Requisiti precedenti: Linguaggio di programmazione R di base e conoscenza di base della classificazione
Mentre l'approccio del set di convalida funziona dividendo il set di dati una volta, k-Fold lo fa cinque o dieci volte. Immagina di eseguire l'approccio del set di convalida dieci volte utilizzando un set di dati diverso.
Diciamo che abbiamo 100 righe di dati. Li dividiamo casualmente in dieci gruppi di pieghe. Ogni piega sarà composta da circa 10 righe di dati. El primer pliegue se utilizará como conjunto de validación y el resto es para el conjunto de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina..... Quindi addestriamo il nostro modello utilizzando questo set di dati e calcoliamo la precisione o la perdita. Quindi ripetiamo questo processo ma usando una piega diversa per il set di convalida. Guarda l'immagine qui sotto.
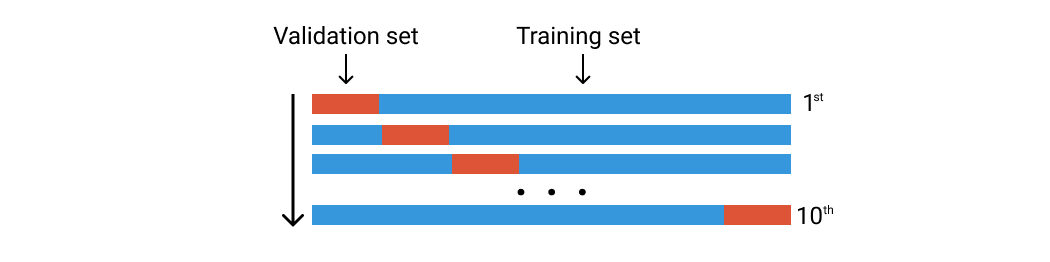
Convalida incrociata di K-Fold. Immagine dell'autore
Passiamo al codice
Le librerie che usiamo sono queste due:
biblioteca(ordinatoverso) biblioteca(caret)
I dati utilizzati qui sono dati sulle malattie cardiache in terapia intensiva che possono essere scaricati all'indirizzo Kaggle. Puoi anche utilizzare qualsiasi dato di classificazione per questo esperimento.
dati <- leggi.csv("../input/heart-malattia-uci/heart.csv")
testa(dati)
Ecco le prime sei righe dei dati caricati. Tiene trece predictores y la última columna es la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de respuesta. Puoi anche controllare le ultime righe usando la funzione tail ().
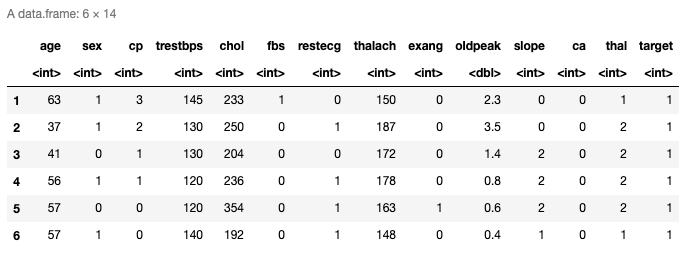
Distribuzione dei dati
Qui vogliamo confermare che la distribuzione tra i dati di due etichette non è molto diversa. Perché set di dati sbilanciati possono portare a una precisione sbilanciata. Ciò significa che il tuo modello predirà sempre verso una singola etichetta., o predice sempre 0 oh 1.
storico(dati$target,col="corallo") prop.table(tavolo(dati$target))
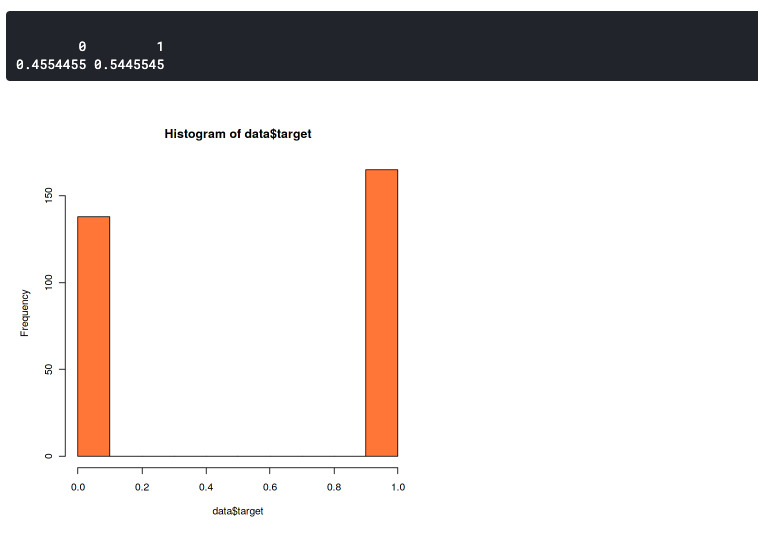
Questo grafico mostra che il nostro set di dati è leggermente sbilanciato ma comunque abbastanza buono. Ha un rapporto di 46:54. Dovresti iniziare a preoccuparti se il tuo set di dati è più di 60% dei dati in una classe. Quindi, puoi usare SMOTE per gestire un set di dati sbilanciato.
Il k-fold
set.seme(100) trctrl <- trainControl(metodo = "CV", numero = 10, savePrediction=VERO) nb_fit <- treno(fattore(obbiettivo) ~., dati = dati, metodo = "ingenuo_bayes", trControl=trctrl, tuneLength = 0) nb_fit
La prima riga è impostare il seme dello pseudo-casuale in modo che lo stesso risultato possa essere riprodotto. Puoi usare qualsiasi numero per il valore iniziale.
Prossimo, possiamo impostare l'impostazione k-Fold nella funzione trainControl (). Impostare il parametro del metodo su "cv" e il parametro numerico su 10. Significa che impostiamo la convalida incrociata con dieci pieghe. Possiamo impostare il numero di piegatura con qualsiasi numero, ma il modo più comune è impostarlo su cinque o dieci.
La funzione del treno () viene utilizzato per determinare il metodo che usiamo. Qui usiamo il metodo Naive Bayes e impostiamo tuneLength a zero perché ci concentriamo sulla valutazione del metodo su ogni piega. También podemos establecer tuneLength si queremos hacer el ajuste de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... durante la validación cruzada. Ad esempio, se usiamo il metodo K-NN e vogliamo analizzare quanti K sono i migliori per il nostro modello.
Puoi vedere il metodo supportato in Documentazione R.
Tieni presente che la convalida incrociata di k-Fold può richiedere del tempo perché esegui il processo di formazione dieci volte.
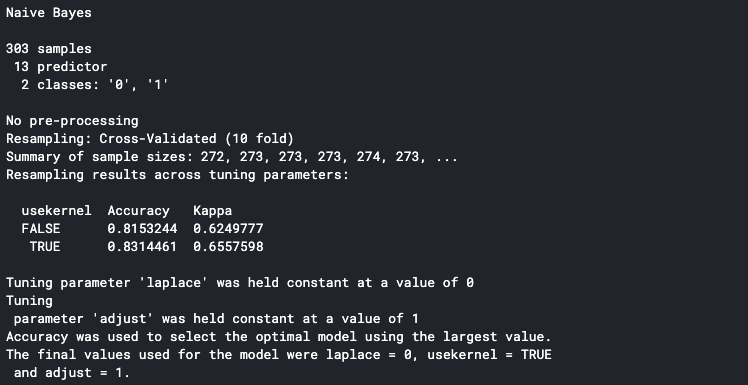
Stamperà i dettagli sulla console una volta terminato. La precisione mostrata sulla console è la precisione media di tutte le pieghe di allenamento. Possiamo vedere che il nostro modello ha una precisione media di 83%.
Distribuire il k-Fold
Possiamo determinare che il nostro modello funziona bene in ogni piega se osserviamo la precisione di ogni piega.. Per fare questo, Assicurarsi di configurare il comando savePredictions true nella funzione trainControl ().
pred <- nb_fit$pred
pred$equal <- ifelse(pred$pred == pred$obs, 1,0)
ogni volta <- pred %>%
group_by(Ricampionare) %>%
summarise_at(Vars(uguale),
elenco(Precisione = media))
ogni volta
Ecco il grafico di precisione in ogni piega.

Possiamo anche tracciarlo sul grafico per renderlo più facile da analizzare. In questo caso, usiamo il box plot per rappresentare le nostre precisioni.
ggplot(dati=ogni volta, aes(x=Ricampiona, y=Precisione, gruppo=1)) + geom_boxplot(colore="marrone") + geom_point() + theme_minimal()
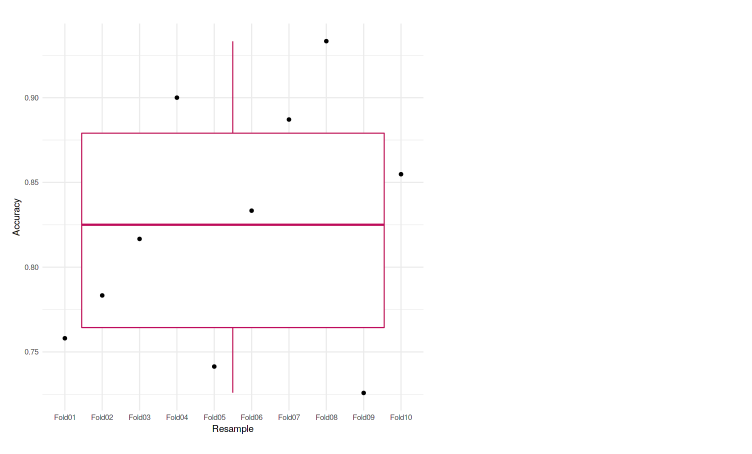
Possiamo vedere che ciascuna delle pieghe raggiunge una precisione che non differisce molto l'una dall'altra. La precisione più bassa è 72,58%, e anche nel box plot, non vediamo valori anomali. Il che significa che il nostro modello funzionava bene con la convalida incrociata di k volte.
Qual è il prossimo
- Prova un numero diverso di pieghe
- Effettuare un'impostazione dei parametri
- Usa altri set di dati e metodi
Breve biografia dell'autore
Il mio nome è Muhammad Arnold, un appassionato di machine learning e data science. Attualmente studentessa magistrale in informatica in Indonesia.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





