Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Un'anomalia è un'osservazione che si discosta significativamente da tutte le altre osservazioni. Un sistema di rilevamento delle anomalie è un sistema che rileva anomalie nei dati. Un'anomalia è anche chiamata outlier.
Esempio: Diciamo che una colonna di dati è composta dal reddito mensile dei cittadini e quella colonna contiene anche lo stipendio di Bill Gates. Quindi, Lo stipendio di Bill Gates è un valore anomalo in questi dati.
Algoritmi di rilevamento delle anomalie
In questo blog, diamo un'occhiata ai seguenti algoritmi di rilevamento delle anomalie.
Questi sono alcuni dei tanti algoritmi disponibili e non trattenetevi mai dall'esplorare altri algoritmi oltre a questi.
Importa le librerie richieste e scrivi le funzioni di utilità
# rilevamento dei valori anomali di Python !pip install pyod import warnings import numpy as np import pandas as pd from pyod.models.mad import MAD from pyod.models.knn import KNN from pyod.models.lof import LOF import matplotlib.pyplot as plt from sklearn.ensemble import IsolationForest # data for anomaly detection data_values = [['2021-05-1', 45000.0], ['2021-05-2', 70000.0], ['2021-05-3', 250000.0], ['2021-05-4', 70000.0], ['2021-05-5', 45000.0], ['2021-05-6', 55000.0], ['2021-05-7', 35000.0], ['2021-05-8', 60000.0], ['2021-05-9', 45000.0], ['2021-05-10', 25000.0], ['2021-05-11', 142936.0], ['2021-05-12', 138026.0], ['2021-05-13', 28347.0], ['2021-05-14', 40962.66], ['2021-05-15', 34543.0], ['2021-05-16', 40962.66], ['2021-05-17', 25207.0], ['2021-05-18', 37502.0], ['2021-05-19', 29589.0], ['2021-05-20', 78404.0], ['2021-05-21', 26593.0], ['2021-05-22', 123267.0], ['2021-05-23', 46880.0], ['2021-05-24', 65361.0], ['2021-05-25', 46042.0], ['2021-05-26', 48209.0], ['2021-05-27', 44461.0], ['2021-05-28', 90866.0], ['2021-05-29', 46886.0], ['2021-05-30', 33456.0], ['2021-05-31', 46251.0], ['2021-06-1', 29370.0], ['2021-06-2', 165620.0], ['2021-06-3', 20317.0]] data = pd.DataFrame(data_values , colonne=['Data', 'importo']) def fit_model(modello, dati, column='importo'): # fit the model and predict it df = data.copy() data_to_predict = dati[colonna].to_numpy().rimodellare(-1, 1) previsioni = model.fit_predict(data_to_predict) df['Pronostici'] = predictions return df def plot_anomalies(df, x='data', y='importo'): # le categorie avranno valori da 0 a n # per ogni valore in 0 to n it is mapped in colormap categories = df['Pronostici'].to_numpy() colormap = np.array(['G', 'R']) f = plt.figure(figsize=(12, 4)) f = plt.scatter(df[X], df[e], c=colormap[Categorie]) f = plt.xlabel(X) f = plt.ylabel(e) f = plt.xticks(rotazione=90) plt.mostra()
I dati di cui sopra sono costituiti da due colonne, vale a dire, data e importo, possiamo supporre che i dati contengano l'importo delle vendite di un'azienda di display per panifici.
Cosa fit_model la funzione?
- La funzione fit_model prende il modello e i dati come input, qui stiamo trovando anomalie nella colonna quantità.
- Successivamente, cambia la forma dei dati in dati unidimensionali e si adatta al modello fornito e prevede anomalie nei dati e li memorizza nella colonna delle previsioni del frame di dati fornito, e lo restituisce.
Intervallo interquartile
Percentili:
quartili:
-
11° quartile = percentile 25
-
2c quartile = percentile 50
-
3.1° quartile = percentile 75
Intervallo interquartile (IQR):
IQR = 3° quartile – 1è cuartil
Anomalie = [1quarto quartile – (1.5 * IQR)] oh [3terzo quartile + (1.5 * IQR)]
Le anomalie sono qui sotto [1quarto quartile – (1.5 * IQR)] e al di sopra [3terzo quartile + (1.5 * IQR)] questo valore.

def trova_anomalie(valore, soglia_inferiore, soglia_superiore):
se valore < lower_threshold o valore > soglia_superiore:
Restituzione 1
altro: Restituzione 0
def iqr_anomaly_detector(dati, column='importo', soglia=1,1):
df = data.copy()
quartili = dict(dati[colonna].Quantile([.25, .50, .75]))
quartile_3, quartile_1 = quartili[0.75], Quartili[0.25]
iqr = quartile_3 - quartile_1
lower_threshold = quartile_1 - (soglia * iqr)
upper_threshold = quartile_3 + (soglia * iqr)
Stampa(F"Soglia inferiore: {soglia_inferiore}, nPs threshold: {soglia_superiore}n")
df['Pronostici'] = dati[colonna].applicare(find_anomalies, args=(soglia_inferiore, soglia_superiore))
return df
iqr_df = iqr_anomaly_detector(dati)
trama_anomalie(iqr_df)
# produzione
# Soglia inferiore: -2944.050000000003,
# Soglia superiore: 106441.55
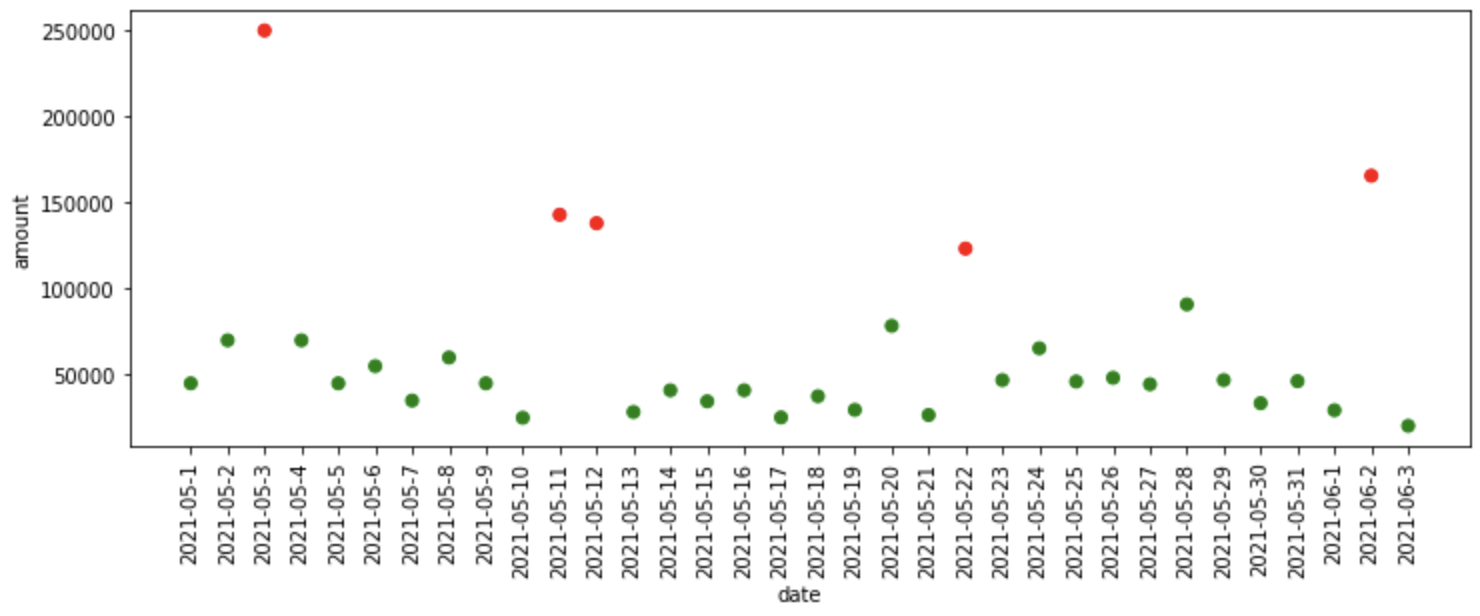
¿Qué sucedió en el código anterior?
- Primo, averigua el percentil 25 e 75, vale a dire, se encontraron el 1er y 3er cuartil.
- E più tardi, si trova l'intervallo interquartile, che è la differenza tra il terzo e il primo quartile.
- Successivamente, stiamo trovando la soglia superiore e inferiore al di sopra e al di sotto della quale si trovano le anomalie, rispettivamente.
- La suddetta funzione trova_anomalie trova le anomalie nei dati secondo le soglie previste.
- Finalmente, stiamo rintracciando le anomalie riscontrate.
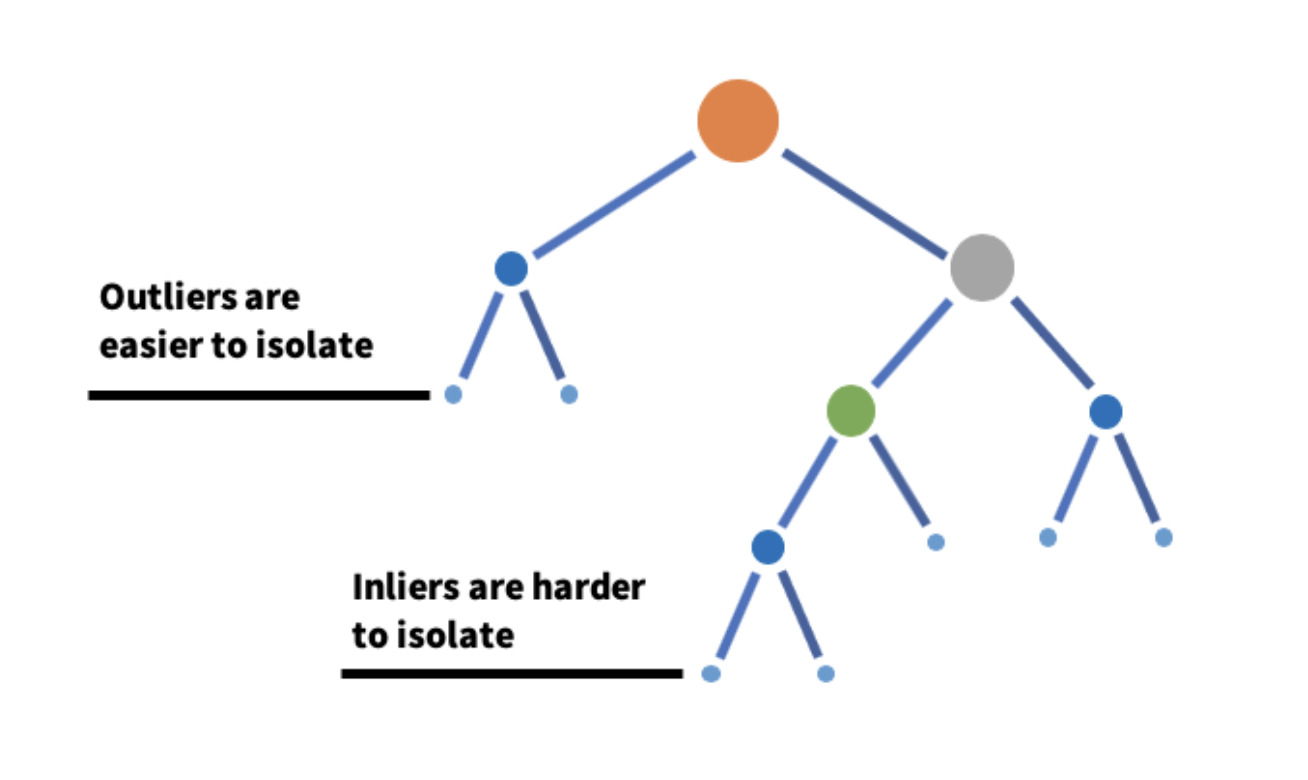
Isolamento foresta
Isolation Forest è un algoritmo che rileva le anomalie prendendo un sottoinsieme di dati e creando molti alberi di isolamento da esso..
-
L'idea centrale è che le anomalie sono molto più facili da isolare rispetto alle normali osservazioni e le anomalie esistono a profondità molto più piccole di un albero di isolamento.. Un albero di isolamento viene costruito selezionando casualmente una caratteristica e selezionando casualmente un valore di quella caratteristica. Si costruisce una foresta aggiungendo tutti gli alberi di isolamento.
iso_forest = IsolationForest(n_stimatori = 125) iso_df = fit_model(iso_forest, dati) iso_df['Pronostici'] = iso_df['Pronostici'].carta geografica(lambda x: 1 se x==-1 altrimenti 0) trama_anomalie(iso_df)
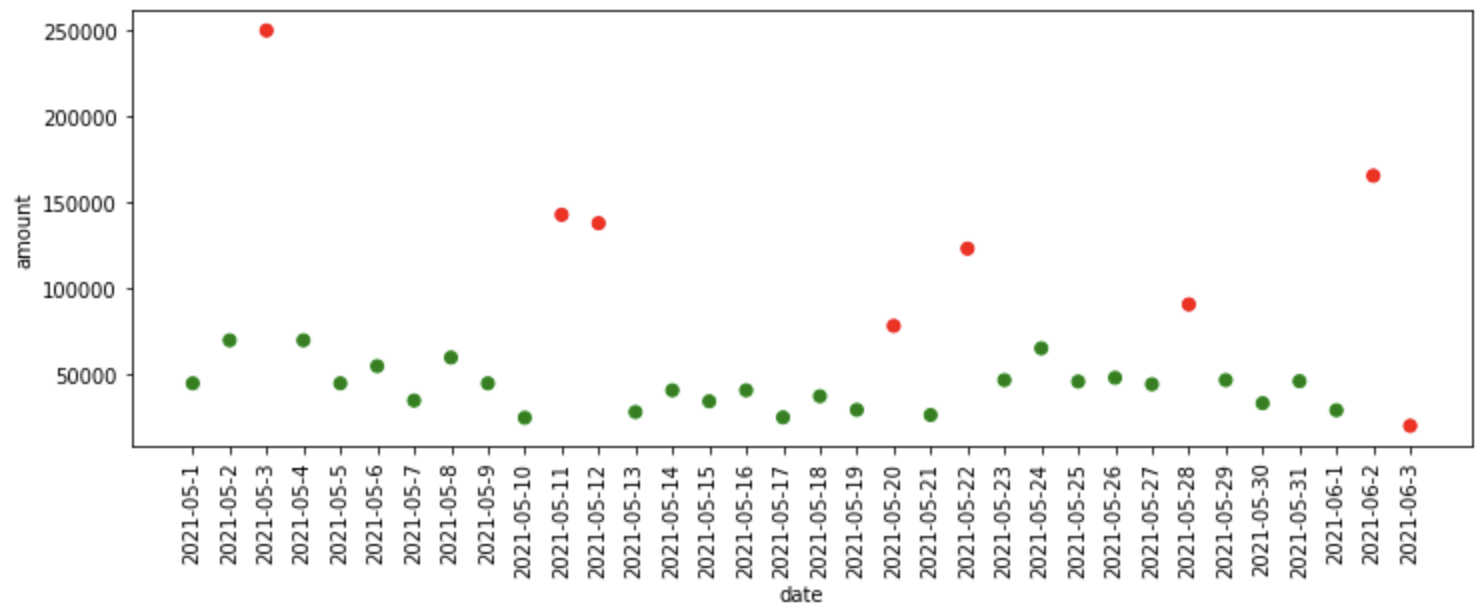
¿Qué sucedió en el código anterior?
- Primo, definiamo il modello Isolation Forest con 125 alberi di isolamento, poi passiamo il modello, i dati come input per la funzione fit_model, dove adatta il modello ai dati e ci fornisce previsioni.
- La foresta di isolamento assegna -1 a dati anomali e 1 ai dati normali, quindi per semplificare, convertiamo la previsione dei dati normali (1) un 0 e la previsione di dati anomali (-1) un 1.
- Finalmente, tracciamo le anomalie previste da Isolation Forest.
Deviazione assoluta mediana
La desviación absoluta media es la diferencia entre cada observación y la medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... de esas observaciones. Un'osservazione che si discosta maggiormente dal resto dell'osservazione è considerata un'anomalia..
Perché mediana invece di media??
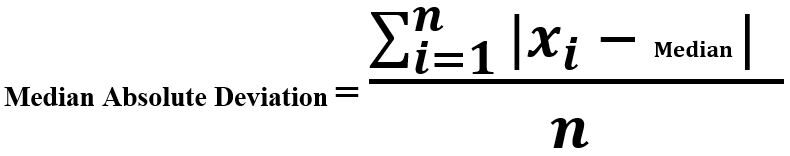
"""Deviazione assoluta mediana""" mad_model = MAD() mad_df = fit_model(mad_model, dati) trama_anomalie(mad_df)
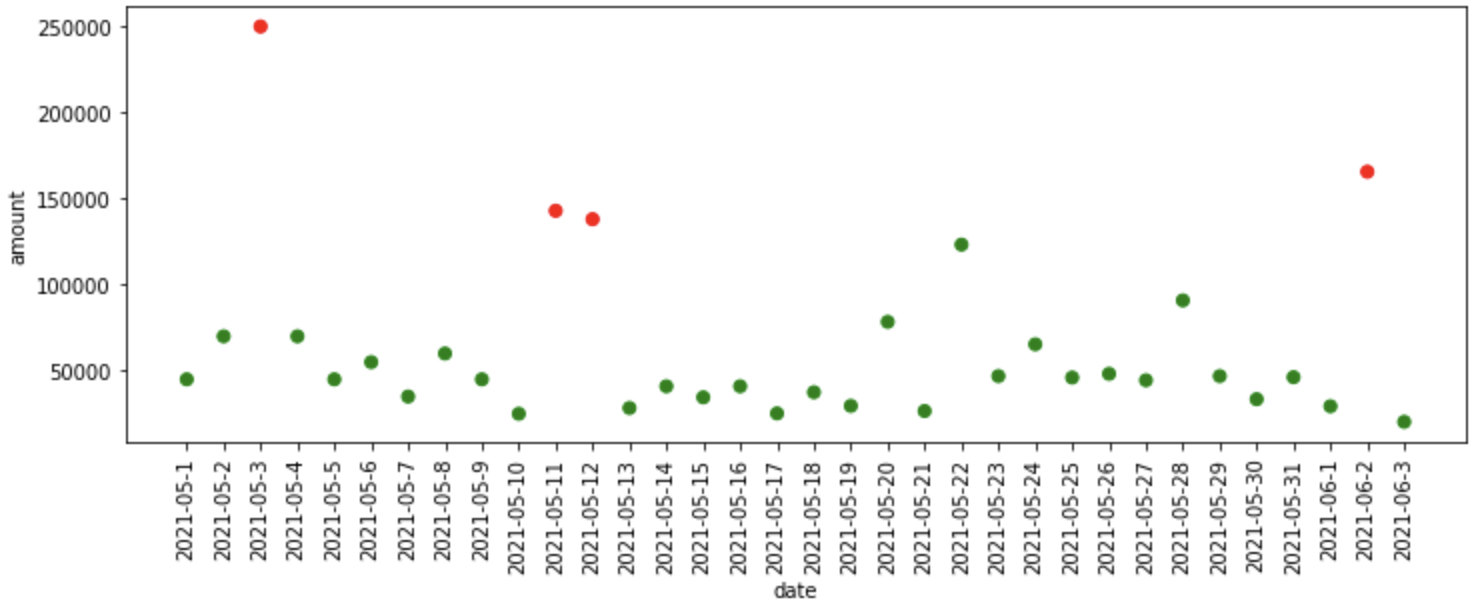
¿Qué sucedió en el código anterior?
- Primo, Definiamo il modello Median Absolute Deviation che è disponibile nella libreria pyod, poi passiamo il modello, i dati come input per la funzione fit_model, dove adatta il modello ai dati e ci fornisce previsioni.
- Finalmente, tracciamo le anomalie previste dal modello MAD.
Algoritmo dei vicini più vicini K
L'algoritmo K-Nearest Neighbor rileva le anomalie utilizzando le distanze K-Nearest Neighbor come punteggi di anomalia. L'idea è che se un'osservazione è molto lontana dalle altre osservazioni, allora quell'osservazione è considerata un'anomalia.
"""Rilevamento outlier basato su KNN""" knn_model = KNN() knn_df = fit_model(knn_model, dati) trama_anomalie(knn_df)
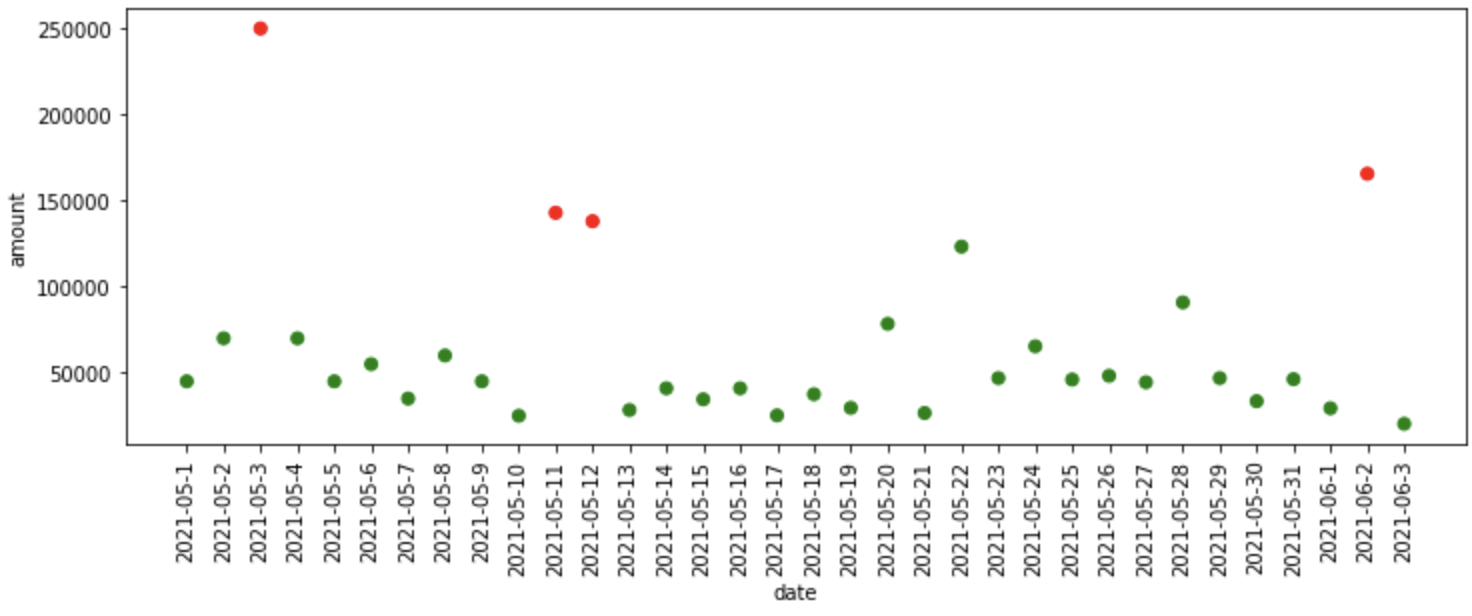
¿Qué sucedió en el código anterior?
- Primo, definiamo il modello del vicino più prossimo K che è disponibile nella libreria pyod, poi passiamo il modello, i dati come input per la funzione fit_model, dove adatta il modello ai dati e ci fornisce previsioni.
- Finalmente, tracciamo le anomalie previste dal modello KNN.
Ci sono molti modelli disponibili nella libreria PyOD come,
- CBLOF (fattore di outlier locale basato su cluster)
- LOF (fattore anomalo locale)
- HBOS (rilevamento outlier basato su istogramma)
- OCSVM (SVM di una classe)
Non astenersi mai dallo sperimentare con più algoritmi disponibili in PyOD.
Le implementazioni pratiche degli algoritmi di cui sopra sono implementate nel seguente quaderno
Riferimenti
[1] PyOD, Libreria Python per il rilevamento di valori atipici
Grazie!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





