introduzione
L'analisi esplorativa dei dati è una delle best practice utilizzate oggi nella scienza dei dati. Iniziare una carriera nella scienza dei dati, Le persone generalmente non conoscono la differenza tra analisi dei dati e analisi esplorativa dei dati.. Non c'è una grande differenza tra i due, Ma entrambi hanno scopi diversi..

Analisi esplorativa dei dati (EDA): L'analisi esplorativa dei dati è un complemento Statistica inferenziale, che tende ad essere abbastanza rigido con regole e formule. A livello avanzato, L'EDA implica l'esame e la descrizione del set di dati da diverse angolazioni e quindi il riepilogo.
Analisi dei dati: L'analisi dei dati è la statistica e la probabilità di scoprire tendenze nel set di dati. Utilizzato per visualizzare i dati storici utilizzando alcuni strumenti di analisi. Consente di eseguire il drill-down per trasformare le metriche, Fatti e cifre nelle iniziative di miglioramento.
Analisi esplorativa dei dati (EDA)
Esploreremo un set di dati ed eseguiremo analisi esplorative dei dati in Python. Puoi consultare il nostro Corso online su Python per salire a bordo con Python.
I principali argomenti da trattare sono i seguenti:
– Gestire il valore mancante
– puoi personalizzarlo in base alle tue particolari esigenze per comunicare il messaggio desiderato
– Trattamento dei valori anomali
– NormalizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... e ridimensionamento (variabili numeriche)
– Codifica di variabili categoriali (Variabili fittizie)
– Analisi bivariata
# Importazione di librerie

# Caricamento del set di dati
Caricheremo il file Excel delle auto EDA usando i panda. Per questo, Utilizzeremo il file read_excel.
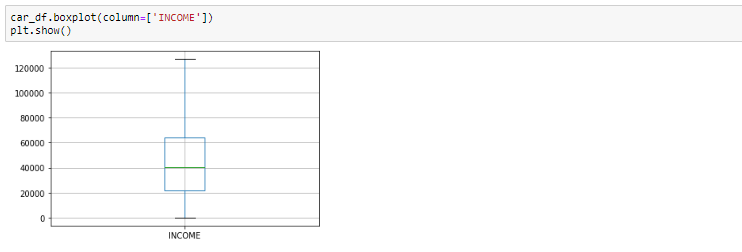
Diagramma box dopo la rimozione dei valori anomali
# Esplorazione dei dati di base
In questo passaggio, Eseguiremo le seguenti operazioni per verificare di cosa è composto il set di dati. Controlleremo le seguenti cose:
– Gestione set di dati
– La forma del set di dati
– informazioni sul set di dati
– Riepilogo del set di dati
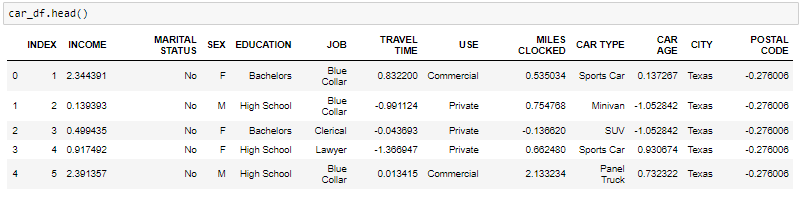
- La funzione head ti dirà i migliori record nel set di dati. Per impostazione predefinita, Python ti mostra solo il 5 Record principali.
-
L'attributo shape ci dice una serie di osservazioni e variabili che abbiamo nel set di dati. Se utiliza para verificar la dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e... dei dati. Il set di dati dell'auto ha 303 osservazioni e 13 variabili nel dataset.

-
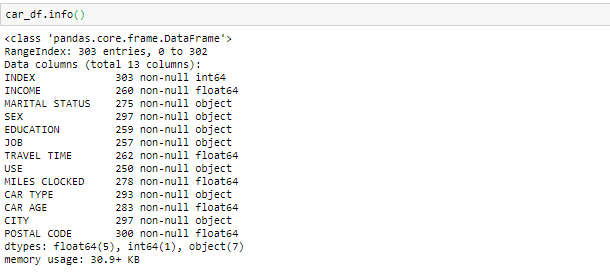
Informazioni () viene utilizzato per verificare le informazioni sui dati e sui tipi di dati di ciascun attributo.

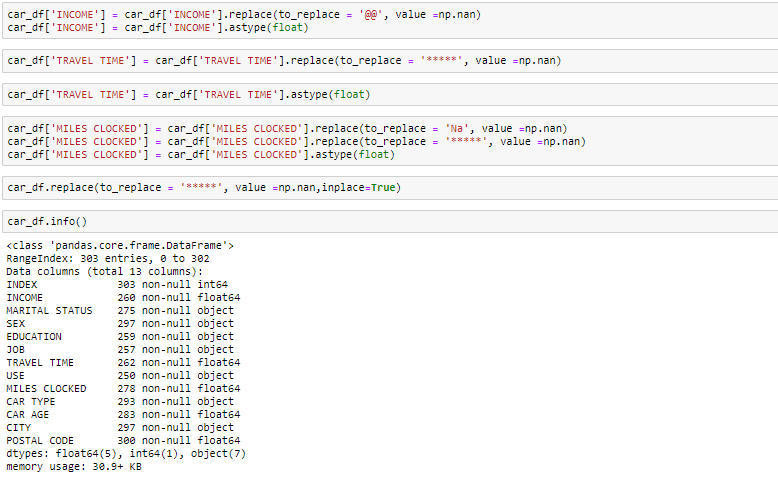
Osservando i dati nella funzione primaria e nelle informazioni, sabemos que la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... Ingresos y el tiempo de viaje son de tipo de datos flotantes en lugar del objeto. Poi lo trasformeremo nel galleggiante. Cosa c'è di più, Esistono alcuni valori non validi come @@ e ‘*'Nei dati tratteremo come valori mancanti.

-
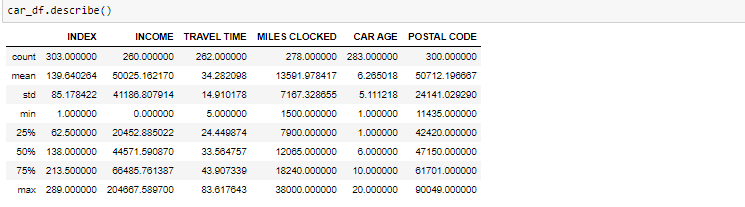
Il metodo descritto ti aiuterà a vedere come sono stati distribuiti i dati per i valori numerici. Possiamo vedere chiaramente il valore minimo, Valori medi, diversi valori percentili e valori massimi.


Gestione del valore mancante
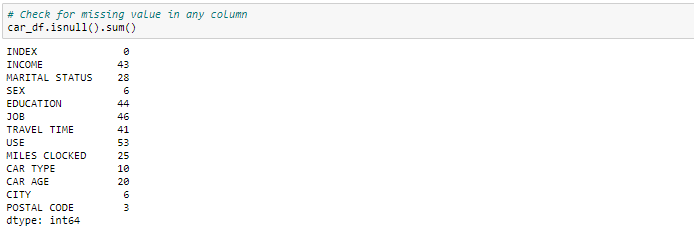
Possiamo vedere che abbiamo diversi valori persi nelle rispettive colonne. Esistono diversi modi per gestire i valori mancanti nel set di dati. E quale tecnica usare quando dipende davvero dal tipo di dati con cui hai a che fare..
- Rimuove i valori persi: in questo caso, Rimuoviamo i valori mancanti da quelle variabili. Nel caso in cui manchino pochissimi valori, Puoi eliminarli.
- Imputare con valore medio: per la colonna numerica, È possibile sostituire i valori mancanti con valori medi. Prima di sostituire con il valore medio, Si consiglia di verificare che la variabile non abbia valori estremi .ie outliers.
- Imputare con valore mediano: per la colonna numerica, È inoltre possibile sostituire i valori mancanti con valori mediani. Nel caso in cui tu abbia valori estremi, come valori anomali, es aconsejable utilizar el método de la medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.....
- Imputare con valore di modo: per la colonna categoriale, È possibile sostituire i valori mancanti con valori di modalità, vale a dire, Il frequente.
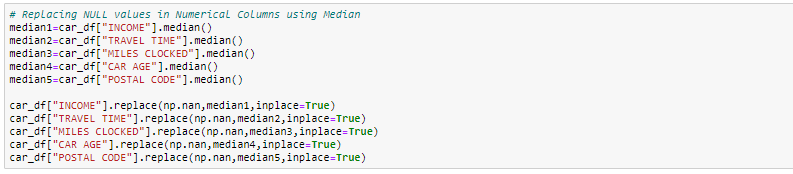
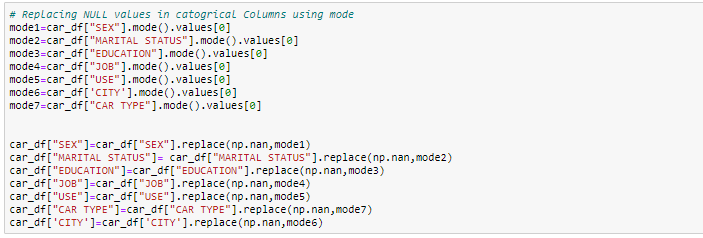
In questo esercizio, sostituire le colonne numeriche con valori mediani e, per le colonne categoriali, Rimuoveremo i valori mancanti.

Gestione di record duplicati
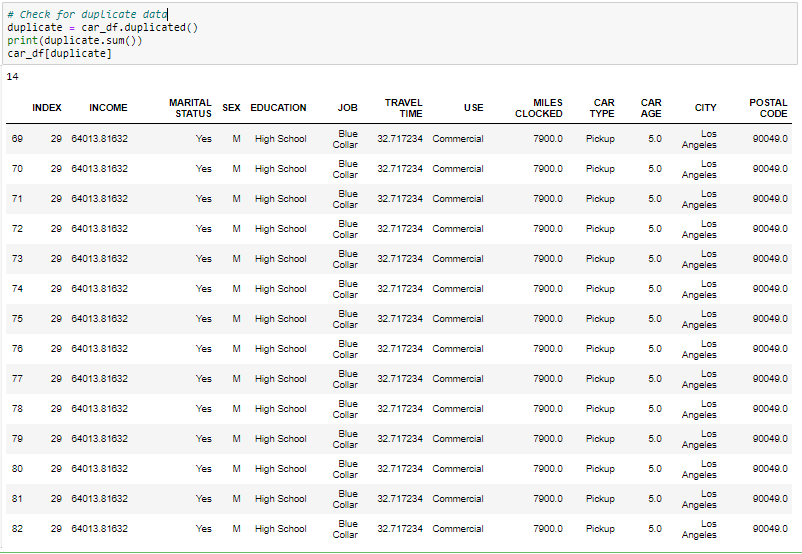
Dal momento che abbiamo 14 Record duplicati nei dati, Lo rimuoveremo dal set di dati per ottenere solo record diversi. Dopo aver eliminato il duplicato, Verificheremo se i duplicati sono stati rimossi dal set di dati o meno.
![]()

Gestione degli outlier
Outlier, essendo le osservazioni più estreme, può includere il massimo o il minimo del campione, o entrambi, a seconda che siano estremamente alti o bassi. tuttavia, Il campione massimo e minimo non sono sempre valori anomali perché potrebbero non essere insolitamente lontani da altre osservazioni..
Di solito identifichiamo i valori anomali con l'aiuto del diagramma a scatola, Quindi qui il diagramma a caselle mostra alcuni dei punti dati al di fuori dell'intervallo dei dati.
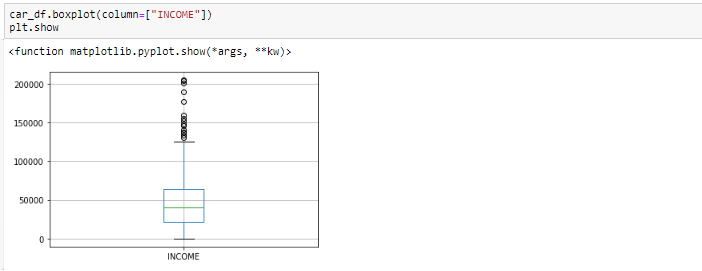
Diagramma della casella prima di rimuovere i valori anomali
Guardando il diagramma della scatola, sembra che le variabili REDDITO, avere valori anomali presenti nelle variabili. Questi valori anomali devono essere presi in considerazione e ci sono diversi modi per trattarli.:
- Rimuove i valori anomali
- Sostituire l'outlier utilizzando IQR
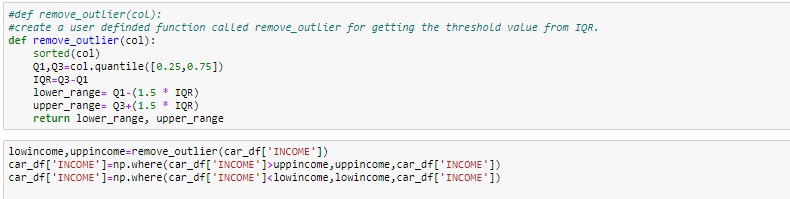
#Boxplot Dopo aver eliminato i valori anomali
Analisi bivariata
Quando parliamo di analisi bivariata, significa analizzare 2 variabili. Come sappiamo che ci sono variabili numeriche e categoriali, C'è un modo per analizzare queste variabili come mostrato di seguito:
-
Numerico vs numerico
1. Diagramma di dispersioneIl grafico a dispersione è uno strumento grafico utilizzato in statistica per visualizzare la relazione tra due variabili. Consiste in un insieme di punti in un piano cartesiano, dove ogni punto rappresenta una coppia di valori corrispondenti alle variabili analizzate. Questo tipo di grafico consente di identificare i modelli, Tendenze e possibili correlazioni, facilitare l'interpretazione dei dati e il processo decisionale sulla base delle informazioni visive presentate....
2. Grafico a lineeIl grafico a linee è uno strumento visivo utilizzato per rappresentare i dati nel tempo. È costituito da una serie di punti collegati da linee, che permette di osservare le tendenze, Fluttuazioni e modelli nei dati. Questo tipo di grafico è particolarmente utile in aree come l'economia, Meteorologia e ricerca scientifica, semplificando il confronto di diversi set di dati e l'identificazione dei comportamenti su tutta la linea..
3. Mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate.... para la correlación
4. Trama comune -
Categorico vs numerico
1. Grafico a barreIl grafico a barre è una rappresentazione visiva dei dati che utilizza barre rettangolari per mostrare confronti tra diverse categorie. Ogni barra rappresenta un valore e la sua lunghezza è proporzionale ad esso. Questo tipo di grafico è utile per visualizzare e analizzare le tendenze, facilitare l'interpretazione delle informazioni quantitative. È ampiamente utilizzato in varie discipline, come le statistiche, Marketing e ricerca, Grazie alla sua semplicità ed efficacia....
2. Cornice per violino
3. Diagramma a caselle categoriali
4.Piazzola calda -
Due variabili categoriali
1. Grafico a barre
2. Grafico a barre raggruppato
3. Grafico a punti
Se abbiamo bisogno di trovare la correlazione-
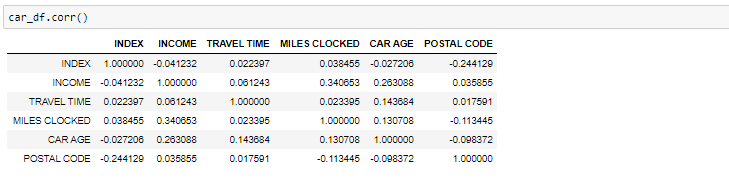
Correlazione tra tutte le variabili
Normalizzazione e scalabilità
Spesso, Le variabili nel set di dati sono di scale diverse, vale a dire, Una variabile è in milioni e le altre in solo 100. Ad esempio, nel nostro set di dati, L'affitto ha valori in migliaia e l'età è solo a due cifre. Poiché i dati per queste variabili sono di scale diverse, È difficile confrontare queste variabili.
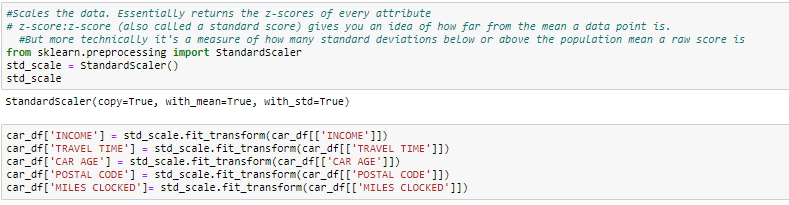
La scala delle feature (Noto anche come normalizzazione dei dati) è il metodo utilizzato per standardizzare la gamma di caratteristiche dei dati. Perché l'intervallo di valori nei dati può variare notevolmente, diventa un passaggio necessario nella pre-elaborazione dei dati durante l'utilizzo di algoritmi di apprendimento automatico.
In questo metodo, Convertiamo variabili con diverse scale di misure in un'unica scala. StandardScaler normalizza i dati utilizzando la formula (X-media) / deviazione standard. Lo faremo solo per le variabili numeriche.
CODIFICAZIONE
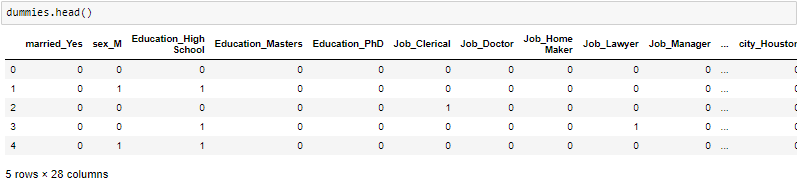
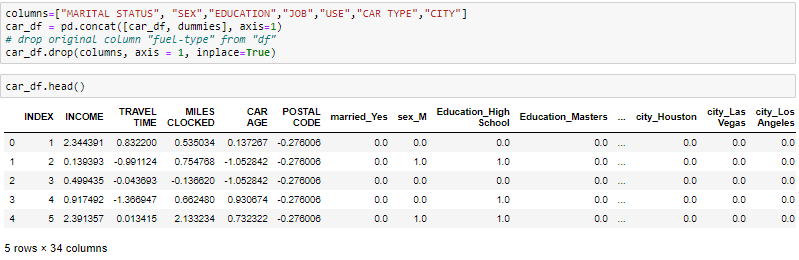
One-Hot-Encoding viene utilizzato per creare variabili fittizie per sostituire le categorie in una variabile categoriale nelle caratteristiche di ciascuna categoria e rappresentarla utilizzando 1 oh 0 Secondo la presenza o l'assenza di valore categoriale nel registro.
Questo è necessario, Poiché gli algoritmi di apprendimento automatico funzionano solo con dati numerici. Ecco perché è necessario convertire la colonna categoriale in numerica.
get_dummies è il metodo che crea una variabile fittizia per ogni variabile categoriale.

Circa l'autore

Ritika Singh – Scienziato dei dati
Sono un data scientist di professione e un blogger per passione. Ho lavorato su progetti di machine learning per più di 2 anni. Qui troverai articoli su "Machine Learning", Statistiche, Apprendimento profondo, PNL e Intelligenza Artificiale".





