Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
L'analisi del sentiment si riferisce all'identificazione e alla classificazione dei sentimenti espressi nella fonte del testo.. I tweet sono spesso utili per generare molti dati di opinione dopo l'analisi.. Questi dati sono utili per comprendere l'opinione delle persone su una varietà di argomenti..
Perciò, abbiamo bisogno di sviluppare un Modello automatizzato di analisi del sentiment di Machine Learning per calcolare la percezione del cliente. A causa della presenza di personaggi inutili (collettivamente indicato come rumore) insieme a dati utili, È difficile implementare modelli in essi.
In questo articolo, il nostro obiettivo è quello di analizzare il sentiment dei tweet forniti dal Set di dati Sentiment140 sviluppando una pipeline di machine learning che prevede l'utilizzo di tre classificatori (Regressione logistica, Bernoulli Naive Bayes e SVM) insieme all'uso Frequenza dei termini – Frequenza inversa del documento (TF-IDF). Le prestazioni di questi classificatori vengono quindi valutate utilizzando precisione e Classificazioni F1.

Fonte immagine: Google Immagini
Dichiarazione problema
In questo progetto, cerchiamo di implementare un Modello di analisi del sentiment di Twitter che aiuta a superare le sfide dell'identificazione dei sentimenti dei tweet. I dettagli necessari per quanto riguarda il set di dati sono:
Il set di dati fornito è il Set di dati Sentiment140 composto da 1,600,000 tweet che sono stati estratti utilizzando l'API di Twitter. Le varie colonne presenti nel dataset sono:
- obbiettivo: la polarità del tweet (positivo o negativo)
- identificatori: ID tweet univoco
- Data: la data del tweet
- bandiera: Si riferisce alla consultazione. Se non esiste una query di questo tipo, allora NON E' CONSULTAZIONE.
- Nome utente: Si riferisce al nome dell'utente che ha twittato.
- testo: Si riferisce al testo del tweet.
Canalizzazione del progetto
Le varie fasi coinvolte nella Machine Learning Pipeline è così :
- Importare le dipendenze richieste
- Leggere e caricare il set di dati
- Analisi esplorativa dei dati
- Visualizzazione dei dati delle variabili di destinazione
- Pretrattamento dei dati
- Dividir nuestros datos en subconjuntos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... e test
- Trasformare il set di dati utilizzando TF-IDF Vectorizer
- Ruolo per la valutazione del modello
- Costruzione del modello
- conclusione
Cominciamo,
passo 1: Importare le dipendenze necessarie
# Utilità import re import numpy as np import pandas as pd # plotting import seaborn as sns from wordcloud import WordCloud import matplotlib.pyplot as plt # nltk from nltk.stem import WordNetLemmatizer # sklearn from sklearn.svm import LinearSVC from sklearn.naive_bayes import BernoulliNB from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics import confusion_matrix, classificazione_report
passo 2: leer y cargar el conjunto de datos
# Importing the dataset
DATASET_COLUMNS=['obbiettivo','ids','Data','bandiera','utente','testo']
DATASET_ENCODING = "ISO-8859-1 ·"
df = pd.read_csv('Project_Data.csv', encoding=DATASET_ENCODING, nomi=DATASET_COLUMNS)
df.campione(5)
Produzione:

passo 3: Analisi esplorativa dei dati
3.1: Cinco registros principales de datos
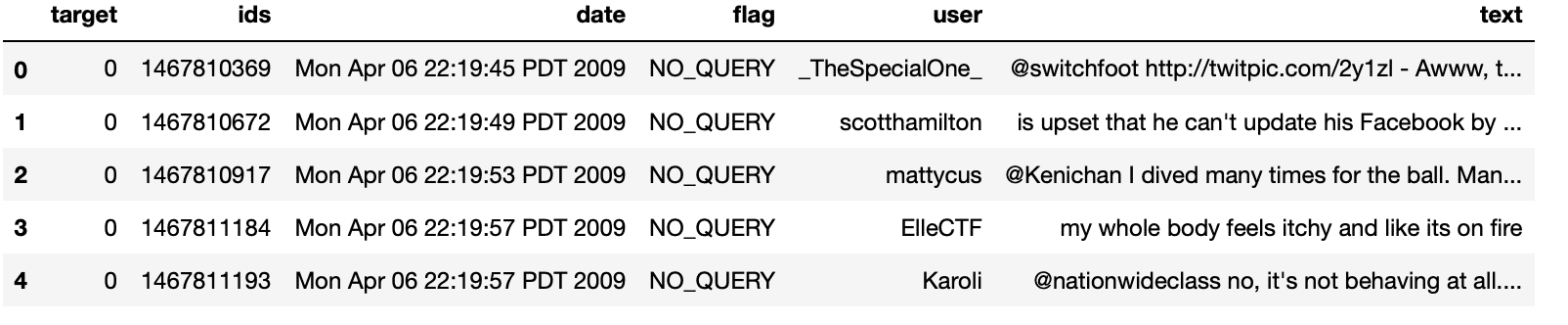
df.head()
Produzione:
3.2: Columnas / características en los datos
df.colonne
Produzione:
Indice(['obbiettivo', 'ids', 'Data', 'bandiera', 'utente', 'testo'], dtype="oggetto")
3.3: Longitud del conjunto de datos
Stampa('lunghezza dei dati è', len(df))
Produzione:
lunghezza dei dati è 1048576
3.4: Forma de los datos
df. forma
Produzione:
(1048576, 6)
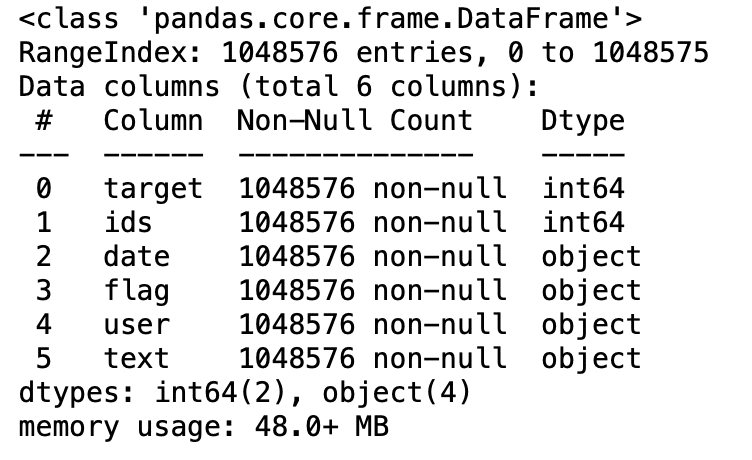
3.5: Información de datos
df.info()
Produzione:
3.6: Tipos de datos de todas las columnas
df.dtypes
Produzione:
target int64
ids int64
date object
flag object
user object
text object
dtype: oggetto
3.7: Comprobación de valores nulos
np.sum(df.isnull().qualunque(asse=1))
Produzione:
0
3.8: Filas y columnas en el conjunto de datos
Stampa("Il conteggio delle colonne nei dati è: ', len(df.colonne))
Stampa("Il conteggio delle righe nei dati è: ', len(df))
Produzione:
Il conteggio delle colonne nei dati è: 6 Il conteggio delle righe nei dati è: 1048576
3.9: Verifique valores objetivo únicos
df['obbiettivo'].unico()
Produzione:
Vettore([0, 4], dtype=int64)
3.10: Verifique el número de valores objetivo
df['obbiettivo'].Ora()
Produzione:
2
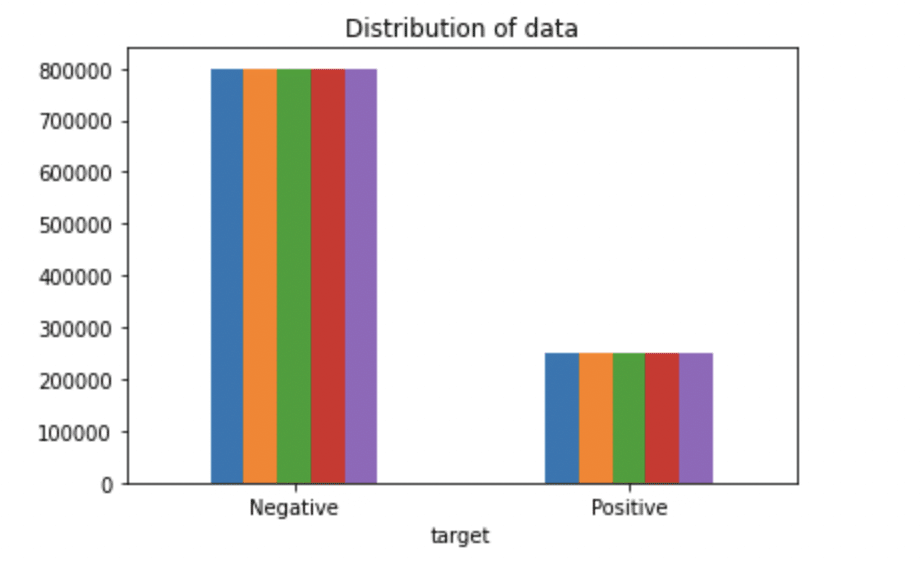
passo 4: Visualización de datos de variables de destino
# Rappresentazione del tracciato della distribuzione per il set di dati.
ax = df.groupby('obbiettivo').contare().complotto(tipo='bar', titolo="Distribuzione dei dati",legend=Falso)
ax.set_xticklabels(['Negativo','Positivo'], rotazione=0)
# Archiviazione dei dati negli elenchi.
testo, sentiment = elenco(df['testo']), elenco(df['obbiettivo'])
Produzione:
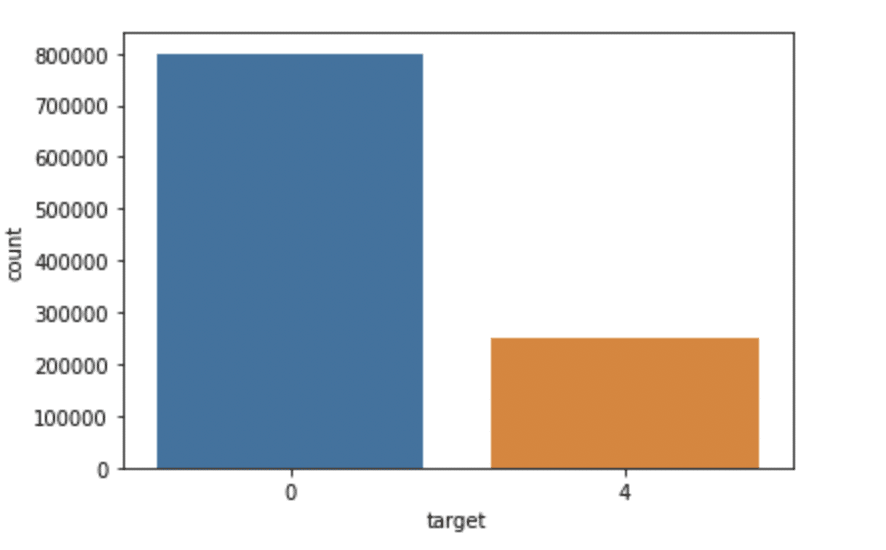
import seaborn come sns
sns.countplot(x='target', dati=df)
Produzione:
passo 5: pre-elaborazione dei dati
En la declaración del problema anterior antes de entrenar el modelo, Sono stati eseguiti diversi passaggi di pre-elaborazione sul set di dati che riguardavano principalmente l'eliminazione di parole vuote, eliminare emoji. Dopo, Documento di testo convertito in minuscolo per una migliore generalizzazione.
Successivamente, i punteggi sono stati puliti e rimossi, riducendo così il rumore non necessario proveniente dal set di dati. Successivamente, abbiamo anche rimosso caratteri ripetuti dalle parole insieme alla rimozione degli URL, in quanto non hanno alcun significato significativo.
Finalmente, Noi Derivanti (ridurre le parole alle loro radici derivate) e Lematizzazione (ridurre le parole derivate alla loro forma radice nota come lemma) per risultati migliori.
5.1: Selezionare il testo e la colonna di destinazione per ulteriori analisi
dati=df[['testo','obbiettivo']]
5.2: Sostituzione dei valori per facilitare la comprensione. (Assegnazione 1 a sentimento positivo 4)
dati['obbiettivo'] = dati['obbiettivo'].sostituire(4,1)
5.3: Stampare valori univoci delle variabili di destinazione
dati['obbiettivo'].unico()
Produzione:
Vettore([0, 1], dtype=int64)
5.4: Separazione dei tweet positivi e negativi
data_pos = dati[dati['obbiettivo'] == 1] data_neg = dati[dati['obbiettivo'] == 0]
5.5: prendendo un quarto dei dati in modo da poter eseguire facilmente sulla nostra macchina
data_pos = data_pos.iloc[:int(20000)] data_neg = data_neg.iloc[:int(20000)]
5.6: Combinazione di tweet positivi e negativi
dataset = pd.concat([data_pos, data_neg])
5.7: Rendere minuscolo il testo dell'istruzione
set di dati['testo']=set di dati['testo'].str.inferiore() set di dati['testo'].coda()
Produzione:

5.8: Set di definizioni contenente tutte le parole inglesi vuote.
stopwordlist = ['un', 'circa', 'sopra', 'dopo', 'di nuovo', 'ain', 'tutti', 'sono', 'an',
'e','qualsiasi','sono', 'come', 'at', 'essere', 'perché', 'stato', 'prima',
'essere', 'sotto', 'tra',"entrambi", 'di', 'può', 'D', 'fatto', 'fare',
'fa', 'fare', 'giù', 'durante', «ciascuno»,'pochi', 'per', 'a partire dal',
«ulteriormente», 'aveva', 'ha', 'avere', 'avere', 'lui', 'lei', 'qui',
'la sua', 'se stessa', 'lui', 'se stesso', 'suo', 'come', 'io', 'se', 'in',
'in','è', 'esso', 'suo', 'se stesso', 'solo', 'll', 'm', 'ma',
'io', 'di più', 'la maggior parte','mio', 'me stesso', 'ora', 'O', 'di', 'Su', 'una volta',
'solo', 'o', 'altro', 'nostro', 'nostro','noi stessi', 'fuori', 'proprio', 'Rif','S', 'stesso', 'lei', "Shes", 'dovrebbe', "dovrebbero",'così', 'alcuni', «tale»,
'T', 'di', 'Quello', "thatll", 'il', 'loro', 'loro', 'loro',
"se stessi", 'allora', 'lì', 'queste', 'loro', 'questo', «quelli»,
'attraverso', 'a', 'troppo','sotto', 'fino a', 'su', 've', 'molto', 'era',
'noi', 'erano', 'cosa', 'quando', 'dove','quale','mentre', 'chi', «chi»,
'perché', 'volontà', 'insieme a', 'vinto', 'e', 'tu', "youd","ti troverai", "Youre",
"hai", 'tuo', 'tuo', 'te stesso', 'voi stessi']
5.9: Limpiar y eliminar la lista de palabras vacías anterior del texto del tweet
STOPWORDS = set(stopwordlist)
def cleaning_stopwords(testo):
Restituzione " ".aderire([parola per parola in str(testo).diviso() se word non è in STOPWORDS])
set di dati['testo'] = set di dati['testo'].applicare(testo lambda: cleaning_stopwords(testo))
set di dati['testo'].testa()
Produzione:

5.10: Limpieza y eliminación de puntuaciones
import string
english_punctuations = string.punctuation
punctuations_list = english_punctuations
def cleaning_punctuations(testo):
traduttore = str.maketrans('', '', punctuations_list)
return text.translate(Translator)
set di dati['testo']= set di dati['testo'].applicare(lambda x: cleaning_punctuations(X))
set di dati['testo'].coda()
Produzione:

5.11: Limpieza y eliminación de caracteres repetidos
def cleaning_repeating_char(testo):
restituisci re.sub(R'(.)1+', r'1', testo)
set di dati['testo'] = set di dati['testo'].applicare(lambda x: cleaning_repeating_char(X))
set di dati['testo'].coda()
Produzione:

5.12: Limpieza y eliminación de URL
def cleaning_URLs(dati):
restituisci re.sub('((www.[^s]+)|(https?://[^s]+))',' ',dati)
set di dati['testo'] = set di dati['testo'].applicare(lambda x: cleaning_URLs(X))
set di dati['testo'].coda()
Produzione:

5.13: Limpieza y eliminación de números numéricos
def cleaning_numbers(dati):
restituisci re.sub('[0-9]+', '', dati)
set di dati['testo'] = set di dati['testo'].applicare(lambda x: cleaning_numbers(X))
set di dati['testo'].coda()
Produzione:

5.14: Obtención de tokenización del texto del tweet
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'w+')
set di dati['testo'] = set di dati['testo'].applicare(tokenizer.tokenize)
set di dati['testo'].testa()
Produzione:

5.15: Aplicación de la derivación
import nltk st = nltk.PorterStemmer() def stemming_on_text(dati): testo = [st.stem(parola) per Word nei dati] return data dataset['testo']= set di dati['testo'].applicare(lambda x: stemming_on_text(X)) set di dati['testo'].testa()
Produzione:

5.16: Aplicación de Lemmatizer
lm = nltk. WordNetLemmatizer()
def lemmatizer_on_text(dati):
testo = [lm.lemmatize(parola) per Word nei dati]
return data
dataset['testo'] = set di dati['testo'].applicare(lambda x: lemmatizer_on_text(X))
set di dati['testo'].testa()
Produzione:

5.17: Separazione della funzione di input e dell'etichetta
X=data.text
y=data.target
5.18: traccia una nuvola di parole per tweet negativi
data_neg = dati['testo'][:800000]
plt.figure(dimensione del fico = (20,20))
wc = WordCloud(max_words = 1000 , larghezza = 1600 , altezza = 800,
collocazioni=Falso).creare(" ".aderire(data_neg))
plt.imshow(Wc)
Produzione:
5.19: traccia una nuvola di parole per tweet positivi
data_pos = dati['testo'][800000:]
wc = WordCloud(max_words = 1000 , larghezza = 1600 , altezza = 800,
collocazioni=Falso).creare(" ".aderire(data_pos))
plt.figure(dimensione del fico = (20,20))
plt.imshow(Wc)
Produzione:
passo 6: Suddividere i nostri dati in sottoinsiemi di formazione e test
# Separando l'oggetto 95% dati per i dati di addestramento e 5% for testing data
X_train, X_test, y_train, y_test = train_test_split(X,e,test_size = 0.05, random_state =26105111)
passo 7: Trasformare il set di dati utilizzando TF-IDF Vectorizer
7.1: Installare il vectorizer TF-IDF
vectoriser = TfidfVectorizer(ngram_range=(1,2), max_features=500000)
vectoriser.fit(X_treno)
Stampa('No. di feature_words: ', len(vectoriser.get_feature_names()))
Produzione:
No. di feature_words: 500000
7.2: Trasformare i dati utilizzando TF-IDF Vectorizer
X_train = vectoriser.transform(X_treno) X_test = vectoriser.transform(X_test)
passo 8: Ruolo per la valutazione del modello
Dopo il training del modello, applichiamo le misure di valutazione per verificare le prestazioni del modello. Di conseguenza, utilizamos los siguientes parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... de evaluación para verificar el rendimiento de los modelos respectivamente:
- Puntuación de precisión
- Matriz de confusión con trama
- Curva ROC-AUC
def model_Evaluate(modello): # Predict values for Test dataset y_pred = model.predict(X_test) # Stampare le metriche di valutazione per il set di dati. Stampa(classificazione_report(y_test, y_pred)) # Compute and plot the Confusion matrix cf_matrix = confusion_matrix(y_test, y_pred) categorie = ['Negativo','Positivo'] group_names = ['True Neg','Falso Pos', 'Falso Neg','True Pos'] group_percentages = ['{0:.2%}'.formato(valore) per il valore in cf_matrix.flatten() / np.sum(cf_matrix)] etichette = [F'{V1}n{v2}' per v1, v2 in zip(group_names,group_percentages)] etichette = np.asarray(etichette).rimodellare(2,2) sns.heatmap(cf_matrix, annot = etichette, cmap = 'Blues',fmt="", xticklabels = categorie, yticklabels = categorie) plt.xlabel("Valori previsti", fontdict = {'dimensione':14}, labelpad = 10) plt.ylabel("Valori effettivi" , fontdict = {'dimensione':14}, labelpad = 10) plt.titolo ("Matrice di confusione", fontdict = {'dimensione':18}, pad = 20)
passo 9: Costruzione di modelli
En el planteamiento del problema hemos utilizado tres modelos diferentes respectivamente:
- Naive Bernoulli Bayes
- SVM (supporto macchina vettoriale)
- Regressione logistica
L'idea alla base della scelta di questi modelli è che vogliamo testare tutti i classificatori nel set di dati., da modelli semplici a modelli complessi, e poi cerca di trovare quello che offre le migliori prestazioni tra loro.
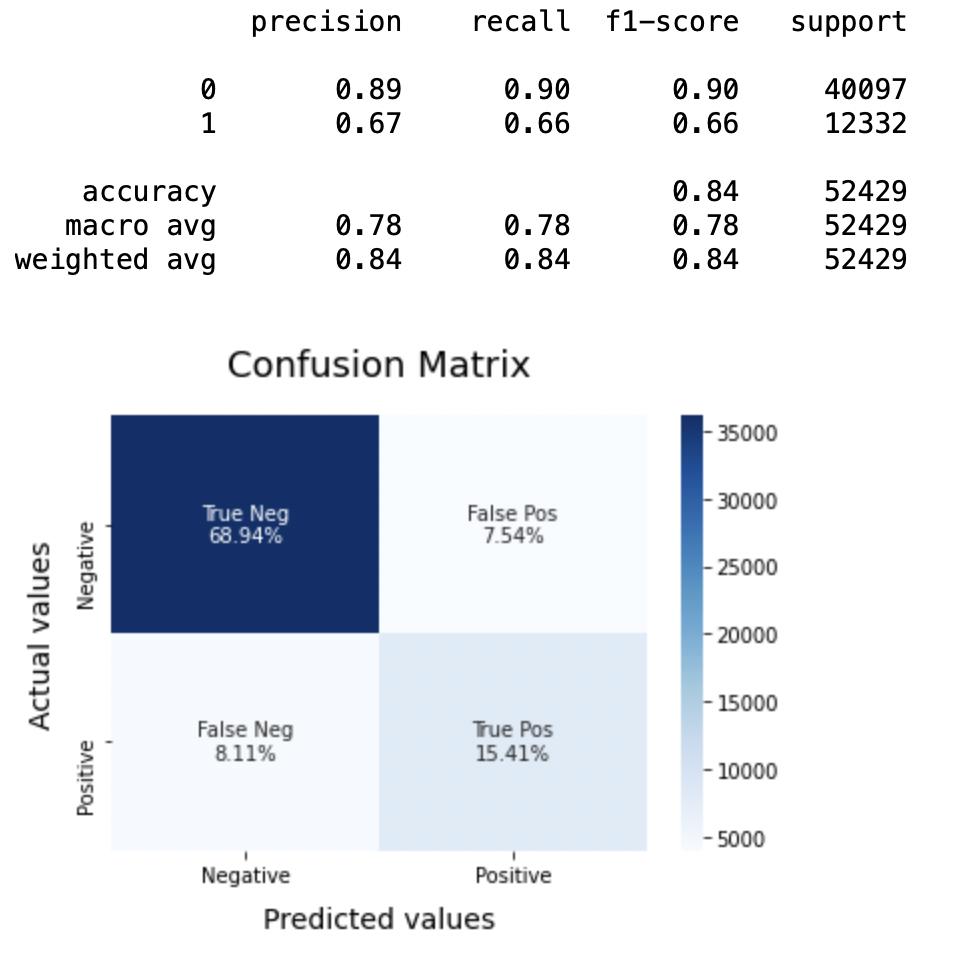
8.1: Modello-1
BNBmodel = BernoulliNB() BNBmodel.fit(X_treno, y_train) model_Evaluate(Modello BNB) y_pred1 = BNBmodel.predict(X_test)
Produzione:
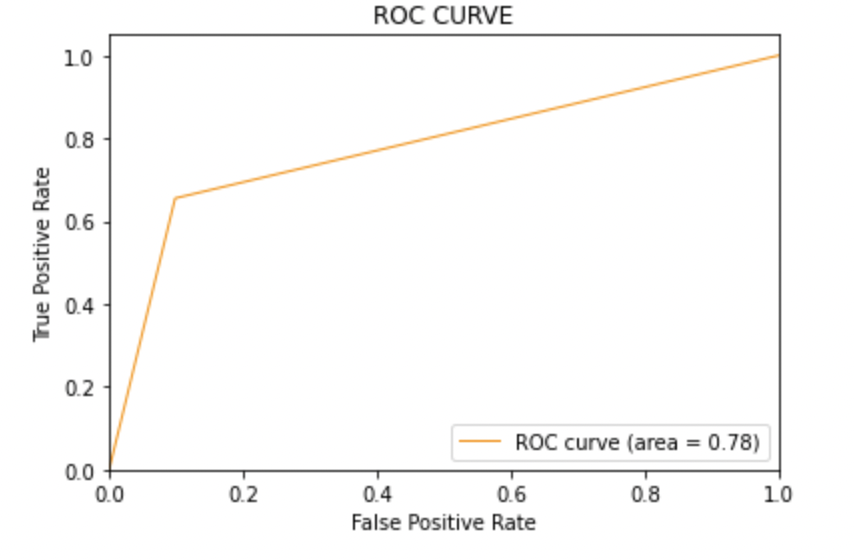
8.2: Tracciare la curva ROC-AUC per il modello 1
da sklearn.metrics importare roc_curve, auc
fpr, Tpr, soglie = roc_curve(y_test, y_pred1)
roc_auc = auc(fpr, Tpr)
plt.figure()
plt.trama(fpr, Tpr, colore="darkorange", lw=1, etichetta="Curva ROC (area = %0,2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Tasso di falsi positivi')
plt.ylabel("Tasso positivo vero")
plt.titolo('CURVA ROC')
plt.legend(loc ="in basso a destra")
plt.mostra()
Produzione:
8.3: Modello-2:
SVCmodel = LinearSVC() SVCmodel.fit(X_treno, y_train) model_Evaluate(SVCmodel) y_pred2 = SVCmodel.predict(X_test)
Produzione:
8.4: Tracciare la curva ROC-AUC per il modello 2
da sklearn.metrics importare roc_curve, auc
fpr, Tpr, soglie = roc_curve(y_test, y_pred2)
roc_auc = auc(fpr, Tpr)
plt.figure()
plt.trama(fpr, Tpr, colore="darkorange", lw=1, etichetta="Curva ROC (area = %0,2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Tasso di falsi positivi')
plt.ylabel("Tasso positivo vero")
plt.titolo('CURVA ROC')
plt.legend(loc ="in basso a destra")
plt.mostra()
Produzione:
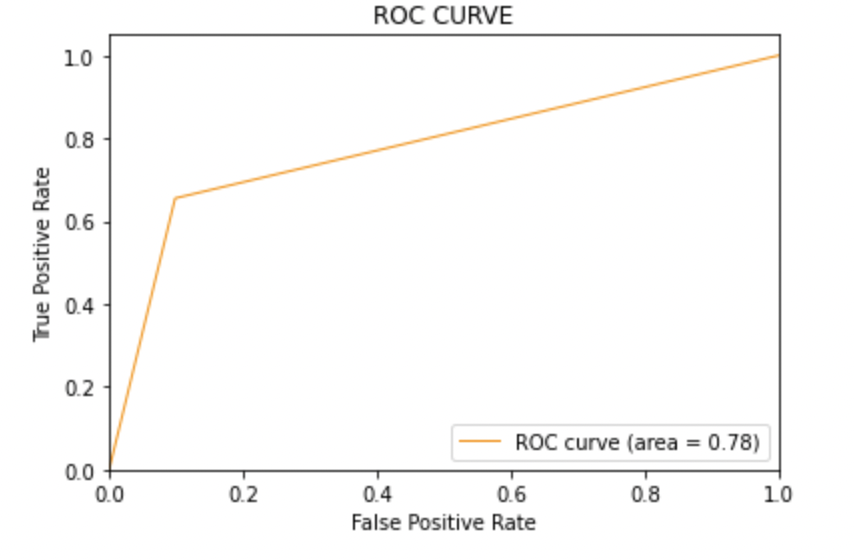
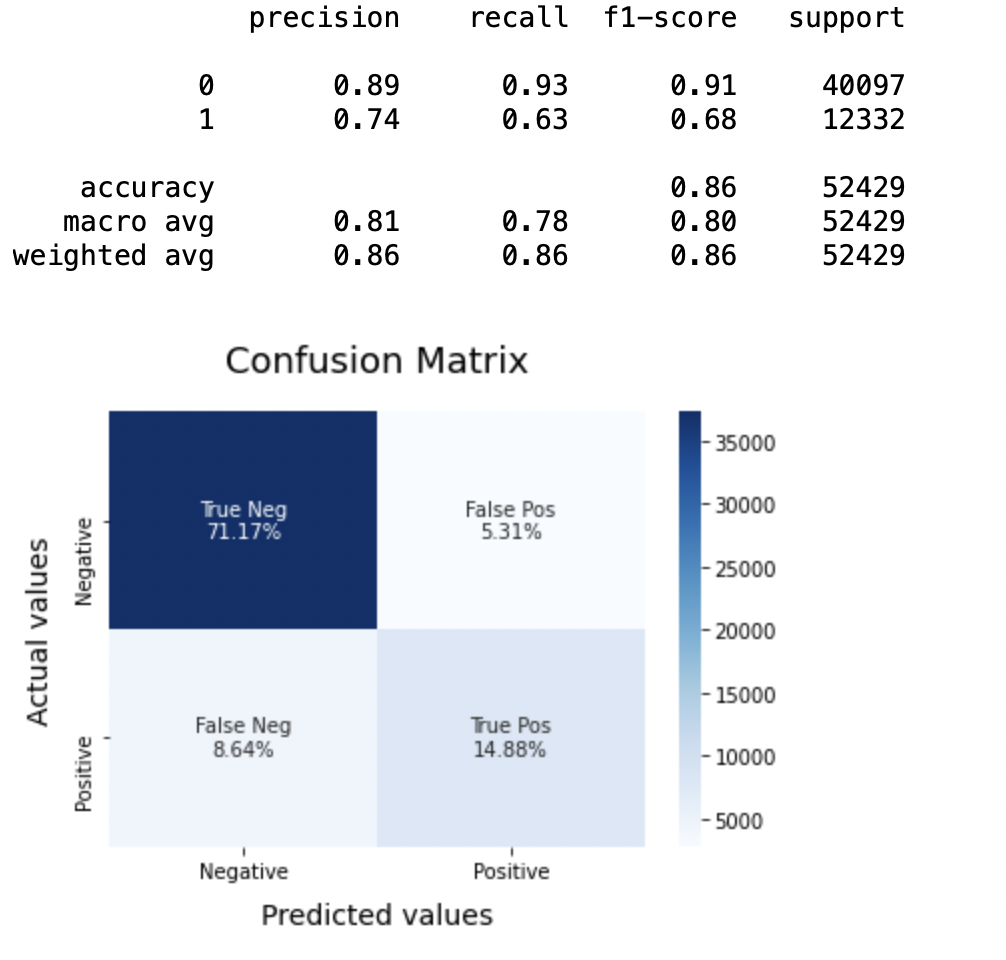
8.5: Modello-3
LRmodel = LogisticRegression(C = 2, max_iter = 1000, n_jobs=-1) LRmodel.fit(X_treno, y_train) model_Evaluate(LRmodel ·) y_pred3 = LRmodel.predict(X_test)
Produzione:
8.6: Tracciare la curva ROC-AUC per il modello 3
da sklearn.metrics importare roc_curve, auc
fpr, Tpr, soglie = roc_curve(y_test, y_pred3)
roc_auc = auc(fpr, Tpr)
plt.figure()
plt.trama(fpr, Tpr, colore="darkorange", lw=1, etichetta="Curva ROC (area = %0,2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Tasso di falsi positivi')
plt.ylabel("Tasso positivo vero")
plt.titolo('CURVA ROC')
plt.legend(loc ="in basso a destra")
plt.mostra()
Produzione:
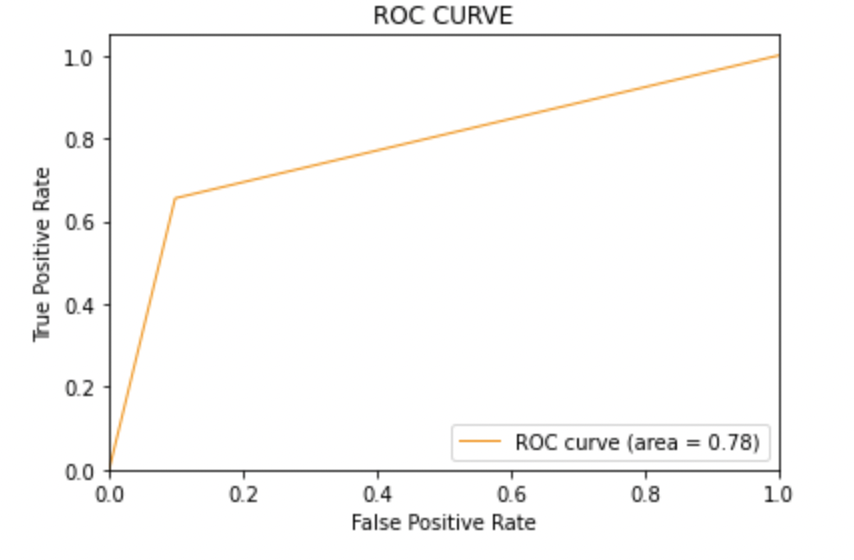
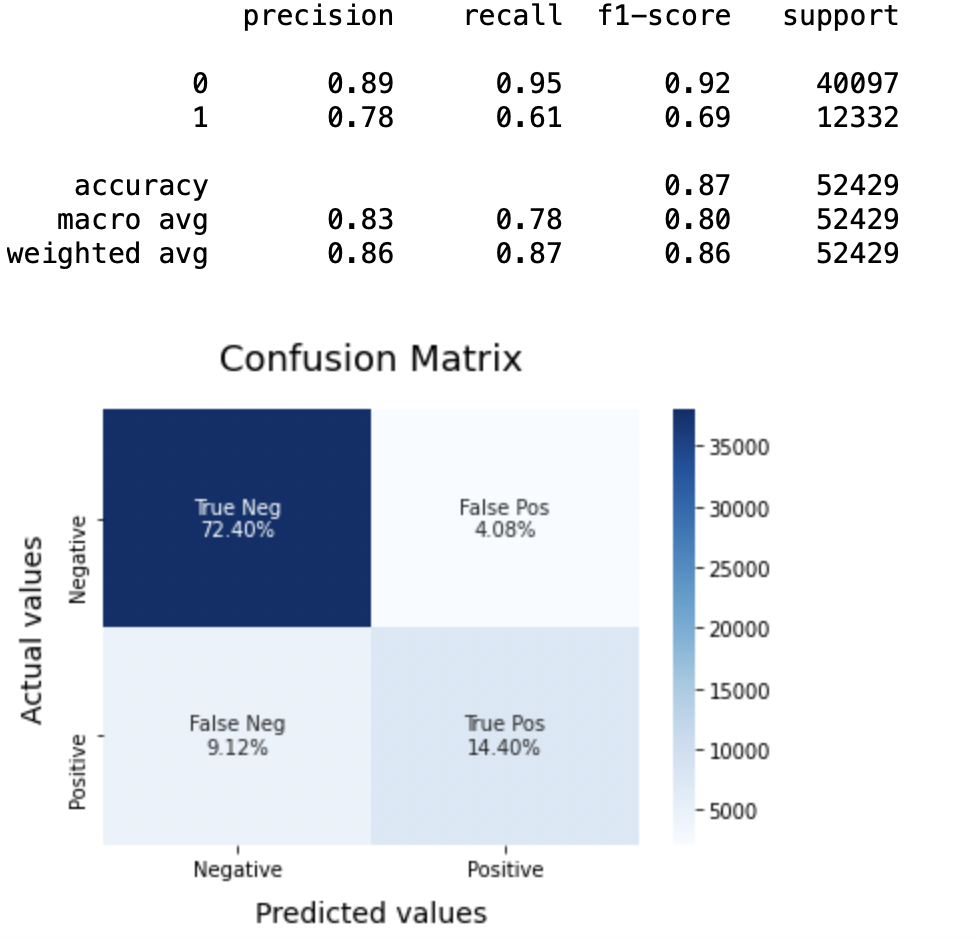
passo 10: conclusione
Valutando tutti i modelli possiamo concludere i seguenti dettagli, ovvero
Precisione: Per quanto riguarda l'accuratezza del modello, la regressione logistica funziona meglio di SVM, che a sua volta funziona meglio di Bernoulli Naive Bayes.
Punteggio F1: Punteggi F1 per la classe 0 e la classe 1 figlio:
(un) Per la classe 0: Bernoulli Naive Bayes (precisione = 0,90) <SVM (precisione = 0,91) <Regressione logistica (precisione = 0,92)
(B) Per la classe 1: Bernoulli Naive Bayes (precisione = 0,66) <SVM (precisione = 0,68) <Regressione logistica (precisione = 0,69)
Punteggio AUC: Tutti e tre i modelli hanno lo stesso punteggio ROC-AUC.
Perciò, concludiamo che la regressione logistica è il modello migliore per il set di dati di cui sopra.
Nella nostra dichiarazione di problema, Regressione logistica sta seguendo il principio di rasoio di Occam che lo definisce per una particolare istruzione di problema, Se i dati non hanno presupposti, quindi il modello più semplice funziona meglio. Poiché il nostro set di dati non ha presupposti e la regressione logistica è un modello semplice, Il concetto è valido per il set di dati sopra menzionato.
Note finali
Spero che l'articolo ti sia piaciuto.
Se vuoi connetterti con me, Non dubitare di restare in contatto con me. su E-mail
I vostri suggerimenti e dubbi sono i benvenuti qui nella sezione commenti. Grazie per aver letto il mio articolo!
Il supporto mostrato in questo articolo non è di proprietà di Analytics Vidhya e viene utilizzato a discrezione dell'autore.





