Panoramica:
Questo articolo KNN è per:
Comprendere la rappresentazione e la previsione dell'algoritmo K più vicino (KNN).
Capire come scegliere il valore K e la metrica della distanza.
Metodi di preparazione dei dati richiesti e vantaggi e svantaggi dell'algoritmo KNN.
Implementazione di Python e pseudocodice.
introduzione:
K El algoritmo del vecino más cercano se incluye en la categoría de apprendimento supervisionatoL'apprendimento supervisionato è un approccio di apprendimento automatico in cui un modello viene addestrato utilizzando un set di dati etichettati. Ogni input nel set di dati è associato a un output noto, consentendo al modello di imparare a prevedere i risultati per nuovi input. Questo metodo è ampiamente utilizzato in applicazioni come la classificazione delle immagini, Riconoscimento vocale e previsione delle tendenze, sottolineandone l'importanza in... y se usa para clasificación (più comunemente) e regressione. È un algoritmo versatile che viene utilizzato anche per imputare i valori mancanti e ricampionare i set di dati.. Come suggerisce il nome (K vicino più prossimo), considera K vicini più prossimi (punti dati) per prevedere la classe o il valore continuo per il nuovo punto dati.
Imparare l'algoritmo è:
1. Apprendimento basato sull'istanza: aquí no aprendemos ponderaciones de los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... para predecir la salida (come negli algoritmi basati su modelli), invece usiamo istanze di addestramento complete per prevedere l'output di dati non visti.
2. Apprendimento pigro: il modello non viene appreso utilizzando i dati di addestramento prima e il processo di apprendimento viene posticipato a un momento in cui viene richiesta la previsione nella nuova istanza.
3. in parametrico: UN KNN, non esiste una forma predefinita di funzione di mappatura.
Come funziona KNN??
-
Inizio:
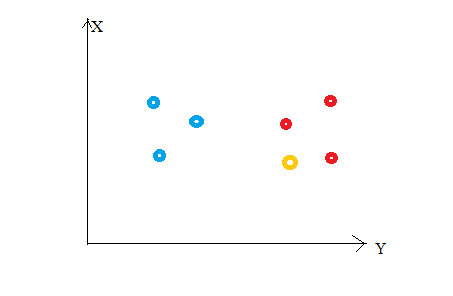
Considere la siguiente figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline..... Supponiamo di aver tracciato punti dati dal nostro set di addestramento in uno spazio di funzionalità bidimensionale. Come mostrato, abbiamo un totale di 6 punti dati (3 rosso e 3 blu). I punti dati rossi appartengono a "class1"’ e i punti dati blu appartengono a 'class2'. E il punto dati giallo in uno spazio delle caratteristiche rappresenta il nuovo punto per il quale deve essere prevista una classe. Ovviamente, diciamo che appartiene a 'class1'’ (puntini rossi)
Come mai?
Perché i tuoi vicini più prossimi appartengono a quella classe!!

sì, questo è il principio alla base di K Neighbors Neighbors. Qui, i vicini più vicini sono quei punti dati che hanno una distanza minima nello spazio delle caratteristiche dal nostro nuovo punto dati. E K è il numero di punti dati che consideriamo nella nostra implementazione dell'algoritmo. Perciò, la metrica della distanza e il valore K sono due considerazioni importanti quando si utilizza l'algoritmo KNN. La distanza euclidea è la metrica di distanza più popolare. Puoi anche usare la distanza di Hamming, la distanza da Manhattan, la distanza Minkowski secondo le vostre esigenze. Per prevedere la classe / valore continuo per un nuovo punto dati, considera tutti i punti dati nel set di dati di addestramento. Trova i vicini più vicini (punti dati) 'K’ dei nuovi punti dati dello spazio delle caratteristiche e delle relative etichette di classe o valori continui.
Dopo:
Per la classificazione: un'etichetta di classe assegnata al maggior numero di K vicini più prossimi nel set di dati di addestramento è considerata una classe prevista per il nuovo punto dati.
Per la regressione: la media o medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... de los valores continuos asignados a K vecinos más cercanos del conjunto de datos de entrenamiento es un valor continuo predicho para nuestro nuevo punto de datos
-
Rappresentazione del modello
Qui, non impariamo i pesi e li memorizziamo, piuttosto l'intero set di dati di allenamento è archiviato in memoria. Perciò, la rappresentazione del modello per KNN è il set di dati di addestramento completo.
Come scegliere il valore di K?
K è un parametro cruciale nell'algoritmo KNN. Alcuni suggerimenti per la scelta di K Value sono:
1. Utilizzo delle curve di errore: La figura seguente mostra le curve di errore per diversi valori K per i dati di allenamento e test.
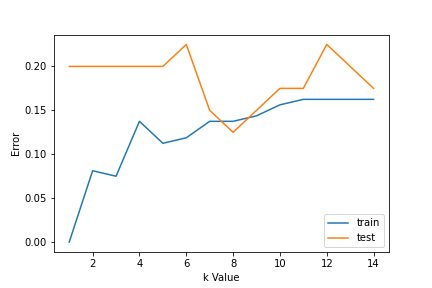
A bassi valori di K, c'è un sovradattamento dei dati / alta varianza. Perciò, l'errore del test è alto e l'errore del treno è basso. E K = 1 nei dati del treno, l'errore è sempre zero, perché il vicino più prossimo a quel punto è quel punto stesso. Perciò, anche se l'errore di addestramento è basso, l'errore di test è alto con valori K inferiori. Questo si chiama sovradattamento.. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que aumentamos el valor de K, l'errore di prova è ridotto.
Ma dopo un certo valore di K, viene introdotto il pregiudizio / la mancata corrispondenza e l'errore di test aumentano. Quindi, possiamo dire che inizialmente l'errore dei dati di test è alto (a causa della varianza), poi scende e si stabilizza e con un ulteriore aumento del valore di K, aumenta di nuovo (a causa di pregiudizi). Il valore di K quando l'errore di prova si stabilizza ed è basso è considerato il valore ottimale per K. Dalla curva di errore sopra, possiamo scegliere K = 8 per l'implementazione del nostro algoritmo KNN.
2. Cosa c'è di più, la conoscenza del dominio è molto utile per scegliere il valore K.
3. Il valore di K deve essere dispari quando si considera la classificazione binaria (due classi).
Preparazione dei dati richiesta:
1. Scala dei dati: per individuare il punto dati nello spazio delle caratteristiche multidimensionali, sarebbe utile se tutte le caratteristiche fossero sulla stessa scala. Perciò, il standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... o estandarización de los datos ayudará.
2. Riduzione della dimensionalità: KNN potrebbe non funzionare bene se ci sono troppe funzioni. Perciò, È possibile implementare tecniche di riduzione della dimensionalità come la selezione delle caratteristiche e l'analisi dei componenti principali.
3. Trattamento del valore mancante: Se le feature M mancano di dati da una feature per un particolare esempio nel set di allenamento, quindi non possiamo individuare o calcolare la distanza da quel punto. Perciò, È necessario eliminare tale riga o imputazione.
Implementazione Python:
Implementazione dell'algoritmo K del vicino più vicino utilizzando la libreria scikit-learn di Python:
passo 1: ottenere e preparare i dati
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
Dopo aver caricato librerie importanti, creiamo i nostri dati utilizzando sklearn.datasets con 200 campioni, 8 caratteristiche e 2 Lezioni. Dopo, i dati sono divisi sul treno (80%) e dati di prova (20%) e vengono ridimensionati utilizzando StandardScaler.
X,Y=make_classification(n_samples= 200,n_features=8,n_informative=8,n_redundant=0,n_repeated=0,n_classes=2,random_state=14) X_treno, X_test, y_train, y_test = train_test_split(X, E, test_size= 0.2,random_state=32) sc= Scala standard() sc.fit(X_treno) X_train= sc.transform(X_treno) sc.fit(X_test) X_test= sc.transform(X_test) X.forma
(200, 8)
passo 2: Trova il valore di K
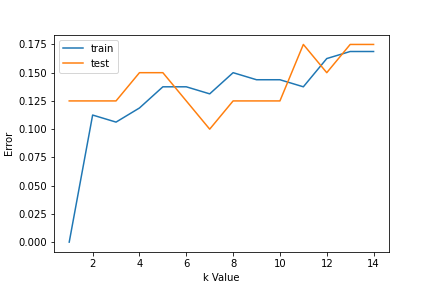
Per scegliere il valore K, usiamo curve di errore e valore K con varianza ottima, e l'errore di bias viene scelto come valore K per scopi di previsione. Con la curva di errore tracciata di seguito, scegliamo K = 7 per la previsione
errore1= []
errore2= []
per k nell'intervallo(1,15):
knn= KNeighborsClassifier(n_vicini=k)
knn.fit(X_treno,y_train)
y_pred1= knn.predict(X_treno)
errore1.append(np.significa(y_train!= y_pred1))
y_pred2= knn.predict(X_test)
errore2.append(np.significa(y_test!= y_pred2))
# plt.figure(figsize(10,5))
plt.trama(gamma(1,15),errore1,etichetta="treno")
plt.trama(gamma(1,15),errore2, etichetta="test")
plt.xlabel('Valore k')
plt.ylabel('Errore')
plt.legend()
passo 3: prevedere:
al passo 2, abbiamo scelto che il valore di K è 7. Ora sostituiamo quel valore e otteniamo il punteggio di precisione = 0,9 per i dati di prova.
knn= KNeighborsClassifier(n_vicini=7) knn.fit(X_treno,y_train) y_pred= knn.predict(X_test) metrics.accuracy_score(y_test,y_pred)
0.9
Pseudocodice per K vicino più vicino (classificazione):
Questo è uno pseudocodice per implementare l'algoritmo KNN da zero:
- Carica dati di allenamento.
- Preparare i dati utilizzando la bilancia, trattare i valori mancanti e ridurre la dimensionalità secondo necessità.
- Trova il valore ottimale per K:
- Prevedere un valore di classe per i nuovi dati:
- Calcola la distanza (X, Xi) di i = 1,2,3,…., n.
dove X = nuovo punto dati, Xi = dati di allenamento, distanza in base alla metrica della distanza scelta. - Ordina queste distanze in ordine crescente con i dati del treno corrispondenti.
- Da questa lista ordinata, seleziona le righe K’ superiore.
- Trova la classe più frequente di queste righe 'K’ scelto. Questa sarà la tua lezione programmata.
- Calcola la distanza (X, Xi) di i = 1,2,3,…., n.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





