introduzione
Se in qualsiasi momento hai partecipato a concorsi di data science, dovresti essere consapevole del ruolo fondamentale che gioca la modellazione d'insieme. In realtà, Si dice che la modellazione di insieme offra uno dei modi più convincenti per costruire modelli predittivi altamente accurati. La disponibilità di insaccamento e rinforzo Gli algoritmi abbelliscono ulteriormente questo metodo per produrre un sorprendente livello di precisione.
Perché, la prossima volta che crei un modello predittivo, considera l'utilizzo di questo algoritmo. Mi darei sicuramente una pacca sulla spalla per questo suggerimento.. E, se già padroneggi questo metodo, geniale. Mi piacerebbe sentire la tua esperienza sulla modellazione d'insieme nella sezione commenti qui sotto..
Altrimenti, Condivido alcune delle domande più frequenti sulla modellazione d'insieme. Se in qualsiasi momento vuoi esaminare la conoscenza di qualcuno del set, potresti osare porre queste domande e verificare le tue conoscenze. Allo stesso tempo, queste sono alcune delle domande più facili, quindi non puoi osare di sbagliare.

Quali sono le domande comuni (associati a modelli di insieme)?
Dopo aver analizzato diversi forum sulla scienza dei dati, ho identificato il 5 Domande comuni associate alla modellazione d'insieme. Queste domande sono molto importanti per i data scientist che non conoscono la modellazione di insieme.. Ecco le domande:
- Cos'è un modello fisso?
- Cosa stanno insaccando?, rinforzo e impilamento?
- Possiamo assemblare più modelli dello stesso algoritmo ML??
- Come possiamo identificare i pesi dei diversi modelli??
- Quali sono i vantaggi del modello ensemble?
Analizziamo ogni domanda nel dettaglio.
1. Cos'è un modello fisso?
Proviamo a capirlo risolvendo una sfida di qualificazione.
Problema: impostare regole per l'ordinamento delle e-mail di spam

Soluzione: Possiamo generare diverse regole per la classificazione delle email di spam, vediamone qualcuna:
- Posta indesiderata
- Avere un'estensione totale inferiore a 20 parole.
- Avere solo immagine (immagini promozionali)
- Avere parole chiave specifiche come “guadagnare soldi e crescere” e “ridurre il grasso”
- Altre parole scritte nell'e-mail
- Niente spam
- E-mail di dominio DataPeaker
- E-mail dai membri della famiglia o da chiunque nella rubrica degli indirizzi e-mail
Al di sopra, Ho elencato alcune regole comuni per filtrare le email di spam. Pensi che tutte queste regole individualmente possano prevedere la classe corretta??
La maggior parte di noi direbbe di no, Ed è vero! La combinazione di queste regole fornirà una previsione solida rispetto alla previsione fatta dalle singole regole.. Questo è il principio della modellazione d'insieme. Il modello del set combina diversi "modelli individuali"’ (multiplo) insieme e offre un potere predittivo superiore.
Se vuoi metterlo in relazione con la vita reale, è probabile che un gruppo di persone prenda decisioni migliori rispetto agli individui, soprattutto quando i membri del gruppo provengono da più ambienti. Lo stesso vale per l'apprendimento automatico. Semplicemente, un conjunto es una técnica de apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... para combinar múltiples studenti / modelli deboli per produrre un forte apprendista. Il modello di assemblaggio funziona meglio quando assembliamo modelli con bassa correlazione.
Un buon esempio di come i metodi di insieme sono comunemente usati per risolvere problemi di data science è il foresta casuale algoritmo (che ha diversi modelli di CART). Funziona meglio rispetto al modello CART individuale quando si categorizza un nuovo oggetto in cui ogni albero dà “voti” per quella classe e la foresta sceglie la classifica che ha più voti (su tutti gli alberi della foresta). In caso di regressione, prende la media degli output di diversi alberi.
Puoi anche seguire questo post “Imposta le basi dell'apprendimento spiegate in inglese semplice” per saperne di più sulla modellazione d'insieme.
2. Cosa stanno insaccando?, rinforzo e impilamento?
Diamo un'occhiata a ciascuno di questi singolarmente e proviamo a capire le differenze tra questi termini.:
Harpillera (Bootstrap Aggregazione) è un metodo stabilito. Primo, creamos muestras aleatorias del conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... (sottoinsiemi del set di dati di addestramento). Dopo, costruiamo un classificatore per ogni campione. In sintesi, i risultati di questi classificatori multipli sono combinati attraverso il voto medio o a maggioranza. L'insaccamento aiuta a ridurre l'errore di varianza.
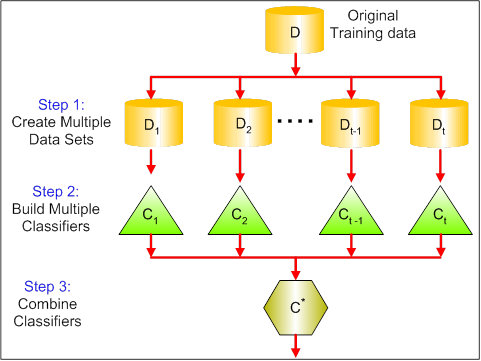
Impulso fornisce l'apprendimento sequenziale dei predittori. Il primo predittore viene appreso attraverso l'intero set di dati, mentre quanto segue viene appreso nel training set in base alle prestazioni del precedente.. Quella inizia classificando il set di dati originale e dando lo stesso peso a ciascuna osservazione. Se le classi sono previste in modo errato utilizzando il primo studente, allora viene dato maggior peso all'osservazione classificata mancante. Essendo una procedura iterativa, continua ad aggiungere studenti classificatori fino a quando non viene raggiunto un limite al numero di modelli o precisione. L'impulso ha mostrato una migliore accuratezza predittiva rispetto all'insaccamento, ma tende anche a sovrastimare i dati di allenamento. 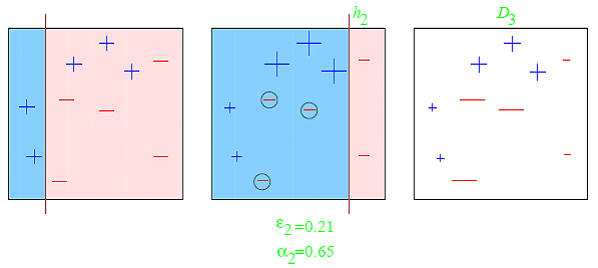
L'esempio più comune di booster è AdaBoost e Gradient Boosting. Puoi anche controllare questi post per ulteriori informazioni su come potenziare gli algoritmi.
Impilati funziona in due fasi. Primo, usiamo più classificatori di base per prevedere la classe. Al secondo posto, un nuovo studente viene utilizzato per combinare le proprie previsioni al fine di ridurre l'errore di generalizzazione. 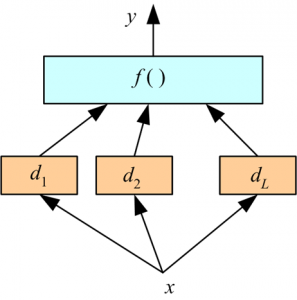
3. Possiamo assemblare più modelli dello stesso algoritmo ML??
sì, possiamo combinare più modelli degli stessi algoritmi ML, ma combinare più previsioni generate da diversi algoritmi regolarmente ti darebbe previsioni migliori. È dovuto alla diversificazione o alla natura indipendente rispetto l'uno all'altro. Come esempio, le previsioni di una foresta casuale, un KNN e un Naive Bayes possono essere combinati per creare un set finale di previsioni più robusto rispetto alla combinazione di tre modelli di foreste casuali. La chiave per creare un insieme potente è la diversità dei modelli. Un set con due tecniche che sono molto equivalenti in natura avrà prestazioni scadenti rispetto a un set di modelli più diversificato..
Esempio: Diciamo che abbiamo tre modelli (UN, Per C). UN, B e C hanno una precisione di previsione di 85%, 80% e 55% rispettivamente. Ma A e B risultano essere altamente correlati quando C è scarsamente correlato con A e B. Dovremmo combinare A e B? No, Non dovremmo, perché questi modelli sono altamente correlati. Perché, non combineremo questi due, poiché questo set non aiuta a ridurre eventuali errori di generalizzazione. Preferirei combinare A e C o B e C.
4. Come possiamo identificare i pesi dei diversi modelli per il set??
Una delle sfide più comuni con la modellazione di insieme è trovare pesi ottimali per i modelli di insieme di base. Generalmente, assumiamo lo stesso peso per tutti i modelli e prendiamo la media delle previsioni. Ma, È questo il modo migliore per affrontare questa sfida??
Esistono diversi metodi per trovare il peso ottimale per combinare tutti gli studenti di base. Questi metodi forniscono una buona comprensione di come trovare il peso corretto. Prossimo, Elenco alcuni dei metodi:
- Trova la collinearità tra gli studenti di base e in base a questa tabella, quindi identificare i modelli base da assemblare. Successivamente, guarda il punteggio della convalida incrociata (rapporto punteggio) dei modelli base identificati per trovare il peso.
- Trova l'algoritmo per restituire il peso ottimale per gli studenti di base. Puede consultar el post Cómo hallar pesos óptimos de aprendices de conjunto usando una neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. para ver el método para hallar el peso óptimo.
- Possiamo anche risolvere lo stesso problema usando metodi come:
Puoi anche vedere la risposta vincente dei concorsi di data science / Kaggle per capire altri metodi per affrontare questa sfida.
5. Quali sono i vantaggi del modello ensemble?
Ci sono due vantaggi principali dei modelli Ensemble:
- Migliore previsione
- Modello più stabile
L'opinione aggregata di vari modelli è meno rumorosa di quella di altri modelli. In finanza, chiamata “Diversificazione”: una cartera mixta de muchas acciones será mucho menos variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... que una sola de las acciones. Questo è anche il motivo per cui i tuoi modelli saranno migliori con set di modelli piuttosto che con modelli individuali.. Una delle precauzioni con i modelli ensemble è che si adattano troppo strettamente., aún cuando el ensacado se encarga de ello en gran misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.....
Nota finale
In questo post, abbiamo analizzato il 5 Domande frequenti sui modelli Ensemble. Rispondendo a queste domande, abbiamo discusso sui "Modelli d'insieme", "Metodi d'insieme", "Perché dovremmo assemblare più modelli?", "Metodi per identificare il peso ottimale per il set" e per finire "Vantaggi". Ti consiglio di guardare il 5 migliori soluzioni di quiz sulla scienza dei dati e vedere i loro approcci congiunti per una migliore comprensione e molta pratica. Ti aiuterà a capire cosa funziona e cosa no.
Questo post ti è stato utile?? Hai provato qualcos'altro per trovare pesi ottimali o identificare lo studente di base appropriato?? Sarò felice di sentirti nella sezione commenti qui sotto..





