introduzione


(SR) è il processo di recupero alto risoluzioneIl "risoluzione" si riferisce alla capacità di prendere decisioni ferme e raggiungere gli obiettivi prefissati. In contesti personali e professionali, Implica la definizione di obiettivi chiari e lo sviluppo di un piano d'azione per raggiungerli. La risoluzione è fondamentale per la crescita personale e il successo in vari ambiti della vita, In quanto ti permette di superare gli ostacoli e mantenere la concentrazione su ciò che conta davvero.... (ORA) immagini di Bassa risoluzione (LR) immagini. È un'importante classe di tecniche di elaborazione delle immagini nella visione artificiale e nell'elaborazione delle immagini e gode di una vasta gamma di applicazioni del mondo reale., come immagini mediche, immagini satellitari, vigilanza e sicurezza, immagini astronomiche, tra l'altro.
Con el avance en las técnicas de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... en los últimos años, I modelli RH basati sul deep learning sono stati attivamente esplorati e, spesso, raggiungere prestazioni all'avanguardia in vari benchmark SR. Una varietà di metodi di deep learning sono stati applicati per risolvere i compiti RH, che vanno dal metodo basato su reti neurali convoluzionali (CNN) ai recenti promettenti approcci RH basati su reti generative avverse.
Problema
Il problema della cancellazione delle immagini (SR), in particolare la super risoluzione di una singola immagine (SISR), ha guadagnato molta attenzione nella comunità di ricerca. SISR mira a ricostruire un'immagine ad alta risoluzione ISR immagine singola a bassa risoluzione ILR. In genere, il rapporto tra meLR e l'immagine originale ad alta risoluzione IORA può variare a seconda della situazione. Molti studi presumono che ioLR è una versione bicubica ridotta di IORA, ma altri fattori degradanti come la sfocatura, distruzione o rumore possono essere considerati anche per applicazioni pratiche.
In questo articolo, ci concentreremo su apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... metodi per compiti di super risoluzione. Quando si utilizzano immagini HR come target e LR come input, possiamo trattare questo problema come un problema di apprendimento supervisionato.
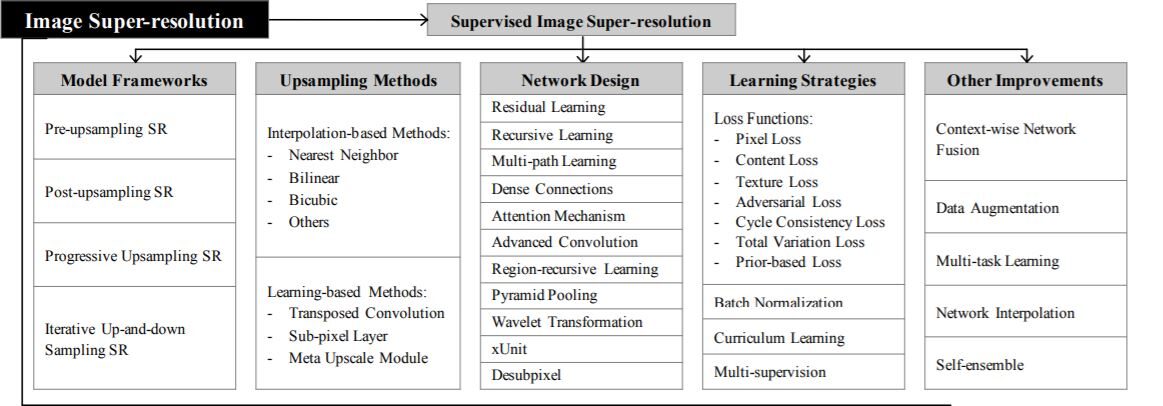
Metodi di campionamento superiori
Prima di capire il resto della teoria dietro la super risoluzione, dobbiamo capire campionamento (Aumenta la risoluzione spaziale delle immagini o semplicemente aumenta il numero di righe / colonne di pixel o entrambi nell'immagine) e i suoi vari metodi.
1. Metodi basati sull'interpolazione – Interpolazione delle immagini (ridimensionamento dell'immagine) si riferisce al ridimensionamento delle immagini digitali ed è ampiamente utilizzato dalle applicazioni relative alle immagini. I metodi tradizionali includono l'interpolazione del vicino più prossimo, interpolazione lineare, binaurale, bicubica, eccetera.
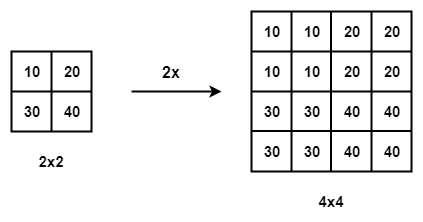
Interpolazione del vicino più prossimo con la scala di 2
- Interpolazione del vicino più vicino – L'interpolazione del vicino più vicino è un algoritmo semplice e intuitivo. Seleziona il valore di pixel più vicino per ogni posizione da interpolare indipendentemente da qualsiasi altro pixel.
- Interpolazione bilineare – Interpolazione bilineare (DIVENTARE) esegue prima l'interpolazione lineare su un asse dell'immagine e poi sull'altro asse. Poiché risulta in un'interpolazione quadratica con un campo recettivo di 2 × 2, mostra prestazioni molto migliori rispetto all'interpolazione del vicino più prossimo, mantenendo una velocità relativamente elevata.
- Interpolazione bicubica – Allo stesso modo, interpolazione bicubica (BCI) esegue l'interpolazione cubica su ciascuno dei due assi. Rispetto a BLI, la BCI tiene conto 4 × 4 pixel e produce risultati più uniformi con meno artefatti ma velocità molto più bassa. Fare riferimento a questa per una discussione dettagliata.
carenze – I metodi basati sull'interpolazione spesso introducono alcuni effetti collaterali come la complessità computazionale, amplificazione del rumore, risultati sfocati, eccetera.
2. Campionamento bottom-up basato sull'apprendimento – Per superare le carenze dei metodi basati sull'interpolazione e imparare il sovracampionamento end-to-end, il livello di convoluzione trasposto e il livello sub-pixel sono inseriti nel campo SR.
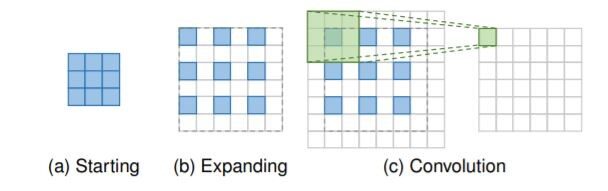
Strato di convoluzione trasposto: i quadrati blu indicano l'ingresso,
e le caselle verdi indicano il kernel e l'output della convoluzione.
- Convoluzione trasposta: strato, noto anche come strato di deconvoluzione, prova a eseguire una trasformazione opposta a una normale convoluzione, vale a dire, prevedere il possibile input in base alle mappe delle caratteristiche della dimensione dell'output della convoluzione. In particolare, aumenta la risoluzione dell'immagine espandendo l'immagine inserendo zeri ed eseguendo una convoluzione.
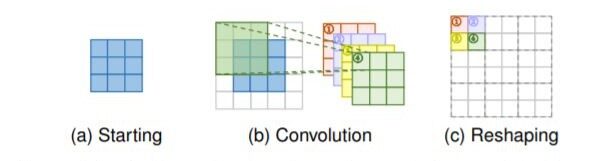
Livello subpixel: le caselle blu indicano l'input e le caselle con altri colori indicano diverse operazioni di convoluzione e diverse mappe di funzionalità di output.
- Livello subpixel: Il livello subpixel, un altro livello di sovracampionamento che può essere appreso end-to-end, esegue l'upsampling generando una pluralità di canali per convoluzione e quindi rimodellando i programmi. All'interno di questo livello, Viene prima applicata una convoluzione per produrre output con
S2 canali orari, dove s è il fattore di scala. Supponendo che la dimensione di input sia h × w × c, la dimensione dell'output sarà h × w × s2C. Successivamente, l'operazione di risagomatura viene eseguita per produrre output con dimensione sh × sw × c
Frame di sovrasoluzione
Poiché la super-risoluzione delle immagini è un problema mal posto, come sovracampionare (vale a dire, generare un'uscita della frequenza cardiaca dall'ingresso LR) è il problema chiave. Ci sono principalmente quattro fotogrammi del modello basati sulle operazioni di campionamento superiori impiegate e le loro posizioni nel modello (vedi la tabella sopra).
1. Risoluzione super pre-campionamento –
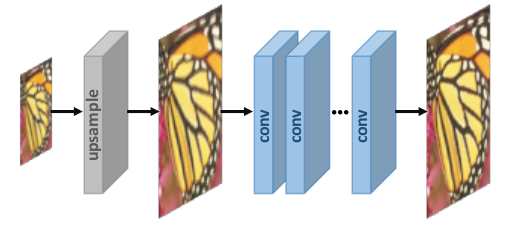
Non eseguiamo la mappatura diretta dalle immagini LR alle immagini HR in quanto è considerato un compito difficile. L'utilizzo di algoritmi di sovracampionamento tradizionali per ottenere immagini a risoluzione più elevata e quindi perfezionarle utilizzando reti neurali profonde è una soluzione semplice. Ad esempio, Le immagini LR vengono campionate in immagini HR spesse con la dimensione desiderata mediante interpolazione bicubica. Dopo, le CNN profonde vengono applicate a queste immagini per ricostruire immagini di alta qualità.
2. Super risoluzione post-campionamento:
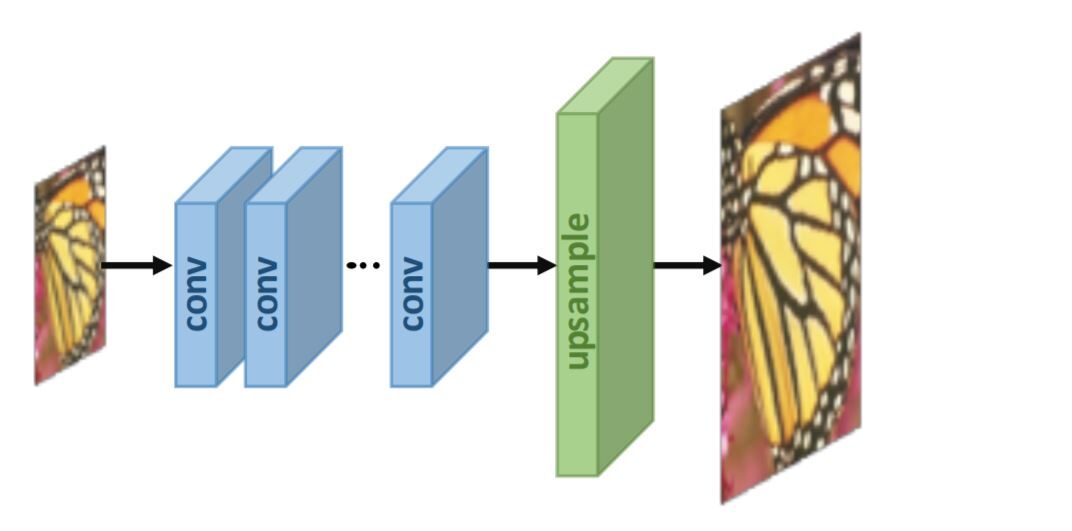
Per migliorare l'efficienza computazionale e sfruttare appieno la tecnologia di deep learning per aumentare automaticamente la risoluzione, los investigadores proponen realizar la mayoría de los cálculos en un espacio de baja dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e... reemplazando el muestreo predefinido con capas de aprendizaje de extremo a extremo integradas al final de los modelos. Nel lavoro pionieristico di questo quadro, vale a dire, SR post-campionamento, Le immagini in ingresso LR si inseriscono in profondità nella CNN senza aumentare la risoluzione, e gli strati di campionamento superiori che possono essere appresi end-to-end sono applicati alla fine della rete.
Strategie di apprendimento
Nel campo della super risoluzione, le funzioni di perdita sono usate per
misurare l'errore di ricostruzione e guidare l'ottimizzazione del modello. Nei primi giorni, i ricercatori di solito usano Perdita L2 per pixel (errore quadratico medio), ma poi scopre di non poter misurare il
qualità di ricostruzione molto accurata. Perciò, una varietà
funzioni di perdita (P. non., perdita di contenuto, gli avversariS) sono adottati per misurare meglio la ricostruzione
errore e produrre risultati di qualità superiore e più realistici.
- Perdita di Pixelwise L1 – Differenza assoluta tra i pixel dell'immagine HR della verità al suolo e quella generata.
- Perdita di Pixelwise L2 – Differenza quadratica media della radice tra i pixel dell'immagine HR della verità al suolo e quella generata.
- Perdita di contenuto – la perdita di contenuto è riportata come la distanza euclidea tra i rendering di alto livello dell'immagine di output e l'immagine di destinazione. Le funzioni di alto livello si ottengono passando attraverso CNN precedentemente addestrate come VGG e ResNet.
- Perdita dell'avversario – Basato su GAN, dove trattiamo il modello SR come un generatore e definiamo un discriminatore aggiuntivo per giudicare se l'immagine in ingresso è generata o meno.
- PSNR – Il rapporto segnale-rumore di picco (PSNR) è una metrica oggettiva comunemente usata per misurare la qualità di ricostruzione di una trasformazione con perdita. PSNR è inversamente proporzionale al logaritmo dell'errore quadratico medio (MSE) tra l'immagine reale del terreno e l'immagine generata.
In MSE, sono un senza rumore Metro×Nord immagine monocromatica (verità fondamentale) e K è l'immagine generata (approccio rumoroso). UN PSNR, MAXio rappresenta il valore di pixel massimo possibile dell'immagine.
Layout di rete
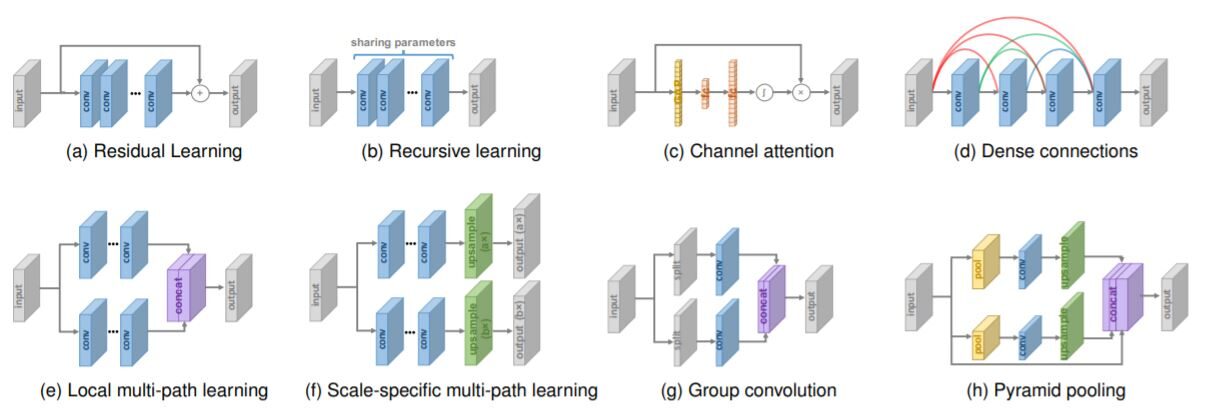
Vari progetti di rete in architettura a super risoluzione
Basta con le basi! Analizziamo alcune delle All'avanguardia metodi di superrisoluzione –
Metodi di superrisoluzione
Rete avversaria generativa a super risoluzione (SRGAN) – Usa l'idea di GAN per compiti di super risoluzione, vale a dire, il generatore proverà a produrre un'immagine dal rumore che sarà giudicata dal discriminatore. Ambos seguirán entrenando para que el generador pueda generar imágenes que puedan coincidir con los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... reales.
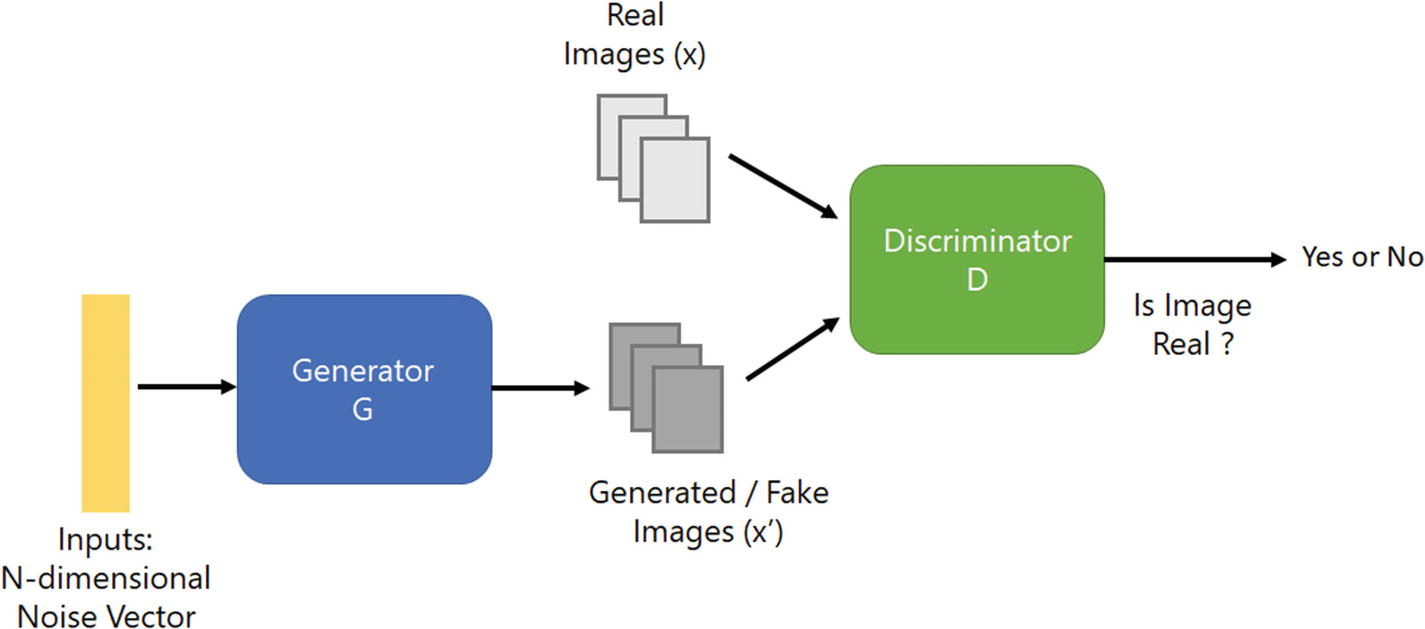
Architettura della rete avversaria generativa
Esistono diverse forme di super risoluzione, ma c'è un problema: Come possiamo recuperare dettagli di trama più fini da un'immagine a bassa risoluzione in modo che l'immagine non sia distorta??
I risultati hanno un alto PSNR; i media hanno risultati di alta qualità, ma spesso mancano di dettagli ad alta frequenza.
Per raggiungere questo obiettivo in SRGAN, usamos la Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... perceptiva que comprende la pérdida de contenido y de adversario.
Controlla il documenti originali per informazioni dettagliate.
Passi –
1. Elaboriamo le risorse umane (immagini ad alta risoluzione) per immagini LR a campionamento ridotto. Ora abbiamo immagini HR e LR per il set di dati di allenamento.
2. Passiamo le immagini LR attraverso un generatore che campiona e fornisce immagini SR.
3. Usiamo il discriminatore per distinguere l'immagine HR e propaghiamo la perdita di GAN per addestrare il discriminatore e il generatore.
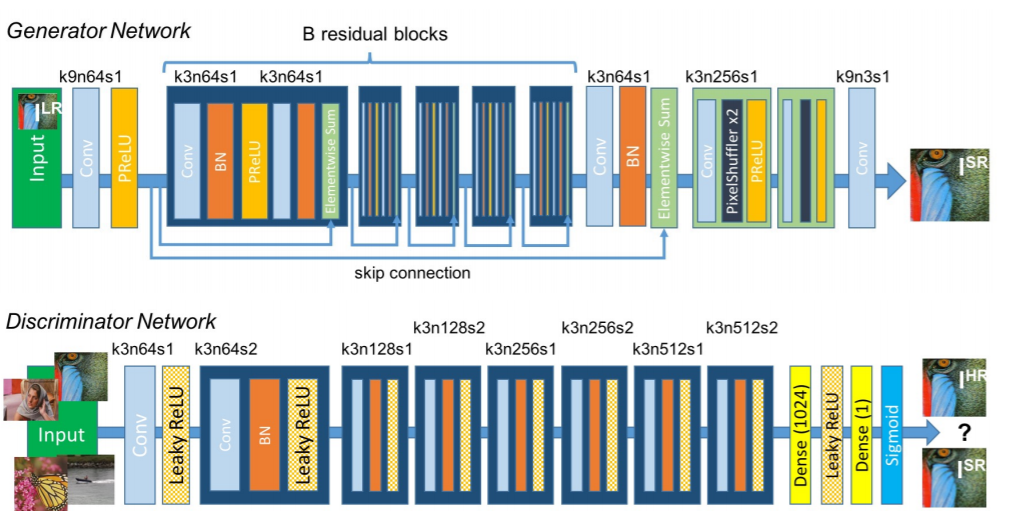
Architettura di rete SRGAN
Caratteristiche principali del metodo:
- Tipo di telaio post-campionamento
- Livello sub-pixel per un campionamento più elevato
- Contiene blocchi residui
- Usa la perdita di percezione
EDSR, MDSR – Mostra tecniche di apprendimento residuo
prestazioni di super-risoluzione migliorate attraverso reti neurali convoluzionali profonde (DCNN). Architettura a scala singola Rete ad alta risoluzione avanzata e profonda (EDSR) gestisce una specifica scala di super-risoluzione e Sistema a super risoluzione profonda multiscala (MDSR) ricostruisce più scale di immagini ad alta risoluzione in un unico modello. Significativo miglioramento delle prestazioni del modello.
è dovuto all'ottimizzazione rimuovendo i moduli non necessari in
reti residuali convenzionali.
Controlla il documenti originali per informazioni dettagliate.
Alcune delle caratteristiche chiave dei metodi:
- Blocchi residui – SRGAN ha applicato con successo l'architettura ResNet al problema della super-risoluzione con SRResNet, prestazioni ulteriormente migliorate utilizzando un framework ResNet migliore. Nell'architettura proposta –
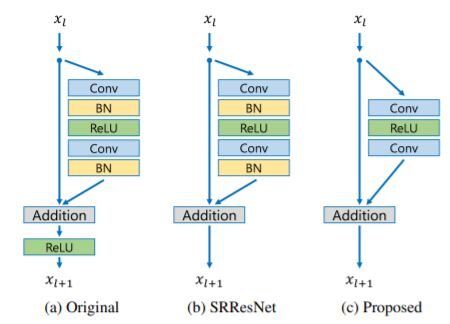
Confronto dei blocchi residui
- Quitaron las capas de standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... por lotes de la red como en SRResNets. Poiché i livelli di normalizzazione batch normalizzano le caratteristiche, eliminare la flessibilità della gamma di rete standardizzando le caratteristiche, è meglio eliminarli.
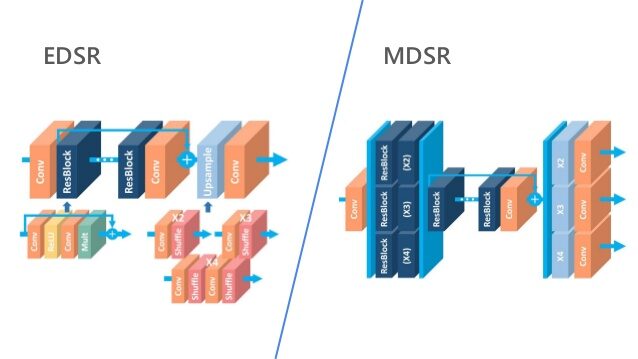
- Un MDSR, propusieron una arquitectura multiescala que comparte la mayoría de los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... en diferentes escalas. Il modello multiscala proposto utilizza un numero significativamente inferiore di parametri rispetto a diversi modelli a scala singola, ma mostra prestazioni comparabili.
Quindi ora siamo arrivati alla fine del blog!! Per maggiori informazioni sulla super risoluzione, controlla questi lavori di indagine.
Per favore condividi i tuoi commenti sul blog nella sezione commenti. Buon apprendimento 🙂
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





