Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Dopo aver compreso e lavorato con questo tutorial pratico, Maggio:
- Capire cos'è l'analisi di coorte e di coorte.
- Gestione dei valori mancanti
- Estrazione del mese dalla data
- Assegna una coorte a ciascuna transazione
- Assegna un indice di coorte a ciascuna transazione
- Calcola il numero di clienti unici in ogni gruppo.
- Crea una tabella di coorte per il tasso di ritenzione
- Visualizza la tabella delle coorti utilizzando la mappa termica
- Interpretare il tasso di ritenzione
Cos'è l'analisi di coorte e di coorte??
Una coorte è un insieme di utenti che hanno qualcosa in comune. Una coorte tradizionale, ad esempio, dividere le persone per la settimana o il mese in cui sono state acquisite per la prima volta. Quando si fa riferimento a raggruppamenti non dipendenti dal tempo, il termine segmento è spesso usato al posto di coorte.
L'analisi di coorte è una tecnica analitica descrittiva nell'analisi di coorte. I clienti sono divisi in coorti che si escludono a vicenda, che vengono poi tracciati nel tempo. Gli indicatori di vanità non offrono lo stesso livello di prospettiva della ricerca di coorte. Aiuta nell'interpretazione più profonda dei modelli di alto livello fornendo metriche del ciclo di vita del consumatore e del prodotto.
In genere, ci sono tre tipi principali di coorti:
- coorti di tempo: clienti che si sono registrati per un prodotto o servizio durante un determinato periodo di tempo.
- Coorti comportamentali: clienti che hanno acquistato un prodotto o si sono abbonati a un servizio in passato.
- Coorti di dimensioni: fare riferimento alle diverse dimensioni dei clienti che acquistano i prodotti o servizi dell'azienda.
tuttavia, faremo Analisi di coorte basata sul tempo. I clienti saranno divisi in coorti di acquisizione in base al mese del loro primo acquisto. Dopo, l'indice di coorte sarebbe assegnato a ciascuno degli acquisti del cliente, che rappresenterà il numero di mesi dalla prima transazione.
obiettivi:
- Trova la percentuale di clienti attivi rispetto al numero totale di clienti dopo ogni mese: Segmentazione dei clienti
- Interpretare il tasso di ritenzione
Ecco il codice completo per questo tutorial. se vuoi seguire le informazioni mentre segui il tutorial.
Fase coinvolta nell'analisi del tasso di ritenzione della coorte
1. Caricamento e pulizia dei dati
2. Assegna la coorte e calcola il
passo 2.1
- Tronca l'oggetto dati a uno richiesto (qui ci vuole il mese, quindi la data della transazione)
- Crea un oggetto groupby con la colonna di destinazione (qui, identificativo del cliente)
- Trasforma con una funzione min () assegnare a ciascun cliente la data di transazione più piccola nel valore del mese.
Il risultato di questo processo è la coorte del mese di acquisizione per ogni cliente, vale a dire, abbiamo assegnato a ciascun cliente la coorte del mese di acquisizione.
passo 2.2
- Calcola la compensazione temporale estraendo valori interi per l'anno, mese e giorno di un oggetto datetime ().
- Calcola il numero di mesi tra qualsiasi transazione e la prima transazione per ogni cliente. Useremo i valori TransactionMonth e CohortMonth per farlo.
Il risultato di questo sarà cohortIndex, vale a dire, la differenza tra “mese di transazione” e “Mese di coorte” in termini di numero di mesi e chiama la colonna “indice di coorte”.
passo 2.3
- Crea un oggetto groupby con CohortMonth e CohortIndex.
- Contare il numero di clienti in ciascun gruppo applicando la funzione pandas nunique ().
- Reimposta l'indice e crea il pivot dei panda con CohortMonth sulle righe, CohortIndex in colonne e customer_id conta come valori.
Il risultato di questo sarà la tabella che servirà come base per il calcolo del tasso di ritenzione e anche altre matrici.
3. Calcola matrici commerciali: Tasso di ritenzione.
La fidelizzazione misura quanti clienti di ogni coorte sono tornati nei mesi successivi.
- Utilizzo del framework di dati denominato cohort_counts, selezioneremo le prime colonne (pari al numero totale di clienti in coorti)
- Calcola la proporzione di quanti di questi clienti sono tornati nei mesi successivi.
Il risultato dà un tasso di ritenzione.
4. Visualizzazione del tasso di ritenzione
5. Interpretazione del tasso di ritenzione
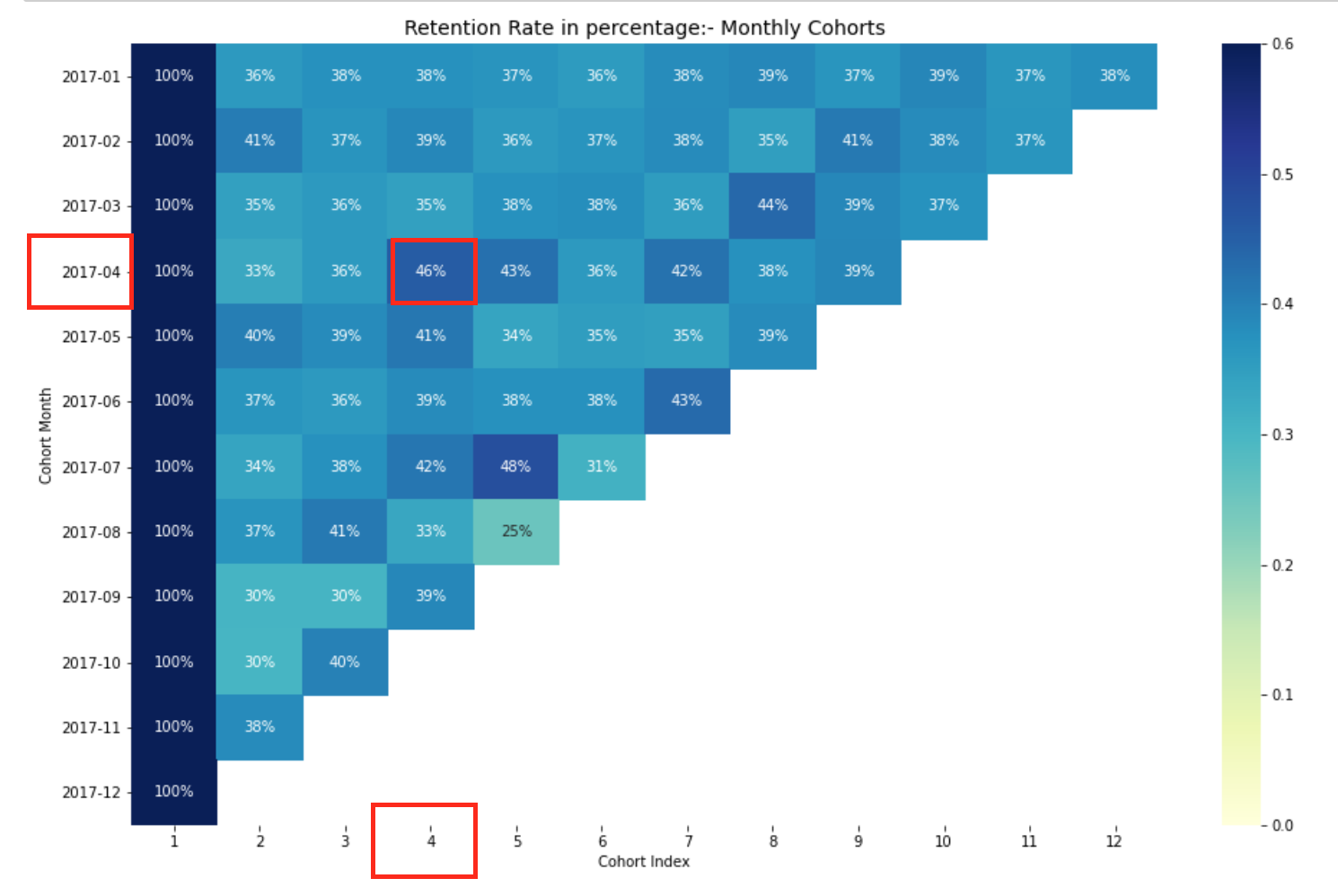
Tasso di ritenzione mensile della coorte.
Iniziamo:
Importa librerie
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import datetime as dt
import missingno as msno
from textwrap import wrap
Caricamento e pulizia dei dati
# Loading dataset transaction_df = pd.read_excel(«transcazioni.xlsx») # View data transaction_df.head()
Comprobando y trabajando con valor faltante
# Inspect missing values in the dataset print(transaction_df.isnull().values.sum()) # Replace the ' 's with NaN transaction_df = transaction_df.replace(" ",Np. Nan) # Impute the missing values with mean imputation transaction_df = transaction_df.fillna(transaction_df.media()) # Count the number of NaNs in the dataset to verify print(transaction_df.isnull().values.sum())
Stampa(transaction_df.info())
per col in transaction_df.columns:
# Check if the column is of object type
if transaction_df[col].dtypes == 'oggetto':
# Impute with the most frequent value
transaction_df[col] = transaction_df[col].riempire(transaction_df[col].value_counts().indice[0])
# Count the number of NaNs in the dataset and print the counts to verify
print(transaction_df.isnull().values.sum())
Qui, podemos ver que tenemos 1542 valores nulos. Que tratamos con valores medios y más frecuentes según el tipo de datos. Ahora que hemos completado nuestra limpieza y comprensión de datos, comenzaremos el análisis de cohorte.
Asignó las cohortes y calculó la compensación mensual.
# Una funzione che analizzerà la coorte basata sull'ora della data: 1 day of month def get_month(X): return dt.datetime(x.anno, x.mese, 1) # Create transaction_date column based on month and store in TransactionMonth transaction_df['TransactionMonth'] = transaction_df['transaction_date'].applicare(get_month) # Grouping by customer_id and select the InvoiceMonth value grouping = transaction_df.groupby('customer_id')['TransactionMonth'] # Assigning a minimum InvoiceMonth value to the dataset transaction_df['CohortMonth'] = grouping.transform('min') # piano di stampa 5 rows print(transaction_df.head())
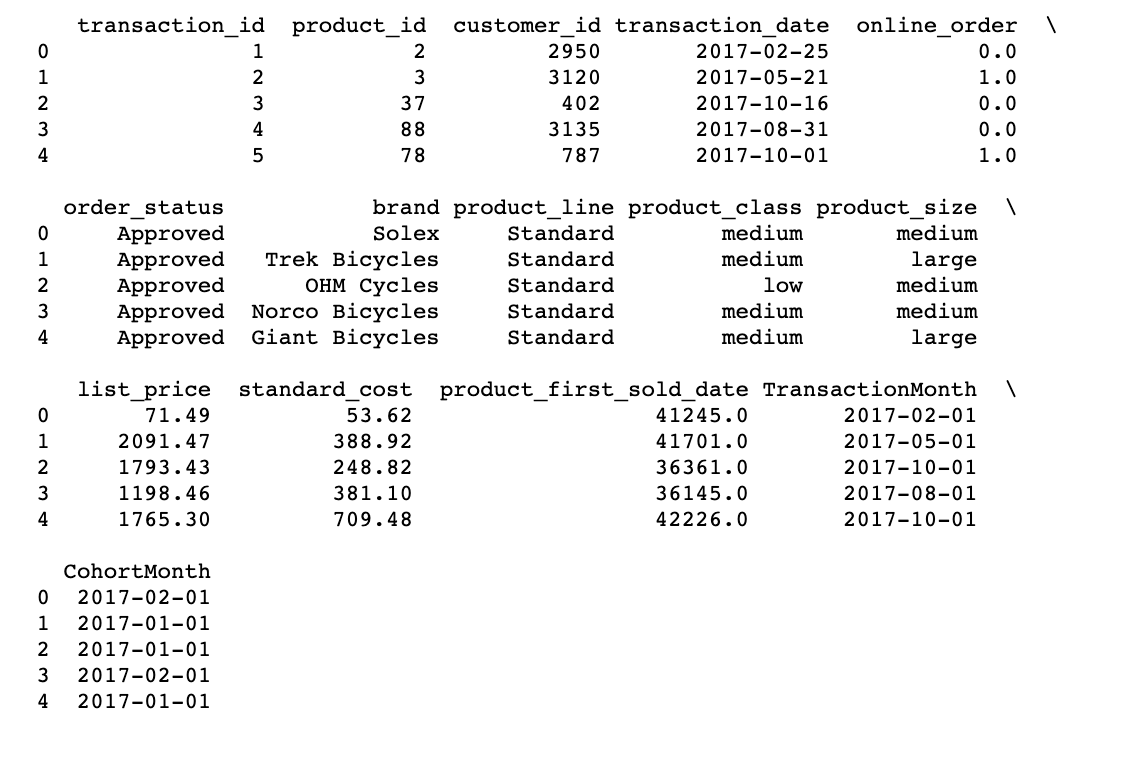
Cálculo de la compensación de tiempo en el mes como índice de cohorte
Il calcolo della compensazione temporale per ogni transazione consente di valutare le metriche per ciascuna coorte in modo comparabile.
Primo, creeremo 6 variabili che catturano il valore intero degli anni, mesi e giorni per la data di transazione e di coorte utilizzando la funzione get_date_int ().
def get_date_int(df, colonna):
anno = df[colonna].dt.year
month = df[colonna].dt.month
day = df[colonna].dt.day
return year, mese, giorno
# Getting the integers for date parts from the `InvoiceDay` column
transcation_year, transaction_month, _ = get_date_int(transaction_df, 'TransactionMonth')
# Getting the integers for date parts from the `CohortDay` column
cohort_year, cohort_month, _ = get_date_int(transaction_df, 'CohortMonth')
Ora calcoleremo la differenza tra le date delle fatture e le date di coorte in anni, mesi separatamente. quindi calcola la differenza totale di mesi tra i due. Questo sarà l'indice di coorte o di compensazione del nostro mese, che useremo nella prossima sezione per calcolare il tasso di ritenzione.
# Get the difference in years years_diff = transcation_year - cohort_year # Calculate difference in months months_diff = transaction_month - cohort_month """ Estrarre la differenza in mesi da tutti i valori precedenti "+1" in aggiunto alla fine in modo che il primo mese sia contrassegnato come 1 invece di 0 per una più facile interpretazione. """ transaction_df['CohortIndex'] = years_diff * 12 + months_diff + 1 Stampa(transaction_df.head(5))
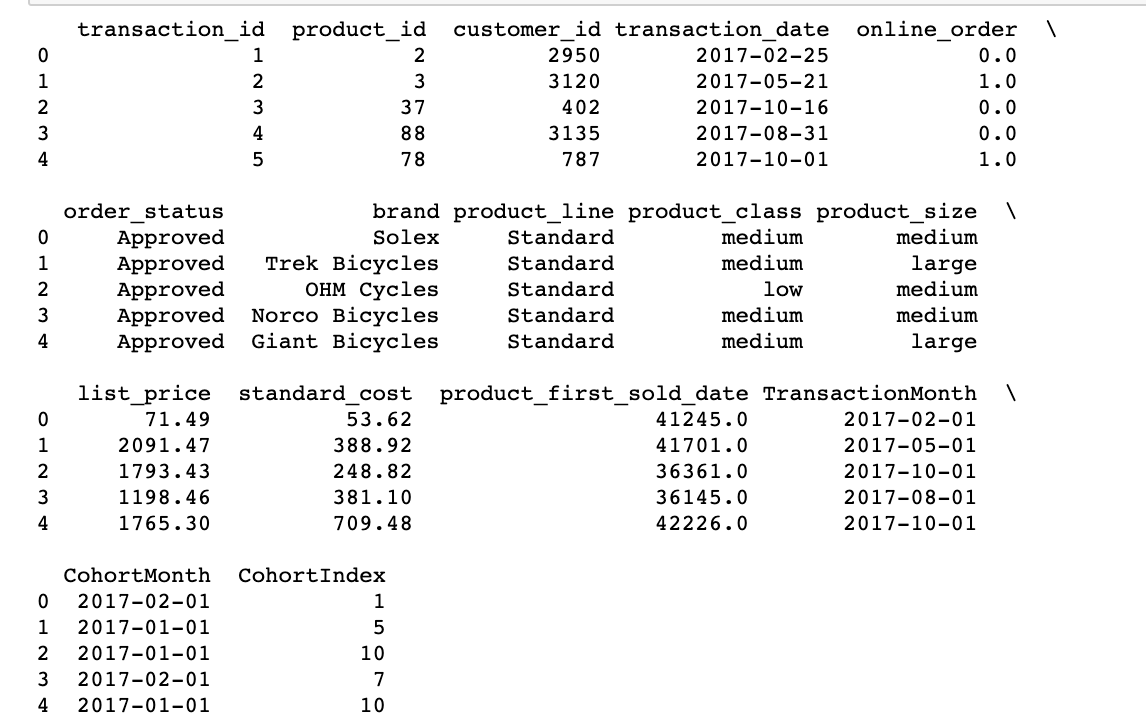
Qui, All'inizio, creiamo un gruppo() oggetto con CohortMonth e CohortIndex e salvalo come raggruppamento.
Dopo, chiamiamo questo oggetto, selezioniamo il Identificazione del cliente e calcola la media.
Quindi memorizziamo i risultati come cohort_data. Dopo, Reimpostare l'indice prima di chiamare la funzione pivot per poter accedere alle colonne ora memorizzate come indici.
Finalmente, Creiamo una tabella pivot saltando
- CohortMes al parametro index,
- Indice di coorte al parametro column,
- Identificazione del cliente al parametro values.
e arrotondarlo a 1 digita e vedi cosa otteniamo.
# Counting daily active user from each chort grouping = transaction_df.groupby(['CohortMonth', 'CohortIndex']) # Counting number of unique customer Id's falling in each group of CohortMonth and CohortIndex cohort_data = grouping['customer_id'].applicare(Pd. Serie.nunique) cohort_data = cohort_data.reset_index() # Assigning column names to the dataframe created above cohort_counts = cohort_data.pivot(index='CoorteMonth', colonne="CohortIndex", valori="identificativo del cliente") # Piano di stampa 5 rows of Dataframe cohort_data.head()
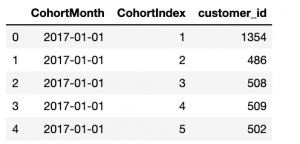
Calcola le metriche aziendali: tasso di ritenzione
La percentuale di clienti attivi rispetto al numero totale di clienti dopo un intervallo di tempo specificato è chiamata tasso di ritenzione..
In questa sezione, calcoleremo il conteggio della conservazione per ogni mese di coorte abbinato all'indice di coorte
Ora che abbiamo un conteggio dei clienti mantenuti per ciascuno coorteMes e indice di coorte. Calcoleremo il tasso di ritenzione per ogni coorte.
Creeremo una tabella pivot per questo scopo.
cohort_sizes = cohort_counts.iloc[:,0] ritenzione = cohort_counts.divide(dimensioni_coorte, asse=0) # Conversione del tasso di ritenzione in percentuale e Arrotondamento. ritenzione.rotondo(3)*100
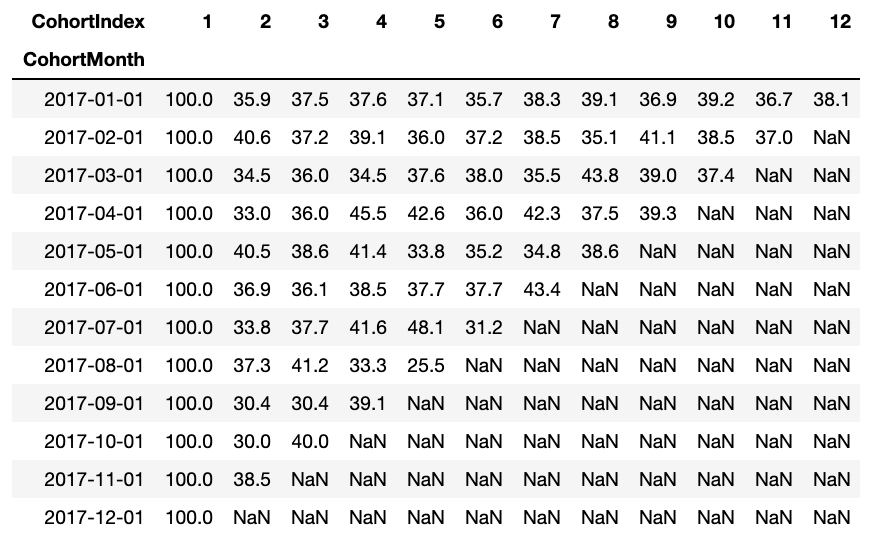
Il frame di dati del tasso di ritenzione rappresenta il cliente trattenuto in tutte le coorti. Possiamo leggerlo come segue:
- Il valore dell'indice rappresenta la coorte
- Le colonne rappresentano il numero di mesi trascorsi dalla coorte corrente
Ad esempio: Il valore in CoorteMese 2017-01-01, CohortIndex 3 è 35,9 e rappresenta 35,9% dei clienti della coorte 2017-01 si sono svolti nel 3è mes.
Cosa c'è di più, puoi vedere nel tasso di ritenzione DataFrame:
- Tasso di ritenzione Il primo indice, vale a dire, il primo mese è da 100%, poiché tutti i clienti di quel particolare cliente si sono registrati nel primo mese
- Il tasso di ritenzione può aumentare o diminuire negli indici successivi.
- I valori in basso a destra hanno molti valori NaN.
Visualizzazione del tasso di ritenzione
Prima di iniziare a disegnare la nostra mappa termica, impostiamo l'indice del nostro frame di dati del tasso di conservazione su un formato di stringa più leggibile.
average_standard_cost.index = average_standard_cost.index.strftime('%Y-%m')
# Initialize the figure
plt.figure(figsize=(16, 10))
# Adding a title
plt.title(«Costo standard medio: Coorti mensili, fontsize = 14)
# Creating the heatmap
sns.heatmap(average_standard_cost, annot = Vero,vmin = 0.0, vmax =20,cmap="YlGnBu", fmt="G")
plt.ylabel('Mese della coorte')
plt.xlabel('Indice di coorte')
plt.yticks( rotazione='360')
plt.mostra()
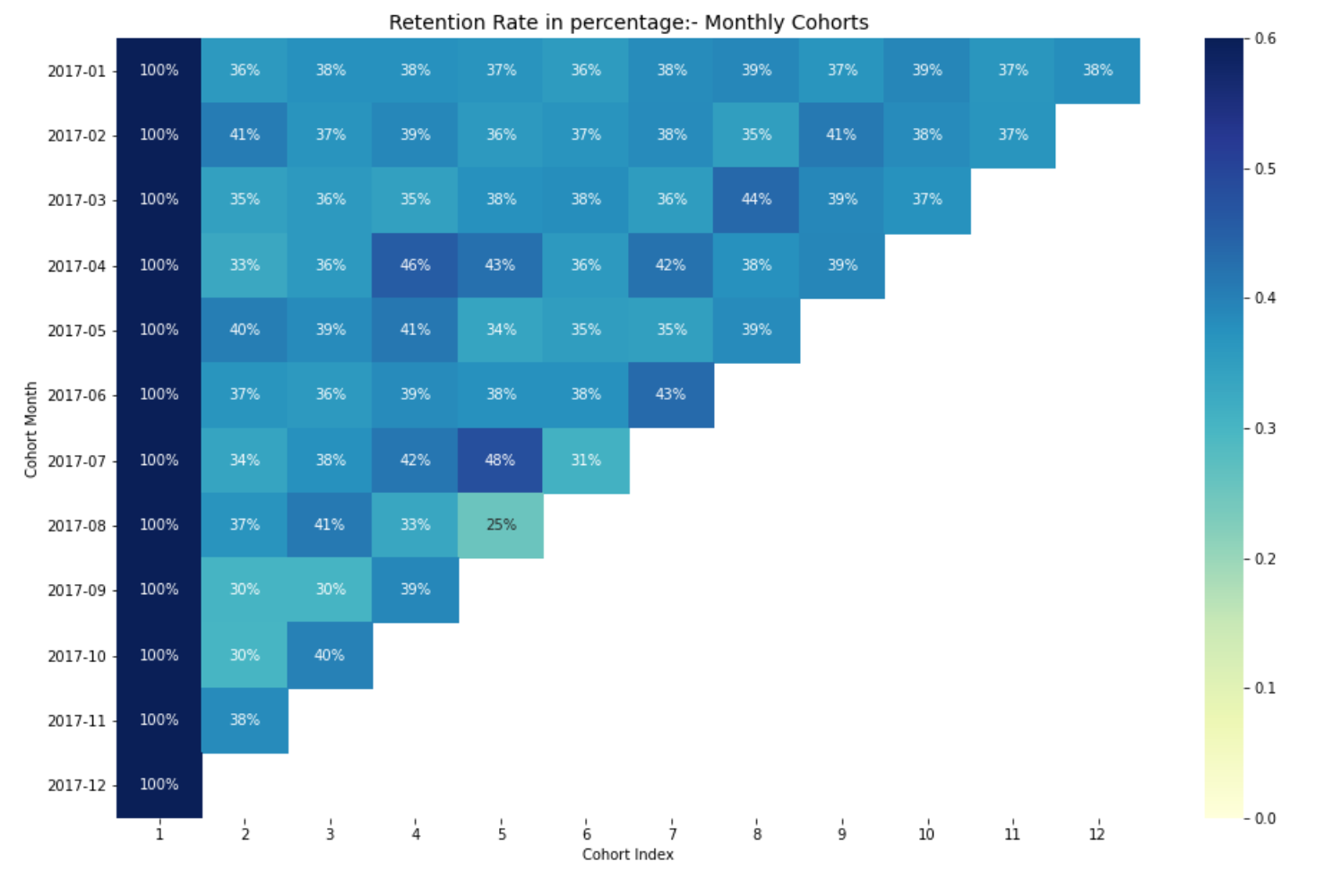
Interpretazione del tasso di ritenzione
Il modo più efficace per visualizzare e analizzare i dati di analisi di coorte è attraverso una mappa di calore., come abbiamo fatto in precedenza. Fornisce sia i valori metrici effettivi che la codifica a colori per vedere visivamente le differenze nei numeri.
Se non hai una conoscenza di base su heatmap, puoi controllare il mio blog. Analisi esplorativa dei dati per principianti con Python, dove ho parlato di mappe di calore per principianti.
Qui, avere 12 coorti per ogni mese e 12 indici di coorte. Più scure sono le sfumature del blu, più alti saranno i valori. A) Sì, se vediamo nel mese della coorte 2017-07 nel quinto indice di coorte, vediamo il tono blu scuro con a 48% il che significa che il 48% delle coorti che hanno firmato a luglio 2017 erano attivi 5 mesi dopo.
Questo conclude la nostra analisi di coorte per il tasso di ritenzione.. Allo stesso modo, possiamo eseguire analisi di coorte per altre matrici commerciali.
Clicca qui per saperne di più sull'analisi di coorte per le aziende gratis con DataCamp.(Link di affiliazione)
Perciò, abbiamo completato la nostra analisi di coorte, dove hai imparato le analisi di base e di coorte, condurre coorti temporali, lavorare con il perno dei panda e creare una tabella di attesa insieme alla visualizzazione. Abbiamo anche imparato a esplorare altre matrici.
Ora, puoi iniziare a creare ed esplorare da solo le metriche che sono importanti per la tua attività.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





