introduzione
Quando inizia con la scienza dei dati, inizia semplice. Passi attraverso progetti semplici come Problema di previsione del prestito oh Previsione delle vendite del Big Mart. Questi problemi hanno dati strutturati disposti ordinatamente in un formato tabulare. In altre parole, Sei stato imboccato la parte più difficile nella pipeline della scienza dei dati.

I set di dati nella vita reale sono molto più complessi.
Devi capirlo prima, raccoglierlo da varie fonti e organizzarlo in un formato pronto per l'elaborazione. Questo è ancora più difficile quando i dati sono in un formato non strutturato, come immagine o audio. Questo perché dovrebbe rappresentare i dati dell'immagine / audio in modo standard per essere utile per l'analisi.
L'abbondanza di dati non strutturati
curiosamente, i dati non strutturati rappresentano una grande opportunità non sfruttata. È più vicino a come comunichiamo e interagiamo come esseri umani. Contiene anche molte informazioni utili e potenti. Ad esempio, se una persona parla; non capisci solo quello che dice, ma anche quali erano le emozioni della persona dalla voce.
Cosa c'è di più, il linguaggio del corpo della persona può mostrarti molte più caratteristiche di una persona, Perché le azioni parlano più forte delle parole! In sintesi, i dati non strutturati sono complessi, ma elaborarli può produrre facili ricompense.
In questo articolo, Intendo trattare una panoramica dell'elaborazione audio / voce con un case study in modo da poter ottenere un'introduzione pratica alla risoluzione dei problemi di elaborazione audio.
Andiamo avanti!
Sommario
- Cosa intendi per dati audio?
- Applicazioni di elaborazione audio
- Gestione dei dati nel dominio audio
- Risolviamo la sfida UrbanSound!!
- Intermedio: la nostra prima presentazione
- Risolviamo la sfida! Parte 2: Costruire modelli migliori
- Passi futuri da esplorare
Cosa intendi per dati audio?
Direttamente o indirettamente, sei sempre in contatto con l'audio. Il tuo cervello elabora e comprende continuamente i dati audio e ti fornisce informazioni sull'ambiente. Un semplice esempio possono essere le tue conversazioni con le persone che fai quotidianamente.. Questo discorso è discernuto dall'altra persona per continuare le discussioni. Anche quando pensi di essere in un ambiente tranquillo, tende a captare suoni molto più sottili, come il fruscio delle foglie o lo spruzzo della pioggia. Questa è l'estensione della tua connessione all'audio.
Quindi, Riesci in qualche modo a catturare questo audio che fluttua intorno a te per fare qualcosa di costruttivo?? sì, Certo! Ci sono dispositivi integrati che ti aiutano a raccogliere questi suoni e rappresentarli in un formato leggibile dal computer.. Esempi di questi formati sono
- formato wav (file audio della forma d'onda)
- formato mp3 (Livello audio MPEG-1 3)
- Formato WMA (Windows Media Audio)
Se pensi a come appare un audio, non è altro che un formato di dati di forma d'onda, dove l'ampiezza dell'audio cambia rispetto al tempo. Questo può essere rappresentato pittoricamente come segue.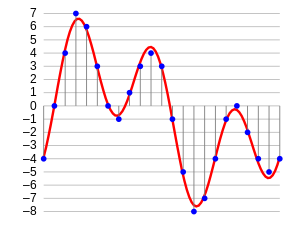
Applicazioni di elaborazione audio
Sebbene commentiamo che i dati audio possono essere utili per l'analisi. Ma, Quali sono le possibili applicazioni dell'elaborazione audio? Qui ne elencherei alcuni.
- Indicizzazione delle raccolte musicali in base alle loro caratteristiche audio.
- Consiglia musica per i canali radio
- Trovare somiglianze per i file audio (alias Shazam)
- Elaborazione e sintesi del parlato: generazione di voce artificiale per agenti conversazionali
Ecco un esercizio; Riesci a pensare a un'app di elaborazione audio che può potenzialmente aiutare migliaia di vite??
Gestione dei dati nel dominio audio
Come con tutti i formati di dati non strutturati, i dati audio hanno un paio di passaggi di pre-elaborazione che devono essere seguiti prima di essere presentati per l'analisi. Ne parleremo in dettaglio in un articolo successivo., qui avremo un'idea del perché questo è fatto.
Il primo passo è caricare i dati in un formato comprensibile dalla macchina. Per questo, prendiamo solo valori dopo ogni specifico passaggio temporale. Ad esempio; in un file audio di 2 secondi, estraiamo i valori a mezzo secondo. È chiamato campionamento dati audio, e la velocità con cui viene campionato è chiamata frequenza di campionamento.
Un altro modo per rappresentare i dati audio è convertirli in un diverso dominio di rappresentazione dei dati, vale a dire, il dominio della frequenza. Quando campioniamo i dati audio, abbiamo bisogno di molti più punti dati per rappresentare tutti i dati e, Cosa c'è di più, la frequenza di campionamento dovrebbe essere la più alta possibile.
In secondo luogo, se rappresentiamo i dati audio in dominio della frequenza, è richiesto molto meno spazio di calcolo. Avere un'intuizione, Date un'occhiata alla foto qui sotto.
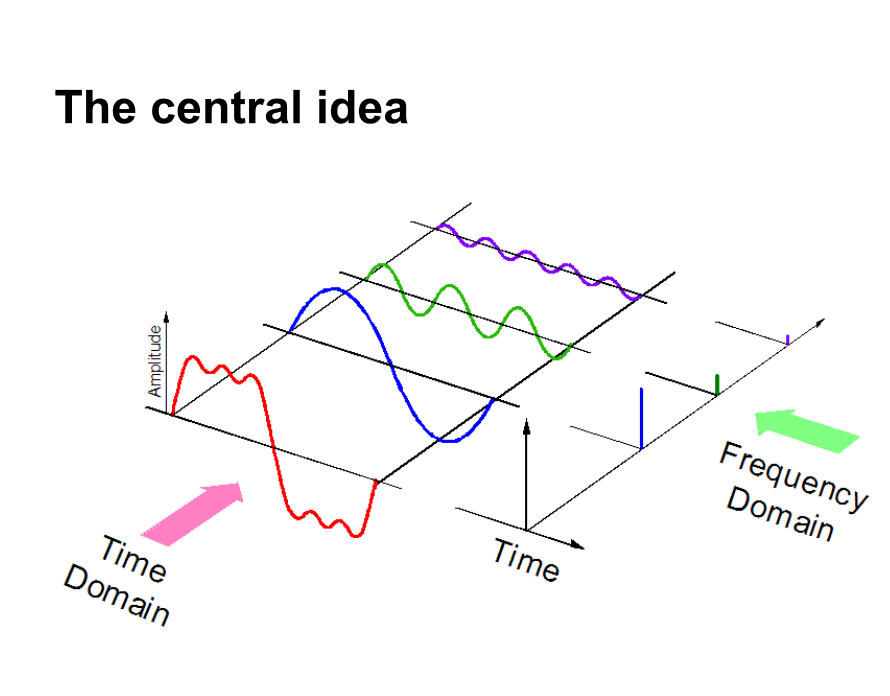
Qui, separiamo un segnale audio in 3 diversi segnali puri, che ora può essere rappresentato come tre valori univoci nel dominio della frequenza.
Ci sono altri modi in cui i dati audio possono essere rappresentati, ad esempio. usando MFC (miele di frequenza cepstrum. PD: Ne parleremo nell'articolo successivo.). Questi sono solo modi diversi di rappresentare i dati.
Ora, il prossimo passo è estrarre le caratteristiche da queste rappresentazioni audio, in modo che il nostro algoritmo possa lavorare su queste caratteristiche e svolgere il compito per il quale è progettato. Prossimo, viene mostrata una rappresentazione visiva delle categorie di funzioni audio estraibili.
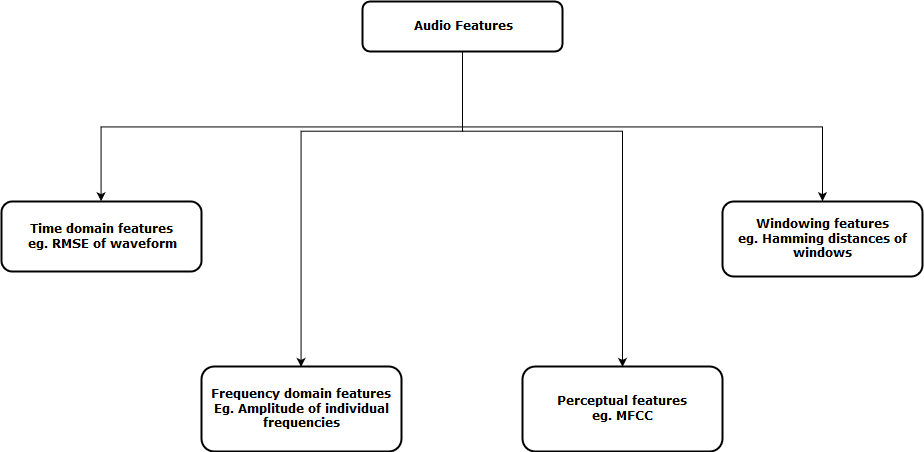
Dopo aver estratto queste funzionalità, inviato al modello di apprendimento automatico per ulteriori analisi.
Risolviamo la sfida UrbanSound!!
Facciamo una panoramica pratica migliore su un progetto di vita reale, il Sfida del suono urbano. Questo problema pratico ha lo scopo di introdurti all'elaborazione audio nel tipico scenario di classificazione.
Il set di dati contiene 8732 brani sonori (<= 4 S) di suoni urbani di 10 Lezioni, vale a dire:
- aria condizionata,
- Corno,
- bambini che giocano,
- cane che abbaia,
- perforazione,
- Motore al minimo,
- sparo
- martello pneumatico,
- sirena e
- Musica di strada
Ecco un estratto del suono dal set di dati. Riuscite a indovinare a quale classe appartiene??
Per riprodurre questo nel taccuino di jupyter, puoi semplicemente seguire il codice.
importa IPython.display come ipd
ipd.Audio('../data/Treno/2022.wav')
Ora carichiamo questo audio nel nostro laptop come una grande matrice. Per questo useremo libri libreria Python. Per installare libri, basta digitare questo nella riga di comando
pip install librosaOra possiamo eseguire il seguente codice per caricare i dati.
dati, campionamento_rate = librosa.load('../data/Treno/2022.wav')
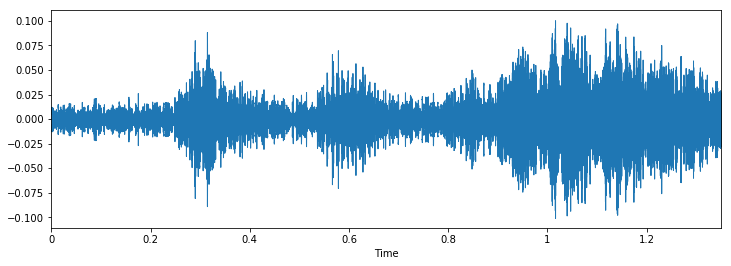
Quando carichi i dati, ti dà due oggetti; una vasta gamma di un file audio e la frequenza di campionamento corrispondente con cui è stato estratto. Ora, per rappresentare questo come una forma d'onda (che è originariamente), usa il seguente codice
% pylab in linea importare il sistema operativo importa panda come pd importare libri importare globo plt.figure(figsize=(12, 4)) librosa.display.waveplot(dati, sr=sampling_rate)
L'output è il seguente
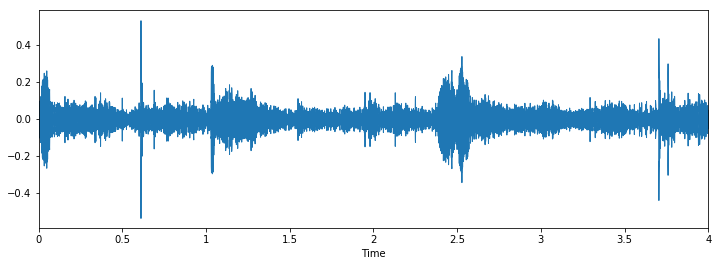
Ora esaminiamo visivamente i nostri dati e vediamo se possiamo trovare modelli nei dati..
Classe: martello pneumaticoClasse: perforazione
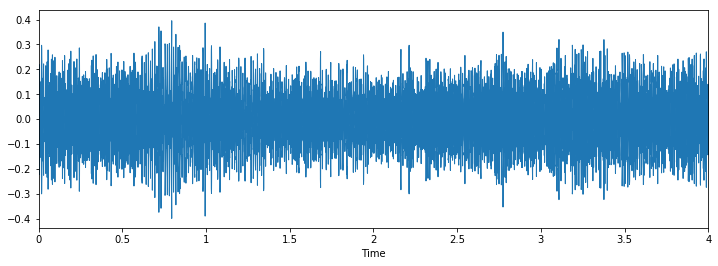 Classe: perforazione
Classe: perforazione
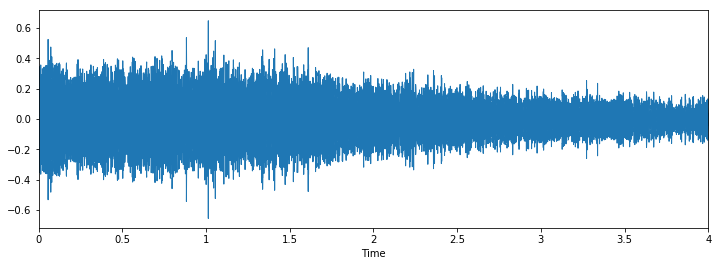 Classe: cane che abbaia
Classe: cane che abbaia
Possiamo vedere che può essere difficile distinguere tra martello pneumatico e perforazione, ma è ancora facile distinguere tra cane che abbaia e piercing. Per vedere altri esempi di questo tipo, puoi usare questo codice
i = random.choice(train.index)
nome_audio = train.ID[io]
percorso = os.path.join(data_dir, 'Treno', str(nome_audio) + '.wav')
Stampa('Classe: ', treno.Classe[io])
X, sr = librosa.load('../data/Treno/' + str(train.ID[io]) + '.wav')
plt.figure(figsize=(12, 4))
librosa.display.waveplot(X, sr=sr)
Intermedio: la nostra prima presentazione
Faremo un approccio simile a quello che abbiamo fatto per il problema del rilevamento dell'età, per vedere le distribuzioni di classi e prevedere solo l'occorrenza massima di tutti i casi di test come quella classe.
Diamo un'occhiata alle distribuzioni per questo problema.
train.Class.value_counts()
Fuori[10]: martello pneumatico 0.122907 motore_minimo 0.114811 sirena 0.111684 cane_abbaiare 0.110396 condizionatore 0.110396 bambini_che giocano 0.110396 street_music 0.110396 perforazione 0.110396 clacson 0.056302 sparo 0.042318
Vediamo che la classe del martello pneumatico ha più valori di qualsiasi altra classe. Quindi creiamo la nostra prima presentazione con questa idea.
test = pd.read_csv('../data/test.csv')
test['Classe'] = 'martello pneumatico'
test.to_csv('sub01.csv', indice=Falso)
Questa sembra una buona idea come punto di riferimento per qualsiasi sfida, ma per questo problema, mi sembra un po' ingiusto. Questo perché il set di dati non è molto sbilanciato.
Risolviamo la sfida! Parte 2: Costruire modelli migliori
Ora vediamo come possiamo sfruttare i concetti appresi in precedenza per risolvere il problema.. Seguiremo questi passaggi per risolvere il problema.
passo 1: caricare file audio
passo 2: estrarre le funzioni dall'audio
passo 3: convertire i dati da passare nel nostro modello di deep learning
passo 4: Esegui un modello di deep learning e ottieni risultati
Di seguito è riportato un codice di come ho implementato questi passaggi
passo 1 e 2 combinato: caricare file audio ed estrarre funzioni
def parser(riga): # function to load files and extract features file_name = os.path.join(os.path.abspath(data_dir), 'Treno', str(riga.ID) + '.wav') # handle exception to check if there isn't a file which is corrupted try: # here kaiser_fast is a technique used for faster extraction X, sample_rate = librosa.load(nome del file, res_type="kaiser_fast") # we extract mfcc feature from data mfccs = np.mean(librosa.feature.mfcc(y = X, sr=tasso_campione, n_mfcc=40).T,asse=0) tranne Eccezione come e: Stampa("Si è verificato un errore durante l'analisi del file: ", file) restituisci Nessuno, None feature = mfccs label = row.Class return [caratteristica, etichetta] temp = train.apply(analizzatore, asse=1) colonne.temp = ['caratteristica', 'etichetta']
passo 3: convertire i dati da passare nel nostro modello di deep learning
da sklearn.preprocessing import LabelEncoder X = np.array(temp.feature.tolist()) y = np.array(temp.label.tolist()) lb = LabelEncoder() y = np_utils.to_categorical(lb.fit_transform(e))
passo 4: Esegui un modello di deep learning e ottieni risultati
importa numpy come np
da keras.models import Sequential
da keras.layers import Dense, Ritirarsi, Attivazione, Appiattire
da keras.layers import Convolution2D, MaxPooling2D
da keras.optimizers import Adam
da keras.utils import np_utils
da sklearn import metrics
num_labels = y.shape[1]
filter_size = 2
# costruire modello
modello = Sequenziale()
modello.aggiungi(Denso(256, input_shape=(40,)))
modello.aggiungi(Attivazione('relu'))
modello.aggiungi(Ritirarsi(0.5))
modello.aggiungi(Denso(256))
modello.aggiungi(Attivazione('relu'))
modello.aggiungi(Ritirarsi(0.5))
modello.aggiungi(Denso(num_labels))
modello.aggiungi(Attivazione('softmax'))
modello.compila(perdita="categorical_crossentropy", metriche=['precisione'], ottimizzatore="Adamo")
Ora alleniamo il nostro modello
model.fit(X, e, batch_size=32, epoche=5, validation_data=(val_x, val_y))
Questo è il risultato che ho ottenuto dall'allenamento durante 5 epoche
Allenati 5435 campioni, convalidare su 1359 campioni Epoca 1/10 5435/5435 [==============================] - 2S - perdita: 12.0145 - acc: 0.1799 - val_loss: 8.3553 - val_acc: 0.2958 Epoca 2/10 5435/5435 [==============================] - 0S - perdita: 7.6847 - acc: 0.2925 - val_loss: 2.1265 - val_acc: 0.5026 Epoca 3/10 5435/5435 [==============================] - 0S - perdita: 2.5338 - acc: 0.3553 - val_loss: 1.7296 - val_acc: 0.5033 Epoca 4/10 5435/5435 [==============================] - 0S - perdita: 1.8101 - acc: 0.4039 - val_loss: 1.4127 - val_acc: 0.6144 Epoca 5/10 5435/5435 [==============================] - 0S - perdita: 1.5522 - acc: 0.4822 - val_loss: 1.2489 - val_acc: 0.6637
Sembra andare bene, ma ovviamente puoi aumentare il punteggio. (PD: potrebbe ottenere precisione da 80% nel mio set di dati di convalida). Ora tocca a te, Puoi aumentare questo punteggio?? Se è così, Fatemelo sapere nei commenti qui sotto!!
Passi futuri da esplorare
Ora che abbiamo visto semplici applicazioni, possiamo trovare altri metodi che possono aiutarci a migliorare il nostro punteggio.
- Applichiamo al problema un semplice modello di rete neurale. Il nostro prossimo passo immediato dovrebbe essere capire dove il modello fallisce e perché. Con questo, vogliamo concettualizzare la nostra comprensione dei fallimenti dell'algoritmo in modo che la prossima volta che costruiamo un modello, non fare gli stessi errori.
- Possiamo costruire modelli più efficienti che il nostro “i migliori modelli”, come le reti neurali convoluzionali o le reti neurali ricorrenti. Questi modelli hanno dimostrato di risolvere più facilmente questo tipo di problemi.
- Abbiamo toccato il concetto di aumento dei dati, ma non li applichiamo qui. Puoi provarlo per vedere se funziona per il problema.
Note finali
In questo articolo, Ho fornito una breve panoramica dell'elaborazione audio con un caso di studio sulla sfida UrbanSound. Ho anche mostrato i passaggi da eseguire quando si tratta di dati audio in Python con i libri dei pacchetti. Con questo “shastra” nella tua mano, spero che tu possa testare i tuoi algoritmi nella sfida Urban Sound, o prova a risolvere i tuoi problemi audio nella vita quotidiana. Se hai qualche suggerimento / idea, fammi sapere nei commenti qui sotto.
Imparare, ingaggiare , taglio e fatti assumere!

Podcast: Gioca in una nuova finestra | Scarica





