Cet article a été publié dans le cadre du Blogathon sur la science des données.
introduction
La visualisation des données en Python est peut-être l'une des fonctionnalités les plus utilisées pour la science des données avec Python aujourd'hui. Les bibliothèques en Python sont livrées avec de nombreuses fonctionnalités différentes qui permettent aux utilisateurs de créer des graphiques hautement personnalisés, élégant et interactif.
Dans cet article, nous couvrirons l'utilisation de Matplotlib, Seaborn, ainsi qu'une introduction à d'autres packages alternatifs pouvant être utilisés dans la visualisation Python.
Dans Matplotlib et Seaborn, nous couvrirons certains des tracés les plus utilisés dans le monde de la science des données pour une visualisation facile.
Plus loin dans l'article, nous allons passer en revue une autre fonctionnalité puissante dans les visualisations Python, la sous-trame, et nous avons couvert un tutoriel de base pour créer des sous-parcelles.
Paquets utiles pour les visualisations en python
Matplotlib
Matplotlib est une bibliothèque d'affichage Python pour les diagrammes de tableaux 2D. Matplotlib est écrit en Python et utilise la bibliothèque NumPy. Peut être utilisé dans les shells Python et IPython, Ordinateurs portables Jupyter et serveurs d'applications Web. Matplotlib est livré avec une grande variété de graphiques comme la ligne, bar, dispersion, histogramme, etc. qui peuvent nous aider à approfondir notre compréhension des tendances, modèles et corrélations. Il a été introduit par John Hunter en 2002.
Seaborn
Seaborn est une bibliothèque orientée ensemble de données pour effectuer des représentations statistiques en Python. Il est développé sur matplotlib et permet de créer différentes visualisations. Il est intégré aux structures de données pandas. La bibliothèque fait le mappage et l'agrégation en interne pour créer des visuels informatifs. Il est recommandé d'utiliser une interface Jupyter / IPython et modo matplotlib.
Bokeh
Bokeh est une bibliothèque d'affichage interactive pour les navigateurs Web modernes. Il convient au streaming ou aux données volumineuses et peut être utilisé pour développer des graphiques et des tableaux de bord interactifs. Il existe une large gamme de graphiques intuitifs dans la bibliothèque qui peuvent être exploités pour développer des solutions. Fonctionne en étroite collaboration avec les outils PyData. La bibliothèque est adaptée à la création d'images personnalisées en fonction des cas d'utilisation requis. Les images peuvent également être rendues interactives pour servir de modèle de scénario hypothétique. Tout le code est open source et disponible sur GitHub.
Altaïr
Altair est une bibliothèque d'affichage statistique déclaratif pour Python. L'API Altair est facile à utiliser et cohérente, et est construit sur la spécification Vega-Lite JSON. La bibliothèque déclarative indique que lors de la création de tout objet visuel, nous devons définir les liens entre les colonnes de données et les canaux (Axe X, Axe y, Taille, Couleur). Avec l'aide d'Altaïr, des images informatives peuvent être créées avec un minimum de code. Altair a une grammaire déclarative de visualisation et d'interaction.
tramadamente
plotly.py est une bibliothèque d'affichage interactive, Open source, haut niveau, déclarative et basée sur un navigateur pour Python. Contient une variété de visualisations utiles, y compris des graphiques scientifiques, Graphiques 3D, graphiques statistiques, graphiques financiers, entre autres. Les graphiques de tracé peuvent être affichés dans les blocs-notes Jupyter, fichiers HTML autonomes ou hébergés en ligne. La bibliothèque Plotly offre des options d'interaction et d'édition. L'API robuste fonctionne parfaitement en mode navigateur Web et local.
ggplot
ggplot est une implémentation Python de la grammaire graphique. La grammaire graphique fait référence à la mise en correspondance des données avec des attributs esthétiques (Couleur, façonner, Taille) et objets géométriques (points, lignes, barres). Les blocs de construction de base selon la grammaire des graphiques sont des données, géom (objets géométriques), statistiques (transformations statistiques), escalader, système de coordonnées et facette.
L'utilisation de ggplot en Python vous permet de développer des visualisations informatives de manière incrémentielle, comprendre d'abord les nuances des données, puis ajuster les composants pour améliorer les représentations visuelles.
Comment utiliser la bonne visualisation?
Pour extraire les informations requises des différents éléments visuels que nous créons, il est essentiel que nous utilisions la représentation correcte en fonction du type de données et des questions que nous essayons de comprendre. Ensuite, nous examinerons un ensemble de représentations les plus utilisées et comment nous pouvons les utiliser le plus efficacement possible.
Graphique à barres
Un graphique à barres est utilisé lorsque nous voulons comparer des valeurs métriques dans différents sous-groupes de données. Si nous avons un plus grand nombre de groupes, un graphique à barres est préféré à un graphique à colonnes.
Graphique à barres utilisant Matplotlib
#Création du jeu de données
df = sns.load_dataset('titanesque')
df=df.groupby('qui')['tarif'].somme().encadrer().reset_index()
#Création du graphique à barres
plt.barh(df['qui'],df['tarif'],couleur = ['#F0F8FF','#E6E6FA','#B0E0E6'])
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
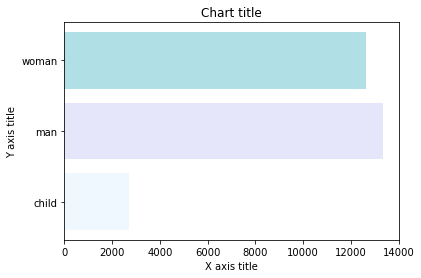
Graphique à barres avec Seaborn
#Création d'un graphique à barres
sns.barplot(x = 'tarif',y = 'qui',data = titanic_dataset,palette = "Bleus")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Graphique à colonnes
Les graphiques à colonnes sont principalement utilisés lorsque nous devons comparer une seule catégorie de données entre des sous-éléments individuels, par exemple, lorsque l'on compare les revenus entre les régions.
Graphique à colonnes utilisant Matplotlib
#Création du jeu de données
df = sns.load_dataset('titanesque')
df=df.groupby('qui')['tarif'].somme().encadrer().reset_index()
#Création du diagramme à colonnes
plt.bar(df['qui'],df['tarif'],couleur = ['#F0F8FF','#E6E6FA','#B0E0E6'])
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
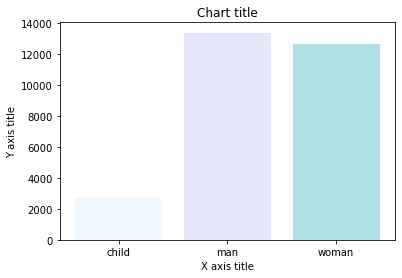
Graphique à colonnes avec Seaborn
#Lecture du jeu de données
titanic_dataset = sns.load_dataset('titanesque')
#Création d'un histogramme
sns.barplot(x = 'qui',y = 'faire',data = titanic_dataset,palette = "Bleus")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Graphique à barres groupées
Un graphique à barres groupées est utilisé lorsque l'on veut comparer les valeurs dans certains groupes et sous-groupes.
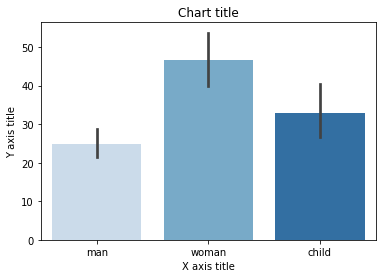
Graphique à barres groupé à l'aide de Matplotlib
#Création du jeu de données
df = sns.load_dataset('titanesque')
df_pivot = pd.table_pivot(df, valeurs="tarif",indice="qui",colonnes="classer", aggfunc=np.mean)
#Création d'un histogramme groupé
ax = df_pivot.plot(genre ="bar",alpha=0,5)
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
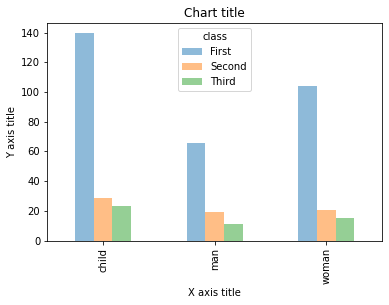
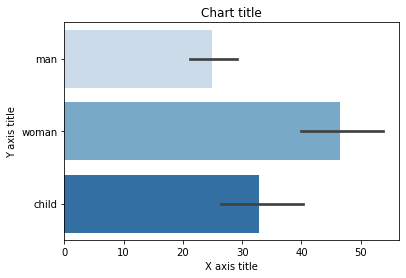
Graphique à barres groupé avec Seaborn
#Lecture du jeu de données
titanic_dataset = sns.load_dataset('titanesque')
#Création du diagramme à barres groupé entre les classes
sns.barplot(x = 'qui',y = 'faire',teinte ="classer",data = titanic_dataset, palette = "Bleus")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
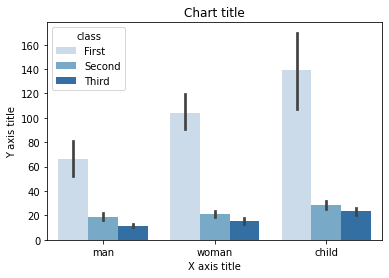
Graphique à barres empilées
Un graphique à barres empilées est utilisé lorsque nous voulons comparer les tailles totales des groupes disponibles et la composition des différents sous-groupes.
Graphique à barres empilées à l'aide de Matplotlib
# Graphique à barres empilées
#Création du jeu de données
df = pd.DataFrame(colonnes=["UNE","B", "C","ré"],
données=[["E",0,1,1],
["F",1,1,0],
["g",0,1,0]])
df.plot.bar(x='A', y =["B", "C","ré"], stacked=True, largeur = 0.4,alpha=0.5)
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
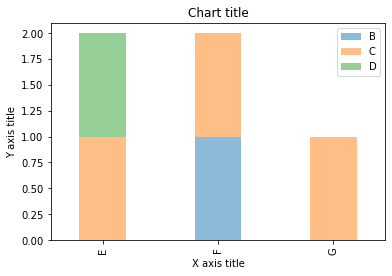
Graphique à barres empilées avec Seaborn
dataframe = pd.DataFrame(colonnes=["UNE","B", "C","ré"],
données=[["E",0,1,1],
["F",1,1,0],
["g",0,1,0]])
dataframe.set_index('UNE').T.plot(genre='bar', stacked=True)
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
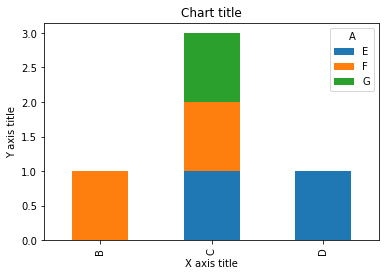
Graphique linéaire
Un graphique en courbes est utilisé pour représenter des points de données continus. Cet élément visuel peut être utilisé efficacement lorsque nous voulons comprendre la tendance au fil du temps..
Graphique en courbes avec Matplotlib
#Création du jeu de données
df = sns.load_dataset("iris")
df=df.groupby('sepal_length')['sepal_width'].somme().encadrer().reset_index()
#Création du graphique en courbes
plt.plot(df['sepal_length'], df['sepal_width'])
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
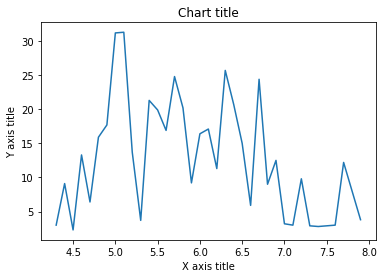
Graphique en courbes avec Seaborn
#Création du jeu de données
voitures = ['AUDI', 'BMW', 'NISSAN',
'TESLA', 'HYUNDAI', 'HONDA']
données = [20, 15, 15, 14, 16, 20]
#Création du camembert
plt.pie(Les données, étiquettes = voitures,couleurs = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B'])
#Ajout de l'esthétique
plt.titre('Titre du graphique')
#Montrer l'intrigue
plt.show()
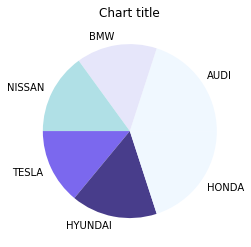
Diagramme circulaire
Les camemberts peuvent être utilisés pour identifier les proportions des différents composants dans un tout donné..
Camembert avec Matplotlib
#Création du jeu de données
voitures = ['AUDI', 'BMW', 'NISSAN',
'TESLA', 'HYUNDAI', 'HONDA']
données = [20, 15, 15, 14, 16, 20]
#Création du camembert
plt.pie(Les données, étiquettes = voitures,couleurs = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B'])
#Ajout de l'esthétique
plt.titre('Titre du graphique')
#Montrer l'intrigue
plt.show()
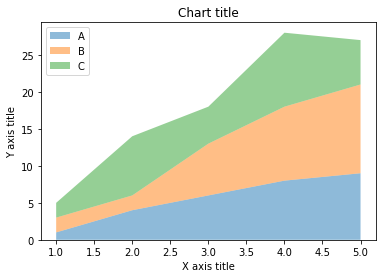
Graphique en aires
Les graphiques en aires sont utilisés pour suivre les changements au fil du temps pour un ou plusieurs groupes. Les graphiques en aires sont préférés aux graphiques en courbes lorsque nous voulons capturer les changements au fil du temps pour plusieurs groupes.
Graphique en aires avec Matplotlib
#Lecture du jeu de données
x=plage(1,6)
y =[ [1,4,6,8,9], [2,2,7,10,12], [2,8,5,10,6] ]
#Création du graphique en aires
hache = plt.gca()
ax.stackplot(X, Oui, étiquettes=['UNE','B','C'],alpha=0,5)
#Ajout de l'esthétique
plt.légende(loc ="en haut à gauche")
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
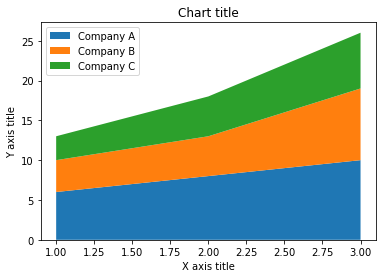
Carte en aires avec Seaborn
# Données
années_d'expérience =[1,2,3]
salaire =[ [6,8,10], [4,5,9], [3,5,7] ]
# Terrain
plt.stackplot(des années d'expérience,un salaire, étiquettes=[« Société A »,« Société B »,'Société C'])
plt.légende(loc ="en haut à gauche")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Histogramme de colonne
Les histogrammes de colonnes sont utilisés pour observer la distribution d'une seule variable avec peu de points de données.
Graphique à colonnes utilisant Matplotlib
#Création du jeu de données
pingouins = sns.load_dataset("pingouins")
#Création de l'histogramme des colonnes
hache = plt.gca()
hache.hist(pingouins['flipper_length_mm'], couleur="bleu",alpha=0,5, bacs=10)
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
Graphique à colonnes avec Seaborn
#Lecture du jeu de données
penguins_dataframe = sns.load_dataset("pingouins")
#Tracer l'histogramme des barres
sns.distplot(pingouins_dataframe['flipper_length_mm'], kde = Faux, couleur="bleu", bacs=10)
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Histogramme de ligne
Les histogrammes linéaires sont utilisés pour observer la distribution d'une seule variable avec de nombreux points de données.
Tracé d'histogramme de ligne à l'aide de Matplotlib
#Création du jeu de données
df_1 = np.aléatoire.normal(0, 1, (1000, ))
densité = stats.gaussian_kde(df_1)
#Création de l'histogramme de la ligne
m, X, _ = plt.hist(df_1, bins=np.linspace(-3, 3, 50), histtype=u'pas', densité=Vrai)
plt.plot(X, densité(X))
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
Graphique d'histogramme linéaire avec Seaborn
#Lecture du jeu de données
penguins_dataframe = sns.load_dataset("pingouins")
#Tracer l'histogramme de la ligne
sns.distplot(pingouins_dataframe['flipper_length_mm'], hist = Faux, où = Vrai, étiquette="Afrique")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Nuage de points
Les diagrammes de dispersion peuvent être utilisés pour identifier les relations entre deux variables. Peut être utilisé efficacement dans des circonstances où la variable dépendante peut avoir plusieurs valeurs pour la variable indépendante.
Nuage de points à l'aide de Matplotlib
#Création du jeu de données
df = sns.load_dataset("des astuces")
#Création du nuage de points
plt.scatter(df['Facture totale'],df['Astuce'],alpha=0,5 )
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
Nuage de points utilisant Seaborn
#Lecture du jeu de données
bill_dataframe = sns.load_dataset("des astuces")
#Création d'un nuage de points
sns.scatterplot(data=bill_dataframe, x="Facture totale", y ="Astuce")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Graphique à bulles
Les graphiques en nuage de points peuvent être utilisés pour représenter et montrer les relations entre trois variables.
Graphique à bulles avec Matplotlib
#Création du jeu de données
np.random.seed(42)
N = 100
x = np.aléatoire.normal(170, 20, N)
y = x + np.aléatoire.normal(5, 25, N)
couleurs = np.random.rand(N)
zone = (25 * np.random.rand(N))**2
df = pd.DataFrame({
'X': X,
'ET': Oui,
'Couleurs': couleurs,
"taille_bulle":Région})
#Création du graphique à bulles
plt.scatter('X', 'ET', s="taille_bulle",alpha=0,5, données=df)
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
Graphique à bulles avec Seaborn
#Lecture du jeu de données
bill_dataframe = sns.load_dataset("des astuces")
#Création d'un graphique à bulles
sns.scatterplot(data=bill_dataframe, x="Facture totale", y ="Astuce", teinte ="Taille", taille ="Taille")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Box plot
Une boîte à moustaches est utilisée pour montrer la forme de la distribution, sa valeur centrale et sa variabilité.
Box plot en utilisant Matplotlib
de past.builtins importer xrange
#Création du jeu de données
df_1 = [[1,2,5], [5,7,2,2,5], [7,2,5]]
df_2 = [[6,4,2], [1,2,5,3,2], [2,3,5,1]]
#Création de la boîte à moustaches
tiques = ['UNE', 'B', 'C']
plt.figure()
bpl = plt.boxplot(df_1, positions=np.tableau(xrange(longueur(df_1)))*2.0-0.4, sym = '', largeurs=0.6)
bpr = plt.boxplot(df_2, positions=np.tableau(xrange(longueur(df_2)))*2.0+0.4, sym = '', largeurs=0.6)
plt.plot([], c="#D7191C", étiquette="Étiqueter 1")
plt.plot([], c="#2C7BB6", étiquette="Étiqueter 2")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
plt.légende()
plt.xticks(xrange(0, longueur(tiques) * 2, 2), tiques)
plt.xlim(-2, longueur(tiques)*2)
plt.ylim(0, 8)
plt.tight_layout()
#Montrer l'intrigue
plt.show()
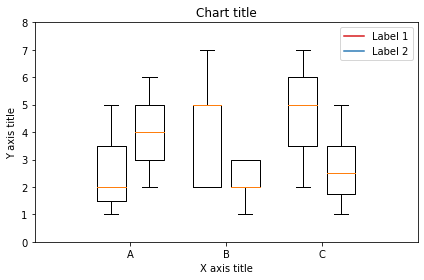
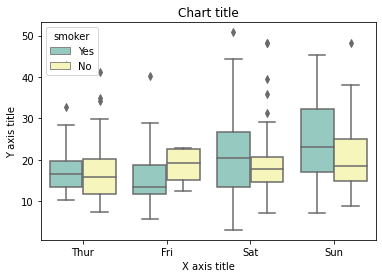
Box plot utilisant Seaborn
#Lecture du jeu de données
bill_dataframe = sns.load_dataset("des astuces")
#Création de boîtes à moustaches
ax = sns.boxplot(x="journée", y ="Facture totale", teinte ="fumeur", data=bill_dataframe, palette="Ensemble3")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Graphique en cascade
Un graphique en cascade peut être utilisé pour expliquer la transition progressive de la valeur d'une variable soumise à des augmentations ou des diminutions.
#Lecture du jeu de données
test = pd.Série(-1 + 2 * np.random.rand(10), index=liste('abcdefghij'))
#Fonction pour créer un graphique en cascade
chute d'eau def(séries):
df = pd.DataFrame({'pos':np.maximum(séries,0),'nég':np.minimum(séries,0)})
vide = series.cumsum().décalage(1).remplir(0)
df.plot(genre='bar', stacked=True, bas = vierge, couleur=['r','b'], alpha=0,5)
step = blank.reset_index(drop=Vrai).répéter(3).décalage(-1)
étape[1::3] = np.nan
plt.plot(step.index, step.values,'k')
#Création du graphique en cascade
cascade(test)
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
#Montrer l'intrigue
plt.show()
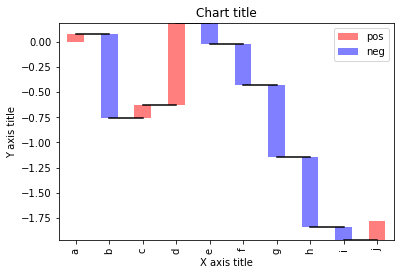
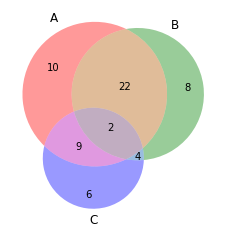
schéma de Venn
Les diagrammes de Venn sont utilisés pour voir les relations entre deux ou trois ensembles d'éléments. Mettre en évidence les similitudes et les différences
depuis matplotlib_venn importer venn3 #Faire un tableau d'amis ami3(sous-ensembles = (10, 8, 22, 6,9,4,2)) plt.show()
Carte arborescente
Les treemaps sont principalement utilisés pour afficher des données regroupées et imbriquées dans une structure hiérarchique et pour observer la contribution de chaque composant.
importer squarify
tailles = [40, 30, 5, 25, 10]
squarify.plot(tailles)
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
# Montrer l'intrigue
plt.show()
Graphique à barres 100% empilé
Vous pouvez profiter d'un graphique à barres empilées en 100% quand on veut montrer les différences relatives au sein de chaque groupe pour les différents sous-groupes disponibles.
#Lecture du jeu de données
r = [0,1,2,3,4]
raw_data = {« barres vertes »: [20, 1.5, 7, 10, 5], 'orangeBars': [5, 15, 5, 10, 15],'blueBars': [2, 15, 18, 5, 10]}
df = pd.DataFrame(données brutes)
# De la valeur brute au pourcentage
totaux = [i+j+k pour i,j,k en zip(df[« barres vertes »], df['orangeBars'], df['blueBars'])]
barres vertes = [je / j * 100 pour moi,j en zip(df[« barres vertes »], totaux)]
orangeBars = [je / j * 100 pour moi,j en zip(df['orangeBars'], totaux)]
barres bleues = [je / j * 100 pour moi,j en zip(df['blueBars'], totaux)]
# terrain
barWidth = 0.85
noms = ('UNE','B','C','RÉ','E')
# Créer des barres vertes
plt.bar(r, barres vertes, couleur="#b5ffb9", edgecolor="blanche", largeur=barWidth)
# Créer des barres oranges
plt.bar(r, orangeBars, bas = barres vertes, couleur="#f9bc86", edgecolor="blanche", largeur=barWidth)
# Créer des barres bleues
plt.bar(r, blueBars, bas =[i+j pour i,j en zip(barres vertes, orangeBars)], couleur="#a3acff", edgecolor="blanche", largeur=barWidth)
# Axe x personnalisé
plt.xticks(r, noms)
plt.xlabel("grouper")
#Ajout de l'esthétique
plt.titre('Titre du graphique')
plt.xlabel('Titre de l'axe X')
plt.ylabel('Titre de l'axe Y')
plt.show()
Parcelles marginales
Les graphiques marginaux sont utilisés pour évaluer la relation entre deux variables et examiner leurs distributions. Ces nuages de points qui ont des histogrammes, boîtes à moustaches ou dot plots sur les marges des axes x et y respectifs
#Lecture du jeu de données
iris_dataframe = sns.load_dataset('iris')
#Création de graphiques marginaux
sns.jointplot(x=iris_dataframe["longueur_sépale"], y = iris_dataframe["sepal_width"], kind='scatter')
# Montrer l'intrigue
plt.show()
Sous-parcelas
Les sous-trames sont des affichages puissants qui facilitent les comparaisons entre les trames
#Création du jeu de données
df = sns.load_dataset("iris")
df=df.groupby('sepal_length')['sepal_width'].somme().encadrer().reset_index()
#Création de l'intrigue secondaire
figure, axes = plt.subplots(nrows = 2, ncols = 2)
ax=df.plot('sepal_length', 'sepal_width',hache=axes[0,0])
ax.get_legend().supprimer()
#Ajout de l'esthétique
ax.set_title('Titre du graphique')
ax.set_xlabel('Titre de l'axe X')
ax.set_ylabel('Titre de l'axe Y')
ax=df.plot('sepal_length', 'sepal_width',hache=axes[0,1])
ax.get_legend().supprimer()
ax=df.plot('sepal_length', 'sepal_width',hache=axes[1,0])
ax.get_legend().supprimer()
ax=df.plot('sepal_length', 'sepal_width',hache=axes[1,1])
ax.get_legend().supprimer()
#Montrer l'intrigue
plt.show()
En conclusion, il existe une variété de bibliothèques différentes qui peuvent être exploitées à leur plein potentiel en comprenant le cas d'utilisation et les exigences. La syntaxe et la sémantique varient d'un package à l'autre et il est essentiel de comprendre les défis et les avantages des différentes bibliothèques.. Bon visionnage!
Scientifique des données et passionné d'analyse
Les supports présentés dans cet article ne sont pas la propriété d'Analytics Vidhya et sont utilisés à la discrétion de l'auteur..





