introduzione
L'industria dell'analisi si occupa di ottenere il “informazione” dei dati. Con la crescente quantità di dati negli ultimi anni, che sono per lo più non strutturati, è difficile ottenere le informazioni pertinenti e desiderate. Ma, la tecnologia ha sviluppato alcuni potenti metodi che possono essere utilizzati per estrarre i dati e ottenere le informazioni che stiamo cercando.
Una di queste tecniche nel campo del text mining è la modellazione dei temi. Come suggerisce il nome, è una procedura per identificare automaticamente i temi presenti in un oggetto di testo e derivare modelli nascosti esibiti da un corpus di testo. Perché, aiutando a prendere decisioni migliori.
La modellazione degli argomenti è distinta dagli approcci di estrazione del testo basati su regole che utilizzano espressioni regolari o tecniche di ricerca di parole chiave basate su dizionari. È un approccio non supervisionato che viene utilizzato per cercare e osservare l'insieme delle parole (chiama “temi”) in grandi gruppi di testi.
I temi possono essere impostati come “uno schema ripetuto di termini concorrenti in un corpus”. Un buon modello di tema dovrebbe risultare in: “Salute”, “medico”, “paziente”, “Ospedale” per un argomento – Assistenza medica e “azienda agricola”, “raccolti”, “Grano” per un argomento – “agricoltura”.
I modelli di temi sono molto utili per raggruppare i documenti, organizzare grandi blocchi di dati testuali, recupero delle informazioni di testo non strutturato e selezione delle funzioni. Come esempio, Il New York Times utilizza modelli di argomenti per potenziare i motori di raccomandazione dei post degli utenti. Vari professionisti utilizzano modelli tematici per le industrie di reclutamento, dove il tuo obiettivo è estrarre le caratteristiche latenti dalle descrizioni del lavoro e assegnarle ai candidati giusti. Utilizzato per organizzare grandi insiemi di dati di posta elettronica, recensioni dei clienti e profili dei social media degli utenti.
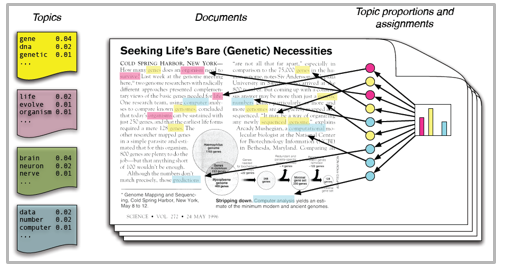
Quindi, se non sei sicuro dell'intera procedura di modellazione dell'argomento, Questa guida ti introdurrà a diversi concetti seguiti dalla loro implementazione in Python.
Sommario
- Assegnazione di Dirichlet latente per la modellazione del tema
- Implementazione Python
- Preparazione dei documenti
- Pulizia e pretrattamento
- Preparazione della matrice dei termini del documento
- Esecuzione del modello LDA
- Risultati
- Suggerimenti per guidare i risultati della modellazione degli argomenti
- Filtro di frequenza
- Parte del filtro dei tag vocali
- Batch Wise LDA
- Modellazione del tema per la selezione delle funzionalità
Assegnazione di Dirichlet latente per la modellazione del tema
Ci sono molti approcci per ottenere temi da un testo come: Frequenza del termine e frequenza del documento inverso. Tecniche di fattorizzazione a matrice non negativa. La mappatura di Dirichlet latente è la tecnica di modellazione di argomenti più popolare e in questo post parleremo della stessa cosa.
LDA presuppone che i documenti siano prodotti da una combinazione di argomenti. Successivamente, questi argomenti generano parole supportate dalla loro distribuzione di probabilità. Dato un insieme di dati di documenti, LDA torna indietro e cerca di capire quali argomenti creerebbero quei documenti in primo luogo.
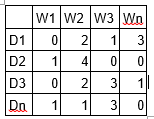
LDA è una tecnica di fattorizzazione a matrice. Nello spazio vettoriale, qualsiasi corpus (raccolta di documenti) può essere rappresentato come una matrice documento-termine. La matrice successiva mostra un corpus di N documenti D1, re2, D3… Dn e la dimensione del vocabolario di M parole W1, W2 .. Wn. Il valore della cella i, j fornisce il conteggio della frequenza della parola Wj nel documento Di.
LDA converte questo array di documenti e termini in due array di dimensioni minori: M1 e M2.
M1 è una matrice di documenti e argomenti e M2 è una matrice di argomenti e termini con dimensioni (n, K) e (K, m) rispettivamente, dove N è il numero di documenti, K è il numero di argomenti e M è la dimensione del vocabolario .
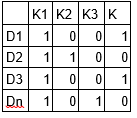
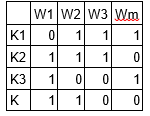
Si noti che queste due matrici forniscono già distribuzioni di soggetti di parole e documenti. Nonostante questo, queste distribuzioni devono essere migliorate, che è l'obiettivo principale dell'ADL. LDA utilizza tecniche di campionamento per guidare queste matrici.
Ripeti ogni parola “w” per ogni documento “D” e prova a modificare il tema corrente – assegnazione di parole con una nuova assegnazione. Viene assegnato un nuovo argomento “K” alla parola “w” con una probabilità P che è un prodotto di due probabilità p1 e p2.
Per ogni argomento, si calcolano due probabilità p1 e p2. P1 – P (tema t / documento d) = la proporzione di parole nel documento d che sono attualmente assegnate all'argomento t. P2 – P (palabra con / tema t) = la proporzione di assegnazioni all'argomento t su tutti i documenti che derivano da questa parola w.
L'argomento attuale: l'assegnazione della parola viene aggiornata con un nuovo argomento con la probabilità, prodotto di p1 e p2. In questo passaggio, il modello presuppone che tutte le assegnazioni di parole e argomenti esistenti, tranne la parola corrente, hanno ragione. Questa è essenzialmente la probabilità che l'argomento t generi la parola w, quindi ha senso adattare l'argomento della parola corrente con una nuova probabilità.
Dopo diverse iterazioni, si raggiunge uno stato stazionario in cui le distribuzioni dell'oggetto del documento e dei termini dell'oggetto sono abbastanza buone. Questo è il punto di convergenza di LDA.
Parametri LDA
Iperparametri alfa e beta: Alpha rappresenta la densità di documenti e argomenti e Beta rappresenta la densità di argomenti e parole. Più alto è il valore alfa, i documenti sono composti da più argomenti e da un valore alfa inferiore, i documenti contengono meno argomenti. D'altra parte, beta più alto, gli argomenti sono costituiti da un gran numero di parole nel corpus, e con un valore beta inferiore, composto da poche parole.
Numero di argomenti: numero di argomenti da estrarre dal corpus. I ricercatori hanno sviluppato approcci per ottenere un numero ottimale di soggetti utilizzando il Kullback Leibler Divergence Score.. Non discuterò questo in dettaglio., visto che è troppo matematico. Capire, si può fare riferimento a questo[1] documento originale sull'uso della divergenza KL.
Numero di termini dell'argomento: numero di termini composti in un singolo argomento. In genere è deciso in base al requisito. Se la dichiarazione del problema parla dell'estrazione di temi o concetti, si consiglia di selezionare un numero maggiore, se la dichiarazione del problema parla dell'estrazione di caratteristiche o termini, si consiglia un numero basso.
Numero di iterazioni / passato: numero massimo di iterazioni consentite all'algoritmo LDA per la convergenza.
Puoi approfondire i temi di modellazione qui.
Correre in Python
Preparazione dei documenti
Ecco i documenti di esempio che vengono combinati per formare un corpus.
doc1 = "Sugar is bad to consume. My sister likes to have sugar, but not my father." doc2 = "My father spends a lot of time driving my sister around to dance practice." doc3 = "Doctors suggest that driving may cause increased stress and blood pressure." doc4 = "Sometimes I feel pressure to perform well at school, but my father never seems to drive my sister to do better." doc5 = "Health experts say that Sugar is not good for your lifestyle."
# compile documents doc_complete = [doc1, doc2, doc3, doc4, doc5]
Pulizia e pretrattamento
La pulizia è un passaggio importante prima di qualsiasi attività di estrazione di testo, in questo passaggio rimuoveremo i segni di punteggiatura, parole vuote e normalizzeremo il corpus.
``` from nltk.corpus import stopwords from nltk.stem.wordnet import WordNetLemmatizer import stringstop = set(stopwords.words('english')) exclude = set(string.punctuation) lemma = WordNetLemmatizer()def clean(doc): stop_free = " ".join([i for i in doc.lower().split() if i not in stop]) punc_free="".join(ch for ch in stop_free if ch not in exclude) normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split()) return normalized
doc_clean = [clean(doc).split() for doc in doc_complete] ```
Preparazione della matrice di scadenza del documento
Tutti i documenti di testo combinati sono noti come corpus. Per eseguire qualsiasi modello matematico su un corpus di testo, è buona norma convertirlo in una rappresentazione matriciale. Il modello LDA cerca modelli di termini ripetuti in tutta la matrice DT. Python fornisce molte ottime librerie per le pratiche di text mining, “gemma” è una di quelle librerie pulite e belle per gestire i dati di testo. È scalabile, robusto ed efficiente. Il codice seguente mostra come convertire un corpus in un array di documenti e termini.
```# Importing Gensim
import gensim
from gensim import corpora
# Creating the term dictionary of our courpus, where every unique term is assigned an index. dictionary = corpora.Dictionary(doc_clean)
# Converting list of documents (corpus) into Document Term Matrix using dictionary prepared above.
doc_term_matrix = [dictionary.doc2bow(doc) for doc in doc_clean] ```
Esecuzione del modello LDA
Il prossimo passo è creare un oggetto per il modello LDA e addestrarlo nella matrice Document-Term. La formazione necessita anche di alcuni parametri come input che sono spiegati nella sezione precedente. Il modulo gensim consente sia la stima del modello LDA da un corpus formativo sia l'inferenza della distribuzione degli argomenti in documenti nuovi e inediti.
```# Creating the object for LDA model using gensim library
Lda = gensim.models.ldamodel.LdaModel
# Running and Trainign LDA model on the document term matrix.ldamodel = Lda(doc_term_matrix, num_topics=3, id2word = dictionary, passes=50)
```
Risultati
``` print(ldamodel.print_topics(num_topics=3, num_words=3)) ['0.168*health + 0.083*sugar + 0.072*bad,
'0.061*consume + 0.050*drive + 0.050*sister,
'0.049*pressur + 0.049*father + 0.049*sister] ```
Ogni riga è un argomento con termini e pesi individuali. Topic1 può essere chiamato Poor Health e Topic3 può essere chiamato Family.
Suggerimenti per guidare i risultati della modellazione degli argomenti
I risultati dei modelli tematici dipendono totalmente dalle caratteristiche (termini) presente nel corpus. Il corpus è rappresentato come una matrice di termini del documento, che è generalmente molto raro in natura. Ridurre la dimensionalità dell'array può migliorare i risultati della modellazione del tema. Secondo la mia esperienza pratica, ci sono pochi approcci che funzionano.
1. Filtro di frequenza – Organizza ogni termine in base alla sua frequenza. I termini con frequenze più alte hanno maggiori probabilità di apparire nei risultati rispetto a quelli con frequenze basse. I termini a bassa frequenza sono essenzialmente caratteristiche deboli del corpus, quindi è buona norma sbarazzarsi di tutte quelle caratteristiche deboli. Un'analisi esplorativa dei termini e della loro frequenza può aiutare a scegliere quale valore di frequenza deve essere considerato come soglia..
2. Parte del filtro dei tag vocali: Il filtro tag POS ha più a che fare con il contesto delle funzioni che con la frequenza delle funzioni. La modellazione degli argomenti tenta di tracciare i modelli ricorrenti dei termini negli argomenti. Nonostante questo, tutti i termini potrebbero non essere ugualmente importanti dal punto di vista contestuale. Come esempio, il tag POS IN contiene termini come – “entro”, “su”, “tranne”. “cd” contiene – “uno”, “A partire dal”, “cento”, eccetera. “MD” contiene “Maggio”, “deve”, eccetera. Questi termini sono le parole di supporto per una lingua e possono essere rimossi studiando i suoi post tag.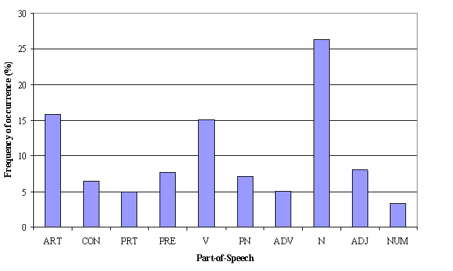
3. Batch Wise LDA –Per recuperare i termini dell'argomento più importanti, un corpus può essere suddiviso in lotti di dimensioni fisse. L'esecuzione di LDA più volte su questi lotti darà risultati diversi; nonostante questo, i migliori termini dell'oggetto saranno l'intersezione di tutti i lotti.
Nota: Se vuoi imparare la modellazione di argomenti in dettaglio e anche realizzare un progetto usandola, quindi, abbiamo un corso basato su video e PNL, coprendo la modellazione del tema e la sua implementazione in Python.
Modellazione del tema per la selezione delle funzionalità
Qualche volta, LDA può essere utilizzato anche come tecnica di selezione delle caratteristiche. Facciamo un esempio di un ostacolo di classificazione del testo in cui i dati di allenamento contengono documenti per categorie. Se LDA viene eseguito su set di documenti di categoria. Seguita dalla rimozione di termini di argomento comuni nei risultati di diverse categorie, si otterranno le migliori caratteristiche per una categoria.
Note finali
Con questo, arriviamo alla fine del tutorial sulla Modellazione dei Temi. Spero che questo ti aiuti a migliorare la tua conoscenza del lavoro con i dati di testo. Per ottenere i massimi benefici da questo tutorial, Ti suggerisco di esercitarti con i codici fianco a fianco e controllare i risultati.
Il post ti è stato utile?? Per favore condividi con noi se hai eseguito un tipo di analisi simile in precedenza. Fateci sapere i vostri pensieri su questo post nella casella qui sotto..
Riferimenti
- http://link.springer.com/chapter/10.1007/978-3-642-13657-3_43





