Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
“Per vincere sul mercato, devi vincere sul posto di lavoro” –Steve Jobs, fondatore di Apple Inc..
introduzione
Perché utilizziamo la regressione logistica per analizzare l'attrito dei dipendenti??
Se un dipendente rimarrà o lascerà un'azienda, la tua risposta è semplicemente binomiale, vale a dire, può essere “SÌ” oh “NO”. Quindi, podemos ver que nuestra variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... dependiente Desgaste de empleados es solo una variable categórica. Nel caso di una variabile dipendente categoriale, non possiamo usare la regressione lineare, poi, dobbiamo usare"REGRESSIONE LOGISTICA“.
Metodologia
Qui, indosserò 5 Semplici passaggi per analizzare l'attrito dei dipendenti utilizzando il software R
- RACCOLTA DATI
- PRE-TRATTAMENTO DEI DATI
- DIVIDERE I DATI IN DUE PARTI “ADDESTRAMENTO” E “PROVE”
- COSTRUISCI IL MODELLO CON THE “SET DI DATI DI ALLENAMENTO”
- ESEGUI IL TEST DI PRECISIONE UTILIZZANDO IL “IMPOSTAZIONE DATI DI PROVA”
Esplorazione dei dati
Questo set di dati viene raccolto dal dipartimento delle risorse umane di IBM. Il set di dati contiene 1470 osservazioni e 35 variabili. Entro 35 variabili, "Usura" è la variabile dipendente.
Una rapida occhiata al set di dati:
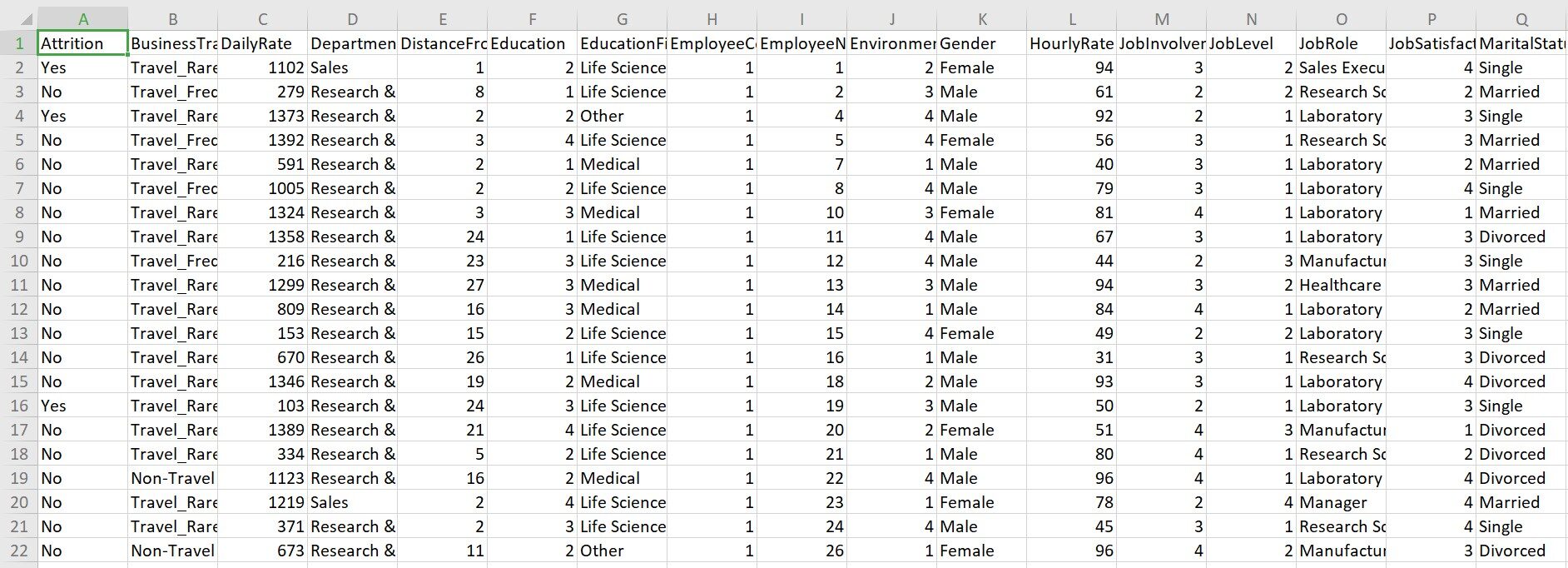
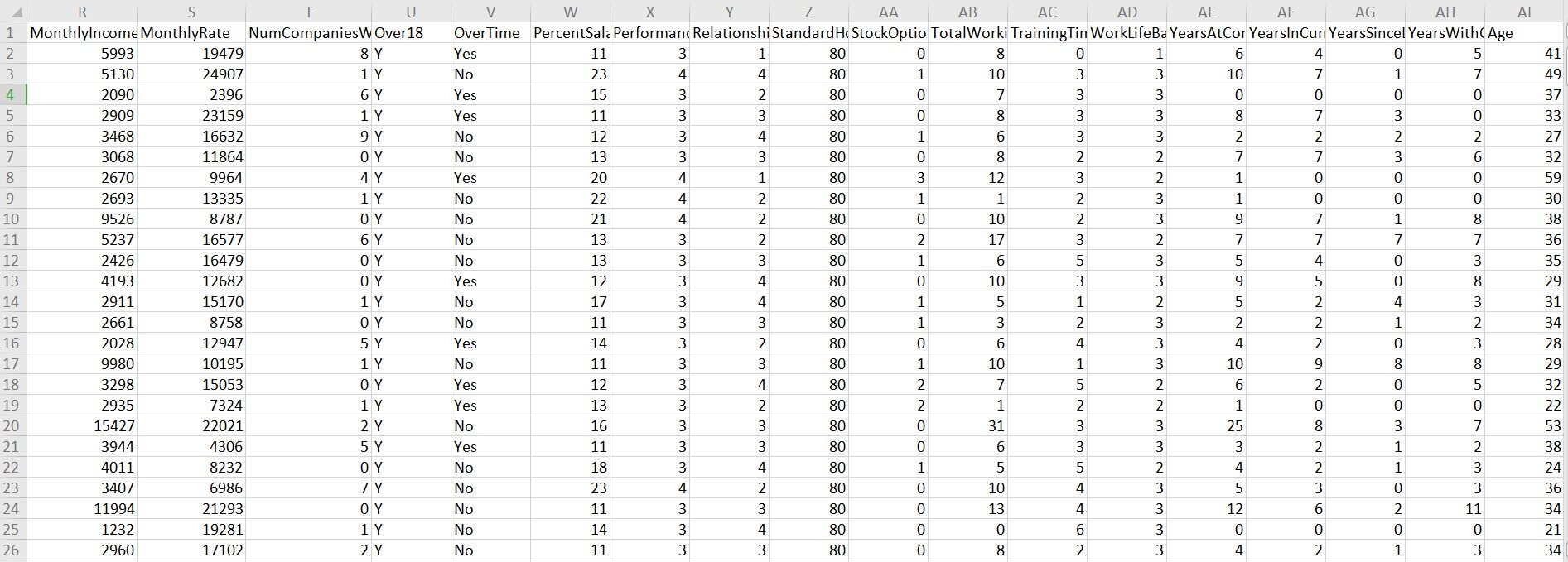
Dai un'occhiata:
Preparazione dei dati
-
Modificare i tipi di dati:
Primo, Dobbiamo cambiare il tipo di dati della variabile dipendente “Portare”. È dato sotto forma di "Sì" e "No", vale a dire, è una variabile categoriale. Per realizzare un modello adatto dobbiamo convertirlo in forma numerica. Per questo, assegneremo il valore 1 a "Sì" e valore 0 a "No" e lo renderemo numerico.
JOB_Attrition$Attrito[JOB_Attrition$Attrito=="Sì"]=1 JOB_Attrition$Attrition[JOB_Attrition$Attrito=="No"]=0 JOB_Attrition$Attrition=as.numeric(JOB_Attrition$Attrito)
prossimo, cambieremo tutte le variabili di “carattere” un “Fattore”
Ci sono 8 variabili carattere: viaggi d'affari, dipartimento, formazione scolastica, campo educativo, Genere, funzione lavorativa, stato civile, nel tempo. I numeri di colonna sono 2, 4, 6, 7, 11, 15, 17, 22 rispettivamente.
JOB_Attrition[,C(2,4,6,7,11,15,17,22)]=lapply(JOB_Attrition[,C(2,4,6,7,11,15,17,22)],come.fattore)
Finalmente, C'è un'altra variabile “Più di 18” che ha tutte le voci come “E”. È anche una variabile di carattere. Diventeremo numerici poiché ha un solo livello, quindi trasformarsi in un fattore non darà un buon risultato. Per questo, assegneremo il valore 1 a "Y" e lo trasformeremo in numerico.
JOB_Attrition$Over18[JOB_Attrition$Over18=="E"]=1 JOB_Attrition$Over18=as.numeric(JOB_Attrition$Over18)
Dividere il set di dati in “addestramento” e “prova”
In qualsiasi analisi di regressione, dobbiamo dividere il set di dati in 2 parti:
- CONJUNTO DE DATOS DE ADDESTRAMENTOLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina....
- IMPOSTAZIONE DATI DI PROVA
Con l'aiuto del set di dati di allenamento, creeremo il nostro modello e testeremo la sua accuratezza utilizzando il set di dati di test.
set.seme(1000)
ranuni=campione(x=c("Addestramento","test"),taglia=numero(JOB_Attrition),sostituire=T,problema=c(0.7,0.3))
TrainingData=JOB_Attrition[ranuni =="Addestramento",]
TestingData=JOB_Attrition[ranuni =="test",]
ora(Dati di allenamento)
ora(Dati di prova)
Abbiamo diviso con successo l'intero set di dati in due parti. Ora abbiamo 1025 Dati di allenamento e 445 Dati di test.
Costruzione del modello
Ora costruiamo il modello seguendo alcuni semplici passaggi come segue:
- Identificare variabili indipendenti
- Incorporare la variabile dipendente “Portare” nel modello.
- Trasformare il tipo di dati dell'oggetto “carattere” un “formula”
- Incorporare i dati di TRAINING nella formula e creare il modello
independentvariables=colnames(JOB_Attrition[,2:35]) independentvariables Model=paste(variabili indipendenti,collapse="+") Model Model_1=paste("Attrito~",Modello) Model_1 class(Model_1) formula=as.formula(Model_1) formula
Produzione:

Prossimo, Incorporeremo "Dati di allenamento" nella formula utilizzando la funzione "glm" e costruiremo un modello di regressione logistica.
Trainingmodel1=glm(formula = formula,data=Dati di allenamento,famiglia="binomiale")
Ora, disegneremo il modello dal “Selezione passo passo”Metodo per ottenere variabili significative dal modello. L'esecuzione del codice ci darà un elenco di output in cui le variabili vengono aggiunte e rimosse in base alla nostra importanza del modello. Il valore dell'AIC ad ogni livello riflette la bontà del rispettivo modello. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que el valor sigue cayendo, si ottiene un modello di regressione logistica che si adatta meglio.
L'applicazione della sintesi sul modello finale ci darà l'elenco delle variabili significative finali e le rispettive informazioni importanti..
Modello di allenamento1=passo(oggetto = Trainingmodel1,direzione = "entrambi") riepilogo(Modello di allenamento1)
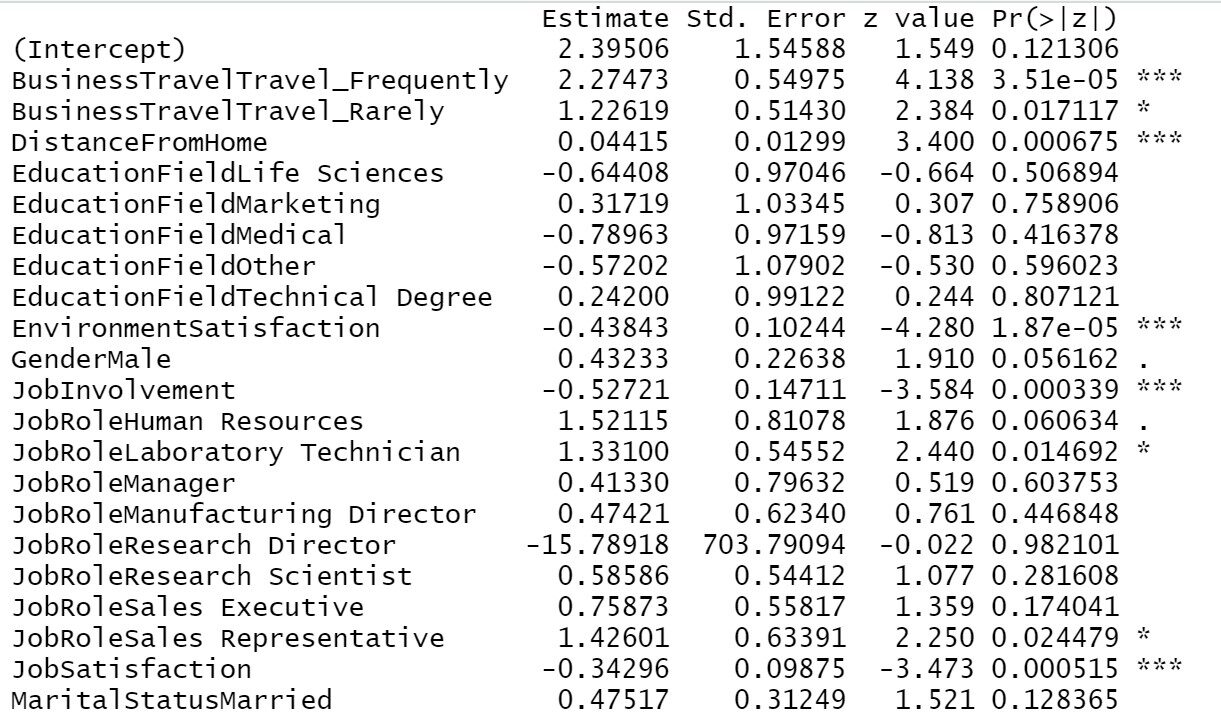
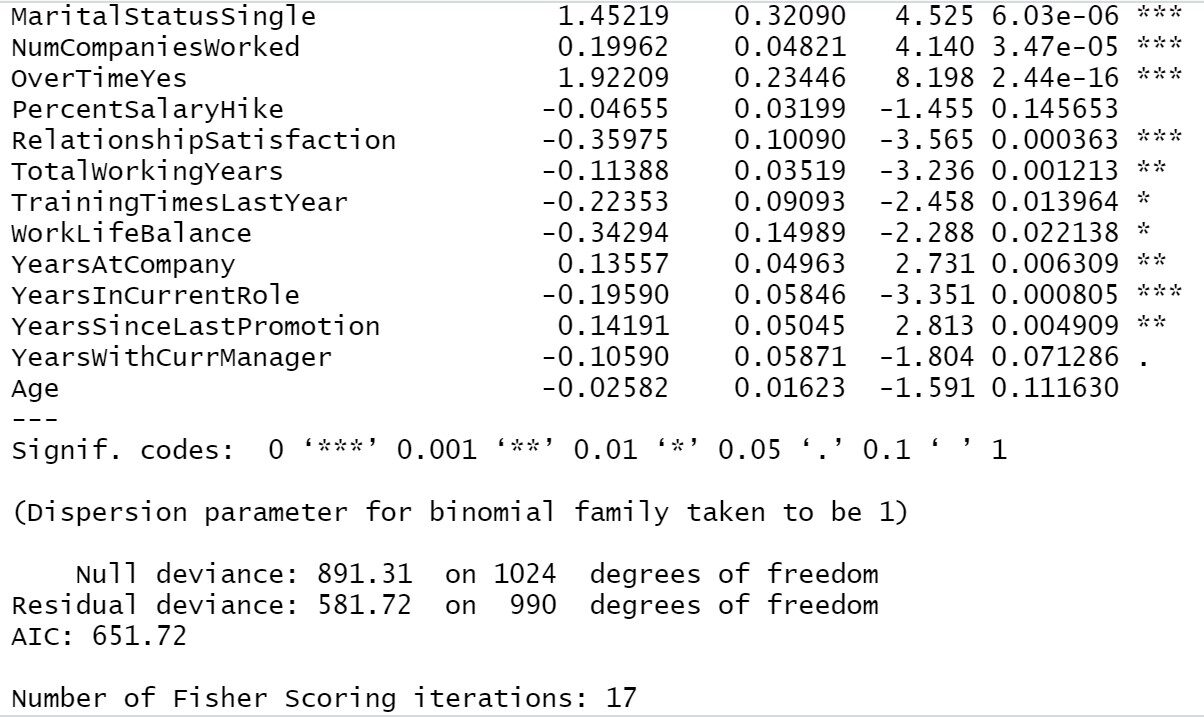
Dal nostro risultato precedente possiamo vedere, Viaggio di lavoro, Distanza da casa, Soddisfazione per l'ambiente, Coinvolgimento del lavoro, Soddisfazione lavorativa, Stato civile, Numero di aziende lavorate, Col tempo, Soddisfazione nelle relazioni, Anni di lavoro totali, Anni in azienda, anni dall'ultima promozione, anni nella posizione attuale tutte queste sono le variabili più importanti nel determinare l'attrito dei dipendenti. Se l'azienda si occupa principalmente di queste aree, ci saranno meno possibilità di perdere un dipendente.
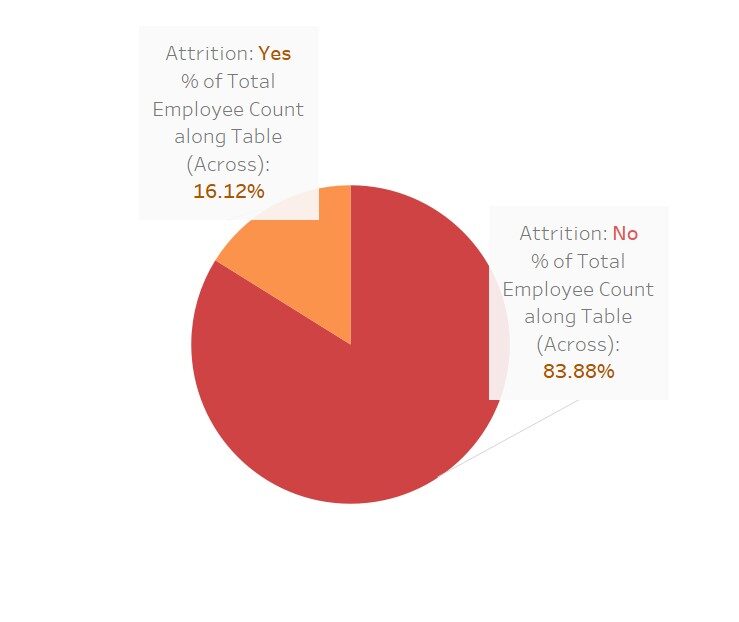
Una rapida visualizzazione per vedere quanto queste variabili influenzano il “indossare”
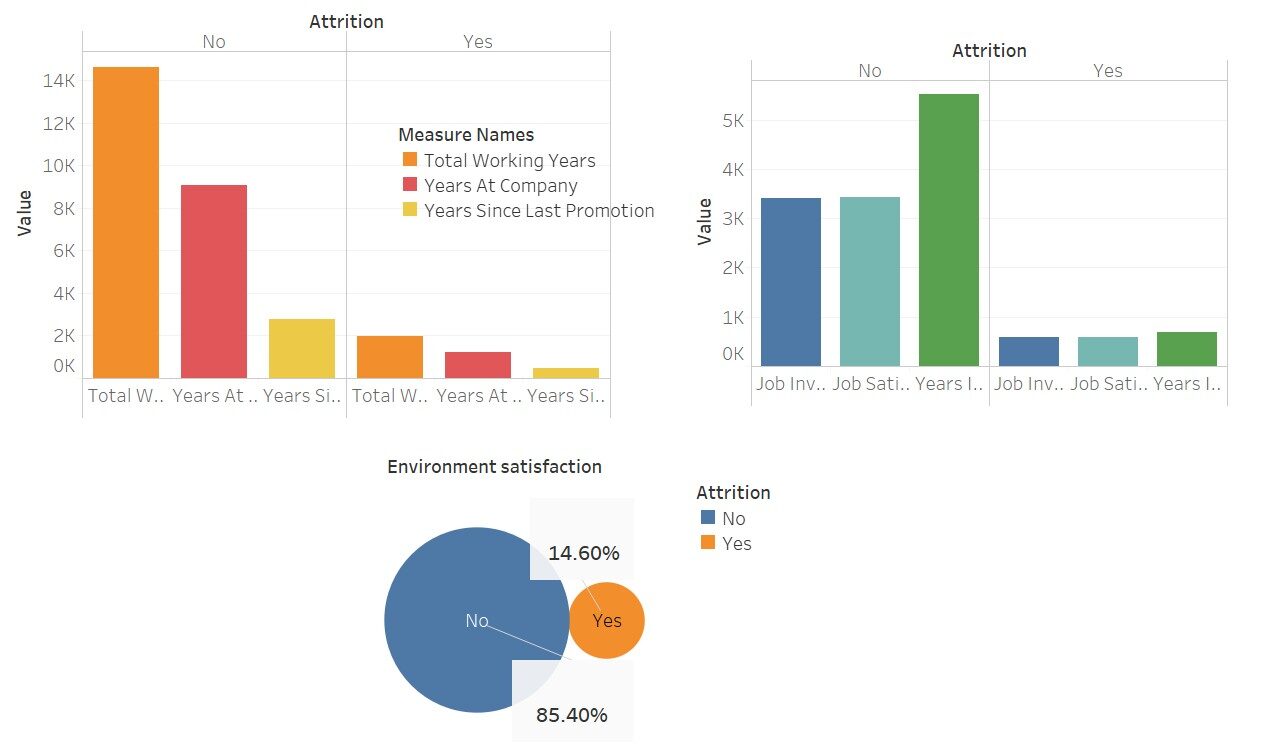
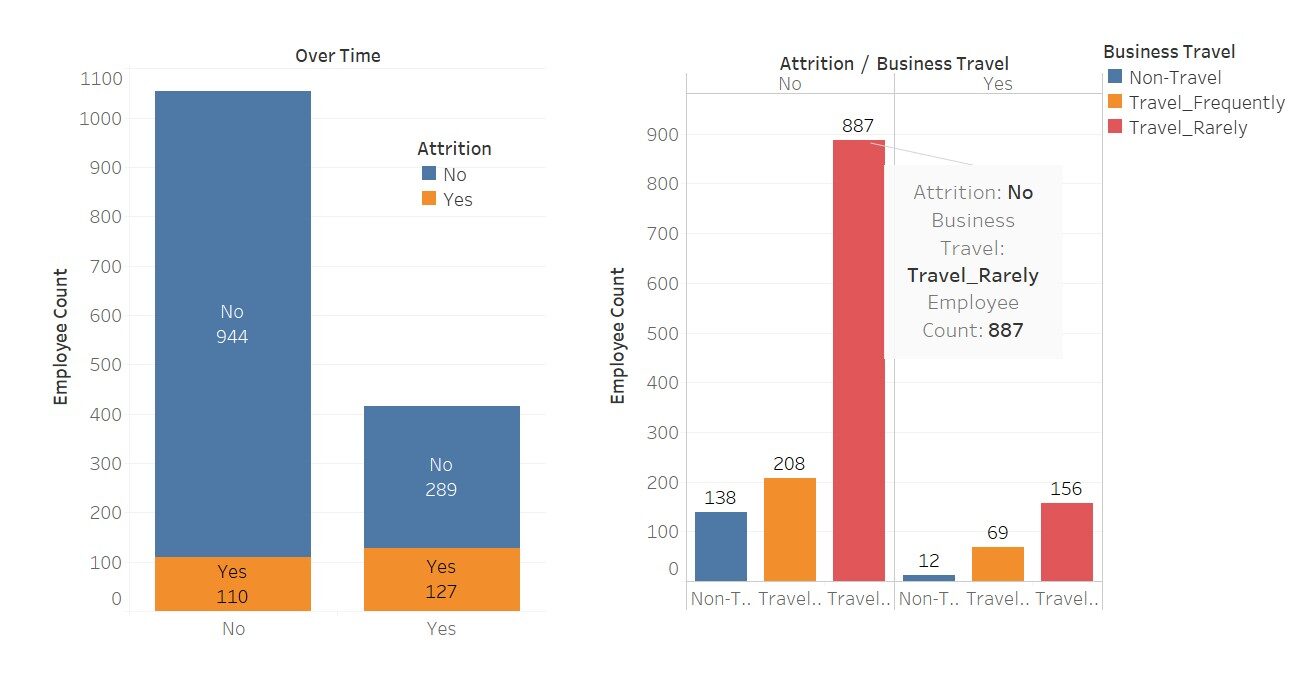
Qui ho usato Tableau per queste visualizzazioni; non è bello Questo software semplifica il nostro lavoro.
Ora, possiamo realizzare lo spettacolo di Hoshmer-Lemes test di bontà di adattamento sul set di dati, giudicare la precisione della probabilità prevista del modello.
L'ipotesi è:
H0: Il modello si adatta bene.
H1: Il modello non si adatta bene.
e, valore p> 0,05 accetteremo H0 e rifiuteremo H1.
Per eseguire il test in R dobbiamo installare il mkMisc pacchetto.
HLgof.test(fit=Trainingmodel1$fitted.values,obs=Modello di allenamento1$y)

Qui, possiamo vedere che il p-value è maggiore di 0.05, quindi accetteremo H0. Ora, è dimostrato che il nostro modello è ben regolato.
Generazione di una curva ROC per i dati di allenamento
Un'altra tecnica per analizzare la bontà di adattamento della regressione logistica è il Misure ROC (caratteristiche di funzionamento del ricevitore). Le misure ROC sono la sensibilità, specificità 1, falso positivo e falso negativo. Le due misure che usiamo ampiamente sono la sensibilità e la specificità.. La sensibilità misura la bontà dell'accuratezza del modello, mentre la specificità misura la debolezza del modello.
Per farlo in R dobbiamo installare un pacchetto PROC.
baratto = roccia(risposta=Modello di allenamento1$y,predittore = Trainingmodel1$fitted.values,trama=T) baratto $ auc
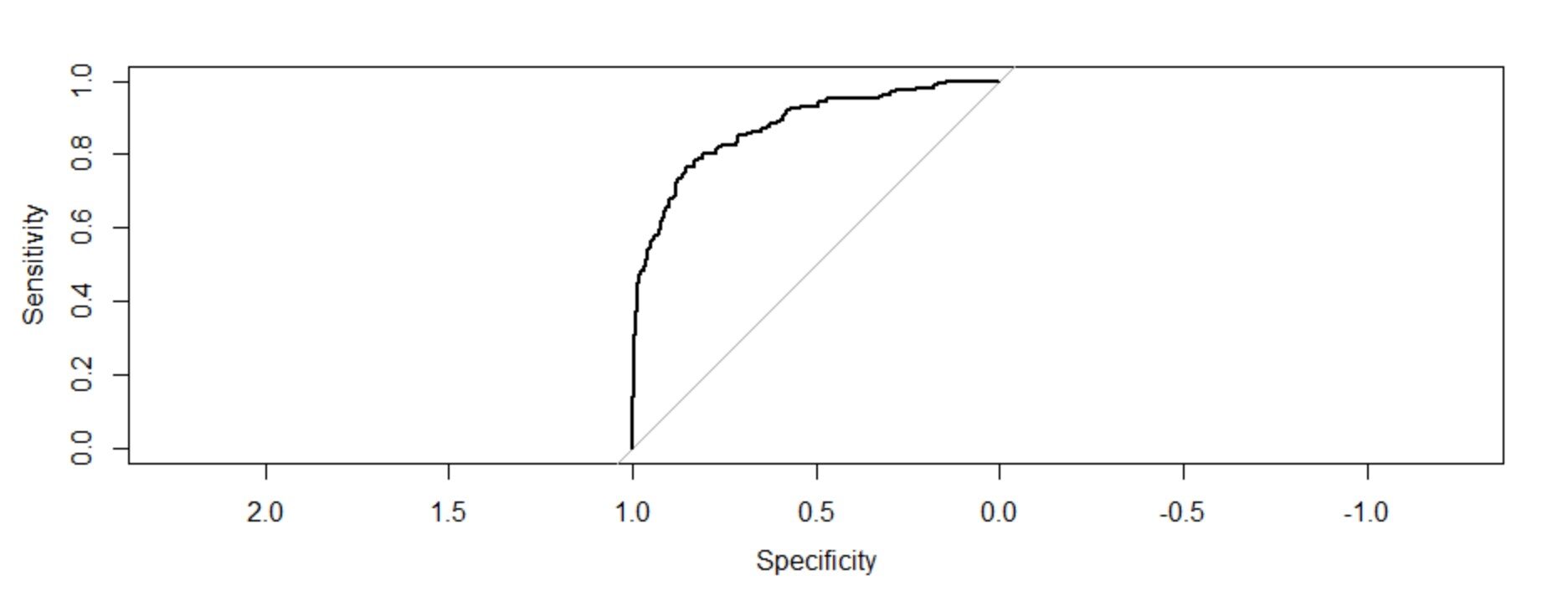
L'area sotto la curva: 0.8759
Interpretazione della figura:
Il grafico di queste due misurazioni ci fornisce un grafico concavo che mostra come la sensibilità sta aumentando 1-la specificità sta aumentando ma a una velocità decrescente. Il valore C (AUC) o el valor del indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... de concordancia da la medida del área bajo la curva ROC. Se c = 0,5, avrebbe significato che il modello non può discriminare perfettamente tra 0 e 1 risposte. Quindi implica che il modello iniziale non può dire perfettamente quali dipendenti lasceranno e chi rimarranno..
Ma qui possiamo vedere che il nostro valore c è molto maggiore di 0.5. è 0,8759. Il nostro modello può perfettamente discriminare tra 0 e 1. Perciò, possiamo concludere con successo che si tratta di un modello ben adattato.
Creazione della classifica per il set di dati di allenamento:
trpred=ifelse(test=Trainingmodel1$fitted.values>0.5,si = 1, no=0) tavolo(Modello di allenamento1$y,trpred)
I set di codici di cui sopra, il valore previsto della probabilità maggiore di 0, .5, allora il valore dello stato è 1, altrimenti è 0. in base a questo criterio, Questo codice ripubblica le risposte “sì” e “No” a partire dal “Portare”. Ora, È importante comprendere la percentuale di stime che corrispondono alla credenza iniziale ottenuta dal set di dati. Qui confronteremo la coppia (1-1) e (0-0).
Ho 1025 dati di allenamento. Abbiamo previsto {(839 + 78) / 1025} * 100 =89% correttamente.
Confronto del risultato con i dati del test:
Ora confronteremo il modello con i dati di test. È molto simile a un test di precisione.
testpred=predict.glm(object=Trainingmodel1,newdata=TestingData,tipo = "risposta")
testpred
tsroc=roc(response=TestingData$Attrition,predittore = testpred,trama=T)
tsroc$auc
Ora, abbiamo incorporato i dati dei test nel modello di addestramento e vedremo il ROC.
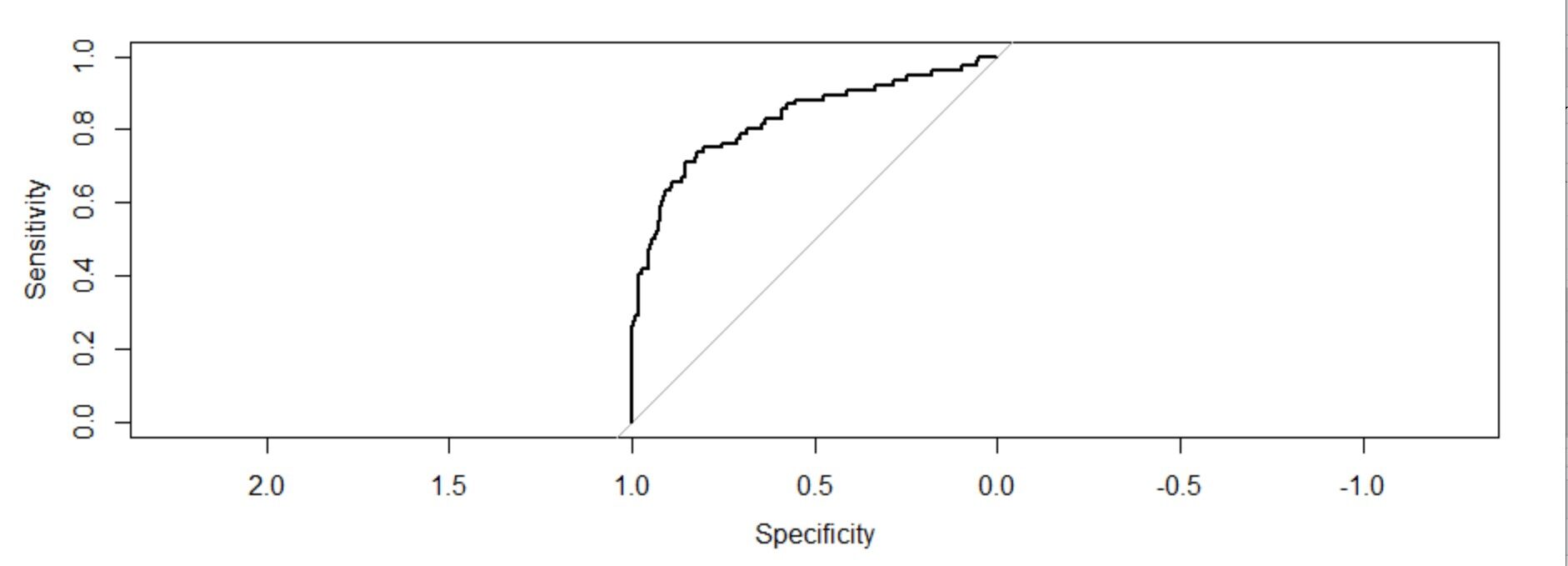
L'area sotto la curva: 0,8286 (c valore). È anche di gran lunga superiore a 0,5. È anche un modello ben montato.
Crea la tabella di classificazione per il set di dati del test
testpred = ifelse(test = testpred>0.5,si=1,no=0) tavolo(TestDati$Attrito,testpred)

Ho 445 dati di test. abbiamo previsto correttamente {(362 + 28) / 445} * 100 =87,64%.
Dovuto, possiamo dire che il nostro modello di regressione logistica è un modello molto ben adattato. Qualsiasi insieme di dati sull'abbandono dei dipendenti può essere analizzato utilizzando questo modello.
Quale pensi sia un buon modello? Commenta qui sotto
CONCLUSIONE:
Abbiamo imparato con successo come analizzare l'attrito dei dipendenti utilizzando "REGRESSIONE LOGISTICA" con l'aiuto del software R. Solo con un paio di codici e un set di dati adeguato, un'azienda può facilmente capire di quali aree deve occuparsi per rendere il posto di lavoro più confortevole per i propri dipendenti e ripristinare l'energia delle proprie risorse umane per un periodo più lungo.
L'immagine in primo piano è tratta da trainingjournal.com
Link al mio profilo LinkedIn:
https://www.linkedin.com/in/tiasa-patra-37287b1b4/





