Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
Panoramica
- Scopri di più sull'algoritmo dell'albero decisionale in Machine Learning per i problemi di classificazione.
- Qui abbiamo coperto l'entropia, il guadagno di informazioni e l'impurità di Gini
Algoritmo dell'albero decisionale
algoritmi. Quella può essere utilizzato sia per un problema di classificazione che per un problema di regressione.
L'obiettivo di questo algoritmo è creare un modello che preveda il valore di una variabile di destinazione., per i quali l'albero decisionale utilizza la rappresentazione ad albero per risolvere il problema in cui il nodo foglia corrisponde a un tag di classe e gli attributi sono rappresentati sul nodo interno. dell'albero.
Prendiamo un set di dati di esempio per avanzare ulteriormente ....
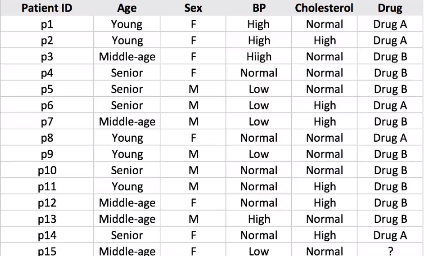
Supponiamo di avere un campione di 14 set di dati dei pazienti e dobbiamo prevedere quale farmaco suggerire al paziente A o B.
Diciamo che scegliamo il colesterolo come primo attributo per dividere i dati.
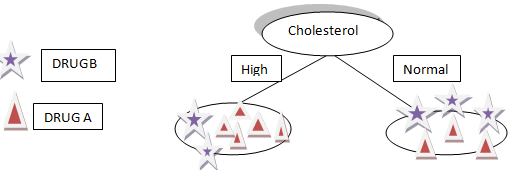
Dividerà i nostri dati in due rami Alto e Normale in base al colesterolo, como puede ver en la figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... anteriore.
Supponiamo che il nostro nuovo paziente abbia il colesterolo alto a causa della precedente divisione dei nostri dati che non possiamo dire. o Il farmaco B o il farmaco A saranno adatti al paziente.
Cosa c'è di più, se il colesterolo del paziente è normale, non abbiamo ancora un'idea o informazioni per determinare se il farmaco A o il farmaco B è giusto per il paziente.
Prendiamo un'altra età degli attributi, come possiamo vedere, L'età ha tre categorie: Giovane, medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... edad y mayor, Proviamo a dividere.
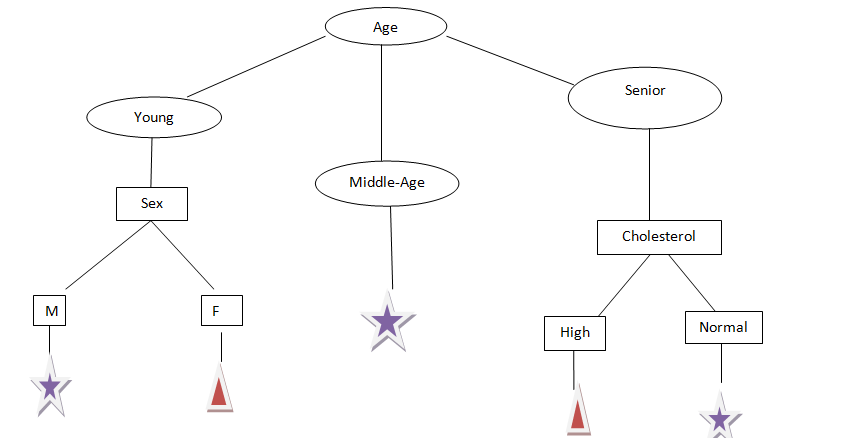
Dalla figura precedente, Ora possiamo dire che possiamo facilmente prevedere quale farmaco somministrare a un paziente in base ai loro rapporti..
Ipotesi che facciamo quando usiamo l'albero decisionale:
– All'inizio, consideramos todo el conjunto de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... como la raíz.
-I valori caratteristici sono preferiti per essere categorici, Se i valori continuano, vengono convertiti in discreti prima di costruire il modello.
-In base ai valori degli attributi, I record sono distribuiti in modo ricorsivo.
-Utilizamos un método estadístico para ordenar atributos como nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... raíz o nodo interno.
Matematica dietro l'algoritmo dell'albero decisionale: Prima di passare al guadagno delle informazioni, Per prima cosa dobbiamo capire l'entropia.
entropia: entropia sono le misure di impurità, disordine, oh incertezza in molti esempi.
Scopo dell'entropia:
L'entropia controlla il modo in cui un albero decisionale decide spezzare i dati. Influisce sul modo in cui un Albero decisionale Disegna i tuoi confini.
"I valori di entropia vanno da 0 fino a 1", meno il valore dell'entropia è più affidabile.

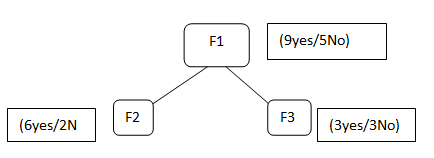
Supponiamo di avere caratteristiche F1, F2, F3, selezioniamo la funzione F1 come nodo principale
F1 contiene 9 etichetta sì e 5 nessuna etichetta, dopo aver diviso la F1 otteniamo F2 che ha 6 sì / 2 No e F3 hai 3 sì / 3 no.
Ora, se proviamo a calcolare l'Entropia di entrambi F2 usando la formula dell'Entropia …
Inserimento di valori nella formula:
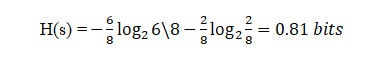
Qui, 6 è il numero di sì preso come positivo poiché stiamo calcolando la probabilità divisa per 8 è il numero totale di righe presenti in F2.
Nello stesso modo, se eseguiamo l'entropia per F3 otterremo 1 bit che è un caso di un attributo poiché in esso ci sono 50%, Sì e 50% no.
Questa divisione continuerà a meno che e fino a quando non otteniamo un sottoinsieme puro..
Cos'è un sottoinsieme Pure.?
Il sottoinsieme puro è una situazione in cui otterremo tutti sì o tutti i no in questo caso.
Lo abbiamo fatto rispetto a un nodo, Cosa succede se dopo aver diviso F2 possiamo anche richiedere qualche altro attributo per arrivare al nodo foglia e dobbiamo anche prendere l'entropia di quei valori e aggiungerli per inviare tutti quei valori di entropia per quello? Abbiamo il concetto di guadagno di informazioni.
Guadagno di informazioni: Il guadagno di informazioni viene utilizzato per decidere in quale funzione dividersi in ogni fase della costruzione dell'albero.. La semplicità è la cosa migliore, Ecco perché vogliamo che il nostro albero sia piccolo. Per farlo, Ad ogni passo dobbiamo scegliere la divisione che risulta nei nodi figlio più puri. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... de pureza comúnmente utilizada se llama información.
Per ogni nodo della struttura, Il valore dell'informazione misura la quantità di informazioni fornite da una caratteristica di classe. La divisione con il maggior guadagno di informazioni sarà presa come prima divisione e il processo continuerà fino a quando tutti i nodi figlio sono puri o fino a quando il guadagno di informazioni non sarà 0.
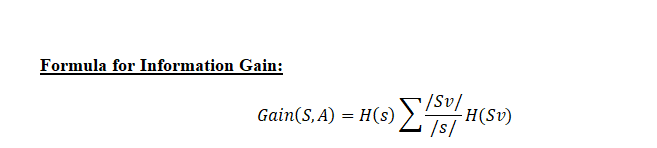
L'algoritmo calcola il guadagno di informazioni per ogni divisione e seleziona la divisione che dà il valore più alto di guadagno di informazioni.
Possiamo dire che in Information Gain calcoleremo la media di tutta l'entropia in funzione della divisione specifica..
Sv = Campione totale dopo la divisione come in F2 ci sono 6 sì
S = Campione totale come in F1 = 9 + 5 = 14
Ora calcolando il guadagno di informazioni:
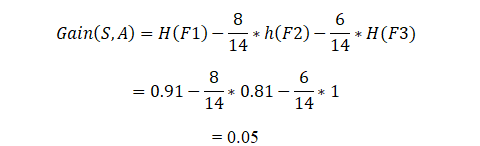
In questo modo, L'algoritmo eseguirà questa operazione per n numero di divisioni, e il guadagno di informazioni per la divisione che è maggiore lo porterà a costruire l'albero decisionale.
Maggiore è il valore del guadagno informativo della divisione, Maggiore è la probabilità che venga selezionato per la particolare divisione.
Gini impurità:
L'impurità di Gini è una misura utilizzata per costruire alberi decisionali per determinare come le caratteristiche di un set di dati dovrebbero dividere i nodi per formare l'albero.. Più precisamente, l'impurità di Gini di un set di dati è un numero compreso tra 0-0,5, Indicare la probabilità che i dati nuovi e casuali vengano classificati in modo errato se viene assegnata un'etichetta di classe casuale in base alla distribuzione della classe nel set di dati.
Entropia vs impurità di Gini
Il valore massimo di entropia è 1, mentre il valore massimo di impurità di Gini è 0,5.
Come il Gini Impurit
In questo articolo, Abbiamo coperto molti dettagli sull'albero decisionale, Come funziona e la matematica dietro di esso, misure di selezione degli attributi come Entropia, Guadagno di informazioni, Impurità di Gini con le sue formule e come l'algoritmo di apprendimento automatico lo risolve.
In questa fase, Spero che tu abbia un'idea dell'albero decisionale, Uno dei migliori algoritmi di apprendimento automatico per risolvere un problema di classificazione.
Come nuovo, Ti consiglio di imparare queste tecniche e capire la loro implementazione e poi implementarle nei tuoi modelli..
per una migliore comprensione, Vedi HTTPS://scikit-learn.org/stable/modules/tree.html
Il supporto mostrato in questo articolo non è di proprietà di Analytics Vidhya e viene utilizzato a discrezione dell'autore.





