,Rajiv,21)
NOTES FINALES
Voici quelques-unes des bases d'Apache Pig. J'espère que vous avez apprécié la lecture de cet article. Commencer à pratiquer
avec l'environnement Cloudera.
Les médias présentés dans cet article ne sont pas la propriété de DataPeaker et sont utilisés à la discrétion de l'auteur.






{kind=link}