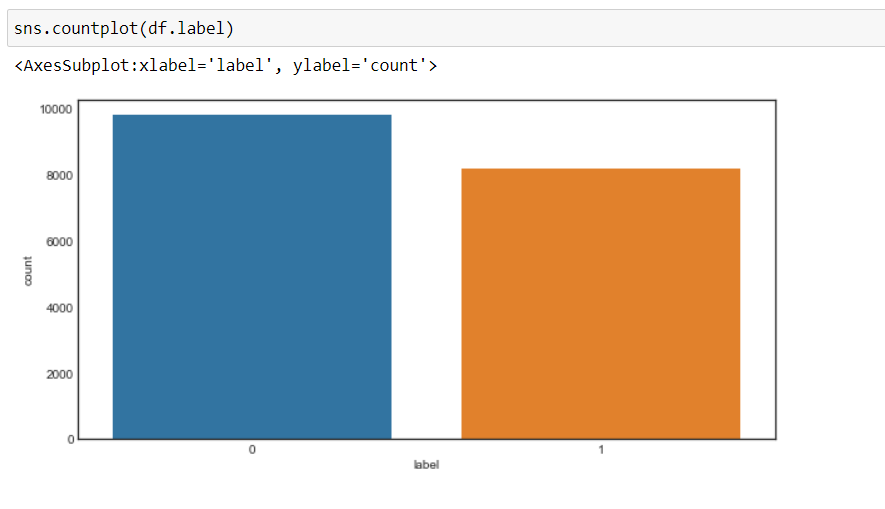
Ora, possiamo vedere che il nostro obiettivo è cambiato in 0 e 1, vale a dire, 0 per negativo e 1 per positivo, e i dati sono più o meno in uno stato equilibrato.
Pretrattamento dei dati
Ora, elaboreremo i dati prima di convertirli in vettori e passarli al modello di apprendimento automatico.
Creeremo una funzione per la preelaborazione dei dati.
1. Primo, Itereremo attraverso ogni record e useremo a frase regolare, rimuoveremo qualsiasi carattere a parte gli alfabeti.
2. Dopo, convertiremo la stringa in minuscolo Che cosa, la parola “Bene” è diverso dalla parola “Buona”.
Perché, non convertito in minuscolo, causerà un problema quando creiamo vettori di queste parole, poiché verranno creati due vettori diversi per la stessa parola che non vogliamo.
3. Dopo, Cercheremo parole vuote nei dati e le cancelleremo. Per le parole sono parole comunemente usate in una frase come “il”, “un”, “un”, eccetera. che non aggiungono molto valore.
4. Dopo, Ci esibiremo lematizzazione in ogni parola, vale a dire, Cambia le diverse forme di una parola in un unico elemento chiamato motto.
UN motto è una forma base di una parola. Ad esempio, “correre”, “correre” e “correre” Sono tutte forme dello stesso lessema, dove “correre” è il motto. Perciò, Stiamo convertendo tutte le apparizioni dello stesso lessema al loro rispettivo motto..
5. E quindi restituire un corpus di dati elaborati.
Ma prima creeremo un oggetto WordNetLemmatizer e quindi eseguiremo la trasformazione.
#object of WordNetLemmatizer
lm = WordNetLemmatizer()
def text_transformation(df_col):
corpo = []
per l'articolo in df_col:
new_item = re.sub('[^ a-zA-Z]',' ',str(articolo))
new_item = new_item.inferiore()
new_item = new_item.split()
new_item = [lm.lemmatize(parola) per Word in new_item se Word non è in Set(stopwords.parole('inglese'))]
corpus.append(' '.join(str(X) per x in new_item))
corpus di ritorno
corpus = text_transformation(df['text'])
Ora creeremo un nuvola di parole. Si tratta di una tecnica di visualizzazione dei dati utilizzata per rappresentare il testo in modo tale che le parole più frequenti appaiano ingrandite rispetto alle parole meno frequenti. Questo ci dà un'idea di come appaiono i dati dopo essere stati elaborati attraverso tutti i passaggi fino ad ora.
rcParams['figure.figsize'] = 20,8
nuvola_parola = ""
per riga nel corpus:
per parola di fila:
parola_nuvola+=" ".aderire(parola)
wordcloud = WordCloud(larghezza = 1000, altezza = 500,colore_sfondo="bianco",min_font_size = 10).creare(word_cloud)
plt.imshow(nuvola di parole)
Produzione:
Borsa di parole
Ora, useremo il modello Bag of Words (ARCO), che viene utilizzato per rappresentare il testo sotto forma di un sacco di parole, vale a dire, la grammatica e l'ordine delle parole in una frase non hanno alcuna importanza, Invece, la molteplicità , vale a dire (Il numero di volte in cui una parola viene visualizzata in un documento) è la principale causa di preoccupazione.
Fondamentalmente, descrive l'occorrenza totale di parole all'interno di un documento.
Scikit-Impara Fornisce un modo semplice per eseguire la tecnica del sacchetto di parole utilizzando Metodo CountVectorizer.
Ora, Convertiremo i dati di testo in vettori, Aggiustare e trasformare il corpus che abbiamo creato.
cv = CountVectorizer(ngram_range=(1,2))
traindata = cv.fit_transform(corpus)
X = traindata
y = df.label
Lo prenderemo noi ngram_range Che cosa (1,2) Cosa significa un bigramma.
Ngram è una sequenza di 'n’ parole in una riga o in una frase. «ngram_range’ è un parametro, Cosa usiamo per dare importanza alla combinazione di parole, Che cosa “Reti sociali” ha un significato diverso da “sociale” e “media” separatamente.
Possiamo sperimentare il valore di ngram_range parametro e selezionare l'opzione che fornisce i risultati migliori.
Ora arriva la parte della creazione del modello di apprendimento automatico e in questo progetto, indosserò Classificatore forestale casuale, e regoleremo gli iperparametri usando GridSearchCV.
GridSearchCV() tomará los siguientes parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto....,
1. EstimatoreIl "Estimatore" è uno strumento statistico utilizzato per dedurre le caratteristiche di una popolazione da un campione. Si basa su metodi matematici per fornire stime accurate e affidabili. Esistono diversi tipi di stimatori, come l'imparzialità e la coerenza, che vengono scelti in base al contesto e all'obiettivo dello studio. Il suo corretto utilizzo è essenziale nella ricerca scientifica, Sondaggi e analisi dei dati.... il modello – RandomForestClassifier nel nostro caso
2. parametri: dizionario dei nomi degli iperparametri e dei loro valori
3. CV: significa pieghe di convalida incrociata
4. return_train_score: devuelve las puntuaciones de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... de los distintos modelos
5. n_jobs – no. lavori da eseguire in parallelo (“-1” significa che verranno utilizzati tutti i core della CPU, che riduce drasticamente i tempi di formazione)
Primo, creeremo un dizionario, “parametri” che conterrà i valori di diversi iperparametri.
Lo passeremo come parametro a GridSearchCV per addestrare il nostro modello di classificatore forestale casuale utilizzando tutte le possibili combinazioni di questi parametri per trovare il modello migliore.
parametri = {'max_features': ('auto','sqrt'),
'n_estimators': [500, 1000, 1500],
'max_depth': [5, 10, Nessuno],
'min_samples_split': [5, 10, 15],
'min_samples_leaf': [1, 2, 5, 10],
'bootstrap': [Vero, falso]}
Ora, adatteremo i dati nella ricerca della griglia e vedremo il miglior parametro usando l'attributo “best_params_” di GridSearchCV.
grid_search = GridSearchCV(Classificatore foresta casuale(),parametri,cv=5,return_train_score=Vero,n_jobs=-1) grid_search.fit(X,e) grid_search.best_params_
Produzione:

E più tardi, possiamo vedere tutti i modelli e i rispettivi parametri, il punteggio medio del test e la classifica, poiché GridSearchCV memorizza tutti i risultati nel file cv_risultati_ attributo.
per io nel raggio d'azione(432):
Stampa('Parameters: ',grid_search.cv_results_['params'][io])
Stampa('Mean Test Score: ',grid_search.cv_results_['mean_test_score'][io])
Stampa('Rank: ',grid_search.cv_results_['rank_test_score'][io])
Partenza: (un campione dell'output)

Ora, sceglieremo i migliori parametri ottenuti da GridSearchCV e creeremo un modello finale di classificatore di foreste casuali e quindi addestreremo il nostro nuovo modello.
rfc = RandomForestClassifier(max_features=grid_search.best_params_['max_features'], max_depth=grid_search.best_params_['max_depth'], n_estimators=grid_search.best_params_['n_estimators'], min_samples_split=grid_search.params_best_['min_samples_split'], min_samples_leaf=grid_search.params_best_['min_samples_leaf'], bootstrap=grid_search.best_params_['bootstrap']) rfc.fit(X,e)
Trasformazione dei dati di test
Ora, Leggeremo i dati di test ed eseguiremo le stesse trasformazioni che abbiamo fatto sui dati di training e infine valuteremo il modello nelle sue previsioni..
test_df = pd.read_csv('test.txt',delimitatore=";",nomi=['text','label'])
X_test,y_test = test_df.text,test_df.label #encode the labels into two classes , 0 e 1 test_df = custom_encoder(y_test) #pre-processing of text test_corpus = text_transformation(X_test) #convert text data into vectors testdata = cv.transform(test_corpus) #predict the target predictions = rfc.predict(TestData)
Evaluación del modelo
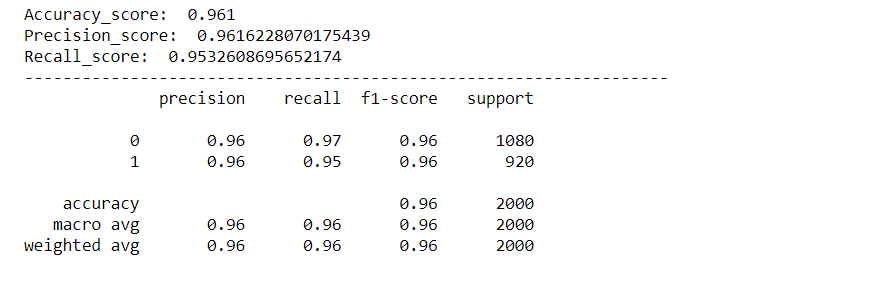
Evaluaremos nuestro modelo usando varias métricas como Accuracy Score, Punteggio di precisione, Punteggio di richiamo, Confusion Matrix y crearemos una curva roc para visualizar cómo se desempeñó nuestro modelo.
rcParams['figure.figsize'] = 10,5 plot_confusion_matrix(y_test,predizioni) acc_score = accuracy_score(y_test,predizioni) pre_score = precision_score(y_test,predizioni) rec_score = recall_score(y_test,predizioni) Stampa('Accuracy_score: ',acc_score) Stampa('Precision_score: ',pre_score) Stampa('Recall_score: ',rec_score) Stampa("-"*50) cr = classification_report(y_test,predizioni) Stampa(Cr)
Produzione:
Matrice di confusione:
Curva de Roc:
Encontraremos la probabilidad de la clase usando el método predict_proba () de Random Forest Classifier y luego trazaremos la curva roc.
predictions_probability = rfc.predict_proba(TestData) fpr,Tpr,soglie = roc_curve(y_test,predictions_probability[:,1]) plt.trama(fpr,Tpr) plt.trama([0,1]) plt.titolo('ROC Curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.mostra()
Come possiamo vedere, il nostro modello ha funzionato molto bene nella classificazione dei sentimenti, con un punteggio di precisione, precisione e recupero di ca. 96%. E anche la curva roc e la matrice di confusione sono eccellenti, il che significa che il nostro modello può classificare accuratamente le etichette, con meno possibilità di errore.
Ora, controlleremo anche l'input personalizzato e consentiremo al nostro modello di identificare il sentimento dell'istruzione di input.
Prevedi per input personalizzato:
def controllo_espressione(previsione_input):
se input_previsione == 0:
Stampa("L'istruzione di input ha un sentimento negativo.")
elif previsione_input == 1:
Stampa("L'istruzione di input ha Sentimento positivo.")
altro:
Stampa("Dichiarazione non valida.")
# function to take the input statement and perform the same transformations we did earlier
def sentiment_predictor(ingresso):
input = text_transformation(ingresso)
transformed_input = cv.transform(ingresso)
previsione = rfc.predict(transformed_input)
expression_check(predizione)
input1 = ["A volte voglio solo dare un pugno in faccia a qualcuno."]
input2 = ["I bought a new phone and it's so good."]
sentiment_predictor(input1) sentiment_predictor(ingresso2)
Produzione:
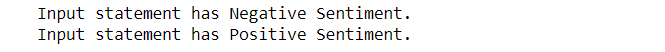
Hurra ·, ya que podemos ver que nuestro modelo clasificó con precisión los sentimientos detrás de las dos oraciones.
se ti piace questo articolo, sígueme en LinkedIn.
Y puede obtener el código completo y la salida de qui.
Las imágenes de salida se mantienen qui para referencia.
Eleonora?
Il supporto mostrato in questo articolo non è di proprietà di Analytics Vidhya e viene utilizzato a discrezione dell'autore.





