introduzione
Sono un grande fan di R, non è un segreto. Mi sono fidato di lui da quando ho imparato le statistiche al college. Infatti, R è ancora la mia lingua preferita per i progetti di machine learning.
Tre cose mi hanno attratto principalmente di R:
- Sintassi facile da capire e da usare
- Lo straordinario strumento RStudio
- Pacchetti R!
R offre un gran numero di pacchetti per eseguire attività di apprendimento automatico, incluso 'dplyr’ per la manipolazione dei dati, 'ggplot2'’ per la visualizzazione dei dati, 'caret’ per la creazione di modelli ML, eccetera.

Esistono anche pacchetti R per funzioni specifiche, che includono il punteggio del rischio di credito, estrazione dei dati del sito web, econometria, eccetera. C'è un motivo per cui R è amata dagli statistici di tutto il mondo: il gran numero di pacchetti R disponibili rende la vita molto più semplice.
In questo articolo, Mostrerò otto pacchetti R che sono passati inosservati tra i data scientist, ma che sono incredibilmente utili per eseguire specifici compiti di machine learning. per iniziare, Ho incluso un esempio insieme al codice di ogni confezione.
crema, Il suo amore per R sta per subire un'altra rivoluzione!!
I pacchetti R che tratteremo in questo articolo
Ho ampiamente diviso questi pacchetti R in tre categorie:
- Visualizzazione dati
- Apprendimento automatico
- Altri vari pacchetti R
- bono: Altri pacchetti R!
Visualizzazione dati

R è uno strumento straordinario per visualizzare i dati. La facilità con cui possiamo generare tutti i tipi di grafica con solo una o due righe di codice? Davvero un risparmio di tempo.
R offre innumerevoli modi per visualizzare i tuoi dati. Anche quando uso Python per un determinato compito, Torno in R per esplorare e visualizzare i miei dati. Sono sicuro che la maggior parte degli utenti di R si sente allo stesso modo!!
Diamo un'occhiata ad alcuni pacchetti R fantastici ma meno conosciuti per eseguire analisi esplorative dei dati.
Questo è il mio pacchetto di riferimento per l'analisi esplorativa dei dati. Dal tracciamento della struttura dei dati ai grafici QQ e persino alla creazione di report per il tuo set di dati, questo pacchetto fa tutto.
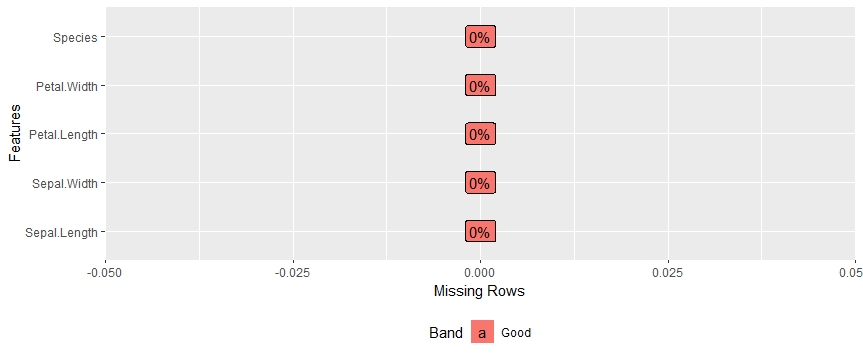
Vediamo cosa può fare DataExplorer con un esempio. Si prega di notare che abbiamo archiviato i nostri dati nel dati variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi..... Ora, vogliamo scoprire la percentuale di valori mancanti in ogni caratteristica presente. Questo è estremamente utile quando si lavora con enormi set di dati e il calcolo della somma dei valori mancanti può richiedere molto tempo..
Puoi installare DataExplorer usando il seguente codice:
install.packages("DataExplorer")
Ora vediamo cosa può fare DataExplorer per noi:
biblioteca(DataExplorer) dati(iris) trama_mancante(iris)
Otteniamo un grafico davvero intuitivo per i valori mancanti:
Uno dei miei aspetti preferiti di DataExplorer è il report completo che possiamo generare utilizzando solo una riga di codice:
create_report(iris)
Di seguito sono riportati i diversi tipi di fattori che otteniamo in questo rapporto:

Puoi accedere al rapporto completo tramite questo link. Un pacchetto MOLTO utile.
Che ne dici di un "plug-in trascina e rilascia"’ per generare grafici in R? Giusto – Schivare è un pacchetto che ti permette di continuare a creare grafici senza doverli codificare.
![]()
Esquisse è basato sul pacchetto ggplot2. Ciò significa che puoi esplorare i tuoi dati in modo interattivo nell'ambiente di scrematura generando grafici ggplot2..
Usa il seguente codice per installare e caricare Schivare sulla tua macchina:
# From CRAN
install.packages("esquisse")
#Load the package in R
library(esquisse)
esquisse::esquisser() #helps in launching the add-inPuoi anche avviare il plug-in esquisse tramite il menu RStudio. L'interfaccia utente di esquisse si presenta così:
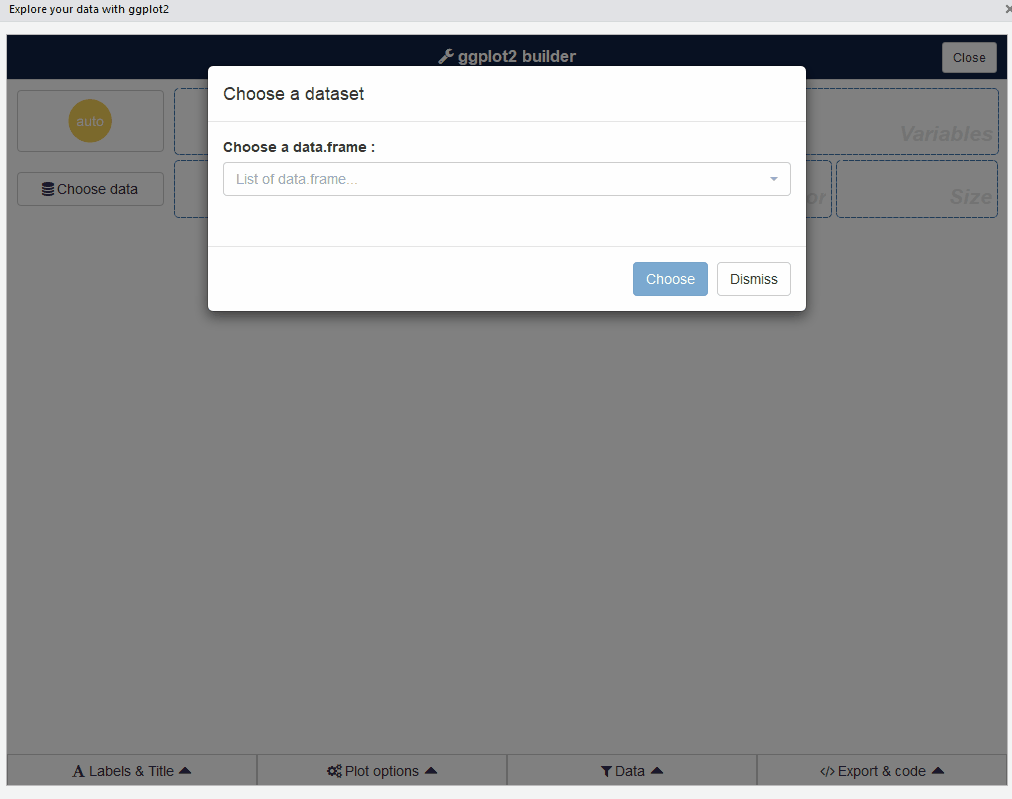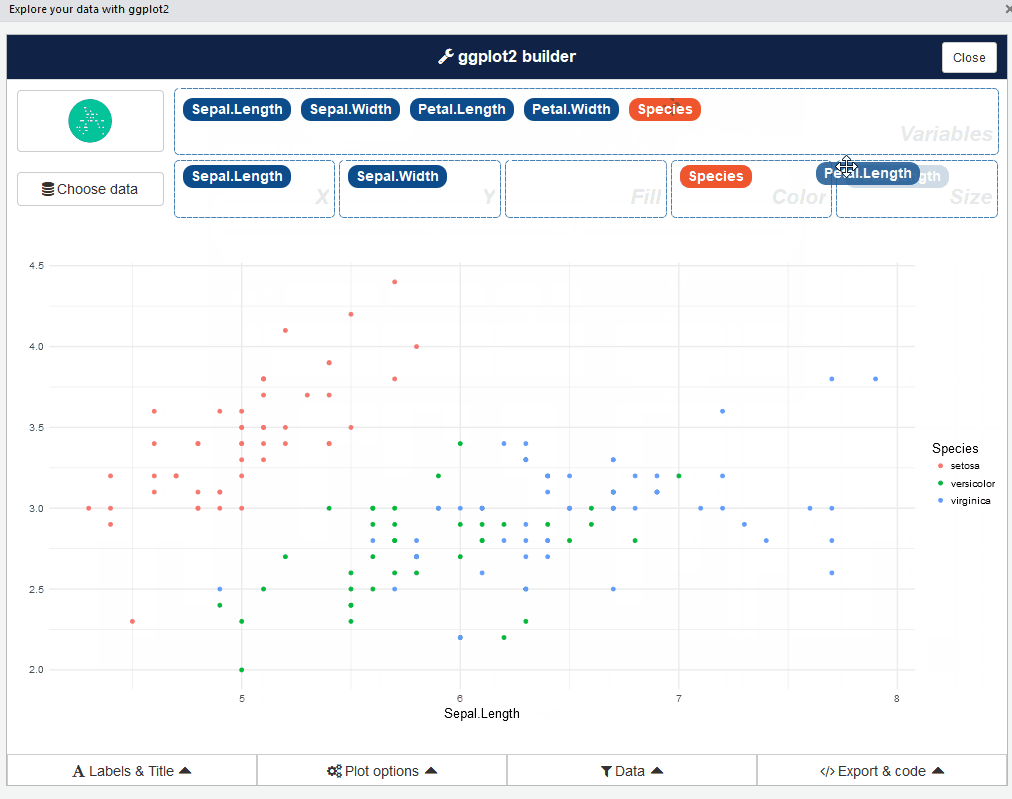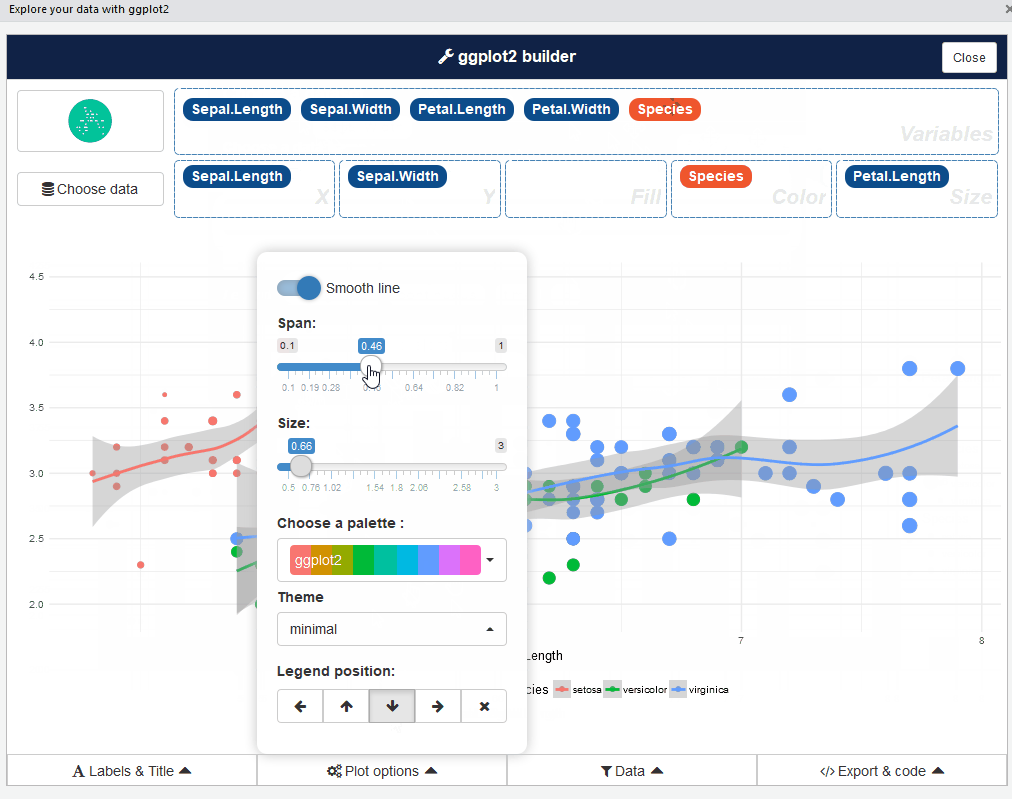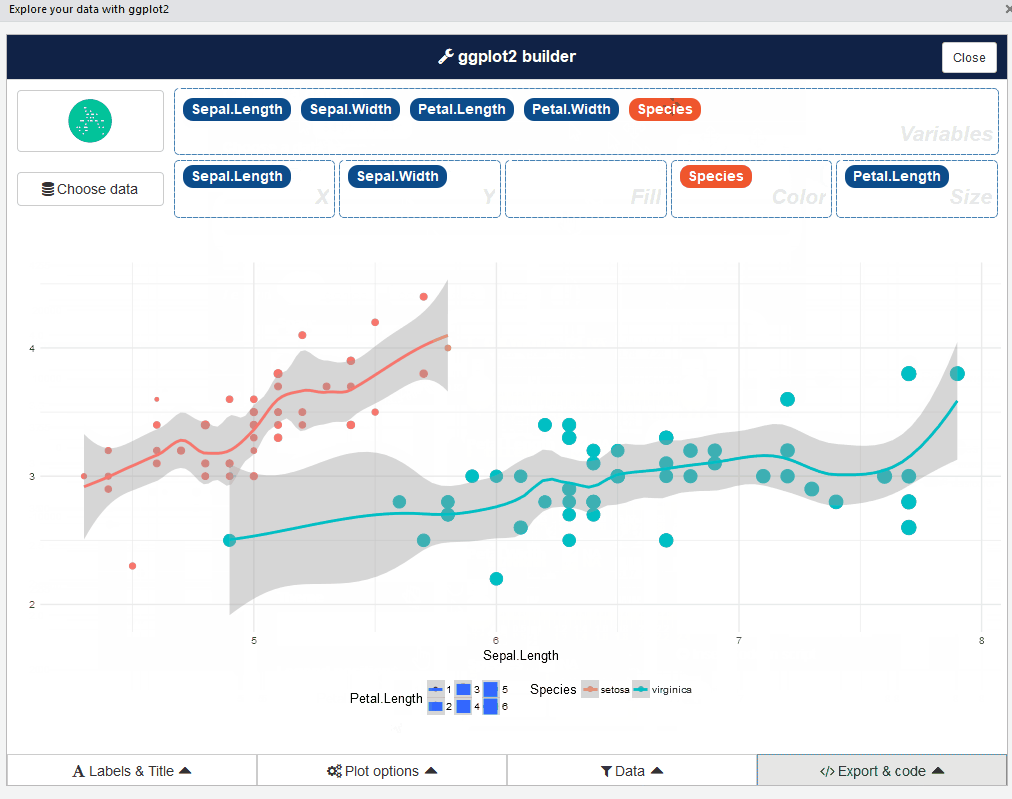
Abbastanza buono, verità? Vai avanti e gioca con diversi tipi di trame: è un'esperienza che apre gli occhi.
Apprendimento automatico

Ah, costruire modelli di machine learning in R. Il Santo Graal a cui ci impegniamo i data scientist quando intraprendiamo nuovi progetti di machine learning. Potresti aver usato il "pacchetto caret"’ costruire modelli prima.
Ora, lascia che ti presenti alcuni pacchetti R che potrebbero cambiare il modo in cui ti avvicini al processo di creazione del modello.
Uno dei motivi principali per cui Python ha superato R è stato grazie alle sue librerie incentrate sull'apprendimento automatico (come scikit-impara). Per molto tempo, A R mancava questa capacità. Certo che potresti usare diversi pacchetti per eseguire diverse attività AA, ma non c'era un singolo pacchetto che potesse fare tutto. Abbiamo dovuto chiamare tre diverse librerie per costruire tre modelli diversi.
Non ideale.
E poi è arrivato il pacchetto MLR.. È un pacchetto straordinario che ci consente di eseguire tutti i tipi di attività di apprendimento automatico.. MLR include tutti i popolari algoritmi di machine learning che utilizziamo nei nostri progetti.
![]()
Consiglio vivamente di leggere il seguente articolo per approfondire MLR:
Vediamo come installare MLR e creare un modello di foresta casuale sul set di dati iris:
install.packages("Mlr")
biblioteca(Mlr)
# Load the dataset
data(iris)
# create task
task = makeClassifTask(id = "iris", iris, target = "Specie")
# create learner
learner = makeLearner("classif.randomForest")
# build model and evaluate
holdout(Studente, compito)
# measure accuracy
holdout(Studente, compito, misure = acc)
Produzione:
Resample Result Task: iris Learner: classif.randomForest Aggr perf: acc.test.mean=0,9200000 # 92% precisione - Non male! Tempo di esecuzione: 0.0239332
Un problema comune con le diverse funzioni disponibili in R (che fanno lo stesso) è che possono avere interfacce e argomenti diversi. Prendiamo l'algoritmo della foresta casuale, ad esempio. Il codice da utilizzare nella finestra di dialogo foresta casuale e il pacchetto segno di regole di confronto Il pacchetto è diverso, verità?
Come MLR, pastinaca elimina il problema di fare riferimento a più pacchetti per un determinato algoritmo di machine learning. Imita con successo il pacchetto scikit-learn di Python in R.
Diamo un'occhiata al seguente semplice esempio per darti un'idea di come pastinaca funziona per un problema di regressione lineare:
install.packages("pastinaca")
biblioteca(pastinaca)
#Load the dataset
data(mtcars)
#Build a linear regression model
fit <- linear_reg("regressione") %>%
set_engine("lm") %>%
in forma(mpg~.,data=mtcars)
adattarsi #extracts valori del coefficiente
Produzione:
parsnip model object
Call:
statistiche::lm(formula = formula, dati = dati)
Coefficienti:
(Intercettare) cyl disp hp drat peso qsec
12.30337 -0.11144 0.01334 -0.02148 0.78711 -3.71530 0.82104
vs sono ingranaggio carb
0.31776 2.52023 0.65541 -0.19942
Ranger è uno dei miei pacchetti R preferiti. Uso regolarmente foreste casuali per creare modelli di base, soprattutto quando partecipo a hackathon di data science.
Ecco una domanda: Quante volte hai riscontrato un calcolo lento della foresta casuale per set di dati di grandi dimensioni in R? Succede troppo spesso sulla mia vecchia macchina.
Pacchetti come il cursore, le foreste casuali e rf impiegano molto tempo per calcolare i risultati. Il "pacchetto Ranger"’ accelera il nostro processo di modellazione per l'algoritmo della foresta casuale. Ti aiuta a creare rapidamente un gran numero di alberi in meno tempo.
Codificare un modello di foresta casuale usando Ranger:
install.packages("Guardia forestale")
#Load the Ranger package
require(Guardia forestale)
Guardia forestale(Specie ~ ., dati = iride,num.trees=100,mtry=3)
train.idx <- campione(ora(iris), 2/3 * ora(iris))
iris.train <- iris[train.idx, ]
iris.test <- iris[-train.idx, ]
rg.iris <- Guardia forestale(Specie ~ ., dati = iris.train)
pred.iris <- prevedere(rg.iris, dati = iris.test)
#Build a confusion matrix
table(iris.test$Specie, pred.iris$previsioni)
Produzione:
setosa versicolor virginica
setosa 16 0 0
Versicolor 0 16 2
virginica 0 0 16
Prestazioni piuttosto impressionanti. Dovresti testare Ranger su set di dati più complessi e vedere quanto più velocemente diventano i tuoi calcoli.
Esaurito durante l'esecuzione del modello di regressione lineare su diversi dati e il calcolo delle metriche di valutazione per ciascun modello? il fusa il pacchetto viene in tuo soccorso.
È inoltre possibile creare modelli lineari generalizzati (glm) per diversi dati e calcolare i valori P per ogni feature in forma di elenco. I vantaggi di fusa sono infiniti!
Vediamo un esempio per capirne le funzionalità. Costruiremo qui un modello di regressione lineare e sottoinsiememo i valori R-quadrati:
#Primo, read in the data mtcars data(mtcars) mtcars %>% diviso(.$Cil) %>% #selecting cylinder to create three sets of data using the cyl values map(~ lm(mpg ~ wt, dati = .)) %>% carta geografica(riepilogo) %>% map_dbl("r.quadrato")
Produzione
4 6 8 0.5086326 0.4645102 0.4229655
Quindi, Hai osservato?? In questo esempio vengono utilizzati fusa per risolvere un problema abbastanza realistico:
- Dividere un frame di dati in parti
- Monta un modello per ogni pezzo
- Calcola sommario
- Finalmente, estrai i valori R-quadrato
Ci fa risparmiare un sacco di tempo, verità? Invece di eseguire tre diversi modelli e tre comandi per creare un sottoinsieme del valore R al quadrato, usiamo solo una riga di codice.
Utilità: Altri fantastici pacchetti R
Diamo un'occhiata ad altri pacchetti che non rientrano necessariamente nell'ambito del "machine learning". Li ho trovati utili in termini di lavoro con R in generale.
L'analisi del sentiment è una delle applicazioni più popolari del machine learning. È una realtà inevitabile nel mondo digitale di oggi. E Twitter è un obiettivo primario per l'estrazione di tweet e la creazione di modelli per comprendere e prevedere il sentimento..
Ora, ci sono alcuni pacchetti R da estrarre / raschiare Tweet ed eseguire analisi del sentiment. Il "pacchetto rtweet"’ fa lo stesso. Quindi, In cosa differisce dagli altri pacchetti là fuori??
![]()
'ritwitta'’ ti aiuta anche a controllare le tendenze dei tweet di R. Degno di nota!
# installa rtweet da CRAN install.packages("ritwitta") # carica il pacchetto rtweet biblioteca(ritwitta)
Tutti gli utenti devono essere autorizzati a interagire con l'API di Twitter. Per ottenere l'autorizzazione, segui le istruzioni qui sotto:
1.Crea un'app per Twitter
2. Crea e salva il tuo token di accesso
Per una procedura dettagliata passo passo per ottenere l'autenticazione Twitter, segui questo link qui.
Puoi cercare tweet con determinati hashtag semplicemente tramite la riga di codice menzionata di seguito. Proviamo a cercare tutti i tweet con l'hashtag #avengers poiché Infinity War è pronto per il rilascio.
#1000 tweet con hashtag avengers tweet <- search_tweets( "#Vendicatori", n = 1000, include_rts = FALSO)
Puoi persino accedere agli ID utente delle persone che seguono una determinata pagina. Vediamo un esempio:
## ottieni gli ID utente degli account che seguono marvel marvel_flw <- get_followers("meraviglia", n = 20000)
Puoi fare molto di più con questo pacchetto. Fai un tentativo e non dimenticare di aggiornare la community se trovi qualcosa di eccitante.
Ti piace programmare in R e Python?, ma vuoi continuare con RStudio? Reticolare è la risposta! Il pacchetto risolve questo importante problema fornendo un'interfaccia Python in R. Puoi facilmente usare le principali librerie Python come numpy!, panda e matplotlib all'interno di R!
Puoi anche trasferire facilmente i tuoi progressi con i dati da Python a R e da R a Python con una sola riga di codice. Non è fantastico?? Guarda il blocco di codice qui sotto per vedere quanto è facile eseguire Python in R.
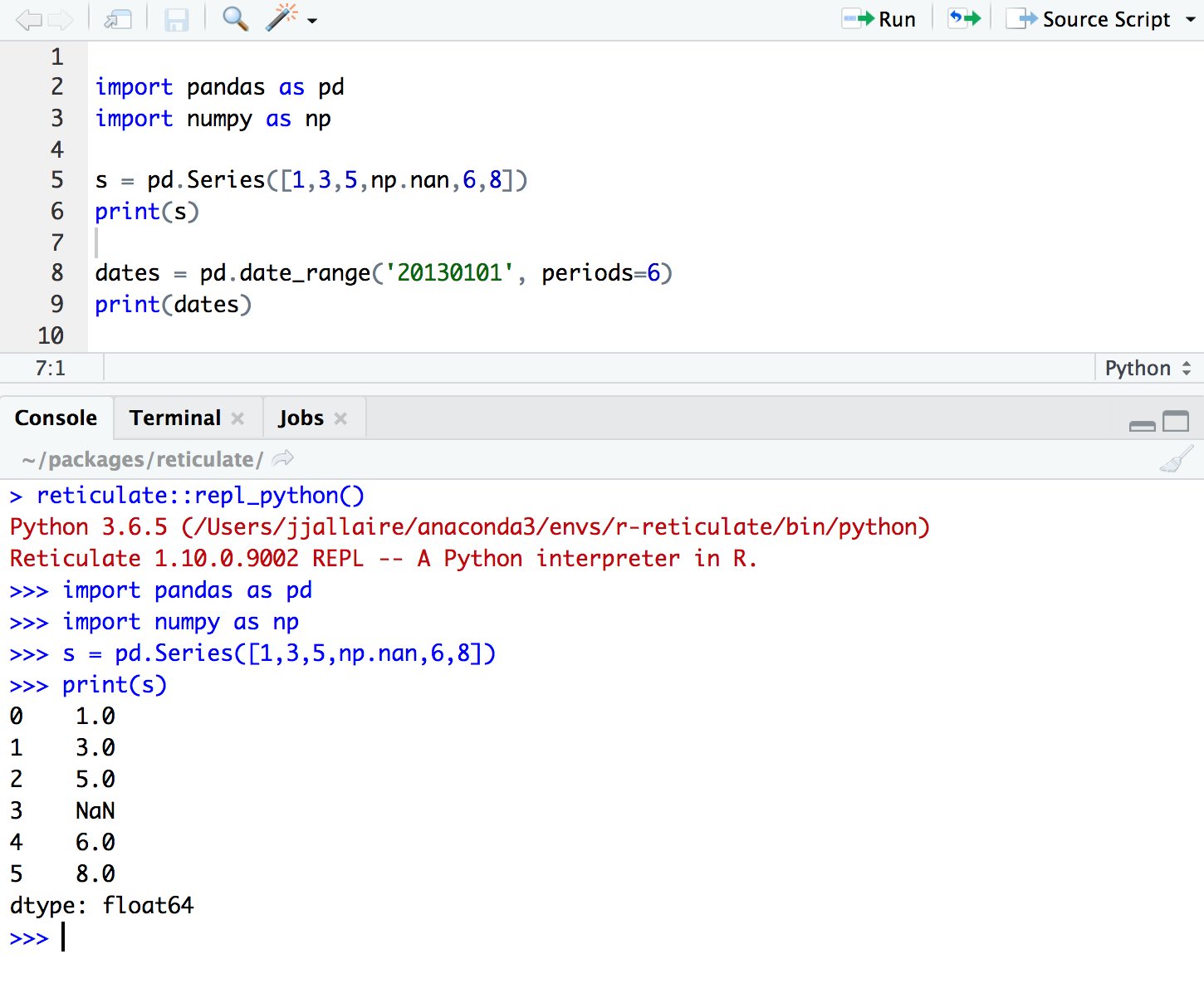
Prima di procedere con la posa diretta del reticolato in R, dovrai prima installare TensorFlow e Keras.
install.packages("flusso tensoriale")
install.packages("duro")
biblioteca(flusso tensoriale)
biblioteca(duro)
install_hard()
install.packages("reticolare")
biblioteca(reticolare)
E sei pronto per partire! Esegui i comandi che ho fornito sopra nello screenshot e testa i tuoi progetti di data science in modo simile.
PRIMA
Ecco altri due pacchetti di utilità R per tutti i tuoi nerd di programmazione!!
Aggiorna i tuoi pacchetti R individualmente?? Può essere un compito noioso, soprattutto quando ci sono più pacchetti in gioco.
"InstallR"’ ti permette di aggiornare R e tutti i suoi pacchetti usando un singolo comando! Invece di controllare l'ultima versione di ogni pacchetto, possiamo usare InstallR per aggiornare tutti i pacchetti contemporaneamente.
# installazione/caricamento del pacchetto:
Se(!richiedere(installatore)) {
install.packages("installatore"); richiedere(installatore)} #carico / installa+carica il programma di installazione
# usando il pacchetto:
aggiornaR() # questo avvierà il processo di aggiornamento della tua installazione di R.
# Verificherà le versioni più recenti, e se uno è disponibile, ti guiderà attraverso le decisioni che dovresti prendere
Quale pacchetto usi per installare le librerie da GitHub? La maggior parte di noi si fida del "pacchetto devtools"’ per molto tempo. Sembrava essere l'unico modo. Ma c'era un avvertimento: dovevamo ricordare il nome dello sviluppatore per installare un pacchetto:
Con il pacchetto 'githubinstall', Il nome dello sviluppatore non è più necessario.
install.packages("githubinstall")
#Install any GitHub package by supplying the name
githubinstall("NomePacchetto")
#githubinstall("AnomaliaRilevamento")
Note finali
Questo non è affatto un elenco esaustivo. Ci sono molti altri pacchetti R che hanno funzioni utili, ma la maggior parte li ha trascurati.
Conosci qualche pacchetto che mi sono perso in questo articolo? O hai usato uno dei precedenti per il tuo progetto?? Mi piacerebbe sentirti!! Connettiti con me nella sezione commenti qui sotto e parliamo di R!





