introduzione
è una componente importante, nonché uno dei passaggi più sottovalutati in qualsiasi progetto di data science. L'EDA è essenziale per un'analisi dei dati ben definita e strutturata e dovrebbe essere eseguita prima della fase di modellazione dell'apprendimento automatico.
Si tratta di trovare idee dai dati dopo un'attenta osservazione e riassumere ulteriormente le sue caratteristiche principali.. In genere, i dati della vita reale con cui lavoriamo contengono molto “rumore” e, così, l'esecuzione manuale dell'analisi dei dati su tali set di dati diventa un processo complicato e noioso.

Tutorial introduttivo su Python: calcolo scientifico con i panda | da un appassionato di analisi dei dati | Metà
Chiodo è uno dei linguaggi più utilizzati per Scienza dei dati in particolare per la presenza di varie librerie e pacchetti che facilitano l'analisi dei dati.
Rispettivamente, panda è una delle librerie Python più popolari che aiuta a presentare i dati in un modo adatto all'analisi attraverso il suo Serie e Cornice dati Strutture dati. Fornisce varie funzioni e metodi per semplificare e velocizzare il processo di analisi dei dati.
Qui utilizziamo il set di dati "TITANIC" per eseguire l'implementazione pratica di tutte le funzioni.
Primo, importiamo la libreria Numpy e pandas e poi leggiamo il dataset.

Ora cominciamo
1. df.head (): Per impostazione predefinita, restituisce il primo 5 righe di frame di dati. Per modificare il valore predefinito, puoi inserire un valore tra parentesi per modificare il numero di righe restituite.

2. df.coda (): Per impostazione predefinita, restituisce l'ultimo 5 righe di frame di dati. Questa funzione viene utilizzata per ottenere le ultime n righe. Questa funzione restituisce le ultime n righe dell'oggetto in base alla posizione.

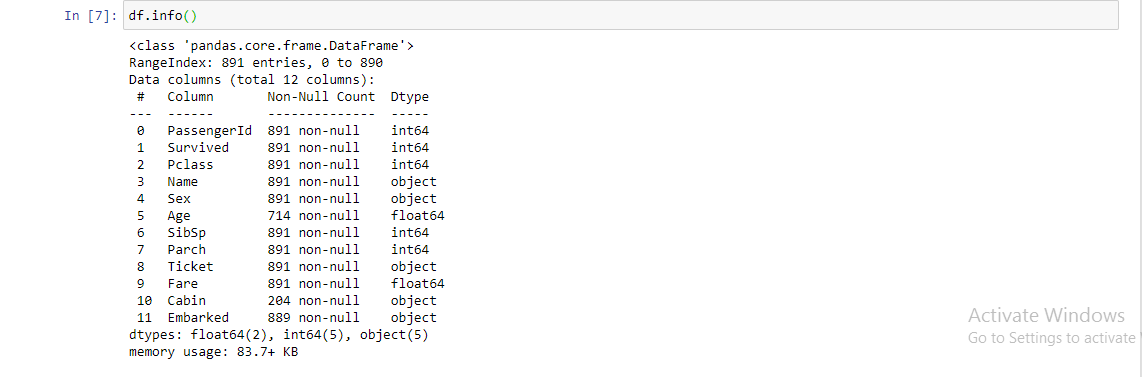
3. df.info (): Aiuta a ottenere una rapida panoramica del set di dati. Questa funzione viene utilizzata per ottenere un breve riepilogo del frame di dati. Questo metodo stampa le informazioni su un DataFrame, incluido el tipo de indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... y los tipos de columna, valori non nulli e utilizzo della memoria.
4. df. Forma: Muestra el número de dimensiones así como el tamaño en cada dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e.... Poiché i frame di dati sono bidimensionali, il modulo che restituisce è il numero di righe e colonne.
![]()
5. dimensione df: Restituisce un int che rappresenta il numero di elementi in questo oggetto. Restituisce il numero di righe se è Series; altrimenti, restituisce il numero di righe moltiplicato per il numero di colonne se è DataFrame.
![]()
6. df.ndim: Restituisce la dimensione della cornice / serie di dati. 1 per una dimensione (serie), 2 per due dimensioni (frame di dati).
![]()
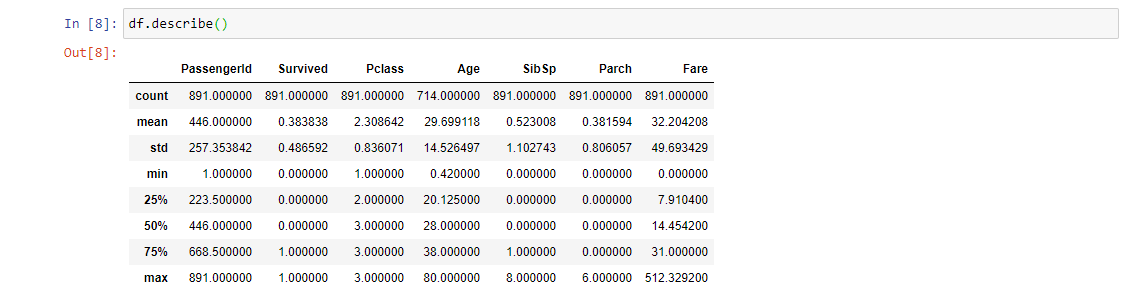
7. df.descrivi (): Restituisce un riepilogo statistico delle colonne numeriche presenti nel set di dati. Questo metodo calcola alcune misure statistiche come il percentile, la media e la deviazione standard dei valori numerici della Serie o DataFrame.
8. df.campione (): Utilizzato per campionare casualmente in una riga o in una colonna. Consente di selezionare casualmente i valori da una serie o DataFrame. È utile quando vogliamo selezionare un campione casuale da una distribuzione.

9. df.isnull () .somma (): Restituisce il numero di valori mancanti in ogni colonna.

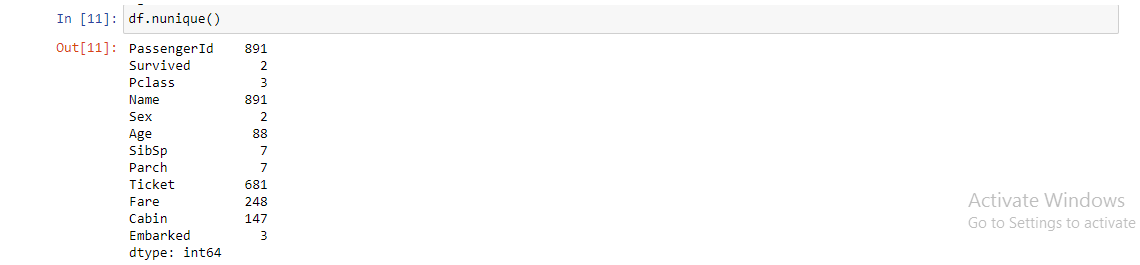
10. df.nunique (): Restituisce il numero di elementi univoci nell'oggetto. Conta il numero di voci univoche in colonne o righe. È molto utile nelle caratteristiche categoriche, soprattutto nei casi in cui non conosciamo in anticipo il numero di categorie.
11. df.index: Questa funzione cerca un dato elemento dall'inizio dell'elenco e restituisce l'indice più basso in cui appare l'elemento.
![]()
12. colonne df .: Restituisce le etichette delle colonne del frame di dati.

13. df.memory_usage (): Restituisce la quantità di memoria utilizzata da ogni colonna in byte. È utile soprattutto quando si lavora con frame di dati di grandi dimensioni.

14. df.dropna (): Questa funzione viene utilizzata per rimuovere una riga o una colonna da un frame di dati che ha un NaN o valori mancanti.

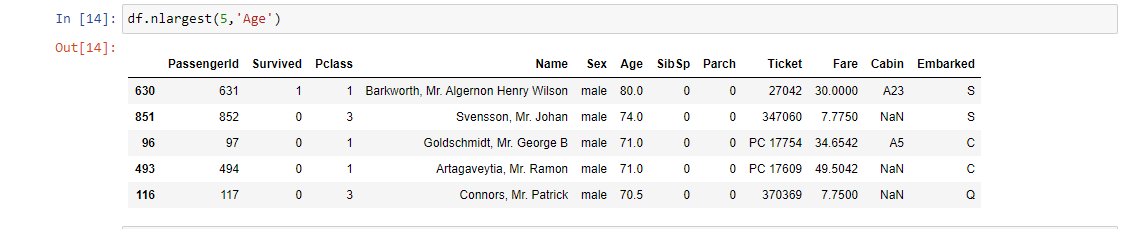
15. df.nlargest (): Restituisce il primo Nord righe ordinate per colonne in ordine decrescente.
16. df.isna (): Questa funzione restituisce un frame di dati pieno di valori booleani con true che indica i valori mancanti.

17. df.duplicato (): Restituisce una stringa booleana che denota righe duplicate.

18. value_counts (): Questa funzione viene utilizzata per ottenere una serie contenente conteggi di valori univoci. L'oggetto risultante sarà in ordine decrescente in modo che il primo elemento sia l'elemento che si verifica più frequentemente. Escludi i valori mancanti per impostazione predefinita. Esta función es útil cuando queremos verificar el problema del desequilibrio de clases para una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... Categorico.

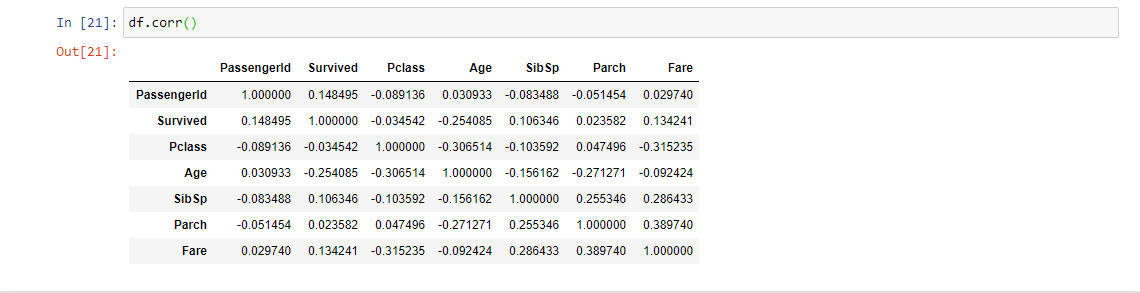
19. df.corr (): Questa funzione viene utilizzata per trovare la correlazione a coppie di tutte le colonne nel frame di dati. I valori mancanti vengono automaticamente esclusi. Per qualsiasi colonna di tipo di dati non numerico nel frame di dati, è ignorato. Questa funzione è utile durante la selezione delle caratteristiche osservando la correlazione tra le caratteristiche e la variabile target o tra le variabili.
20. tipi di df.d: Questa funzione mostra il tipo di dati di ogni colonna.

Note finali
Grazie per aver letto!
Se ti è piaciuto e vuoi saperne di più, visita gli altri miei articoli sulla scienza dei dati e sull'apprendimento automatico facendo clic sul collegamento
Sentiti libero di contattarmi a Linkedin, E-mail.
Tutto ciò che non è stato menzionato o vuoi condividere i tuoi pensieri? Sentiti libero di commentare qui sotto e ti ricontatterò.
Fino ad allora, stare a casa, stare al sicuro per prevenire la diffusione di COVID-19, E continua a imparare!
Circa l'autore
Chirag Goyal
Attualmente, Sto perseguendo il mio Bachelor of Technology (B.Tech) in informatica e ingegneria da Istituto indiano di tecnologia Jodhpur (IITJ). Sono molto entusiasta dell'apprendimento automatico, il apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... e intelligenza artificiale.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





