Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
“Generative Adversarial Networks è l'idea più interessante degli ultimi dieci anni in Machine Learning” – Yann LeCun
introduzione
comprensione matematica e pratica di esso, ma prima, se vuoi dare un'occhiata alle basi di GAN, puoi continuare con il seguente link:
La maggior parte dei giganti della tecnologia (come Google, Microsoft, Amazon, eccetera.) stanno lavorando duramente per applicare i GAN all'uso pratico, alcuni di questi casi d'uso sono:
- Adobe: usando GAN per il tuo Photoshop di nuova generazione.
- Google: utilizzando GAN per la generazione del testo.
- IBM: uso del GAN per l'aumento dei dati (per generare immagini sintetiche per addestrare i tuoi modelli di classificazione).
- Scatta Chat / Tic toc: per creare più filtri immagine (che potresti aver già visto).
- Disney: uso de GAN para súper risoluzioneIl "risoluzione" si riferisce alla capacità di prendere decisioni ferme e raggiungere gli obiettivi prefissati. In contesti personali e professionali, Implica la definizione di obiettivi chiari e lo sviluppo di un piano d'azione per raggiungerli. La risoluzione è fondamentale per la crescita personale e il successo in vari ambiti della vita, In quanto ti permette di superare gli ostacoli e mantenere la concentrazione su ciò che conta davvero.... (miglioramento della qualità del video) per i tuoi film.
Qualcosa di speciale nei GAN è che queste aziende dipendono da loro per il loro futuro., Non credi??
Quindi, Cosa ti impedisce di acquisire la conoscenza di questa tecnologia epica? ti rispondo, qualunque, hai solo bisogno di un vantaggio e questo articolo lo farebbe. Discutiamo prima la matematica dietro Generator e Discriminator.
Operazione matematica del discriminatore:
L'unico scopo del Discriminatore è classificare le immagini vere e false. Per la classificazione, utiliza una convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. (CNN) tradizionale con una specifica funzione di costo. Il processo di formazione del discriminatore funziona come segue:
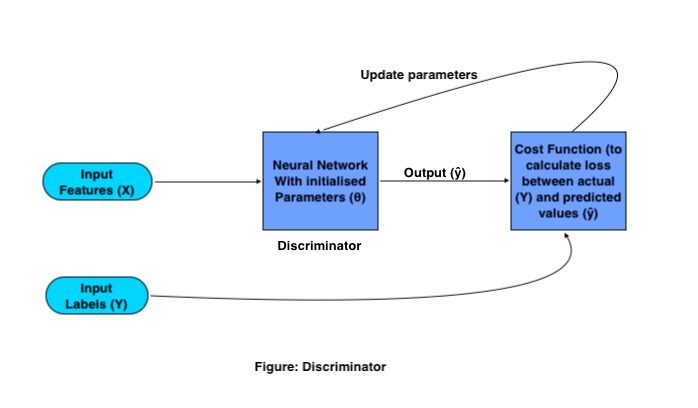
Dove X e Y sono rispettivamente caratteristiche ed etichette di input, l'uscita è rappresentata da (?) e il parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... de red se representan con (?).
Los GAN de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... necesitan un conjunto de imágenes de entrenamiento y sus respectivas etiquetas, queste immagini come funzionalità di input vanno alla CNN, con un set di parametri inizializzati. Questa CNN genera output moltiplicando la matrice del peso (W) con caratteristiche di ingresso (X) e aggiungendo un bias (B) en ella y convirtiéndola en una matriz no lineal pasándola a una funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.....
Questo output è noto come output previsto., quindi la perdita viene calcolata in base ai parametri di peso che vengono regolati nella rete per ridurre al minimo la perdita.
Funzionamento matematico del generatore:
L'obiettivo del generatore è generare un'immagine falsa dalla distribuzione data (set di immagini), lo fa con la seguente procedura:
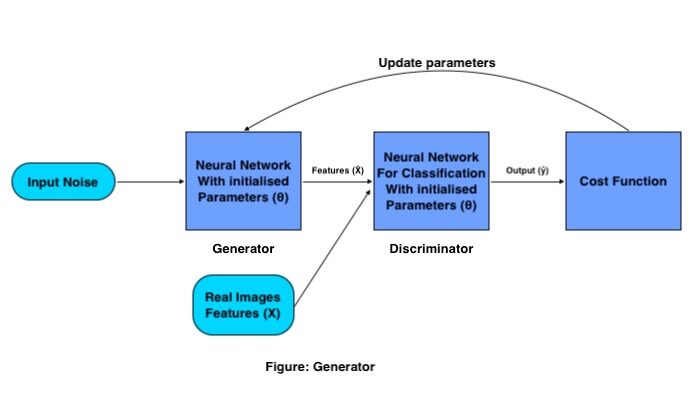
Viene passato un insieme di vettori di input (rumore casuale) tramite la neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. del generador, che crea un'immagine completamente nuova moltiplicando la matrice del peso del generatore con il rumore in ingresso.
Questa immagine generata funziona come input per il discriminatore che è addestrato a classificare immagini false e reali.. Quindi la perdita viene calcolata per le immagini generate, in base a quali parametri vengono aggiornati per il generatore finché non otteniamo una buona precisione.
Una volta che siamo soddisfatti della precisione del generatore, Salviamo i pesi del Generatore ed eliminiamo il Discriminatore dalla rete, e usiamo quella matrice di peso per generare più nuove immagini passandole ogni volta una matrice di rumore casuale diversa.
Perdita di entropia incrociata binaria per GAN:
Per ottimizzare i parametri GAN, abbiamo bisogno di una funzione di costo che dica alla rete quanto deve migliorare semplicemente calcolando la differenza tra il valore effettivo e quello previsto. Il Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e... que se utiliza en las GAN se denomina entropía cruzada binaria y se representa como:
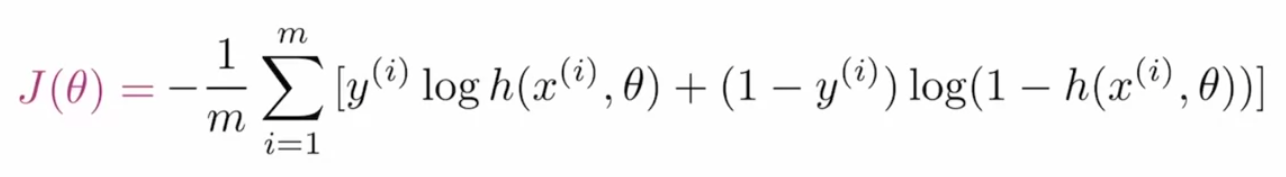
Dove m è la dimensione del lotto, e(io) è il valore effettivo del tag, h è il valore dell'etichetta previsto, X(io) è la caratteristica di ingresso e rappresenta il parametro.
Dividiamo questa funzione di costo in sottoparti per capire meglio. La formula data è la combinazione di due termini in cui uno viene utilizzato quando è efficace quando l'etichetta è “0” e l'altro è importante quando l'etichetta è “1”. Il primo termine è:
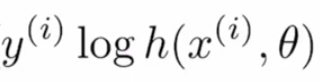
se il valore reale è “1” e il valore previsto è “~ 0” in questo caso, dal log (~ 0) tende all'infinito negativo o molto alto, e se il valore previsto è anche “~ 1”, poi il log ( ~ 1) sarebbe vicino a “0” o molto meno, quindi questo termine aiuta a calcolare la perdita per i valori dell'etichetta “1”.
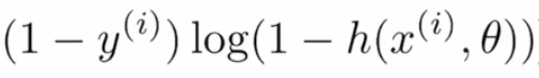
Se il valore effettivo è “0” e il valore previsto è “~ 1”, quindi accedi (1- (~ 1)) risulterebbe in infinito negativo o molto alto, e se il valore previsto è “~ 0”, allora il termine produrrebbe risultati "~ 0" o molto meno perdite, quindi questo termine viene utilizzato per i valori dei tag effettivi "0".
Qualsiasi termine di perdita restituirebbe valori negativi nel caso in cui la previsione fosse sbagliata, la combinazione di questi termini si chiama entropia (perdita logaritmica). Ma visto che è negativo, per renderlo maggiore di "1" applichiamo un segno negativo (può essere visto nella formula principale), applicare questo segno negativo è cosa fa Entropia incrociata (perdita logaritmica negativa).
Addestriamo il primo modello GAN:
Creeremo un modello GAN che potrebbe generare cifre scritte a mano dalla distribuzione dei dati MNIST utilizzando il modulo PyTorch.
Primo, importiamo i moduli richiesti:
%matplotlib in linea importa numpy come np importare la torcia importa matplotlib.pyplot come plt
Quindi leggeremmo i dati dal sottomodulo fornito da PyTorch chiamato set di dati.
# numero di sottoprocessi da utilizzare per il caricamento dei dati
num_lavoratori = 0
# quanti campioni per batch caricare
batch_size = 64
# convertire i dati in torcia.FloatTensor
transform = trasforma.ToTensor()
# ottenere i set di dati di allenamento
train_data = set di dati.MNIST(radice="dati", treno=Vero,
download=Vero, trasformare=trasformare)
# preparare il caricatore di dati
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
num_workers=num_workers)
Visualizza i dati
Dal momento che creeremmo il nostro modello nel framework PyTorch che utilizza i tensori, trasformeremmo i nostri dati in tenditori torcia. Se vuoi visualizzare i dati, puoi andare avanti e utilizzare il seguente frammento di codice:
# ottenere un batch di immagini di allenamento dataiter = iter(train_loader) immagini, etichette = dataiter.next() immagini = immagini.numpy() # ottieni un'immagine dal batch img = np.squeeze(immagini[0]) fig = plt.figure(dimensione del fico = (3,3)) ax = fig.add_subplot(111) ax.imshow(img, cmap='grigio')

discriminato
Ora è il momento di definire la rete dei discriminatori, che è la combinazione di diversi strati della CNN.
import torcia.nn come nn
import torcia.nn.funzionale come F
discriminatore di classe(nn.Modulo):
def __init__(se stesso, input_size, nascosto_dime, output_size):
super(Discriminatore, se stesso).__dentro__()
# definire livelli lineari nascosti
self.fc1 = nn.Lineare(input_size, nascosto_dim*4)
self.fc2 = nn.Lineare(nascosto_dim*4, nascosto_dim*2)
self.fc3 = nn.Lineare(nascosto_dim*2, nascosto_dime)
# strato finale completamente connesso
self.fc4 = nn.Lineare(nascosto_dime, output_size)
# strato di eliminazione
self.dropout = nn.dropout(0.3)
def avanti(se stesso, X):
# immagine piatta
x = x.vista(-1, 28*28)
# tutti i livelli nascosti
x = F.leaky_relu(self.fc1(X), 0.2) # (ingresso, pendenza_negativa=0.2)
x = self.dropout(X)
x = F.leaky_relu(self.fc2(X), 0.2)
x = self.dropout(X)
x = F.leaky_relu(self.fc3(X), 0.2)
x = self.dropout(X)
# strato finale
out = self.fc4(X)
tornare fuori
Il codice sopra segue la tradizionale architettura Python orientata agli oggetti. fc1, fc2, fc3, fc3 sono i livelli completamente connessi. Quando passiamo le nostre entità di input, passa attraverso tutti questi livelli a partire da fc1, Alla fine, abbiamo un livello di abbandono che viene utilizzato per affrontare il problema del sovradattamento.
Nello stesso codice, vedrai una funzione chiamata forward (se stesso, X), questa funzione è l'implementazione dell'effettivo meccanismo di propagazione in avanti in cui ogni strato (fc1, fc2, fc3 e fc4) è seguito da una funzione trigger (saltando_relu ) per convertire l'output del liner in non lineare.
Modello del generatore
Dopo di che, verificheremo il segmento Generator di GAN:
generatore di classe(nn.Modulo):
def __init__(se stesso, input_size, nascosto_dime, output_size):
super(Generatore, se stesso).__dentro__()
# definire livelli lineari nascosti
self.fc1 = nn.Lineare(input_size, nascosto_dime)
self.fc2 = nn.Lineare(nascosto_dime, nascosto_dim*2)
self.fc3 = nn.Lineare(nascosto_dim*2, nascosto_dim*4)
# strato finale completamente connesso
self.fc4 = nn.Lineare(nascosto_dim*4, output_size)
# strato di eliminazione
self.dropout = nn.dropout(0.3)
def avanti(se stesso, X):
# tutti i livelli nascosti
x = F.leaky_relu(self.fc1(X), 0.2) # (ingresso, pendenza_negativa=0.2)
x = self.dropout(X)
x = F.leaky_relu(self.fc2(X), 0.2)
x = self.dropout(X)
x = F.leaky_relu(self.fc3(X), 0.2)
x = self.dropout(X)
# strato finale con tanh applicato
out = F.tanh(self.fc4(X))
tornare fuori
Anche la rete del generatore è costruita dagli strati completamente connessi, las funciones de activación de riprendereLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. Definito come ( F(X) = massimo(0, X) ), ReLU consente ai neuroni di attivarsi solo quando l'input è positivo, che aiuta a mitigare il problema dello sbiadimento del gradiente. È stato dimostrato che il suo utilizzo migliora le prestazioni in varie attività di deep learning, rendendo ReLU un'opzione.. con fugas y la deserción. L'unica cosa che lo rende diverso da Discriminator è che l'output dipende dal parametro output_size (qual è la dimensione dell'immagine da generare).
Ottimizzazione degli iperparametri
Gli iperparametri che useremo per addestrare i GAN sono:
# Iperparametri discriminatori # Dimensione dell'immagine in ingresso al discriminatore (28*28) input_size = 784 # Dimensione dell'uscita del discriminatore (Vero o falso) d_output_size = 1 # Dimensione dell'ultimo livello nascosto nel discriminatore d_hidden_size = 32 # Iperparami del generatore # Dimensione del vettore latente da dare al generatore z_size = 100 # Dimensione dell'uscita del discriminatore (immagine generata) g_output_size = 784 # Dimensione del primo livello nascosto nel generatore g_hidden_size = 32
Crea un'istanza dei modelli
E infine, l'intera rete sarebbe simile a questo:
# istanziare discriminatore e generatore D = discriminatore(input_size, d_hidden_size, d_output_size) G = Generatore(z_size, g_hidden_size, g_output_size) # controlla che siano come ti aspetti Stampa(D) Stampa( ) Stampa(G)

Calcola perdite
Abbiamo definito il Generatore e il Discriminatore ora è il momento di definire le tue perdite in modo che quelle reti migliorino nel tempo. Per il GAN avremmo due perdite reali di funzione di perdita e una falsa perdita che si definirebbe così:
# Calcola perdite
def real_loss(D_out, liscio=Falso):
batch_size = D_out.size(0)
# levigatura dell'etichetta
se liscio:
# liscio, etichette reali = 0.9
etichette = torch.ones(dimensione del lotto)*0.9
altro:
etichette = torch.ones(dimensione del lotto) # etichette reali = 1
# perdita numericamente stabile
criterio = nn.BCEWithLogitsLoss()
# calcolare la perdita
perdita = criterio(D_out.squeeze(), etichette)
perdita di ritorno
def fake_loss(D_out):
batch_size = D_out.size(0)
etichette = torcia.zero(dimensione del lotto) # etichette false = 0
criterio = nn.BCEWithLogitsLoss()
# calcolare la perdita
perdita = criterio(D_out.squeeze(), etichette)
perdita di ritorno
Ottimizzatori
Una volta definite le perdite, sceglieremmo un ottimizzatore adatto per l'allenamento:
importa torch.optim come optim # Ottimizzatori lr = 0.002 # Crea ottimizzatori per il discriminatore e il generatore d_optimizer = optim.Adam(D.parametri(), lr) g_optimizer = optim.Adam(G.parametri(), lr)
Formazione modello
Poiché abbiamo definito Generator e Discriminator entrambe le reti, le sue funzioni di perdita come ottimizzatori, ora useremmo i tempi e altre caratteristiche per allenare tutta la rete.
importa sottaceti come pkl
# iperparametri di allenamento
num_epoche = 100
# tenere traccia della perdita e generato, "impostore" campioni
campioni = []
perdite = []
print_ogni = 400
# Ottieni alcuni dati fissi per il campionamento. Queste sono immagini che si tengono
# costante durante l'allenamento, e ci permettono di ispezionare le prestazioni del modello
sample_size=16
fixed_z = np.random.uniform(-1, 1, taglia=(misura di prova, z_size))
fixed_z = torcia.from_numpy(fixed_z).galleggiante()
# allenare la rete
D.train()
G.treno()
per epoca in gamma(num_epoche):
per batch_i, (real_images, _) in enumerare(train_loader):
batch_size = real_images.size(0)
## Importante passaggio di ridimensionamento ##
immagini_reali = immagini_reali*2 - 1 # ridimensionare le immagini di input da [0,1) a [-1, 1)
# ============================================
# FORMARE IL DISCRIMINATORE
# ============================================
d_optimizer.zero_grad()
# 1. Allenati con immagini reali
# Calcola le perdite del discriminatore su immagini reali
# liscia le vere etichette
D_reale = D(real_images)
d_real_loss = real_loss(D_real, liscio=Vero)
# 2. Allenati con immagini false
# Genera immagini false
# i gradienti non devono fluire durante questo passaggio
con torcia.no_grad():
z = np.random.uniform(-1, 1, taglia=(dimensione del lotto, z_size))
z = torcia.from_numpy(Insieme a).galleggiante()
fake_images = G(Insieme a)
# Calcola le perdite del discriminatore su immagini false
D_falso = D(fake_images)
d_fake_loss = fake_loss(D_falso)
# somma le perdite ed esegui il backprop
d_loss = d_real_loss + d_fake_loss
d_loss.indietro()
d_optimizer.step()
# =========================================
# ALLENA IL GENERATORE
# =========================================
g_optimizer.zero_grad()
# 1. Allenati con immagini false ed etichette capovolte
# Genera immagini false
z = np.random.uniform(-1, 1, taglia=(dimensione del lotto, z_size))
z = torcia.from_numpy(Insieme a).galleggiante()
fake_images = G(Insieme a)
# Calcola le perdite del discriminatore su immagini false
# usando etichette capovolte!
D_falso = D(fake_images)
g_loss = real_loss(D_falso) # usa la perdita reale per capovolgere le etichette
# eseguire backprop
g_loss.indietro()
g_optimizer.step()
# Stampa alcune statistiche di perdita
se batch_i % print_ogni == 0:
# discriminatore di stampa e perdita del generatore
Stampa('Epoca [{:5D}/{:5D}] | d_loss: {:6.4F} | g_loss: {:6.4F}'.formato(
epoca+1, num_epoche, d_loss.item(), g_loss.item()))
## DOPO OGNI EPOCA##
# aggiungere la perdita del discriminatore e la perdita del generatore
perdite.append((d_loss.item(), g_loss.item()))
# generare e salvare il campione, immagini false
G.eval() # modalità eval per la generazione di campioni
campioni_z = G(fixed_z)
campioni.append(campioni_z)
G.treno() # torna alla modalità allenamento
# Salva i campioni del generatore di formazione
con aperto('train_samples.pkl', 'wb') come f:
pkl.dump(campioni, F)
Una volta eseguito lo snippet di codice sopra, il processo di formazione comincerebbe così:

Genera immagini
Finalmente, quando il modello è addestrato, puoi usare il generatore addestrato per produrre le nuove immagini scritte a mano.
# generato casualmente, nuovi vettori latenti sample_size=16 rand_z = np.random.uniform(-1, 1, taglia=(misura di prova, z_size)) rand_z = torcia.from_numpy(rand_z).galleggiante() G.eval() # modalità di valutazione # campioni generati rand_images = G(rand_z) # 0 indica il primo set di campioni nell'elenco passato in # e abbiamo solo un lotto di campioni, qui view_samples(0, [rand_images])
L'output generato con il seguente codice vorrebbe qualcosa del genere:

Quindi, ora che hai il tuo modello GAN addestrato, puoi usare questo modello per allenarti su un diverso set di immagini, per produrre nuove immagini invisibili.
Riferimenti:
1. Apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... de Udacity: https://www.udacity.com/
2. Intelligenza artificiale di apprendimento profondo: https://www.deeplearning.ai/
Grazie per aver letto questo articolo. Se hai imparato qualcosa di nuovo, sentiti libero di commentare, alla prossima volta! !!! ❤️
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





