introduction: –
L'apprentissage automatique alimente les merveilles technologiques d'aujourd'hui, comme les voitures sans conducteur, vols spatiaux, accréditation image et voix. Malgré cela, un professionnel de la science des données aurait besoin d'un grand volume de données pour créer un modèle d'apprentissage automatique robuste et fiable pour de tels problèmes commerciaux.

L'exploration de données ou la collecte de données est une étape très primitive du cycle de vie de la science des données. Selon les exigences commerciales, vous devrez peut-être collecter des données à partir de sources telles que des serveurs, enregistrements, base de données, API, Dépôts SAP en ligne ou Web.
Les outils de grattage Web comme Selenium peuvent gratter un grand volume de données, sous forme de texte et d'images, en un temps relativement court.
Table des matières: –
- Qu'est-ce que le grattage Web?
- Pourquoi le grattage Web
- Comment le grattage Web est utile
- Qu'est-ce que le sélénium?
- Paramètres et outils
- Implémentation de l'image Web Scrapping à l'aide de Selenium Python
- Navigateur Chrome sans tête
- Tout mettre
- Remarques finales
Qu'est-ce que le grattage Web? : –
Mise à la ferraille du Web, aussi appelé « suivi » O « araignée » est la technique de collecte automatique de données à partir d'une source en ligne, en général d'un portail web. Bien que le Web Scrapping soit un moyen facile d'obtenir un grand volume de données dans un laps de temps relativement court, ajoute du stress au serveur où la police est hébergée.
C'est aussi l'une des principales raisons pour lesquelles de nombreux sites web ne permettent pas de tout scraper sur leur portail web.. Malgré cela, tant qu'il n'interrompt pas la fonction principale de la source en ligne, c'est tout à fait acceptable.
Pourquoi le grattage Web? –
Il existe un grand volume de données sur le Web que les gens peuvent utiliser pour répondre aux besoins de l'entreprise. Pour cela, un outil ou une technique est nécessaire pour collecter ces informations sur le Web. Et c'est là que le concept de Web-Scrapping entre en jeu..
A quoi sert le Web Scraping? –
Le scraping Web peut nous aider à extraire une énorme quantité de données client, produits, gens, marchés boursiers, etc.
Les données collectées à partir d'un portail Web peuvent être utilisées, en tant que portail de commerce électronique, portails d'emploi, canaux de médias sociaux pour comprendre les habitudes d'achat des clients, comportement d'attrition des travailleurs et sentiments des clients, Et la liste continue.
Les bibliothèques ou frameworks les plus populaires utilisés en Python pour le Web – Fils à la casse BeautifulSoup, Scrappy et Sélénium.
Dans ce billet, nous parlerons de web scrapping en utilisant Selenium en Python. Y la cereza en la parte de arriba veremos cómo podemos recabar imágenes de la web que puede usar para crear datos de trenes para su proyecto de l'apprentissage en profondeurL'apprentissage en profondeur, Une sous-discipline de l’intelligence artificielle, s’appuie sur des réseaux de neurones artificiels pour analyser et traiter de grands volumes de données. Cette technique permet aux machines d’apprendre des motifs et d’effectuer des tâches complexes, comme la reconnaissance vocale et la vision par ordinateur. Sa capacité à s’améliorer continuellement au fur et à mesure que de nouvelles données lui sont fournies en fait un outil clé dans diverses industries, de la santé....
Qu'est-ce que le sélénium?
Sélénium est un outil d'automatisation open source basé sur le Web. Le sélénium est principalement utilisé pour les tests dans l'industrie, mais il peut aussi être utilisé pour gratter le tissu. Nous utiliserons le navigateur Chrome mais vous pouvez l'essayer dans n'importe quel navigateur, c'est presque pareil.

Voyons maintenant comment utiliser Selenium pour le Web Scraping.
Paramètres et outils: –
- Installation:
- Installer le sélénium à l'aide de pip
pip installer le sélénium
- Installer le sélénium à l'aide de pip
- Téléchargez le pilote Chrome:
Pour télécharger les pilotes Web, vous pouvez sélectionner l'une des méthodes suivantes:- Vous pouvez directement télécharger le pilote Chrome à partir du lien suivant:
https://chromedriver.chromium.org/downloads - Ou vous pouvez le télécharger directement en utilisant la ligne de code suivante:contrôleur = webdriver.Chrome (ChromeDriverManager (). installer ())
- Vous pouvez directement télécharger le pilote Chrome à partir du lien suivant:
Vous pouvez trouver une documentation complète sur le sélénium ici. La documentation est explicite, alors assurez-vous de le lire pour profiter du sélénium avec Python.
Les méthodes suivantes nous aideront à trouver des éléments sur une page Web (ces méthodes renverront une liste):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
À présent, écrire un code Python pour extraire des images du Web.
Implémentation de l'image Web Scrapping à l'aide de Selenium Python: –
Paso 1: – Importer des bibliothèques
import os
import selenium
from selenium import webdriver
import time
from PIL import Image
import io
import requests
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import ElementClickInterceptedException
Paso 2: – Installer le pilote
#Installer le pilote pilote = webdriver.Chrome(ChromeDriverManager().installer())
Paso 3: – Spécifier l’URL de recherche
#Spécifier l’URL de recherche search_url= »https://www.google.com/search?q={q}&tbm=isch&tbs=sud:fc&hl=fr&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568" pilote.get(search_url.format(q='Voiture'))
J’ai utilisé cette URL spécifique afin que vous n’ayez pas d’ennuis pour l’utilisation d’images protégées par le droit d’auteur ou sous licence. Cas contraire, vous pouvez utiliser https://google.com également en tant qu’URL de recherche.
Ensuite, nous recherchons Voiture dans notre URL de recherche. Collez le lien dans la fonction driver.get (« Votre lien ici ») et exécutez la cellule. Cela ouvrira une nouvelle fenêtre de navigateur pour ce lien.
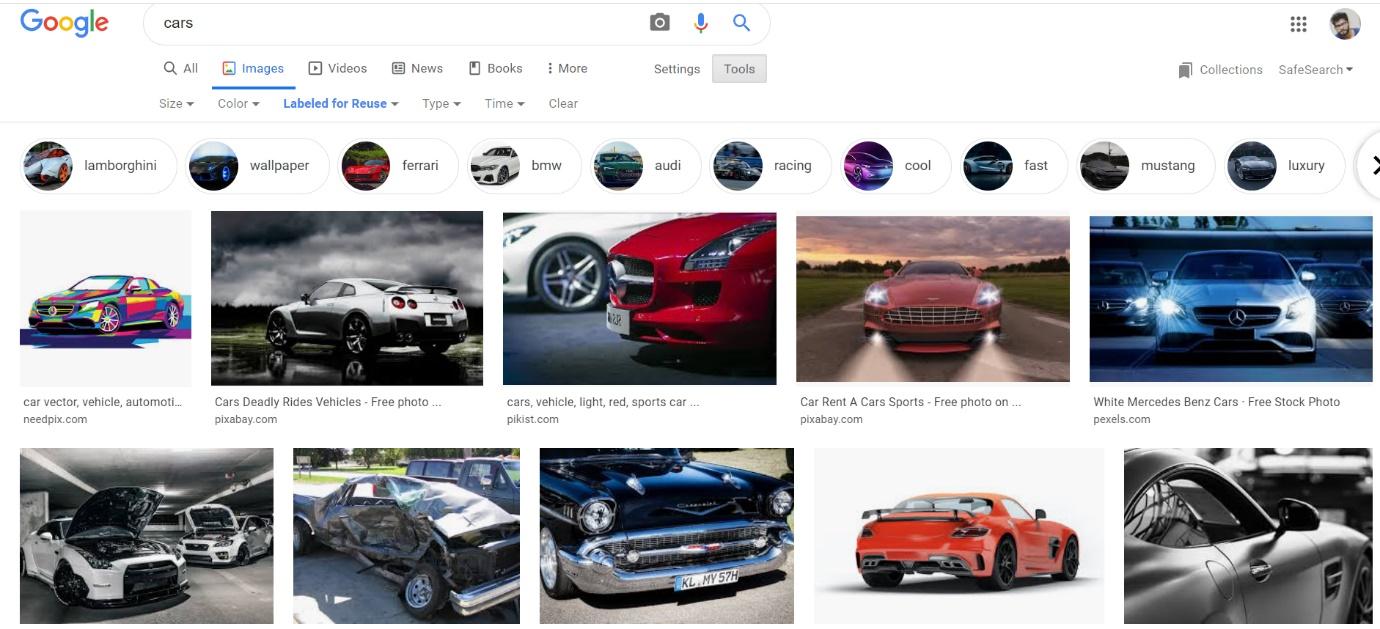
Paso 4: – Faites défiler jusqu’au bas de la page.
#Faites défiler jusqu’à la fin de la page
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
le sommeil de temps(5)#sleep_between_interactions
Cette ligne de code nous aiderait à aller au bas de la page. Et puis nous lui donnons un temps de repos de 5 secondes pour que nous n’ayons pas de problèmes, où nous essayons de lire des éléments de la page, qui n’est pas encore chargé.
Paso 5: – Localisez les images à gratter de la page.
#Localisez les images à gratter de la page active
imgResults = driver.find_elements_by_xpath("//img[contient(@class,'Q4LuWd')]")
totalResults=len(imgRésultats)
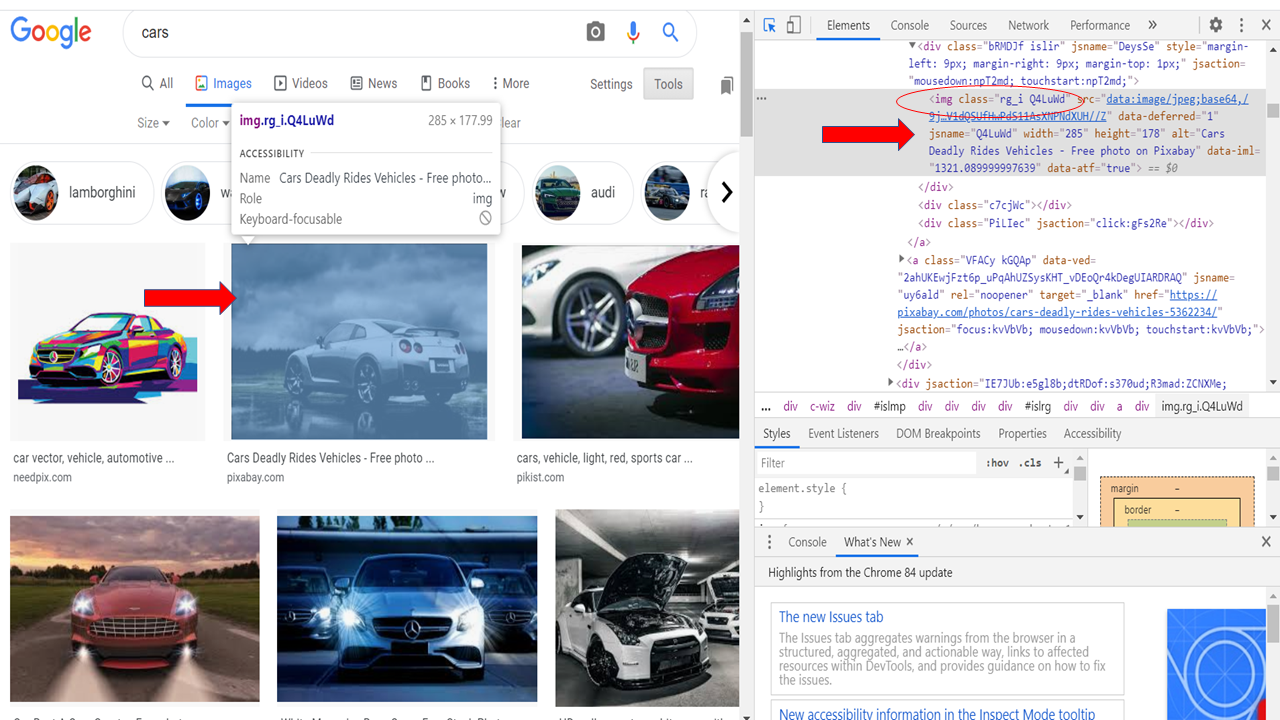
Nous allons maintenant rechercher tous les liens d'images présents sur cette page particulière. Nous allons créer un « prêt » pour enregistrer ces liens. Ensuite, pour faire ça, aller à la fenêtre du navigateur, haga clic derecho en la página y seleccione ‘inspeccionar elemento’ ou activer les outils de développement à l'aide de Ctrl + Changement + je.
Identifiez maintenant n'importe quel attribut en tant que classe, identifiant, etc. Ce qui est commun à toutes ces images.
Dans notre cas, class = ”’Q4LuWd” es común en todas estas imágenes.
Paso 6: – Extraire le lien respectif de chaque image
Comme nous pouvons, les images affichées sur la page sont toujours des vignettes, pas l'image originale. Ensuite, pour télécharger chaque image, nous devons cliquer sur chaque vignette et extraire les informations pertinentes concernant cette image.
#Cliquez sur chaque Image pour extraire son lien correspondant à télécharger
img_urls = définir()
pour je dans gamme(0,longueur(imgRésultats)):
img = imgRésultats[je]
essayer:
img.click()
le sommeil de temps(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
pour image_réelle dans images_réelles:
si actual_image.get_attribute('src') et 'https' dans actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
sauf ElementClickInterceptedException ou ElementNotInteractableException comme se tromper:
imprimer(se tromper)
Ensuite, dans l'extrait de code ci-dessus, nous effectuons les tâches suivantes:
- Répétez chaque vignette puis cliquez dessus.
- Faire dormir notre navigateur pendant 2 secondes (: P).
- Recherchez la balise HTML unique respective à cette image pour la placer sur la page
- Nous obtenons toujours plus d'un résultat pour une image particulière. Mais nous sommes tous intéressés par le lien pour télécharger cette image.
- Ensuite, iteramos por medio de cada resultado para esa imagen y extraemos el atributo ‘src’ de celui-ci et ensuite nous voyons si « https » está presente en el ‘src’ ou non. Dado que regularmente el link web comienza con ‘https’.
Paso 7: – Téléchargez et enregistrez chaque image dans le répertoire de destination
os.chdir('C:/Qurantine/Blog/WebScrapping/Dataset1')
baseDir=os.getcwd()
pour je, Adresse URL dans énumérer(img_urls):
file_name = f"{je:150}.jpg"
essayer:
image_content = requests.get(Adresse URL).contenu
sauf Exception comme e:
imprimer(F"ERREUR - IMPOSSIBLE DE TÉLÉCHARGER {Adresse URL} - {e}")
essayer:
image_file = io. OctetsIO(image_content)
image = Image.ouvrir(image_file).convertir('RVB')
file_path = os.path.join(baseDir, nom de fichier)
avec ouvert(file_path, 'wb') comme F:
image.save(F, "JPEG", qualité=85)
imprimer(F"SAUVÉ - {Adresse URL} - À: {file_path}")
sauf Exception comme e:
imprimer(F"ERREUR - IMPOSSIBLE D’ENREGISTRER {Adresse URL} - {e}")
Maintenant, en résumé, vous avez extrait l’image pour votre projet 😀
Noter: – Une fois que vous avez écrit le bon code, le navigateur n’est pas indispensable, peut collecter des données sans navigateur, ce qu’on appelle la fenêtre du navigateur sans tête, pour cela, remplacer le code suivant par le précédent.
Navigateur Chrome sans tête
#Navigateur chrome sans tête
de sélénium importer webdriver
opts = webdriver.ChromeOptions()
opts.headless =Vrai
pilote =webdriver. Chrome(ChromeDriverManager().installer())
Pour ce cas, le navigateur ne fonctionnera pas en arrière-plan, ce qui est très utile lors de la mise en œuvre d’une solution en production.
Mettons tout ce code dans une seule fonction pour le rendre plus organisable et implémenter la même idée à télécharger. 100 images pour chaque catégorie (par exemple, Voitures, Chevaux).
Et cette fois, nous écrivions notre code en utilisant l’idée du chrome sans tête..
Mettre tous ensemble:
Paso 1: importer toutes les bibliothèques indispensables
importer tu
importer sélénium
de sélénium importer lecteur web
importer temps
de PIL importer Image
importer Io
importer Requêtes
de webdriver_manager.chrome importer ChromeDriverManager
os.chdir('C:/Corantine/Blog/WebScrapping')
Paso 2: installer le pilote Chrome
#Installer le pilote opts=webdriver. ChromeOptions() opts.headless=Vrai pilote = webdriver.Chrome(ChromeDriverManager().installer() ,options=opts)
Dans cette étape, nous avons installé un pilote Chrome et utilisé un navigateur sans tête pour gratter le Web.
Paso 3: spécifier l’URL de recherche
search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sud:fc&hl=fr&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568" pilote.get(search_url.format(q='Voiture'))
J'ai utilisé cette URL spécifique pour extraire des images libres de droits.
Paso 4: écrire une fonction pour déplacer le curseur vers le bas de la page
déf scroll_to_end(conducteur):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
le sommeil de temps(5)#sleep_between_interactions
Cet extrait de code fera défiler la page vers le bas.
Paso 5. Ecrire une fonction pour obtenir l'URL de chaque image.
#aucun problème de licence
déf getImageUrls(Nom,totalImgs,conducteur):
search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sud:fc&hl=fr&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568"
pilote.get(search_url.format(q=nom))
img_urls = définir()
img_count = 0
result_start = 0
tandis que(img_count<totalImgs): #Extraire les images réelles maintenant
scroll_to_end(conducteur)
thumbnail_results = driver.find_elements_by_xpath("//img[contient(@class,'Q4LuWd')]")
totalResults=len(thumbnail_results)
imprimer(F"Trouvé: {totalRésultats} Résultats de recherche. Extraire des liens de{résultats_début}:{totalRésultats}")
pour img dans thumbnail_results[résultats_début:totalRésultats]:
img.click()
le sommeil de temps(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
pour image_réelle dans images_réelles:
si actual_image.get_attribute('src') et 'https' dans actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
img_count=len(img_urls)
si img_count >= totalImgs:
imprimer(F"Trouvé: {img_count} liens d'images")
Pause
autre:
imprimer("Trouvé:", img_count, "à la recherche de plus de liens d'images ...")
load_more_button = driver.find_element_by_css_selector(".mye4qd")
driver.execute_script("document.querySelector('.mye4qd').Cliquez sur();")
result_start = longueur(thumbnail_results)
revenir img_urls
Cette fonction renverrait une liste d'URL pour chaque catégorie (par exemple, voitures, les chevaux, etc.)
Paso 6: écrire une fonction pour télécharger chaque image
déf téléchargerImages(folder_path,nom de fichier,Adresse URL):
essayer:
image_content = requests.get(Adresse URL).contenu
sauf Exception comme e:
imprimer(F"ERREUR - IMPOSSIBLE DE TÉLÉCHARGER {Adresse URL} - {e}")
essayer:
image_file = io. OctetsIO(image_content)
image = Image.ouvrir(image_file).convertir('RVB')
file_path = os.path.join(folder_path, nom de fichier)
avec ouvert(file_path, 'wb') comme F:
image.save(F, "JPEG", qualité=85)
imprimer(F"SAUVÉ - {Adresse URL} - À: {file_path}")
sauf Exception comme e:
imprimer(F"ERREUR - IMPOSSIBLE D’ENREGISTRER {Adresse URL} - {e}")
Cet extrait de code téléchargera l’image de chaque URL.
Paso 7: – tapez une fonction pour enregistrer chaque image dans le répertoire de destination
déf saveInDestFolder(searchNames (noms de recherche),destDir,totalImgs,conducteur):
pour Nom dans liste(searchNames (noms de recherche)):
chemin=os.chemin.join(destDir,Nom)
si ne pas os.path.isdir(chemin):
os.mkdir(chemin)
imprimer('Chemin actuel',chemin)
totalLinks=getImageUrls(Nom,totalImgs,conducteur)
imprimer('totalLinks',totalLiens)
si totalLiens est Rien:
imprimer('images introuvables pour :',Nom)
Continuez
autre:
pour je, relier dans énumérer(totalLiens):
file_name = f"{je:150}.jpg"
téléchargerImages(chemin,nom de fichier,relier)
searchNames=['Voiture',« chevaux »]
destDir=f'./Dataset2/'
totalImgs=5
saveInDestFolder(searchNames (noms de recherche),destDir,totalImgs,conducteur)
cet extrait de code enregistrera chaque image dans le répertoire de destination.
Remarques finales
J’ai essayé ma part pour expliquer le Web Scraping en utilisant Selenium avec Python de la manière la plus simple possible.. N’hésitez pas à commenter vos questions. Je serai plus qu’heureux de vous répondre.
Vous pouvez cloner mon dépôt Github pour télécharger tout le code et les données, Cliquez ici!!
A propos de l'auteur

Praveen Kumar Anwla
J'ai travaillé en tant que data scientist avec des cabinets d'audit soutenus par des produits et Big 4 pour presque 5 ans. J'ai travaillé sur divers frameworks PNL, Machine learning et deep learning à la pointe de la technologie pour résoudre les problèmes commerciaux. N'hésitez pas à revoir mon blog perso, où je couvre des sujets d'apprentissage automatique: intelligence artificielle, des chatbots aux outils de visualisation (Tableau, QlikView, etc.) et diverses plateformes cloud comme Azure, IBM et le cloud AWS.





