Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione:
Come sappiamo tutti, L'intelligenza artificiale è ampiamente utilizzata intorno a noi: dalla lettura delle notizie sul tuo dispositivo mobile o dall'analisi di quei dati complessi sul tuo posto di lavoro, L'intelligenza artificiale ha migliorato la velocità, precisione ed efficacia dello sforzo umano. I progressi nell'intelligenza artificiale ci hanno aiutato a raggiungere cose che in precedenza pensavamo non fossero possibili. Anche avere a casa una pizza del tuo ristorante preferito è a portata di click, grazie ad AI.
In poche parole, intelligenza artificiale significa un computer o un programma per computer che imita l'intelligenza umana. Si ottiene imparando come si pensa, imparare, decide e lavora il cervello umano mentre risolve un problema. I risultati di questo studio vengono quindi utilizzati come base per lo sviluppo di sistemi e software intelligenti..
Ci sono 4 tipi di apprendimento:
● Apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in....
● Apprendimento non supervisionato.
● Apprendimento semi-supervisionato.
● Apprendimento rinforzato.
| Supervisionato | non supervisionato | Semi-sorvegliato | Rinforzati |
| L'apprendimento supervisionato è quando il modello viene addestrato su un set di dati etichettato. | Il Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso... es cuando el modelo se entrena en un conjunto de datos sin etiquetar, sta all'algoritmo trovare i modelli sottostanti nei dati. | Si colloca tra apprendimento supervisionato e non supervisionato, in questo, alcuni dati di apprendimento sono etichettati e altri no. | L'algoritmo valuta le sue prestazioni in base alle risposte di feedback e reagisce di conseguenza. |
Questo blog tratta l'apprendimento dell'IA supervisionato e non supervisionato, usando il set di dati Python e Iris.
Sommario:
- introduzione
- Set di dati dell'iride
- Apprendimento supervisionato
- Albero decisionale
- Regressione logistica
- Apprendimento non supervisionato
- Raggruppamento di K-calze
- Conclusione e riferimenti
Set di dati dell'iride:
Il set di dati contiene 3 lezioni con 50 istanze ciascuno e 150 istanze totali, dove ogni classe si riferisce ad un tipo di pianta di iris.
Classe: Iris Setosa, Iris Versicolor, Iris Virginica
Il formato dei dati: (lunghezza del sepalo, larghezza del sepalo, lunghezza del petalo, larghezza del petalo)

Entrenaremos nuestros modelos en función de estos parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... y los usaremos para predecir las clases de flores.
Capire i dati:
Scarica il set di dati Iris da https://www.kaggle.com/uciml/iris
importa numpy come np
importa panda come pd
importa matplotlib.pyplot come plt
iride = pd.read_csv("Iris.csv") #Iris.csv è ora un dataframe panda
Stampa(iris.testa()) #stampa prima 5 valori
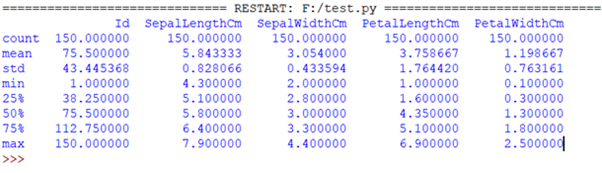
Stampa(iris.descrivi()) #stampa alcuni dettagli statistici di base come percentile,Significare, standard ecc. del frame di dati |

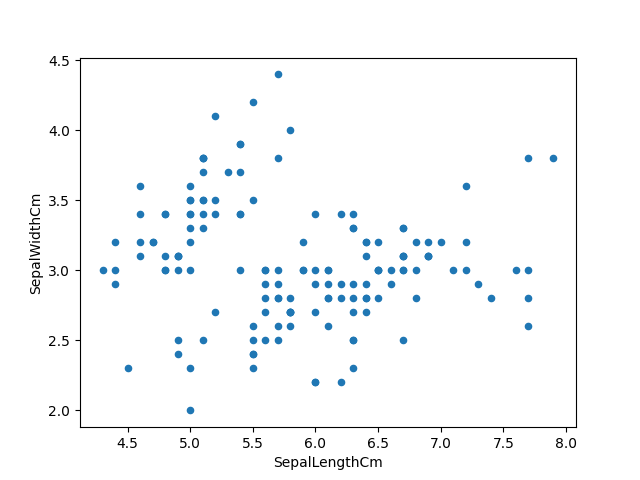
Visualizzazione dei dati utilizzando matplotlib:
iris.trama(gentile="disperdere", x="SepaloLunghezzaCm", y ="SepaloLarghezzaCm") plt.mostra() |
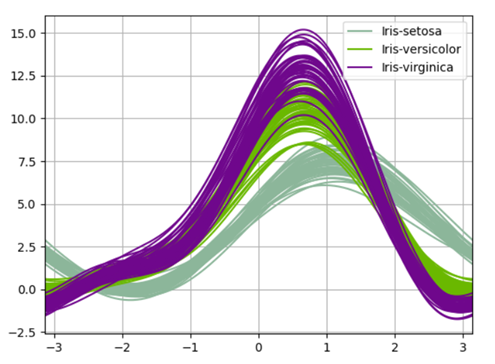
Visualizzazione dei dati utilizzando le curve di Andrew dai panda:
Le curve di Andrews hanno la forma funzionale:
F
x_4 senza (2T) + x_5 cos (2T) +…
Donde los coeficientes x corresponden a los valores de cada dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e... y t está espaciado linealmente entre -pi y + pi. Ogni riga del frame corrisponde a una singola curva.
da pandas.plotting import andrews_curves
andrews_curves(iris.goccia("ID", asse=1), "Specie")
plt.mostra()
|
Pre-elaborazione del set di dati:
Utilizzo di una libreria integrata chiamata 'train_test_split', che divide il nostro set di dati in una proporzione di 80:20. Il 80% se utilizará para addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., valutazione e selezione tra i nostri modelli e il 20% verrà conservato come set di dati di convalida.
da sklearn.model_selection import train_test_split x = iris.iloc[:, :-1].valori #ultima colonna valori esclusi y = iris.iloc[:, -1].valori #ultimo valore colonna da sklearn.model_selection import train_test_split x_treno,x_test,y_train,y_test = train_test_split(X,e,test_size=0.2,random_state=0) #Suddivisione del set di dati in Set di allenamento e Set di test |
Apprendimento supervisionato :
Gli algoritmi di apprendimento automatico supervisionati sono addestrati per trovare modelli utilizzando un set di dati. Il processo è semplice, prende ciò che è stato appreso in passato e poi lo applica a nuovi dati. L'apprendimento supervisionato utilizza esempi etichettati per prevedere modelli ed eventi futuri.
Ad esempio, quando insegniamo a un bambino che 2 + 2 = 4 oppure segnaliamo l'immagine di qualsiasi animale in modo che tu sappia il suo nome.
L'apprendimento supervisionato è a sua volta suddiviso in:
● Classificazione: La classificazione prevede le etichette delle classi categoriali, che sono discreti e disordinati. È un processo in due fasi, costituito da una fase di apprendimento e una fase di classificazione. Esistono vari algoritmi di classificazione come: “Classificatore albero decisionale”, “foresta casuale”, “Classificatore Naive Bayes”, eccetera.
● Regressione: La regressione è generalmente descritta come la determinazione di una relazione tra due o più variabili, come prevedere il lavoro di una persona in base ai dati di input X. Alcuni degli algoritmi di regressione sono: “Regressione logistica”, “Regressione ad anello”, “Regressione della cresta”, eccetera. .
Classificatore albero decisionale:
Il motivo generale per l'utilizzo di un albero decisionale è creare un modello di addestramento che possa essere utilizzato per prevedere la classe o il valore delle variabili di destinazione apprendendo le regole decisionali dedotte dai dati precedenti. (dati di allenamento).
Prova a risolvere il problema usando la rappresentazione ad albero. Ogni nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... interno del árbol corresponde a un atributo y cada nodo hoja corresponde a una etiqueta de clase.
Utilizzo dell'albero decisionale nel set di dati Iris:
da sklearn.tree import DecisionTreeClassifier da sklearn.metrics import precision_score classificatore = DecisionTreeClassifier() classificatore.fit(x_treno, y_train) #addestrare il classificatore y_pred = classificatore.predict(x_test) #fare previsioni Stampa(classificazione_report(y_test, y_pred)) #Riepilogo delle previsioni fatte dal classificatore Stampa(confusione_matrice(y_test, y_pred)) #per valutare la qualità dell'output Stampa('la precisione è',precision_score(y_pred,y_test)) #Punteggio di precisione
|
Precisione: accuratezza delle previsioni positive.
Recupero: frazione di positivi che sono stati correttamente identificati.
Punteggio F1: Quale percentuale di previsioni positive era corretta??
macro media – media non ponderata per etichetta
media ponderata: media della media ponderata del supporto per etichetta
Mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate.... para la matriz de confusión:
import seaborn come sns cm = confusione_matrice(y_test, y_pred) #Trasforma in df cm_df = pd.DataFrame(cm,indice = ['setosa','versicolor','vergine'], colonne = ['setosa','versicolor','vergine']) plt.figure(figsize=(5.5,4)) sns.heatmap(cm_df, annot=Vero) plt.ylabel("Vera etichetta")
plt.xlabel("Etichetta prevista")
plt.mostra() |
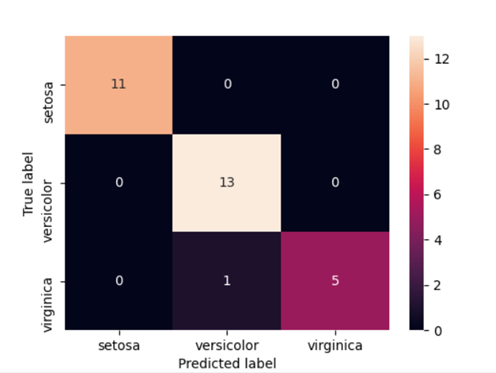
Un'idea che possiamo ottenere dalla matrice è che il modello era molto accurato quando classificava Setosa e Virginica (Vero positivo / Tutto = 1.0). tuttavia, La precisione di Versicolor era inferiore (13/14 = 0,928).
Apprendimento non supervisionato:
L'apprendimento non supervisionato viene utilizzato su dati senza etichette storiche. Il sistema non è soggetto a un insieme predeterminato di output, correlazioni tra input e output o a “risposta corretta”. L'algoritmo deve capire cosa sta vedendo da solo, poiché non ha alcuna memoria di waypoint. L'obiettivo è esplorare i dati e trovare un qualche tipo di pattern o strutture.
L'apprendimento non supervisionato può essere classificato in:
● Raggruppamento: Il clustering è il compito di dividere la popolazione o i punti dati in più gruppi, in modo che i punti dati di un gruppo siano omogenei tra loro rispetto a quelli di gruppi diversi. Esistono numerosi algoritmi di raggruppamento, alcuni di loro sono: “K significa algoritmi di clustering”, “cambiamento medio”, “raggruppamento gerarchico”, eccetera.
● Associazione: Una regla de asociación es un método de aprendizaje no supervisado que se utiliza para encontrar las relaciones entre variables en una gran Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti..... Determinare l'insieme di elementi che si verificano insieme nel set di dati.
Raggruppamento di K-calze:
L'obiettivo dell'algoritmo di clustering K-means è trovare cluster nei dati, con el número de grupos representado por la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... K. L'algoritmo funziona in modo iterativo per assegnare ciascun punto dati a uno dei gruppi K in base alle caratteristiche fornite.. .
I risultati dell'esecuzione di una media K su un set di dati sono:
● Centroide K: centroidi per ciascuno dei K gruppi identificati nel set di dati.
● Etichette per i dati di allenamento: set di dati completo etichettato per garantire che ogni punto dati sia mappato su uno dei cluster.
Utilizzo del clustering di mezzi K sul set di dati Iris:
da sklearn.datasets import load_iris da sklearn.cluster import KMeans iris_data=load_iris() #caricamento del set di dati dell'iride da sklearn.datasets iris_df = pd.DataFrame(iris_data.data, colonne = iris_data.feature_names) #creazione di dataframe kmsignifica = KMezzi(n_clusters=3,init="k-significa++", max_iter = 100, n_init = 10, stato_casuale = 0) #Applicazione del classificatore Kmeans y_kmeans = kmeans.fit_predict(X) Stampa(kmeans.cluster_centers_) #display cluster centri plt.scatter(X[y_ksignifica == 0, 0], X[y_ksignifica == 0, 1],s = 100, c="rosso", etichetta="Iris-setosa") plt.scatter(X[y_ksignifica == 1, 0], X[y_ksignifica == 1, 1],s = 100, c="blu", etichetta="Iris versicolor") plt.scatter(X[y_ksignifica == 2, 0], X[y_ksignifica == 2, 1],s = 100, c="verde", etichetta="Iris-verginica") #Visualizzazione dei cluster - Nelle prime due colonne plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:,1],s = 100, c="Nero", etichetta="centroidi") #tracciando i baricentri dei cluster plt.legend() plt.mostra() |
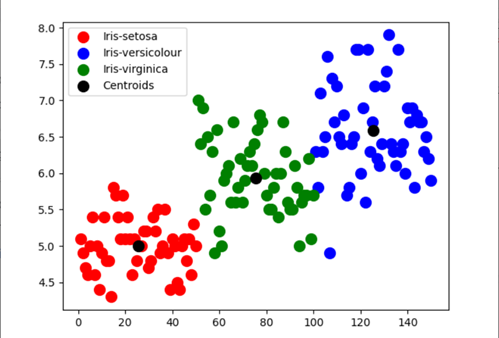
Una idea que podemos obtener del Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate.... es que la precisión del modelo para determinar Setosa y Virginica es comparativamente más a Versicolour.
conclusione:
Abbiamo esplorato e pre-elaborato il set di dati Iris utilizzando sklearn. set di dati, oltre a utilizzare il file Iris.csv. Cosa c'è di più, aprendí sobre el aprendizaje supervisado y no supervisado e implementé el algoritmo de árbol de decisión y el algoritmo de raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. de K-means.
Riferimenti:
https://www.kaggle.com/sixteenpython/machine-learning-with-iris-dataset
https://scikit-learn.org/stable/
https://certes.co.uk/types-of-artificial-intelligence-a-detailed-guide/
Circa l'autore:
Ciao lettore, sono Yashi Saxena, e attualmente lavoro presso TCS come ingegnere di sistemi. AI, ML e PNL sono sempre stati il mio interesse, quindi eccomi qui a fare uno sforzo per saperne di più su questo campo. Puoi connetterti con me su Linkedin: https://www.linkedin.com/in/yashi-saxena-7a9522194/
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





