Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati

introduzione
Apprendimento. La regressione logistica viene generalmente utilizzata quando dobbiamo classificare i dati in due o più classi. Uno è binario e l'altro è una regressione logistica a classi multiple. Come suggerisce il nome, la classe binaria ha 2 classi che sono Sì / No, Vero / Impostore, 0/1, eccetera. Nella classificazione di più classi, c'è di più 2 classi per classificare i dati. Ma, prima di andare, definiamo prima la regressione logistica:
“La regressione logistica è un algoritmo di classificazione per variabili categoriali come Sì / No, Vero / Impostore, 0/1, eccetera.”
In cosa differisce dalla regressione lineare??
Potresti anche aver sentito parlare di regressione lineare. Lascia che ti dica che c'è una grande differenza tra regressione lineare e regressione logistica. La regressione lineare viene utilizzata per generare valori continui come il prezzo della casa, reddito, la popolazione, eccetera. Nella regressione logistica, generalmente calcoliamo la probabilità che si trova tra l'intervallo 0 e 1 (entrambi inclusi). Quindi la probabilità può essere utilizzata per classificare i dati. Ad esempio, se la probabilità calcolata risulta essere maggiore di 0,5, quindi i dati appartenevano alla classe A e, altrimenti, per meno di 0,5, i dati appartenevano alla classe B.
Ma la mia domanda è se possiamo ancora usare la regressione lineare per la classificazione. La mia risposta sarà "Sì!! Perchè no? Ma certo è un'idea assurda". La mia ragione sarà che puoi assegnare un valore di soglia per la regressione lineare, vale a dire, se il valore previsto è maggiore del valore di soglia, apparteneva alla classe A; altrimenti, alla classe B. Ma darà un grande errore e un modello scadente con bassa precisione, che davvero non vogliamo. Destra? Ti suggerisco di utilizzare solo algoritmi di ordinamento.
Ora diamo un'occhiata al grafico di regressione lineare mostrato di seguito.
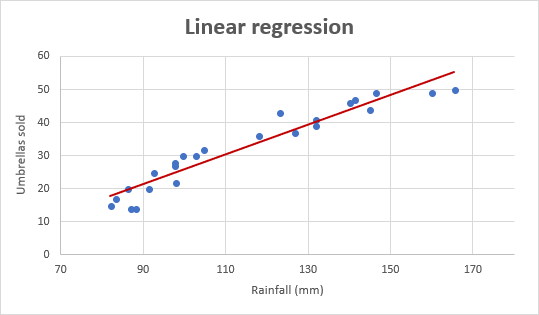
(Cortesia: https://www.ablebits.com/)
Il grafico è una retta che passa per alcuni punti poiché evitiamo sempre curve di overfitting e di misfitting.
Ora diamo un'occhiata al grafico di regressione logistica:
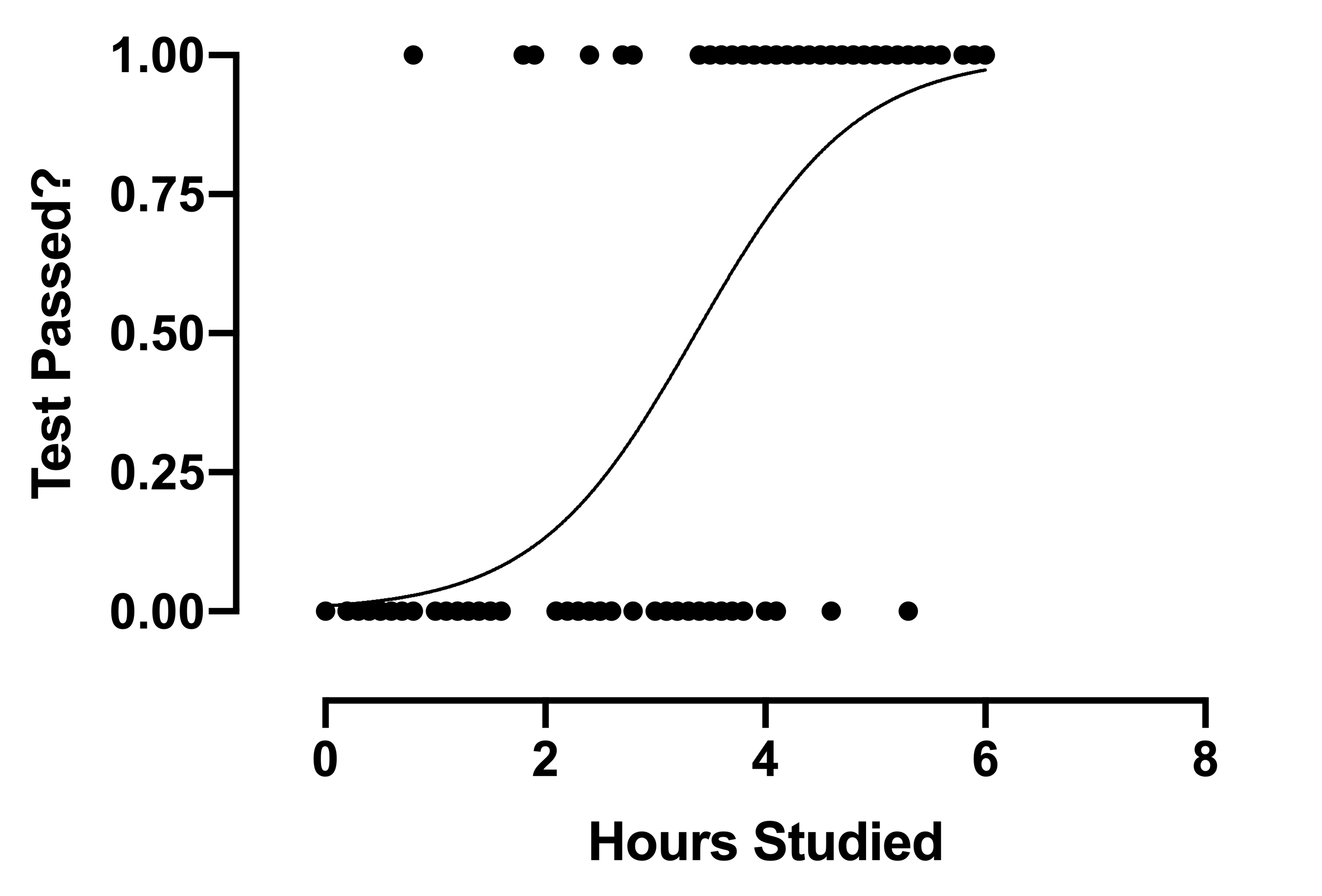
Il grafico è una linea curva invece di una linea retta, a differenza della regressione lineare.
Questa è una grande differenza tra i due tipi di regressione di cui abbiamo appena parlato.. Quindi la mia prossima domanda è.
Perché abbiamo una linea curva per la regressione logistica invece di una linea retta??
Per rispondere a questa domanda, cammineremo un po' attraverso la regressione lineare e da lì arriveremo alla curva di regressione logistica. Va bene? Iniziamo.
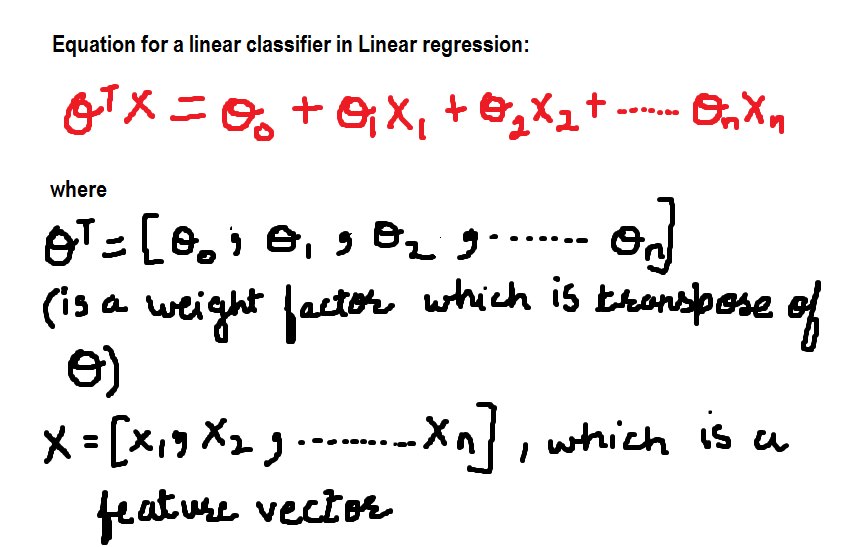
Per adesso, l'equazione per il classificatore lineare è:
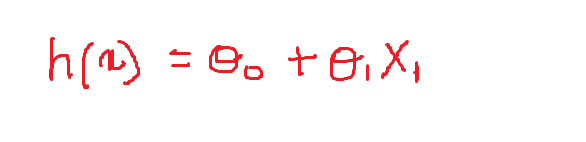
Ora definiremo i valori delle variabili pesi:
theta_0 = -1 e theta = 0.1
Quindi, La nostra equazione ha questo aspetto e il seguente è il grafico che rappresenta l'equazione nel piano 2-D:
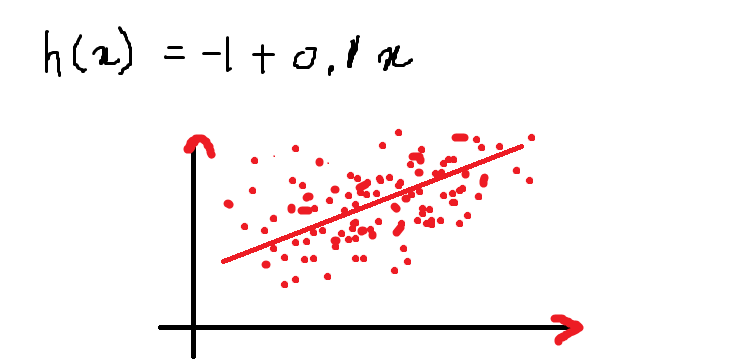
Sopra è un'equazione di una linea per l'equazione data:
h (X) = – 1 + 0.1X
Il valore della funzione h (X) quando x = 13 è:
h (13) = – 1+ (0,1) * (13) = 0,3
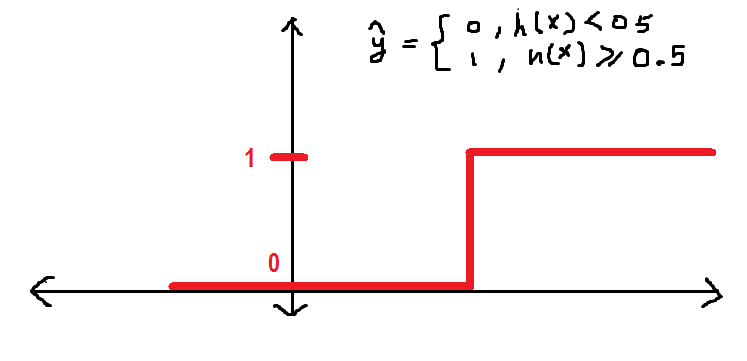
Come descritto in precedenza in questo articolo, Sto definendo la soglia in 0.5, che è un qualsiasi valore di h maggiore di (uguale a) 0.5 sarà etichettato come 1 e, altrimenti, 0. Possiamo definirlo come segue sotto forma di funzione a gradino:

Ora, d'accordo con questo, h ha un valore di 0.3, quindi il valore di y_hat = 0 secondo la funzione sopra definita.
Ora, Una cosa che dovresti notare qui che ogni valore maggiore di 0.5, supponiamo di dire che il valore di 'h’ è 1000 per qualche valore di x, allora sarà etichettato come 1 soltanto, non c'è differenza tra il valore 1 e 1000 poiché entrambi sono classificati come 1 soltanto. È giusto? Possiamo accettare questa soluzione?? Beh no! non lo accetterei !!!
Un'altra cosa, Qual è la probabilità che h abbia un valore di 0.3? Tutte queste domande rimangono senza risposta. Per queste ragioni, gli scienziati dei dati non preferiscono utilizzare la regressione lineare per scopi di classificazione.
prima di continuare, Voglio mostrarti come si comporta graficamente la funzione y_hat:
Sarebbe meglio se avessimo una curva più liscia invece di quella sopra. Vedremo:
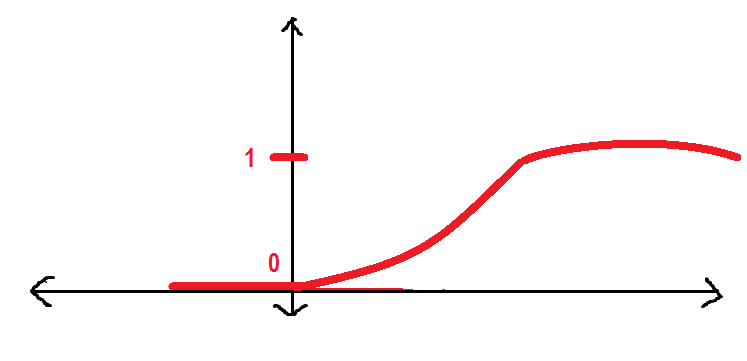
La curva sopra è nota come Funzione sigmoide che useremo in questo articolo. Qui introdurrò la funzione sigmoide.
Cos'è la funzione sigmoide??
La funzione sigmoide è rappresentata dal simbolo sigma. Su comportamiento gráfico se ha descrito en la figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... anteriore. L'equazione matematica per la funzione sigmoide è descritta di seguito:
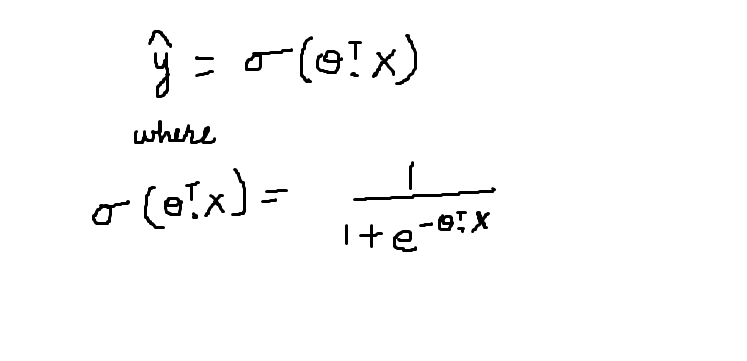
La funzione sigmoide fornisce la probabilità che i dati appartengano a una particolare classe che si trova nell'intervallo [0,1]. Accetta il prodotto scalare della trasposizione theta e il vettore delle caratteristiche X come parametro. Il valore risultante è la probabilità.
Perciò, quando P (Y = 1 | X) = sigmoide (theta * X)
P (Y = 0 | X) = 1- sigmoide (theta * X)
Cosa c'è di più, Voglio che tu osservi il comportamento della funzione sigmoide:
- Quando theta (trasposizione) * X diventa molto più grande, il valore del sigmoide diventa uguale a 1
- quando theta (trasposizione) * X diventa molto piccolo il valore sigmoideo diventa uguale a 0
Applicazioni della regressione logistica
In questa sezione, Vorrei discutere alcune delle applicazioni della regressione logistica.
1. Prevedere la probabilità che una persona abbia un infarto
2. Prevedere la propensione di un cliente ad acquistare un prodotto o sospendere un abbonamento.
3. Prevedere la probabilità di fallimento di un dato processo o prodotto.
Prima di finire questo articolo, Voglio solo ricapitolare quando dovresti usare la regressione logistica:
- Quando i tuoi dati sono binari: 0/1, Vero / Impostore, sì / No
- Quando hai bisogno di risultati probabilistici
- Quando i tuoi dati possono essere separati linearmente
- Quando hai bisogno di capire l'impatto della funzione.
Molti altri algoritmi di classificazione sono ampiamente utilizzati oltre alla regressione logistica come kNN, alberi decisionali, foresta casuale e algoritmi di clustering come clustering di k-means. Ma la regressione logistica è un algoritmo ampiamente utilizzato e anche facile da implementare..
Quindi si trattava di algoritmi di regressione logistica per principianti. Abbiamo parlato di tutto quello che c'è da sapere sulla teoria della regressione logistica. Spero che il mio articolo ti sia piaciuto!!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





