Fonte: https://www.serokell.io
Nella foto sopra, Puoi vedere che le e-mail sono classificate come spam o meno. Quindi, è un esempio di classificazione (Classificazione binaria).
1. Regressione logistica
2. Bayes ingenuo
3. K-vicini più vicini
5. Albero decisionale
Esamineremo tutti gli algoritmi con un po' di codice applicato al set di dati dell'iride utilizzato per le attività di classificazione. Il set di dati ha 150 Istanze (righe), 4 caratteristiche (colonne) e non contiene valori Null. Ci sono 3 Classi nel set di dati Iris:
– Iris Setosa
– Iris Versicolor
– Iris Virginica
Si tratta di un algoritmo di classificazione molto semplice ma importante nell'apprendimento automatico che utilizza una o più variabili indipendenti per stabilire un risultato. La regresión logística intenta hallar la vinculación que mejor se ajuste entre la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... dependiente y un conjunto de variables independientes. La linea che si adatta meglio a questo algoritmo assomiglia alla forma di S, come mostrato nel figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.....
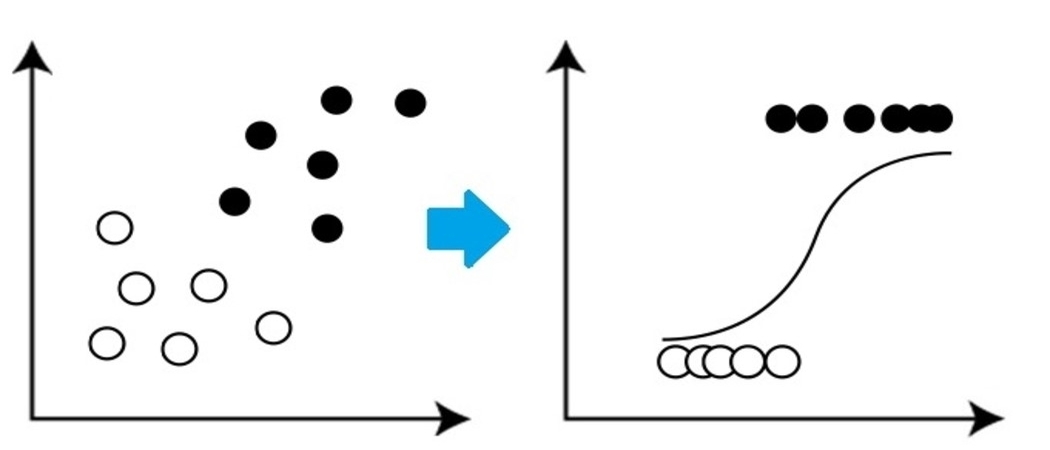
Fonte: https://www.equiskill.com
Professionisti:
- È un algoritmo molto semplice ed efficiente.
- Bassa varianza.
- Fornisce probabilità Punteggio delle osservazioni.
Contro:
- Maltrattamento Un grande Numero di caratteristiche categoriche.
- Si presuppone che i dati siano privi di valori mancanti e che i predittori siano indipendenti l'uno dall'altro.
Esempio:
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
X, y = load_iris()
LR_classifier = RegressioneLogica(stato_casuale=0)
LR_classifier.fit(X, e)
LR_classifier.predict(X[:3, :])
Produzione:
Vettore([0, 0, 0]) Ha predetto 0 Classe per tutti 3 Test forniti per predire la funzione.
2. Bayes ingenuo
Naive Bayes si basa su Teorema di Bayes che fornisce un'ipotesi di indipendenza tra i predittori. Questo classificatore presuppone che la presenza di una particolare funzionalità in una classe non sia correlata alla presenza di un'altra classe
caratteristica / variabile.
I classificatori Naive Bayes sono di tre tipi: Bayes ingenuo multinomiale, Bernoulli Naive Bayes, Bayes naavsiano gaussiano.
Professionisti:
- Questo algoritmo funziona molto velocemente.
- Inoltre, può essere utilizzato per risolvere problemi di previsione di vario tipo, dato che è abbastanza utile con loro.
- Este clasificador funciona mejor que otros modelos con menos datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... si se mantiene el supuesto de independencia de las características.
Contro:
- assume
che tutte le funzioni siano indipendenti. Anche se può suonare benissimo in
teoria, Ma nella vita reale, Nessuno è in grado di trovare un insieme di funzioni indipendenti.
Esempio:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
X, y = load_iris(return_X_y=Vero)
X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size=0.25, random_state=142)
Naive_Bayes = GaussianNB()
Naive_Bayes.fit(X_treno, y_train)
prediction_results = Naive_Bayes.predict(X_test)
Stampa(prediction_results)
Produzione:
Vettore([0, 1, 1, 2, 1, 1, 0, 0, 2, 1, 1, 1, 2, 0, 1, 0, 2, 1, 1, 2, 2, 1,0, 1, 2, 1, 2, 2, 0, 1, 2,
1, 2, 1, 2, 2, 1, 2])
Queste sono le classi previste per i dati X_test dal nostro modello di Bayes ingenuo.
3. Algoritmo K del vicino più prossimo
Devi aver sentito parlare di un detto popolare:
“Dio li risuscita ed essi si riuniscono.”
KNN funziona secondo lo stesso principio. Classifica i nuovi punti dati in base alla classe del maggior numero di punti dati tra il router adiacente K, dove K è il numero di vicini da considerare. KNN cattura l'idea di somiglianza (A volte chiamata distanza,
Prossimità o vicinanza) con alcune formule matematiche di base della distanza come la distanza euclidea, Distanza Manhattan, eccetera.

Fonte: https://www.javatpoint.com
Selezione del valore corretto per K
Per scegliere il K corretto per i dati di cui si vuole eseguire il training, eseguire l'algoritmo KNN più volte con valori K diversi e scegliere il valore K che riduce il numero di errori nei dati non visualizzati.
Professionisti:
- KNN è semplice e facile da implementare.
- Non c'è bisogno di creare un modello, ajustar varios parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... o hacer suposiciones adicionales como algunos de los otros algoritmos de clasificación.
- Può essere utilizzato per lo smistamento, Regressione e ricerca. Quindi, È flessibile.
- El algoritmo se torna significativamente más lento a misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que aumenta el número de ejemplos y / o predittori / variabili indipendenti.
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = train_test_split(X, e, test_size=0.25, random_state=142)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_treno, y_train)
prediction_results = knn.predict(X_test[:5,:)
Stampa(prediction_results)
Produzione:
Vettore([0, 1, 1, 2, 1]) Abbiamo previsto i nostri risultati per 5 Righe di esempio. Da qui l'abbiamo 5 risultati in matrice.
4. SVM
SVM è l'acronimo di Support Vector Machine. Si tratta di un algoritmo di apprendimento automatico supervisionato che viene spesso utilizzato per le sfide di classificazione e regressione. Nonostante questo, utilizzato principalmente nei problemi di classificazione. Il concetto di base della Support Vector Machine e il suo funzionamento possono essere meglio compresi con questo semplice esempio. Quindi, Immagina di avere due etichette: verde e blu, E i nostri dati hanno due caratteristiche: X e e. Vogliamo un classificatore che, dato un paio di (X, e) Coordinate, Partenze se è verde oh blu. Tracciare i dati di training etichettati in un disegno e quindi provare a trovare un disegno (Aumenta l'iperpiano delle dimensioni) che segrega i punti dati di entrambi i colori in modo molto chiaro.

Fonte: https://www.javatpoint.com
Ma questo è il caso dei dati lineari. Ma, Cosa succede se i dati non sono lineari?, Quindi usa il trucco del kernel? Quindi, Per gestire questo problema, aumentamos la dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e..., Questo porta i dati nello spazio e ora i dati diventano linearmente separabili in due gruppi.
Professionisti:
- SVM funciona relativamente bien cuando existe un claro margineMargine è un termine usato in una varietà di contesti, come la contabilità, Economia e stampa. In contabilità, si riferisce alla differenza tra ricavi e costi, che permette di valutare la redditività di un'impresa. Nel campo dell'editoria, Il margine è lo spazio bianco intorno al testo di una pagina, che lo rende facile da leggere e fornisce una presentazione estetica. La sua corretta gestione è fondamentale.. de separación entre clases.
- SVM è più efficace in grandi spazi.
Contro:
- SVM non è adatto per set di dati di grandi dimensioni.
- SVM non funziona molto bene quando il set di dati ha più rumore, In altre parole, Quando le classi target si sovrappongono. Quindi, deve essere gestito.
Esempio:
from sklearn import svm
svm_clf = svm.SVC()
X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size=0.25, random_state=142)
svm_clf.fit(X_treno, y_train)
prediction_results = svm_clf.predict(X_test[:7,:])
Stampa(prediction_results)
Produzione:
Vettore([0, 1, 1, 2, 1, 1, 0])
5.Albero decisionale
L'albero decisionale è uno degli algoritmi di apprendimento automatico più utilizzati. Utilizzato per problemi di classificazione e regressione. Gli alberi decisionali imitano il pensiero a livello umano, Quindi è molto facile capire i dati e fare buone intuizioni e interpretazioni. In realtà, Ti fanno vedere la logica dei dati per interpretarli. Gli alberi decisionali non sono come gli algoritmi black-box come SVM, reti neurali, eccetera.
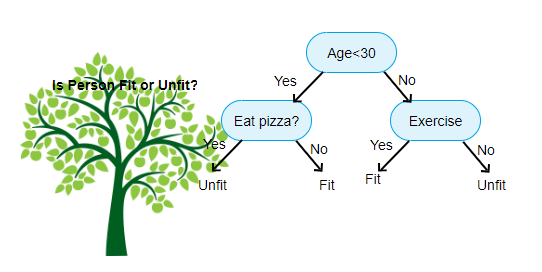
Fonte: https://www.aitimejournal.com
Come esempio, se classifichiamo una persona come idonea o non idonea, L'albero delle decisioni è simile a questo nell'immagine.
Quindi, In sintesi, un árbol de decisión es un árbol donde cada nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... representa un
caratteristica / attributo, Ogni ramo rappresenta una decisione, un righello e ogni foglio rappresenta un risultato. Questo risultato può essere di valore categorico o continuo. Categorico in caso di classificazione e continuo in caso di applicazioni di regressione.
Professionisti:
- Rispetto ad altri algoritmi, Gli alberi decisionali richiedono meno sforzo per la preparazione dei dati durante la pre-elaborazione.
- Tampoco requieren la standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... de datos ni el escalado.
- Il modello sviluppato nell'albero decisionale è molto intuitivo e facile da spiegare sia ai team tecnici che agli stakeholder.
Contro:
- Se viene apportata anche una piccola modifica ai dati, Ciò può portare a un grande cambiamento nella struttura dell'albero decisionale che causa instabilità.
- Qualche volta, Il calcolo può essere molto più complesso rispetto ad altri algoritmi.
- Gli alberi decisionali richiedono in genere più tempo per eseguire il training del modello.
Esempio:
from sklearn import tree
dtc = tree.DecisionTreeClassifier()
X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size=0.25, random_state=142)
dtc.fit(X_treno, y_train)
prediction_results = dtc.predict(X_test[:7,:])
Stampa(prediction_results)
Produzione:
Vettore([0, 1, 1, 2, 1, 1, 0])
Note finali
Queste sono le 5 Algoritmi di classificazione più popolari, Ci sono molti altri algoritmi avanzati per l'avvio. Esplorali anche tu. Connettiamoci LinkedIn
Grazie per aver letto se sei arrivato qui 🙂
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





