Questo post è stato pubblicato come parte del Blogathon sulla scienza dei dati
introduzione
Come scienziato dei dati, il web scraping è una delle abilità vitali che devi padroneggiare, e dovresti cercare dati utili, raccogliere e pre-elaborare i dati in modo che i risultati siano significativi e accurati.
Prima di immergerci negli strumenti che potrebbero aiutare nelle attività di data mining, confermiamo che questa attività è legale dato che il web scraping è stata un'area legale grigia. Il tribunale EE. UU. Scraping web completamente legalizzato di dati pubblicamente disponibili su 2020. Significa che se hai trovato informazioni online (come post wiki), allora è legale raschiare i dati.
Comunque, Quando lo fai, essere sicuri di:
- Non riutilizzare o ripubblicare i dati in modo da violare il copyright.
- Che rispetti i termini di servizio del portale web che stai raschiando.
- Che tu abbia un tasso di monitoraggio equo.
- Non cercare di estrarre parti private del portale web.
Purché non violi i termini di cui sopra, la tua attività di web scraping sarà legale.
Penso che alcuni di voi potrebbero aver usato BeautifulSoup e richieste per raccogliere i dati e i panda per analizzarli per i propri progetti. Questo post ti fornirà cinque strumenti di web scraping che non includono BeautifulSoup; è gratuito e raccoglie i dati per il tuo prossimo progetto.
Il creatore di Common Crawl ha creato questo strumento perché presuppone che tutti dovrebbero avere la capacità di esplorare ed eseguire analisi dei dati che li circondano e scoprire informazioni utili.. Contribuiscono a dati di alta qualità che erano aperti solo a grandi istituzioni e istituti di ricerca a qualsiasi mente indiscreta senza alcun costo per incoraggiare le loro convinzioni sull'open source..
Puoi utilizzare questo strumento senza preoccuparti di commissioni o altre difficoltà finanziarie. Se sei uno studente, un principiante che si tuffa nella scienza dei dati o solo una persona desiderosa che ama esplorare la conoscenza e scoprire nuove tendenze, questo strumento sarebbe utile. Rendi disponibili dati grezzi di pagine Web ed estratti di parole come set di dati aperti. Offre anche risorse per istruttori che insegnano l'analisi dei dati e supporto per casi d'uso non basati su codice..
Vai oltre sito web per ulteriori informazioni sull'utilizzo di set di dati e alternative per l'estrazione dei dati.
Crawly è un'altra alternativa, soprattutto se hai solo bisogno di estrarre dati semplici da un portale web o se vuoi estrarre dati in formato CSV in modo da poterli esaminare senza scrivere alcun codice. L'utente deve inserire un URL, un'e-mail identificativa per inviare i dati estratti, il formato dei dati richiesti (scegli tra CSV o JSON) e pronto, i dati estratti sono nella tua casella di posta per l'uso.
È possibile utilizzare i dati JSON e analizzarli utilizzando Pandas e Matplotlib, o qualsiasi altro linguaggio di programmazione. Se sei un principiante della scienza dei dati e del web scraping, non un programmatore, questo è buono e ha i suoi limiti. È possibile estrarre un set limitato di tag HTML incluso il titolo, Autore, URL immagine ed editor.
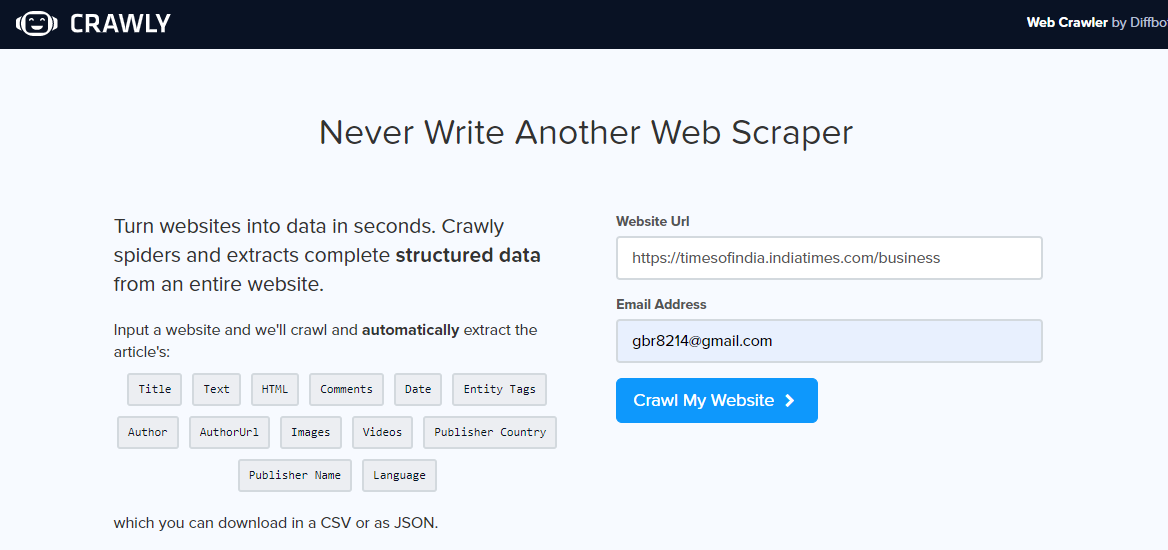
Una volta aperto il portale web di monitoraggio, inserisci l'URL per raschiare, seleziona il formato dei dati e il tuo ID e-mail per ricevere i dati. Controlla la tua casella di posta per vedere i dati.
Il content grabber è uno strumento flessibile se ti piace graffiare una pagina web e non vuoi specificare altri parametri, l'utente può farlo usando la sua semplice GUI. Comunque, offre la possibilità di un controllo completo dei parametri di estrazione da personalizzare.
L'utente può pianificare automaticamente le informazioni di scraping dal Web, è uno dei suoi vantaggi. Attualmente, sappiamo tutti che le pagine web vengono aggiornate regolarmente, quindi l'estrazione frequente dei contenuti sarebbe utile.
Offre vari formati di dati estratti come CSV, JSON a SQL Server o MySQL.
Un rapido esempio per raschiare i dati
È possibile utilizzare questo strumento per navigare visivamente nel portale web e fare clic sugli elementi di dati nell'ordine in cui si desidera raccoglierli.. Rileverà automaticamente il tipo corretto di azione e fornirà nomi predefiniti per ogni comando mentre costruisce l'agente in base agli elementi di contenuto specificati.
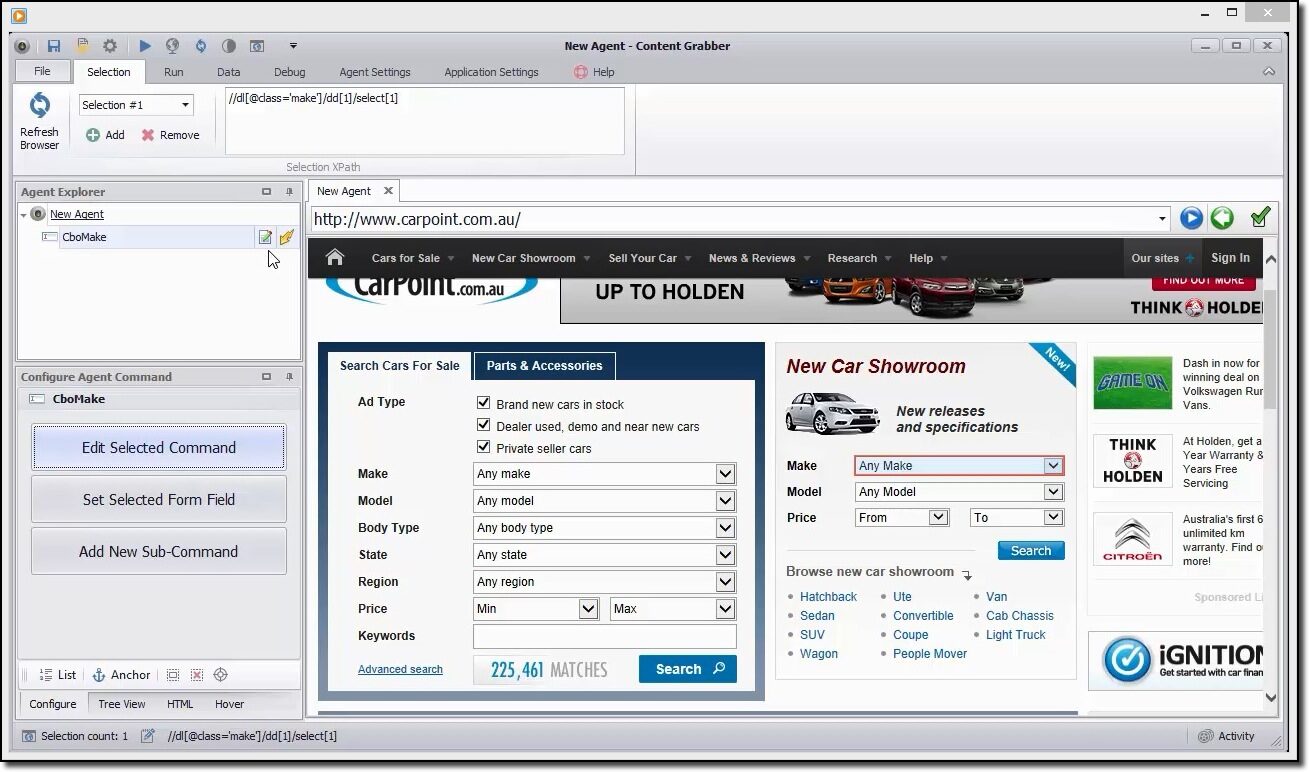
Questo strumento è una raccolta di comandi che vengono eseguiti in ordine fino al completamento. L'ordine di esecuzione viene aggiornato nel pannello Agent Explorer. È possibile utilizzare il pannello comandi dell'agente di configurazione per personalizzare il comando in base ai propri requisiti di dati particolari.. Gli utenti possono anche aggiungere nuovi comandi.
ParseHub è un potente strumento di web scraping che chiunque può utilizzare gratuitamente. Offre un'estrazione dei dati sicura e accurata con la facilità di un clic. Gli utenti possono anche determinare i tempi di estrazione per mantenere la rilevanza dei loro resti..
Uno dei suoi punti di forza è che può cancellare senza problemi anche le pagine web più complicate.. L'utente può specificare istruzioni come moduli di ricerca, accedi ai siti Web e fai clic su mappe o immagini per una raccolta dati successiva.
Gli utenti possono anche entrare con molti link e parole chiave, dove possono estrarre informazioni rilevanti in pochi secondi. Finire, puoi utilizzare l'API REST per scaricare i dati estratti per l'analisi nei formati CSV o JSON. Gli utenti possono anche esportare le informazioni raccolte come foglio Google o Tableau..
Esempio di portale web di scraping e-commerce
Una volta completata l'installazione, apri un nuovo progetto su ParseHub, usa l'URL e-commerce e la pagina verrà visualizzata nell'app.
- Clicca sul nome del prodotto del primo risultato nella pagina dopo che il sito è stato caricato. Quando selezioni il prodotto, diventa verde per indicare che è stato scelto.
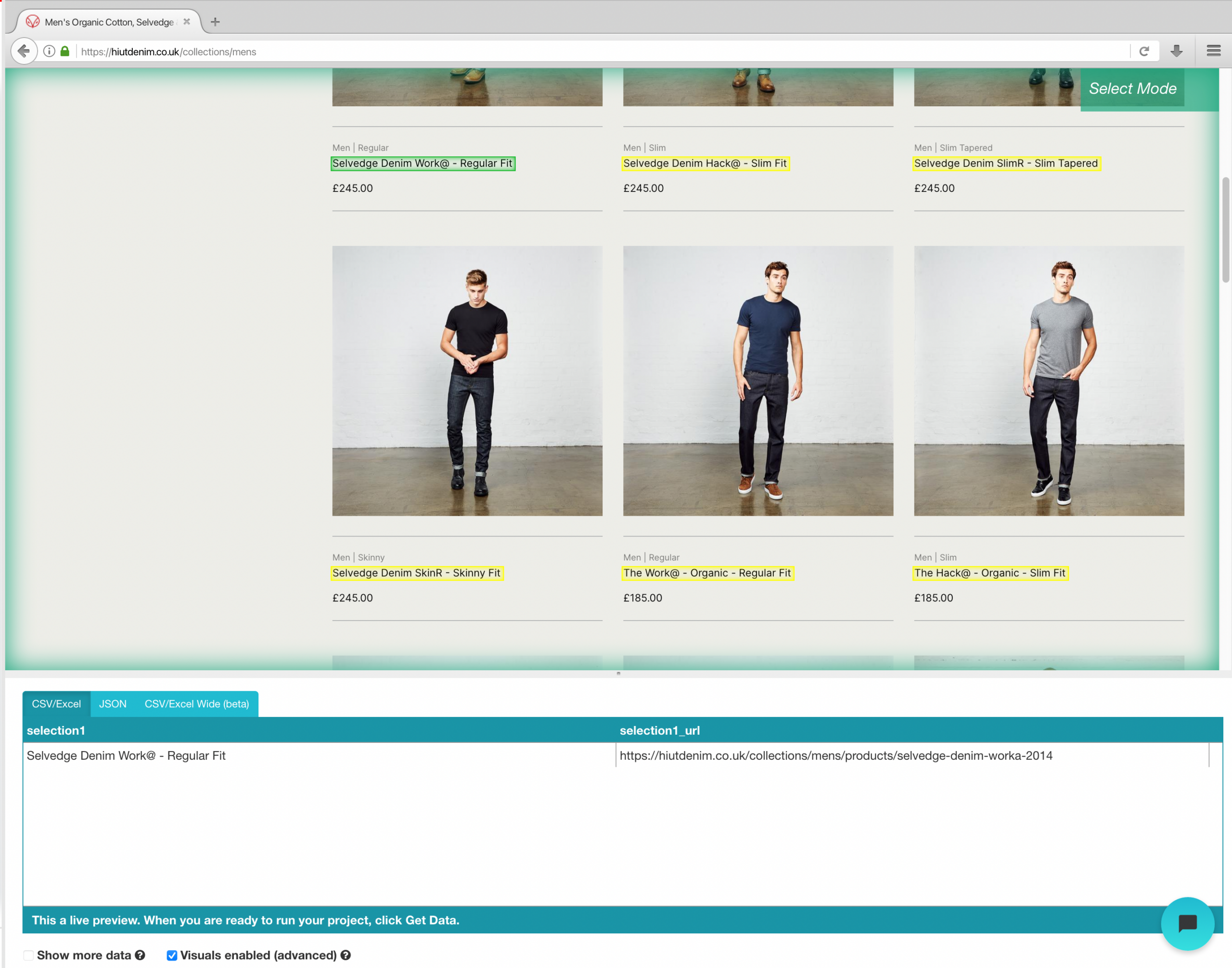
- Il giallo verrà utilizzato per evidenziare il resto dei nomi dei prodotti. Seleziona la seconda opzione dall'elenco. Il verde verrà ora utilizzato per evidenziare tutti gli oggetti.
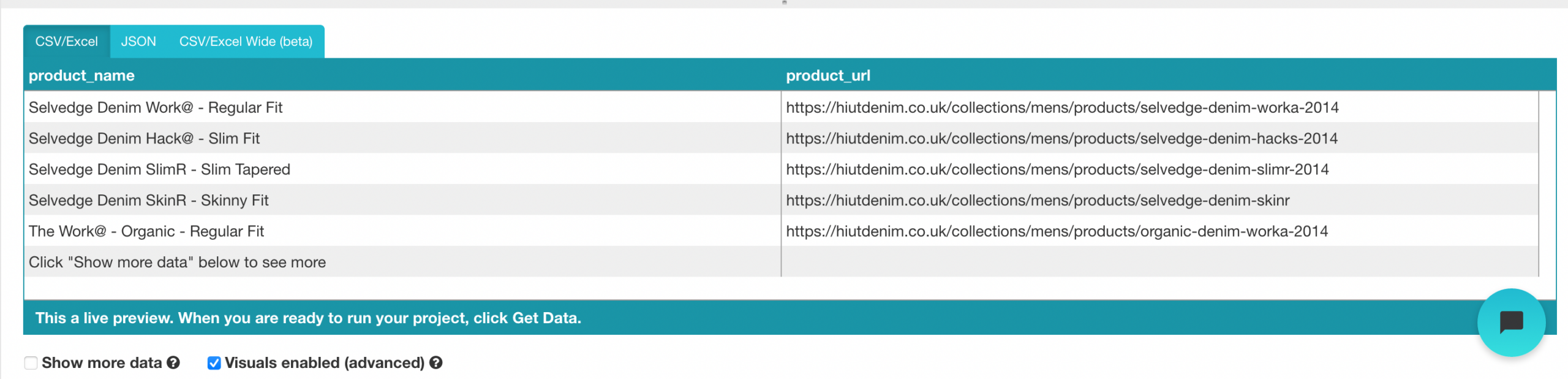
- Cambia il nome che preferisci in “Prodotto” nella barra laterale di sinistra. Ora puoi vedere il nome del prodotto e l'URL estratti da ParseHub.
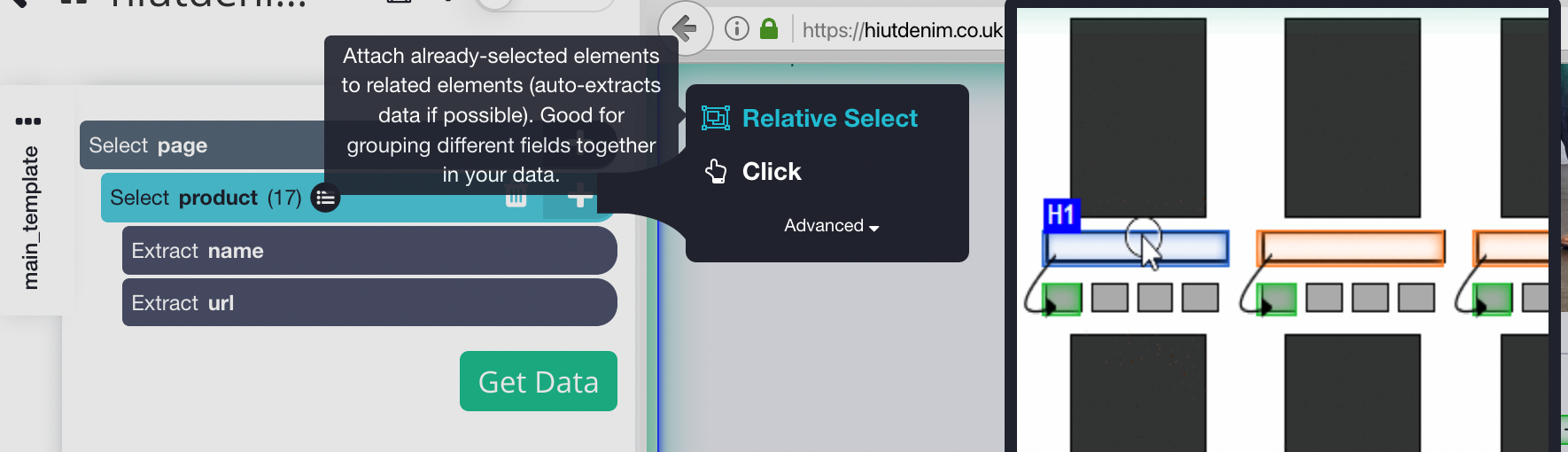
- Clicca sul segno PI (+) accanto alla selezione del prodotto nella barra laterale sinistra e seleziona il comando Selezione relativa.
- Fare clic sul nome del primo prodotto nella pagina, seguito dal prezzo del prodotto, usando il comando Selezione relativa. Apparirà una freccia che collega le due opzioni. Questo passaggio deve essere ripetuto più volte per addestrare Parsehub in ciò che si desidera estrarre.
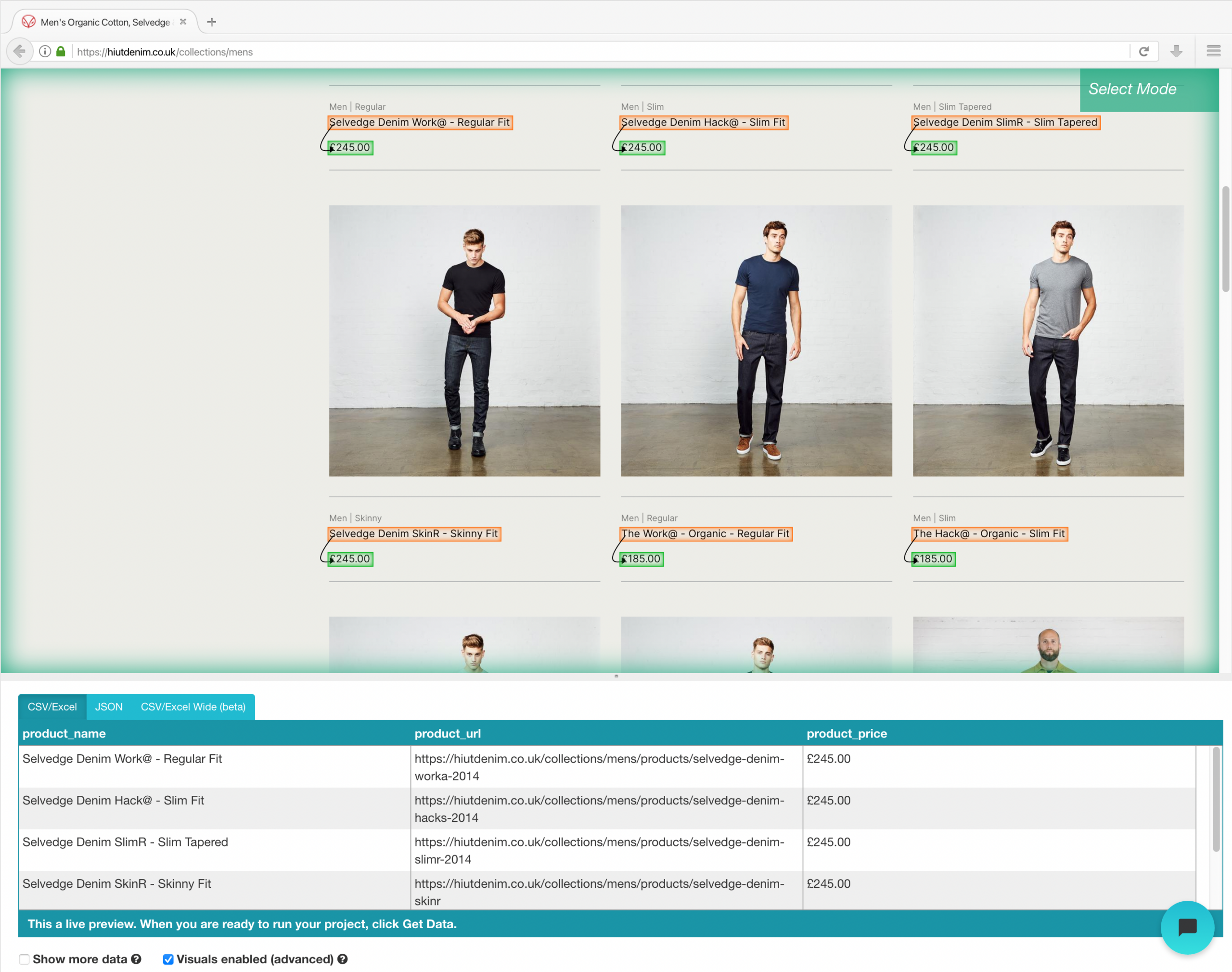
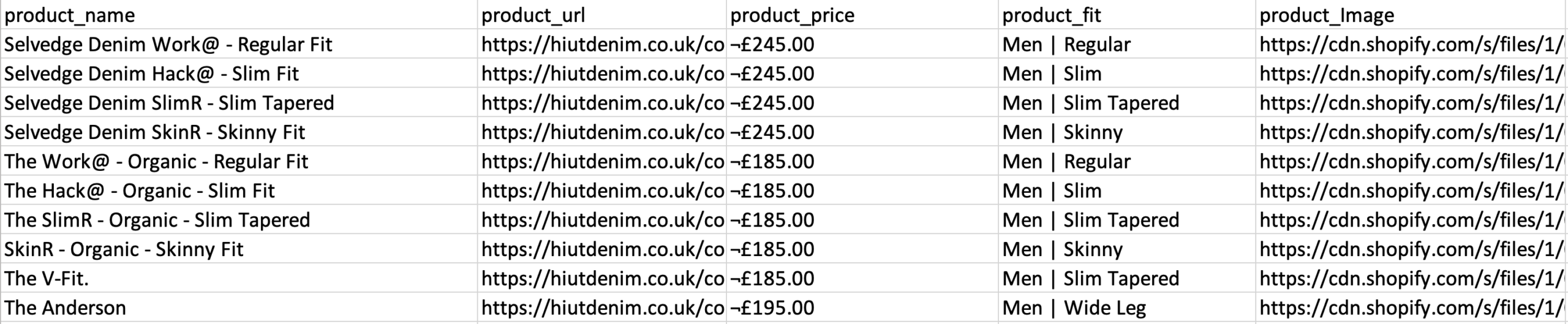
- Ripeti il passaggio precedente per estrarre anche lo stile di adattamento e l'immagine del prodotto. Assicurati di rinominare le nuove opzioni in modo appropriato.
Esecuzione ed esportazione del tuo progetto
Ora che abbiamo finito di configurare il progetto, è ora di eseguire il nostro lavoro di raschiatura.
Per eseguire il tuo raschiamento, fai clic sul pulsante Ottieni dati nella barra laterale sinistra e quindi fai clic sul pulsante Esegui. Per progetti più grandi, ti suggeriamo di eseguire un test per assicurarti che i tuoi dati siano nel formato corretto.
È l'ultimo strumento per raschiare sulla lista. Ha un'API di web scraping in grado di gestire anche le pagine Javascript più complesse e convertirle in HTML non elaborato per l'utilizzo da parte degli utenti.. Offre anche un'API specifica per grattare i siti Web tramite la ricerca di Google..
Possiamo usare questo strumento in tre modi:
- Web Scraping generale, come esempio, estrarre le recensioni dei clienti o i prezzi delle azioni.
- Pagina dei risultati del motore di ricerca utilizzata per il monitoraggio delle parole chiave o SEO.
- L'estrazione di informazioni di contatto o dati dai social network include il Growth Hacking.
Questo strumento offre un piano gratuito che include 1000 crediti e piani a pagamento ad uso illimitato.
Tutorial sull'utilizzo dell'API Scrapingbee
Iscriviti per un piano gratuito sul portale web ScrapingBee e otterrai 1000 richieste API gratuite, che dovrebbe essere sufficiente per imparare e testare questa API.
Ora vai al pannello di controllo e copia la chiave API di cui avremo bisogno più avanti in questa guida. ScrapingBee ora fornisce supporto multilingue, permettendoti di utilizzare la chiave API direttamente nelle tue applicazioni.
Poiché Scaping Bee supporta le API REST, è adatto a qualsiasi linguaggio di programmazione, incluso CURL, Pitone, NodeJS, Giava, PHP e Go. Per ulteriori informazioni sullo scraping, useremo Python e il framework di richiesta, così come BeautifulSoup. Installali usando PIP il prima possibile:
# Per installare la libreria Richieste Python: pip richieste di installazione # Moduli aggiuntivi di cui avevamo bisogno: pip installare BeautifulSoup
Utilizzare il codice seguente per avviare l'API Web ScrapingBee. Stiamo effettuando una chiamata di richiesta con i parametri chiave URL e API, e l'API risponderà con il contenuto HTML dell'URL di destinazione.
import requests def get_data(): risposta = request.get( url="https://app.scrapingbee.com/api/v1/", params={ "api_key": "INSERISCI LA TUA CHIAVE API", "URL": "https://example.com/", #sito web da raschiare }, ) Stampa('codice di stato http: ', response.status_code) Stampa('http corpo di risposta: ', response.content) get_data()
Quando si aggiunge un codice di abbellimento, possiamo rendere questo output più leggibile usando BeautifulSoup.
codifica
È inoltre possibile utilizzare Urllib.parse per crittografare l'URL che si desidera eliminare, come mostrato di seguito:
import urllib.parse
encoded_url = urllib.parse.quote("URL da raschiare")
conclusione
Raccogliere dati per i tuoi progetti è il passaggio più noioso e meno divertente. Questo compito può richiedere molto tempo, e se lavori in un'azienda o come libero professionista, Sapevo che il tempo è denaro, e se c'è un modo più importante per svolgere un compito, è meglio che lo usi. La buona notizia è che il web scraping non deve essere noioso, poiché l'utilizzo dello strumento corretto può aiutarti a risparmiare molto tempo, soldi e fatica. Questi strumenti possono essere utili per analisti o persone senza capacità di codifica.. Prima di scegliere uno strumento per raschiare, ci sono alcuni fattori da considerare, come l'integrazione delle API e l'estensibilità dello scraping su larga scala. Questo post ti ha presentato alcuni strumenti utili per diverse attività di raccolta dati., dove puoi selezionare quello che facilita la raccolta dei dati.
Spero che questo articolo sia utile. Grazie.
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





