- Scopri come costruire un modello di albero decisionale con Weka
- Questo tutorial è perfetto per i neofiti dell'apprendimento automatico e degli alberi decisionali, e per quelle persone che non si sentono a proprio agio con la programmazione.
introduzione
“Più grande è l'ostacolo, più gloria si ottiene vincendola”.
– Moliere
L'apprendimento automatico può intimidire le persone non tecniche. Tutti i lavori di machine learning sembrano richiedere una sana comprensione di Python (il R).
Quindi, In che modo i non programmatori ottengono esperienza di programmazione?? Non è un gioco da ragazzi!

Questa è la buona notizia: ci sono molti strumenti che ci consentono di eseguire attività di apprendimento automatico senza dover codificare. Puoi facilmente creare algoritmi come alberi decisionali da zero in una bellissima interfaccia grafica. Non è questo il sogno?? Questi strumenti, come mettere, ci aiutano principalmente ad affrontare due cose:
- Costruisci rapidamente un modello di apprendimento automatico, come albero decisionale, e capire come si sta comportando l'algoritmo. Questo può essere modificato in seguito e in base a
- Questo è l'ideale per mostrare al cliente / il tuo team di leadership con cosa stai lavorando
Questo articolo ti mostrerà come risolvere problemi di classificazione e regressione utilizzando alberi decisionali in Weka senza alcuna conoscenza di programmazione precedente!!
Ma se ti appassiona sporcarti le mani con la programmazione e l'apprendimento automatico, Ti suggerisco di seguire i seguenti corsi meravigliosamente selezionati:
Sommario
- Classificazione e regressione nell'apprendimento automatico
- Comprensione degli alberi decisionali
- Esplorare il set di dati in Weka
- Classificazione utilizzando l'albero decisionale in Weka
- ParametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... albero decisionale in Weka
- Visualizzazione di un albero decisionale in Weka
- Regressione usando l'albero decisionale in Weka
Classificazione e regressione nell'apprendimento automatico
Permettetemi prima di riassumere rapidamente cosa sono la classificazione e la regressione nel contesto di apprendimento automatico. È importante conoscere questi concetti prima di immergersi negli alberi decisionali.
UN classificazione guaio si tratta di insegnare al tuo modello di machine learning come classificare un valore di dati in una delle tante classi. Lo fa imparando le caratteristiche di ogni tipo di classe. Ad esempio, per prevedere se un'immagine è di un gatto o di un cane, Il modello apprende le caratteristiche del cane e del gatto nei dati di addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.....
UN regressione guaio si tratta di insegnare al tuo modello di apprendimento automatico come prevedere il valore futuro di una quantità continua. Lo fa imparando il modello della quantità nel passato influenzato da diverse variabili.. Ad esempio, un modello che tenta di prevedere il prezzo futuro delle azioni di una società è un problema di regressione.
Potete trovare questi due problemi in abbondanza nel nostro Piattaforma DataHack.
Ora, impariamo a conoscere un algoritmo che risolve entrambi i problemi: Alberi decisionali!
Comprensione degli alberi decisionali
Alberi decisionali sono anche conosciuti come Classificazione e alberi di regressione (CARRELLO). Funzionano imparando le risposte a una gerarchia di domande se / se non questo porta a una decisione. Queste domande formano una struttura ad albero, e da qui il nome.
Ad esempio, diciamo di voler prevedere se una persona ordinerà del cibo oppure no. Possiamo visualizzare il seguente albero decisionale per questo:
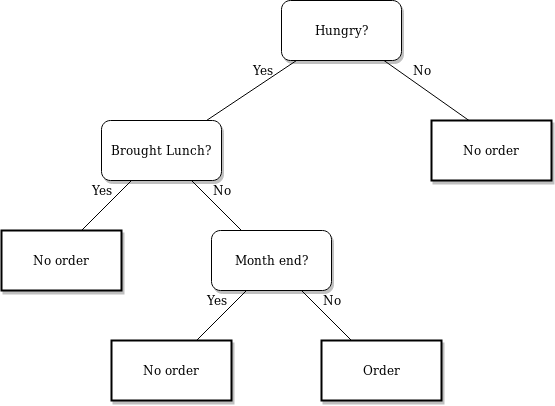
Ogni nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... dell'albero rappresenta una domanda derivata dalle caratteristiche presenti nel set di dati. Il tuo set di dati viene diviso in base a queste domande fino a raggiungere la profondità massima dell'albero.. L'ultimo nodo non fa una domanda, rappresenta a quale classe appartiene il valore.
- Viene chiamato il nodo superiore dell'albero decisionale Rnodo oot
- Il nodo più basso è chiamato leaf nodo
- Un nodo diviso in sottonodi si chiama Nodo padre. I sottonodi sono chiamati nodi secondari
Se vuoi capire in dettaglio gli alberi decisionali, Ti suggerisco di dare un'occhiata alle seguenti risorse:
Cos'è Weka? Perché dovresti usare Weka per l'apprendimento automatico??
“Mettere è un software open source gratuito con una gamma di algoritmi di apprendimento automatico incorporati a cui è possibile accedere tramite un'interfaccia utente grafica. “
WEKA Rappresenta Ambiente Waikato per l'analisi della conoscenza ed è stato sviluppato presso l'Università di Waikato, Nuova Zelanda.
Weka ha più funzioni integrate per implementare un'ampia gamma di algoritmi di apprendimento automatico, dalla regressione lineare a neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti... Ciò ti consente di implementare gli algoritmi più complessi nel tuo set di dati con il clic di un pulsante!! Non solo questo, Weka fornisce supporto per l'accesso ad alcuni dei più comuni algoritmi di libreria di machine learning Python e R!
Con Weka puoi pretrattare i dati, classificarli, raggruppali e persino visualizzali. Questo può essere fatto in diversi formati di file di dati come ARFF, CSV, C4.5 e JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software... Weka ti consente persino di aggiungere filtri al tuo set di dati attraverso i quali puoi normalizzare i tuoi dati., standardizzarli, funzioni di scambio tra valori nominali e numerici, e altro ancora!
Potrei continuare sulla meraviglia che è Weka, ma per lo scopo di questo articolo, proviamo ad esplorare Weka in modo pratico creando un albero decisionale. Ora vai avanti e scarica Weka dal tuo Sito ufficiale!
![]()
Esplorare il set di dati in Weka
Prenderò il set di dati sul cancro al seno da Repository di machine learning UCI. Ti consiglio di leggere il problema prima di procedere oltre..
Carichiamo prima il set di dati in Weka. Fare quello, segui i passaggi seguenti:
- Apri la GUI di Weka
- Seleziona il “Esploratore” opzione.
- Si prega di selezionare “Apri documento” e scegli il tuo set di dati.
La tua finestra Weka dovrebbe ora assomigliare a questa:
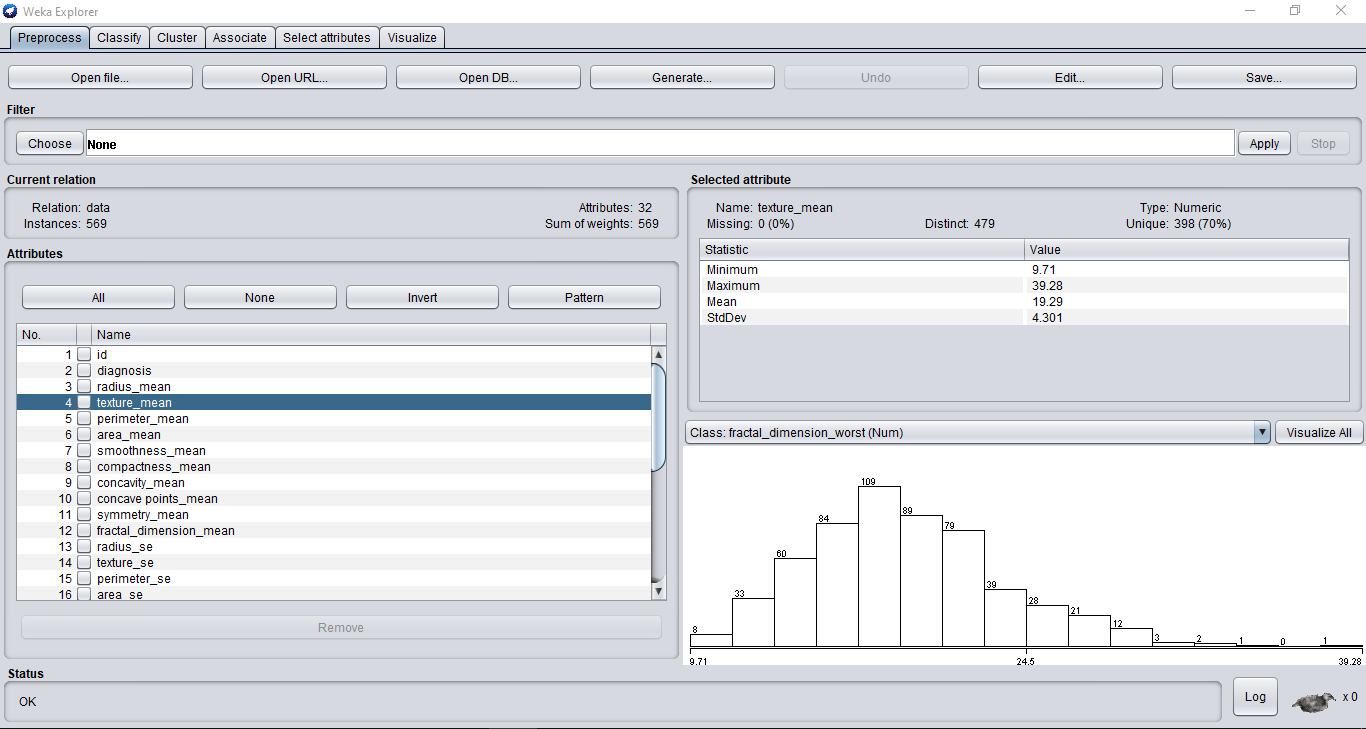
Puoi vedere tutte le funzioni nel tuo set di dati sul lato sinistro. Weka crea automaticamente grafici per le sue funzionalità che noterai in misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... che naviga tra le sue funzionalità.
Puoi anche vedere tutti i pacchi insieme se fai clic su “Mostra tutto” pulsante.
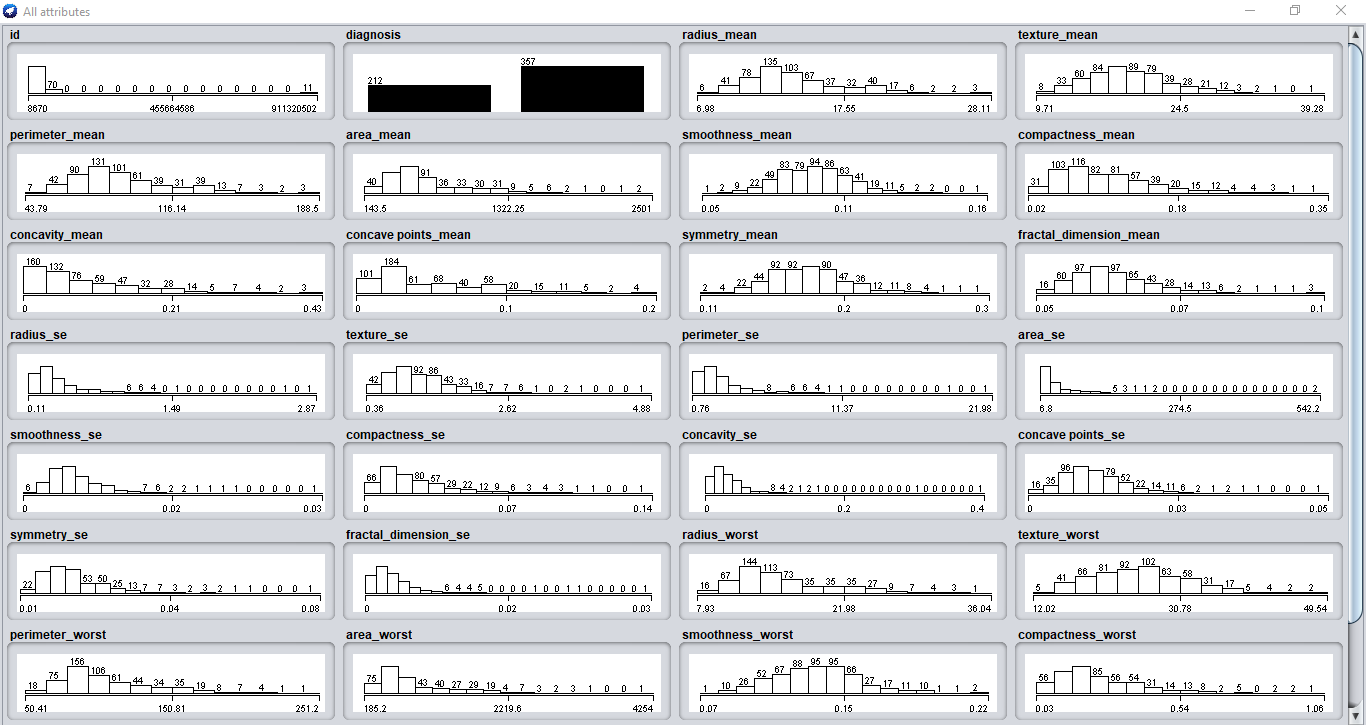
Ora alleniamo il nostro modello di classificazione!
Classificazione utilizzando Albero decisionale in Weka
L'implementazione di un albero decisionale in Weka è abbastanza semplice. Basta completare i seguenti passaggi:
- Clicca sul “Organizzare” scheda in alto
- Clicca sul “Scegliere” pulsante
- Nell'elenco a discesa, Selezionare “alberi” che aprirà tutti gli algoritmi nell'albero
- Finalmente, Selezionare il “RepTree” albero decisionale
"Errore ridotto durante la potatura dell'albero" (RepTree) è uno studente veloce dell'albero delle decisioni che costruisce un albero delle decisioni / regressione usando guadagno di informazioni come criterio di divisione e lo ha potato utilizzando un algoritmo di potatura a errore ridotto “.

“L'albero decisionale divide i nodi in tutte le variabili disponibili e quindi seleziona la divisione che risulta nei sottonodi più omogenei”.
Il guadagno di informazioni viene utilizzato per calcolare l'omogeneità del campione in una divisione.
Puoi selezionare il tuo ruolo target dal menu a discesa appena sopra il “Cominciare” pulsante. Se non lo fai, WEKA seleziona automaticamente l'ultima funzione come obiettivo per te.
il “Divisione percentuale” specifica la quantità di dati che si desidera conservare per addestrare il classificatore. Il resto dei dati viene utilizzato durante la fase di test per calcolare la precisione del modello..
Insieme a “Piegatura con convalida incrociata” può creare più campioni (o pieghe) dal set di dati di allenamento. Se decidi di creare N pieghe, il modello viene eseguito iterativamente N volte. E ogni volta che una delle pieghe viene trattenuta per la convalida, mentre le rimanenti N-1 pieghe vengono utilizzate per addestrare il modello. Viene calcolata la media del risultato di tutte le pieghe per ottenere il risultato della convalida incrociata.
Maggiore è il numero di pieghe di convalida incrociata che usi, migliore sarà il tuo modello. Questo fa sì che il modello venga addestrato su dati selezionati casualmente, cosa lo rende più robusto?.
Finalmente, premi il “Cominciare” Pulsante per il classificatore per fare la sua magia!!

Il nostro classificatore ha una precisione di 92,4%. Weka stampa anche il Matrice di confusione per te, cosa offre metriche diverse. Puoi studiare la matrice di confusione e altre metriche in dettaglio qui.
Parametri dell'albero decisionale in Weka
Gli alberi decisionali hanno molti parametri. Possiamo regolarli per migliorare le prestazioni complessive del nostro modello. È qui che la conoscenza pratica degli alberi decisionali gioca davvero un ruolo cruciale..
Puoi accedere a questi parametri facendo clic sull'algoritmo dell'albero decisionale in alto:

Parliamo brevemente dei parametri principali:
- Profondità massima I– Determina la profondità massima del tuo albero decisionale. Per impostazione predefinita, è -1, il che significa che l'algoritmo controllerà automaticamente la profondità. Ma puoi modificare manualmente questo valore per ottenere i migliori risultati sui tuoi dati.
- non poteva – Potatura significa ridurre automaticamente un nodo foglia che non contiene molte informazioni. Ciò rende l'albero decisionale semplice e di facile interpretazione..
- numFolds – Il numero specificato di pieghe di dati verrà utilizzato per sfoltire l'albero decisionale. Il resto servirà a far crescere le regole.
- minNum – Numero minimo di istanze per foglio. Se non menzionato, l'albero continuerà a dividersi finché tutti i nodi foglia non avranno una sola classe associata.
Puoi sempre sperimentare valori diversi per questi parametri per ottenere la massima precisione nel tuo set di dati..
Visualizzazione dell'albero decisionale in Weka
Weka ti consente persino di visualizzare facilmente l'albero decisionale costruito sul tuo set di dati.:
- Vai al “Elenco dei risultati” sezione e fare clic con il pulsante destro del mouse sull'algoritmo addestrato
- Scegli il “Visualizza albero” opzione

Il tuo albero decisionale apparirà come sotto:

Interpretare questi valori può essere un po' intimidatorio, ma in realtà è abbastanza facile una volta che ci prendi la mano.
- I valori delle linee che uniscono i nodi rappresentano i criteri di divisione in base ai valori della funzione nodo principale.
- Nel nodo foglia:
- Il valore prima delle parentesi indica il valore del rango.
- Il primo valore tra le prime parentesi è il numero totale di istanze del training set su quel foglio. Il secondo valore è il numero di istanze classificate erroneamente su quel foglio.
- Il primo valore nella seconda parentesi è il numero totale di istanze del set di potatura su quel foglio. Il secondo valore è il numero di istanze classificate erroneamente su quel foglio.
Regressione usando l'albero decisionale in Weka
Come ho detto prima, gli alberi decisionali sono così versatili che possono funzionare sia in problemi di classificazione che di regressione. Per questo, userò il “Pronostica il numero di voti a favore“problema di Piattaforma DataHack di DataPeaker.
Qui, dobbiamo prevedere la valutazione di una domanda posta da un utente su una piattaforma di domande e risposte.
Come di solito, inizieremo caricando il file di dati. Ma questa volta, i dati contengono anche a “ID” colonna per ogni utente nel set di dati. Questo non sarebbe utile nella previsione. Quindi, elimineremo questa colonna selezionando il “Rimuovere” opzione sotto i nomi delle colonne:

Possiamo fare previsioni sul set di dati come abbiamo fatto per il Problema cancro al seno. RepTree rileverà automaticamente il problema di regressione:

La metrica di valutazione fornita nell'hackathon è il punteggio RMSE. Possiamo vedere che il modello ha un RMSE molto scarso senza alcuna ingegneria delle funzionalità. È qui che entra in gioco: avanti, sperimentare e migliorare il modello finale!
Note finali
E così, Hai creato un modello di albero decisionale senza dover eseguire alcuna programmazione! Questo sarà di grande aiuto nella tua ricerca per padroneggiare il funzionamento dei modelli di apprendimento automatico..
Se vuoi imparare ed esplorare la parte di programmazione del machine learning, Ti consiglio di seguire questi corsi meravigliosamente selezionati sul Vidhya Analytics sito web:





