Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
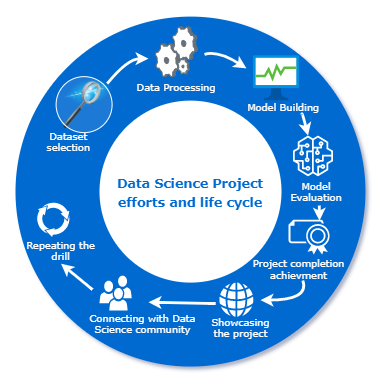
Passaggi per il tuo primo progetto di data science
In questo articolo, Diamo un'occhiata ad alcuni suggerimenti che puoi utilizzare per iniziare i tuoi progetti di data science personali..
1. Scegli un set di dati
Se stai affrontando il progetto di data science per la prima volta, scegli un dataset di tuo interesse. Può essere correlato allo sport, film o musica, tutto ciò che ti interessa. I siti web più comuni per ottenere i dati sono:
Per chi ha già realizzato uno o due progetti, da un'estremità all'altra da soli, seguendo le linee guida di cui sopra, può puntare all'analisi di un set di dati complesso da un particolare dominio, ad esempio la vendita al dettaglio, finanza o sanità per avere un'idea in tempo reale dei progetti.
per iniziare, aveva selezionato un set di dati di assicurazione sanitaria per praticare l'analisi predittiva. Ho tolto il set di dati dal sito web di Kaggle
! pip install -q kaggle
#from google.colab import files
#files.upload()
! mkdir ~/.kaggle ! cp kaggle.json ~/.kaggle/ ! chmod 600 ~/.kaggle/kaggle.json #! download di set di dati kaggle -d mirichoi0218/insurance #! unzip insurance.zip -d assicurazione sanitaria
! download di set di dati kaggle -d mirichoi0218/insurance ! unzip insurance.zip -d assicurazione sanitaria
2. Scegli un IDE
Seleziona un IDE con cui ti senti più a tuo agio. Se stai usando Python come linguaggio, Ecco alcuni esempi
- – È un IDE progettato per scrivere codici Python. Fornisce varie funzioni produttive come le cure di routine, completamento del codice intelligente, controllo degli errori e correzione del codice. Facilita la manutenzione del progetto fornendo l'integrazione con le funzioni di controllo della versione, supporta lo sviluppo web e la scienza dei dati.
- Taccuino Jupyter – È un'applicazione web open source che consente di creare e condividere documenti contenenti codice live, equazioni e visualizzazione. Aiuta a semplificare il lavoro e facilitare le collaborazioni
- Google Colab – Consente agli utenti di scrivere ed eseguire codice Python. È molto adatto per progetti di data science e machine learning, poiché offre risorse computazionali gratuitamente. Puoi eseguire algoritmi di apprendimento automatico pesanti qui con facilità senza doversi preoccupare dell'infrastruttura o dei costi.
- File di testo semplice con estensione .py: sebbene le opzioni di cui sopra siano disponibili e facili da usare, se ti senti più a tuo agio usando il blocco note per scrivere il tuo codice, puoi usarlo e salvare il tuo file con l'estensione .py. Quindi puoi eseguire lo stesso usando una riga di comando con una sintassi come "python <> .pi. Questo eseguirà il tuo programma, ma per i lavori di data science, questa potrebbe non essere l'opzione migliore, poiché non puoi vedere l'output del codice o le visualizzazioni al volo.
Ho selezionato Google Colab come ambiente di lavoro.
3. Elenca chiaramente le attività
Fai un elenco delle attività che vuoi fare nel set di dati per avere un percorso chiaro prima di iniziare. Le attività comuni che svolgiamo nei progetti di data science sono l'acquisizione di dati, pulizia dei dati, trasformazione dei dati, analisi esplorativa dei dati, costruzione di modelli, valutazione del modello e implementazione del modello. Ecco un breve su tutti questi passaggi.
- Ingestione di dati – È un processo di lettura dei dati in un frame di dati.
###Il pacchetto Panda semplifica la lettura di un file in un dataframe #Importing the libraries import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from matplotlib.cbook import boxplot_stats import statsmodels.api as sm from sklearn.model_selection import train_test_split,GridSearchCV, cross_val_score, cross_val_predict from statsmodels.stats.outliers_influence import variance_inflation_factor from sklearn.tree import DecisionTreeRegressor from sklearn import ensemble import numpy as np import pickle #Reading and summarizing the data health_ins_df = pd.read_csv("assicurazione sanitaria/assicurazione.csv") health_ins_df.columns health_ins_df.shape health_ins_df.describe()
- Pulizia dei dati – Es el proceso de identificar y eliminar las anomalías en el conjunto de datos.
- Trasformazione dei dati – Implica la modifica del tipo di dati delle colonne, creare colonne derivate o rimuovere dati duplicati, per dirne alcuni.
- Analisi esplorativa dei dati – Esegui analisi univariate e multivariate su set di dati per trovare informazioni e modelli nascosti in essi.
Mi sono dedicato alla pulizia dei dati e all'analisi esplorativa dei dati di variabili numeriche e categoriali in giorni separati per concentrarmi sui dettagli..
#Visualizzazione della colonna dell'età con un istogramma
Fig,assi=plt.sottotrame(1,2,figsize=(10,5)) sns.histplot( health_ins_df['età'] , colore="cielo blu",ax=assi[0]) sns.histplot( health_ins_df['mi'] , colore="oliva",ax=assi[1]) plt.mostra()
#Visualizing age column with a boxplot
fig,assi=plt.sottotrame(1,2,figsize=(10,5))
sns.boxplot(x = 'età', dati = health_ins_df, ax=assi[0])
sns.boxplot(x = 'bmi', dati = health_ins_df, ax=assi[1])
plt.mostra()
#Finding the outlier values in the bmi column
outlier_list = boxplot_stats(health_ins_df.bmi).pop(0)['volantini'].elencare()
Stampa(outlier_list)
#Finding the number of rows containing outliers
outlier_bmi_rows = health_ins_df[health_ins_df.bmi.isin(outlier_list)].forma[0]
Stampa("Numero di righe che contattano valori anomali in bmi : ", outlier_bmi_rows)
#Percentage of rows which are outliers
percent_bmi_outlier = (outlier_bmi_rows/health_ins_df.shape[0])*100
Stampa("Percentuale di valori anomali nelle colonne BMI : ", percent_bmi_outlier)
#Converting age into age brackets print("Valore minimo per età : ", health_ins_df['età'].min(),"nValore massimo per età : ", health_ins_df['età'].max()) #Età tra 18 a 40 years will fall under young #Age between 41 a 58 years will fall under mid-age #Age above 58 years will fall under old age health_ins_df.loc[(health_ins_df['età'] >=18) & (health_ins_df['età'] <= 40), 'age_group'] = 'young' health_ins_df.loc[(health_ins_df['età'] >= 41) & (health_ins_df['età'] <= 58), 'age_group'] = 'mid-age' health_ins_df.loc[health_ins_df['età'] > 58, 'age_group'] = 'old' fig,assi=plt.sottotrame(1,5,figsize=(20,8)) sns.countplot(x = 'sesso', dati = health_ins_df_clean, tavolozza="magma",ax=assi[0]) sns.countplot(x = 'bambini', dati = health_ins_df_clean, tavolozza="magma",ax=assi[1]) sns.countplot(x = 'fumatore', dati = health_ins_df_clean, tavolozza="magma",ax=assi[2]) sns.countplot(x = 'regione', dati = health_ins_df_clean, tavolozza="magma",ax=assi[3]) sns.countplot(x = 'age_group', dati = health_ins_df_clean, tavolozza="magma",ax=assi[4])
heatmap = sns.heatmap(health_ins_df_clean.corr(), vmin=-1, vmax=1, annot=Vero) sns.relplot(x="bmi", y ="Spese",tonalità="sesso", stile = "sesso", data=health_ins_df_clean); sns.boxplot(x="fumatore", y ="Spese", data=health_ins_df_clean)
- Costruzione del modello – Pruebe y pruebe todos los modelos posibles en el conjunto de datos antes de elegir el correcto según las limitaciones comerciales / técnicas. Durante esta fase, también puede probar algunas técnicas de embolsado o refuerzo.
Primero desarrollé un modelo base, antes de probar cualquier modelo avanzado en el conjunto de datos
#Data Pre-processing
#Converting categorical values into dummies using one-hot encoding technique
health_ins_df_processed = pd.get_dummies(health_ins_df_clean, colonne=['sesso','figli','fumatore',«regione»,'age_group'], prefisso=['sesso','figli','fumatore',«regione»,'age_group'])
health_ins_df_processed.drop(['età'],asse = 1, posto = vero)
#Building linear regression model X = health_ins_df_processed.loc[:, health_ins_df_processed.columns != 'spese'] y = health_ins_df_processed[«spese»] X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size=0,33) X = sm.add_constant(X) # adding a constant model = sm.OLS(e, X).in forma() forecasts = model.predict(X) print_model = model.summary() Stampa(print_model)
#Final model after eliminating variable with least significance and high vif X = health_ins_df_processed[['mi','children_0', 'smoker_yes', 'region_southeast', 'region_southwest', 'age_group_old', 'age_group_young']] y = health_ins_df_processed[«spese»] X_treno, X_test, y_train, y_test = train_test_split(X, e, test_size=0,33) X = sm.add_constant(X) # adding a constant model = sm.OLS(e, X).in forma() forecasts = model.predict(X) print_model = model.summary() Stampa(print_model)
- Evaluación del modelo – En esta fase, testiamo se il nostro modello è abbastanza buono per ottenere un risultato atteso. Misuriamo la precisione, specificità, sensibilità o R-quadrato regolato in base al modello che abbiamo usato
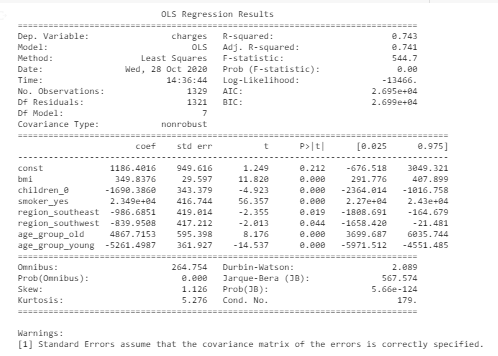
Questa è la metrica di valutazione finale del modello base che mostra a 74% precisione e 7 variabili significative (valore p <valore di significatività)
4. Completa le attività una per una
In questa fase, dovresti avere un'idea di quali attività fare nel tuo progetto. Puoi prenderli uno per uno. Non necessariamente, devi completare tutto in un giorno. Potrebbe volerci fino a 1 giorno di tempo per decidere su quale set di dati vuoi lavorare e in quale ambiente ti senti a tuo agio.
Può dedicare la giornata 2 comprendere i dati ed eseguire attività di pulizia dei dati. Nello stesso modo, puoi mirare a completare il tuo progetto in un arco di 7-8 giorni.
Ho realizzato questo progetto in un arco di tempo 4 giorni. Ho pianificato di testare alcuni modelli più avanzati per aumentare le prestazioni predittive
5. Prepara un riassunto
Farò un breve riassunto dopo che questo progetto sarà completato.
6. Condividilo su piattaforme open source
Scegli una piattaforma open source su cui pubblicare il brief o i codici del progetto in modo da ottenere visibilità nella comunità della scienza dei dati e connetterti con altri appassionati. GitHub è più comunemente usato in questi giorni. Ci sono pochi siti web come Kaggle, Google Colab offrendo kernel in linea in modo da poter scrivere codice ed eseguire senza doversi preoccupare dell'infrastruttura. Puoi anche approfittare di queste piattaforme.
Il codice sorgente è disponibile in my GitHub fattura
I vantaggi di assumere progetti per fasi
1. Non c'è nessuna pressione per completare il progetto tutto in un giorno.
2. Puoi concentrarti solo su un'attività specifica in un giorno e completarla in modo efficiente.
3. Ti terrà incollato ai compiti fino al termine
4. È possibile fare riferimento al riepilogo del progetto in futuro durante la preparazione per i colloqui o durante lo svolgimento di progetti simili..
5. Puoi sfruttare questo progetto per entrare in contatto con altri appassionati di data science e condividere idee creative..
Ho imparato che dobbiamo seguire un approccio disciplinato all'apprendimento e investire il nostro tempo facendo progetti. Impariamo tutti di più, fare le cose in modo pratico. Come ultima opzione, è il duro lavoro e la perseveranza che ti condurranno lungo il sentiero che hai sempre sognato di pavimentare.





