Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
L'analisi dei cluster o il clustering è un algoritmo di apprendimento automatico non supervisionato che raggruppa set di dati non etichettati. Il tuo obiettivo è formare cluster o gruppi utilizzando i punti dati in un set di dati in modo tale che vi sia un'elevata somiglianza tra i cluster e una bassa somiglianza tra i cluster.. In parole povere, il clustering mira a formare sottoinsiemi o gruppi all'interno di un insieme di dati costituito da punti dati che sono effettivamente simili tra loro e i gruppi o sottoinsiemi o gruppi formati possono differire significativamente l'uno dall'altro.
Perché raggruppare??
Supponiamo di avere un set di dati e di non saperne nulla. Quindi, un algoritmo de raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. puede descubrir grupos de objetos donde las distancias promedio entre los miembros / i punti dati di ciascun gruppo sono più vicini rispetto ai membri / punti dati in altri gruppi.
Alcune delle applicazioni pratiche del Clustering nella vita reale come:
1) SegmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione.... dei clienti: Encontrar un grupo de clientes con un comportamiento similar dada una gran Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... dei clienti (viene fornito un esempio pratico utilizzando la segmentazione della clientela bancaria)
2) Classificazione del traffico di rete: Caratteristiche del raggruppamento delle sorgenti di traffico. I tipi di traffico possono essere facilmente classificati utilizzando i cluster.
3) Filtro antispam: I dati sono raggruppati in diverse sezioni (intestazione, mittente e contenuto) e poi possono aiutare a classificare quali di questi sono spam.
4)Pianificazione della citta: Raggruppamento di case in base alla loro posizione geografica, valore e tipo di casa.
Diversi tipi di algoritmi di clustering
1) Raggruppamento di K-calze – Usando questo algoritmo, classifichiamo un dato insieme di dati attraverso un certo numero di cluster predeterminati o “K” grappoli.
2) Raggruppamento gerarchico – Segui due approcci Divisivo e Agglomerato.
Agglomerative considera ogni osservazione come un singolo gruppo e quindi raggruppa punti dati simili fino a quando non vengono uniti in un unico gruppo e Divisive lavora proprio di fronte ad esso.
3) Fuzzy C significa Clustering – Il funzionamento dell'algoritmo FCM è quasi simile all'algoritmo di clustering k-means, la differenza principale è che in FCM un punto dati può essere posizionato in più di un gruppo.
4) Raggruppamento spaziale basato sulla densità – Útil en las áreas de aplicación donde requerimos estructuras de grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... no lineales, puramente basato sulla densità.
Ora, qui in questo articolo, ci concentreremo in modo approfondito sull'algoritmo di clustering k-means, spiegazioni teoriche del funzionamento di k-mezzi, vantaggi e svantaggi, e un problema di raggruppamento pratico risolto che migliorerà la comprensione teorica e ti darà una visione adeguata. come funziona il clustering k-means.
Quella è K-metà Clinsistere?
La agrupación de K-Means es un algoritmo de Apprendimento non supervisionatoL'apprendimento non supervisionato è una tecnica di apprendimento automatico che consente ai modelli di identificare modelli e strutture nei dati senza etichette predefinite. Attraverso algoritmi come k-means e analisi delle componenti principali, Questo approccio viene utilizzato in una varietà di applicazioni, come la segmentazione dei clienti, Rilevamento delle anomalie e compressione dei dati. La sua capacità di rivelare informazioni nascoste lo rende uno strumento prezioso..., che viene utilizzato per raggruppare il set di dati senza etichetta in diversi gruppi / sottoinsiemi.
Ora ti starai chiedendo cosa significa 'k’ e significa’ in k-mezzi Clustering significa ??
Metti da parte tutte le tue supposizioni qui, 'K’ definisce il numero di gruppi predefiniti da creare nel processo di raggruppamento, diciamo se k = 2, ci saranno due gruppi, e per k = 3, ci saranno tre gruppi e così via. Com'è un algoritmo basato sul centroide?, "media"’ nel clustering k-mean è correlato al centroide dei punti dati in cui ciascun gruppo è associato a un centroide. Il concetto di algoritmo basato sul centroide sarà spiegato nella spiegazione operativa di k-means.
Principalmente, l'algoritmo di clustering k-means esegue due compiti:
- Determinare il valore ottimale per K punti centrali o centroidi utilizzando un processo ripetitivo.
- Assegna ogni punto dati al suo centro k più vicino. Il cluster viene creato con punti dati vicini al particolare k center.
Come funziona il clustering di mezzi k??
Supponiamo di avere due variabili X1 e X2, Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate.... prossimo:
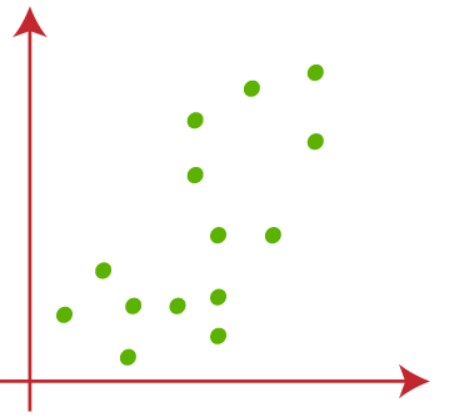
(1) Supponiamo che il valore di k, che è il numero di gruppi predefiniti, è 2 (k = 2), quindi qui raggrupperemo i nostri dati in 2 gruppi.
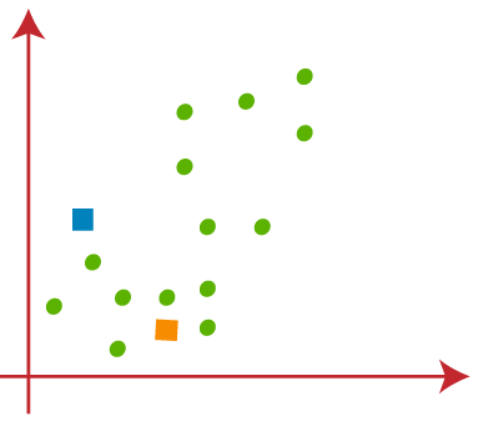
È necessario scegliere k punti casuali per formare i gruppi. Non ci possono essere restrizioni sulla selezione di k punti casuali dall'interno dei dati o dall'esterno. Quindi, qui stiamo considerando 2 punti come k punti (che non fanno parte del nostro set di dati) que se muestran en la siguiente figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline....:
(2) Il prossimo passo è mappare ogni punto dati dal set di dati sul grafico a dispersione al suo punto k più vicino, esto se hará calculando la distancia euclidiana entre cada punto con un punto k y dibujando una medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... entre ambos centroides, mostrato nella figura sottostante-
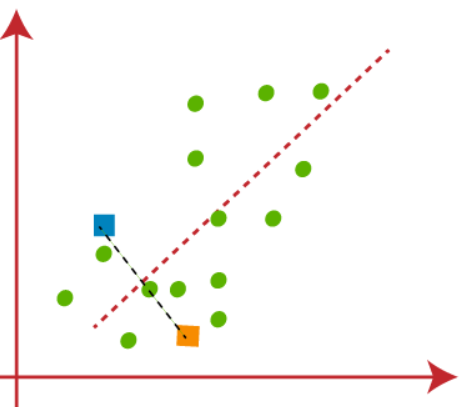
Possiamo vedere chiaramente che il punto a sinistra della linea rossa è vicino a K1 o al baricentro blu e i punti a destra della linea rossa sono vicini a K2 o al baricentro arancione..
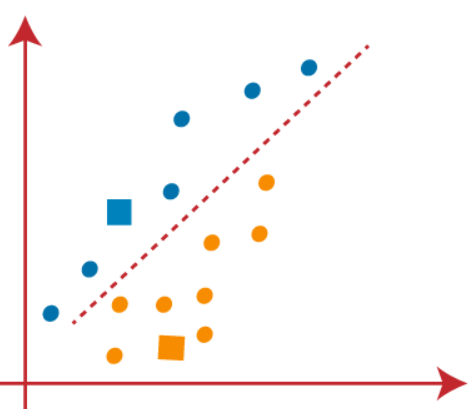
(3) Come dobbiamo trovare il punto più vicino, ripeteremo il processo scegliendo un nuovo centroide. Per scegliere i nuovi centroidi, calcoleremo il centro di gravità di questi centroidi e troveremo nuovi centroidi come mostrato di seguito:
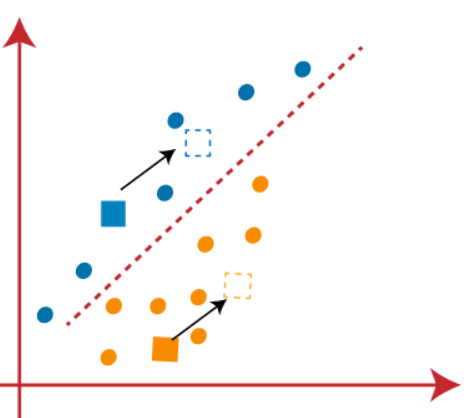
(4) Ora, dobbiamo riassegnare ogni punto dati a un nuovo centroide. Per questo, dobbiamo ripetere lo stesso processo per trovare una linea mediana. La mediana sarà la seguente:
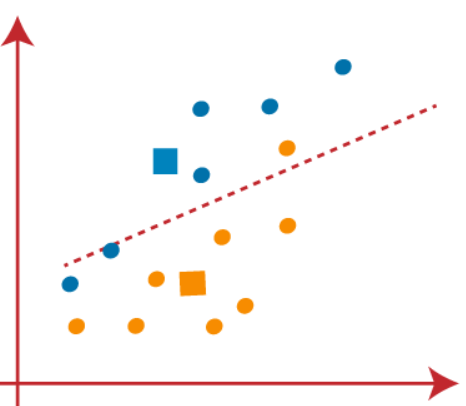
Nella foto sopra, Possiamo vedere, un punto arancione si trova sul lato sinistro della linea e due punti blu sono solo sulla linea. Quindi, questi tre punti verranno assegnati a nuovi centroidi

Continueremo a trovare nuovi centroidi finché non ci saranno punti diversi su entrambi i lati della linea.
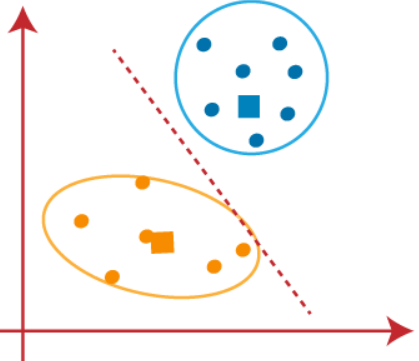
Ora possiamo eliminare i centroidi ipotizzati, e gli ultimi due gruppi saranno come mostrato nell'immagine qui sotto
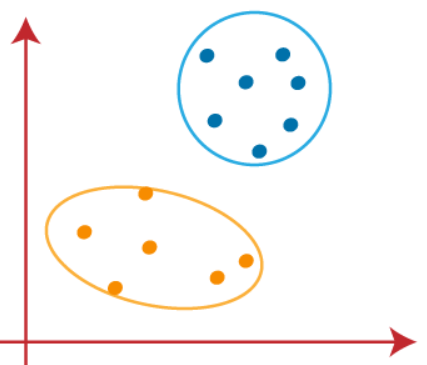
Finora abbiamo visto come funziona l'algoritmo k-means ei diversi passaggi necessari per raggiungere la destinazione finale dei cluster differenzianti..
Ora tutti si staranno chiedendo come scegliere il valore di k numero di cluster.
El rendimiento del algoritmo de agrupación de K-means depende en gran misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... de las agrupaciones que forma. Scegliere il numero ottimale di cluster è un compito difficile. Esistono diversi modi per trovare il numero ottimale di cluster, ma qui stiamo discutendo due metodi per trovare il numero di cluster o il valore di K che è il Metodo del gomito e punteggio della silhouette.
Metodo del gomito per trovare 'k’ numero di gruppi:[1]
Il metodo Elbow è il più popolare per trovare un numero ottimale di cluster, questo metodo utilizza WCSS (Somma dei quadrati all'interno dei cluster) che rappresenta le variazioni totali all'interno di un cluster.
WCSS = ∑Pi e Cluster1 distanza (Pio C1)2 + ?Pi in Cluster2distanza (Pio C2)2+ ?Pi in CLuster3 distanza (Pio C3)2
Nella formula sopra ∑Pi e Cluster1 distanza (Pio C1)2 è la somma del quadrato delle distanze tra ciascun punto dati e il suo baricentro all'interno di un gruppo1 analogamente per gli altri due termini nella formula precedente.
Passi coinvolti nel metodo del gomito:
- K- significa che il clustering viene eseguito per diversi valori di k (a partire dal 1 un 10).
- Il WCSS è calcolato per ogni gruppo.
- Viene disegnata una curva tra i valori WCSS e il numero di cluster k.
- Il punto di piegatura acuto o un punto di cornice sembra un braccio, allora quel punto è considerato come il miglior valore di K.
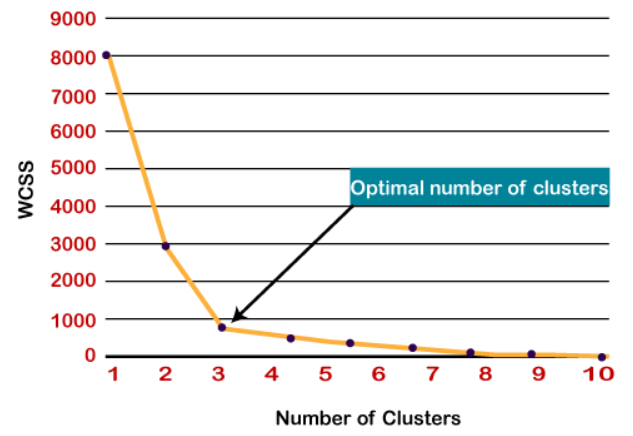
Ecco, come possiamo vedere, una curva ripida è a k = 3, quindi il numero ottimale di gruppi è 3.
Punteggio silhouette Metodo per trovare 'k’ numero di cluster
Il valore della silhouette è una misura di quanto un oggetto sia simile al proprio gruppo (coesione) rispetto ad altri gruppi (separazione). La silhouette varia da -1 un +1, dove un valore alto indica che l'oggetto corrisponde bene al proprio gruppo e non a gruppi vicini. Se la maggior parte degli oggetti ha un valore alto, allora la configurazione del raggruppamento è appropriata. Se molti punti hanno un valore basso o negativo, allora la configurazione del clustering potrebbe avere troppi o troppo pochi cluster.
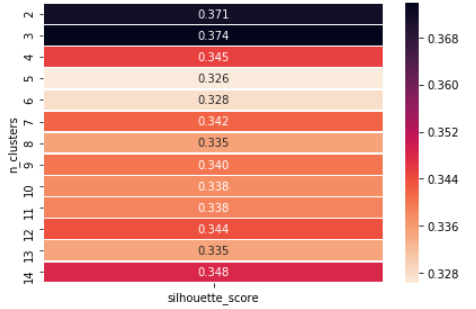
Esempio che mostra come possiamo scegliere il valore di 'k', poiché possiamo vedere che in n = 3 abbiamo il punteggio massimo della silhouette, così, scegliamo il valore di k = 3.
Vantaggi dell'utilizzo del clustering k-means
- Facile da implementare.
- Con un gran numero di variabili, Le K-Means possono essere computazionalmente più veloci del raggruppamento gerarchico (se K è piccolo).
- K-mean possono produrre cluster più alti rispetto ai cluster gerarchici.
Svantaggi dell'utilizzo del clustering k-means
È difficile prevedere il numero di cluster (valore K).
I semi iniziali hanno un forte impatto sui risultati finali.
Implementazione pratica dell'algoritmo di clustering K-means usando Python (segmentazione della clientela bancaria)
Qui stiamo importando le librerie necessarie per la nostra analisi.
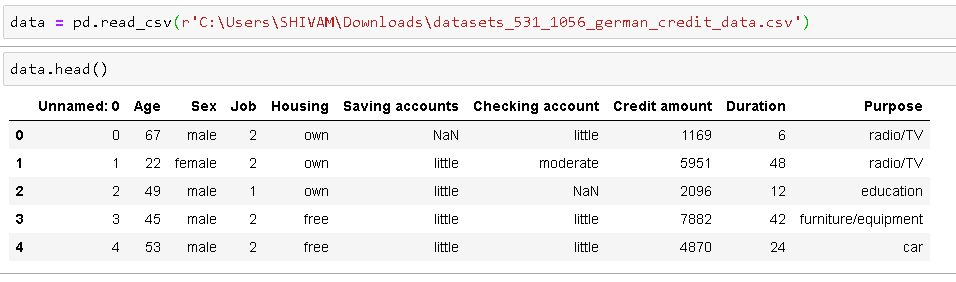
Leggi i dati e ottieni il 5 migliori osservazioni per dare un'occhiata al set di dati
Il codice per EDA non è stato incluso (Analisi esplorativa dei dati), L'EDA è stata eseguita con questi dati ed è stata eseguita un'analisi anomala per pulire i dati e renderli adatti alla nostra analisi..
Come sappiamo, Le medie K vengono eseguite solo su dati numerici, quindi scegliamo le colonne numeriche per la nostra analisi.

Ora, per eseguire il raggruppamento di k-mean come discusso in precedenza in questo articolo, dobbiamo trovare il valore del numero 'k’ di raggruppamenti e possiamo farlo usando il seguente codice, qui usiamo vari valori di k per il raggruppamento e poi selezioniamo usando il Metodo del gomito.

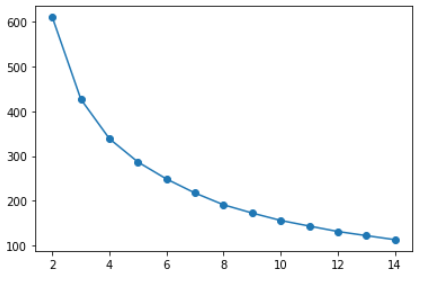
All'aumentare del numero di cluster, la varianza (somma dei quadrati all'interno del cluster) diminuisce. gomito dentro 3 oh 4 gruppi rappresenta l'equilibrio più parsimonioso tra la minimizzazione del numero di gruppi e la minimizzazione della varianza all'interno di ciascun gruppo, quindi possiamo scegliere un valore di k come 3 oh 4
Ora mostriamo come possiamo usare il metodo del valore della silhouette per trovare il valore di 'k'.

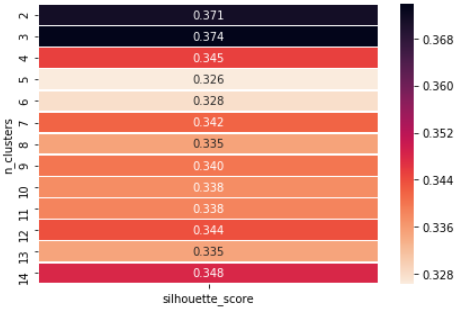
Se osserviamo, otteniamo il numero ottimale di cluster in n = 3, quindi possiamo finalmente scegliere il valore di k = 3.
Ora, adattare l'algoritmo di k significa usare il valore di k = 3 y trazar el mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate.... para los clústeres.
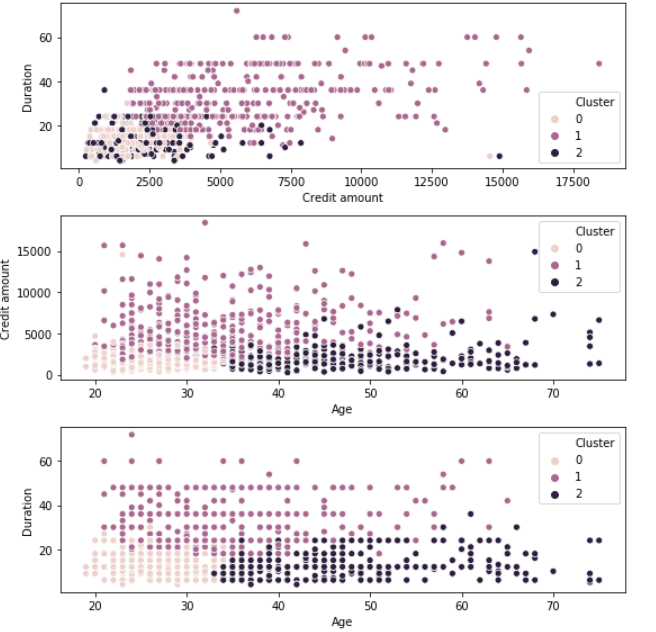

Analisi finale
Grappolo 0: giovani clienti che prendono in prestito a basso credito per un breve periodo
Gruppo 1: Clienti di mezza età che prendono in prestito un credito elevato per un periodo prolungato
Gruppo 2: Clienti più anziani che ottengono prestiti di credito medio per un breve periodo
conclusione
Abbiamo discusso di cosa sia il clustering, i loro tipi e la loro applicazione in diversi settori. Discutiamo di cosa sia il raggruppamento di k-mezzi, il funzionamento dell'algoritmo di raggruppamento di mezzi k, due metodi per selezionare il numero 'k’ di cluster, e i suoi vantaggi e svantaggi. Dopo, passiamo attraverso l'implementazione pratica dell'algoritmo di clustering k-means utilizzando il problema di segmentazione dei clienti bancari in Python.
Riferimenti:
(1) img (1) un'immagine (8) e [1] , riferimento preso da “K significa algoritmo di clustering”
https://www.javatpoint.com/k-means-clustering-algorithm-in-machine-learning





