Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
L'obiettivo finale di questo blog è prevedere il sentimento di un determinato testo usando python, dove usiamo NLTK, noto anche come Natural Language Processing Toolkit, un pacchetto Python creato appositamente per l'analisi basata sul testo. Quindi, con poche righe di codice, possiamo facilmente prevedere se una frase o una recensione (usato nel blog) è una recensione positiva o negativa?.
Prima di passare direttamente all'implementazione, permettetemi brevemente i passaggi necessari per avere un'idea dell'approccio analitico. Questi sono vale a dire:
1. Importazione dei moduli richiesti
2. Importazione di set di dati
3. Pre-elaborazione e visualizzazione dei dati
4. Costruzione di modelli
5. Predizione
Quindi concentriamoci su ogni passaggio in dettaglio.
1. Importazione dei moduli richiesti:
Quindi, come sappiamo tutti, è necessario importare tutti i moduli che useremo inizialmente. Quindi facciamolo come primo passo della nostra pratica..
import numpy as np #linear algebra import pandas as pd # elaborazione dati, CSV file I/O (ad esempio. pd.read_csv) import matplotlib.pyplot as plt #For Visualisation %matplotlib inline import seaborn as sns #For better Visualisation from bs4 import BeautifulSoup #For Text Parsing
Qui stiamo importando tutti i moduli di importazione di base necessari, vale a dire, insensibile, panda, matplotlib, zuppa di mare e bella, ognuno con il proprio caso d'uso. Anche se useremo alcuni altri moduli, escludendoli, capiamoli mentre li usiamo.
2. Importazione di set di dati:
Infatti, Avevo scaricato il set di dati Kaggle parecchio tempo fa, quindi non ho il collegamento al set di dati. Quindi, per ottenere il set di dati e il codice, Metterò il link del repository Github in modo che tutti possano accedervi. Ora, per importare il set di dati, dobbiamo usare il "metodo read_csv" dei panda’ seguito dal percorso del file.
data = pd.read_csv("Recensioni.csv")
Se stampiamo il set di dati, potremmo vedere che ci sono '568454 righe × 10 colonne', che è abbastanza grande.
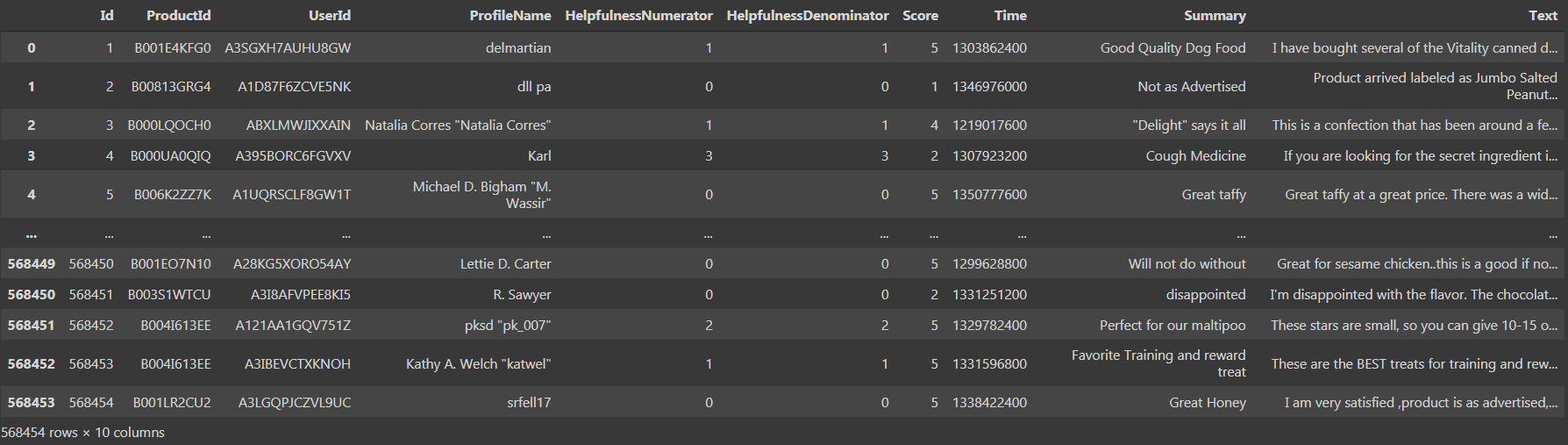
Vediamo che c'è 10 colonne, vale a dire, 'ID', 'Numeratore di utilità', "Denominatore di utilità", 'Punto’ E tempo’ come tipo di dati int64 e 'ProductId', 'ID utente', 'Nome del profilo', 'Riepilogo', 'Testo’ come tipo di dati oggetto. Ora passiamo al terzo passaggio, vale a dire, preelaborazione e visualizzazione dei dati.
3. Pre-elaborazione e visualizzazione dei dati:
Ora abbiamo accesso ai dati e poi li puliamo. Usando il "metodo isnull" (). Somma ()’ potremmo facilmente trovare il numero totale di valori mancanti nel set di dati.
data.isnull().somma()
Se eseguiamo il codice sopra come una cella, abbiamo scoperto che c'è 16 e 27 valori nulli nelle "colonne ProfileName"’ y 'Riepilogo'’ rispettivamente. Ora, dobbiamo sostituire i valori nulli con la tendenza centrale o rimuovere le rispettive righe contenenti i valori nulli. Con un numero così elevato di righe, rimuovere da solo 43 le righe contenenti i valori null non influenzerebbero la precisione complessiva del modello. Perciò, si consiglia di eliminare 43 righe utilizzando il metodo 'dropna'.
data = data.dropna()
Ora, Ho aggiornato il vecchio dataframe invece di creare una nuova variabile e memorizzare il nuovo dataframe con i valori puliti. Ora, ancora, quando controlliamo il frame di dati, abbiamo scoperto che c'è 568411 righe e lo stesso 10 colonne, che significa che 43 le righe che avevano i valori null sono state rimosse e ora il nostro set di dati è stato pulito. Continuando, dobbiamo preelaborare i dati in modo tale che il modello possa utilizzarli direttamente.
Para preprocessore, usiamo la colonna "Punteggio"’ nella cornice dati per avere punteggi che vanno da '1'’ un "5", dove '1’ significa una recensione negativa e "5"’ significa una recensione positiva. Ma è meglio avere il punteggio inizialmente in un intervallo di ‘0’ un '2’ dove ‘0’ significa una recensione negativa, '1’ significa una recensione neutrale e "2"’ significa una recensione positiva. È simile alla codifica in Python, ma qui non usiamo nessuna funzione incorporata, ma eseguiamo esplicitamente un ciclo for where e creiamo un nuovo elenco e aggiungiamo i valori all'elenco.
a=[]
per i dati['Punto']:
se io <3:
a.append(0)
se io==3:
a.append(1)
se io>3:
a.append(2)
Supponendo che il "Punteggio"’ è nell'intervallo di ‘0’ un "2", Le consideriamo recensioni negative e le aggiungiamo alla lista con un punteggio di ‘0', cosa significa recensione negativa. Ora, se graficiamo i valori dei punteggi presenti nella lista 'a’ come la nomenclatura usata sopra, abbiamo scoperto che c'è 82007 recensioni negative, 42638 recensioni neutre e 443766 recensioni positive. Possiamo chiaramente trovare che circa il 85% delle recensioni nel set di dati hanno recensioni positive e le restanti sono recensioni negative o neutre. Questo potrebbe essere visualizzato e compreso più chiaramente con l'aiuto di un diagramma di conteggio nella biblioteca del mare.
sns.countplot(un)
plt.xlabel('Recensioni', colore="rosso")
plt.ylabel('Contare', colore="rosso")
plt.xticks([0,1,2],['Negativo','Neutro','Positivo'])
plt.titolo('CONTEGGIO TRAMA', colore="R")
plt.mostra()
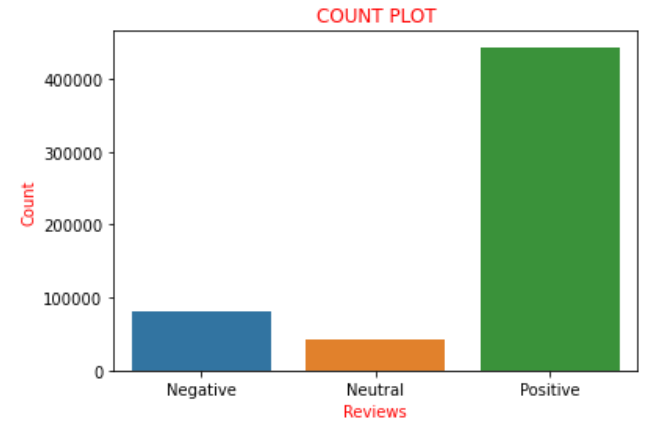
Perciò, la trama di cui sopra ritrae chiaramente tutte le frasi descritte sopra pittoricamente. Ora converto la lista 'in'’ che avevamo precedentemente codificato in una nuova colonna chiamata "sentimento"’ al frame di dati, vale a dire, 'dati'. Ora arriva una svolta in cui creiamo una nuova variabile, diciamo "final_dataset"’ dove considero solo la colonna "Feeling"’ e "testo"’ del frame di dati, che è il nuovo framework di dati su cui lavoreremo per la prossima parte. La ragione di ciò è che tutte le colonne rimanenti sono considerate quelle che non contribuiscono all'analisi del sentiment., così, senza scartarli, Riteniamo che il frame di dati escluda tali colonne. Perciò, questo è il motivo per scegliere solo le colonne 'Testo'’ e 'Sentimento'. Codifichiamo come di seguito:
dati['sentimento']=a
final_dataset = data[['Testo','sentimento']]
set_data_finale
Ora, se stampiamo il 'final_dataset’ e troviamo la strada, veniamo a sapere cosa c'è 568411 righe e solo 2 colonne. Dal final_dataset, se scopriamo che il numero di commenti positivi è 443766 e il numero di commenti negativi è 82007. Perciò, c'è una grande differenza tra commenti positivi e negativi. Perciò, c'è più possibilità che i dati si adattino troppo se proviamo a costruire il modello direttamente. Perciò, dobbiamo scegliere solo pochi input dal final_datset per evitare l'overfitting. Quindi, da varie prove, Ho scoperto che il valore ottimale per il numero di revisioni da considerare è 5000. Perciò, Creo i dati di due nuove variabili’ e "data"’ e negozio a caso 5000 recensioni positive e negative rispettivamente sulle variabili. Il codice che implementa lo stesso è sotto:
datap = data_p.iloc[np.random.randint(1,443766,5000), :] datan = data_n.iloc[np.random.randint(1, 82007,5000), :] len(dati), len(dati)
Ora creo una nuova variabile chiamata data e concateno i valori in 'datap’ e "data".
data = pd.concat([dati,dati]) len(dati)
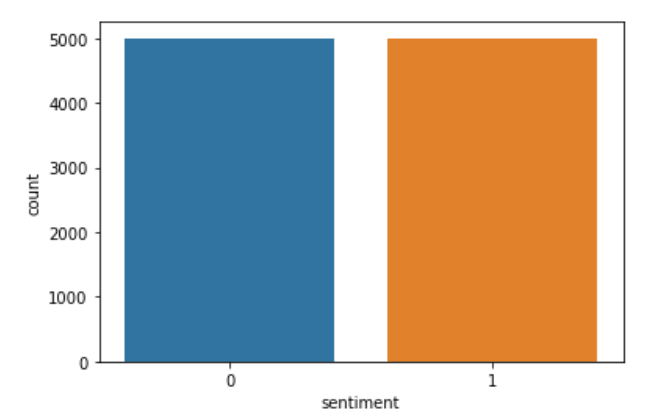
Ora creo un nuovo elenco chiamato 'c’ e quello che faccio è simile alla codifica ma esplicitamente. Salvo recensioni negative “0” Che cosa “0” e recensioni positive “2” prima come “1” Su “C”. Dopo, Nuovamente sostituiti i valori di sentimento memorizzati in 'c’ nei dati della colonna. Dopo, Per verificare se il codice è stato eseguito correttamente, Seguo la colonna "sentimento". Il codice che implementa la stessa cosa è:
c=[]
per i dati['sentimento']:
se i==0:
c.append(0)
se i==2:
c.append(1)
dati['sentimento']=c
sns.countplot(dati['sentimento'])
plt.mostra()
Se vediamo i dati, possiamo scoprire che ci sono alcuni tag HTML, in quanto i dati sono stati originariamente ottenuti da veri e propri siti di e-commerce. Perciò, possiamo scoprire che ci sono tag presenti che devono essere rimossi, in quanto non sono necessari per l'analisi del sentiment. Perciò, usiamo la funzione BeautifulSoup che utilizza il 'html.parser’ e possiamo rimuovere facilmente i tag indesiderati dalle recensioni. Per eseguire il compito, Creo una nuova colonna chiamata "recensione"’ che memorizza il testo analizzato e rilascia la colonna chiamata 'feeling'’ per evitare la ridondanza. Ho svolto l'attività di cui sopra utilizzando una funzione chiamata 'strip_html'. Il codice per fare lo stesso è il seguente:
def strip_html(testo):
zuppa = zuppa bella(testo, "html.parser")
return zuppa.get_text()
dati['recensione'] = dati['Testo'].applicare(strip_html)
data=data.drop('Testo',asse=1)
data.head()
Ora siamo giunti alla fine di un noioso processo di pre-elaborazione e visualizzazione dei dati. Perciò, ora possiamo continuare con il passaggio successivo, vale a dire, costruzione di modelli.
4. Modello di costruzione:
Prima di passare direttamente alla costruzione del modello di cui abbiamo bisogno, per fare un po' di compiti. Sappiamo che per gli esseri umani per classificare i sentimenti abbiamo bisogno di articoli, determinanti, congiunzioni, segni di punteggiatura, eccetera, come possiamo capire chiaramente e quindi valutare la recensione. Ma questo non è il caso delle macchine, quindi non hanno davvero bisogno di loro per classificare la sensazione, ma sono letteralmente confusi se sono presenti. Quindi, per eseguire questo compito come qualsiasi altra analisi del sentimento, dobbiamo usare la libreria 'nltk'. NLTK figlio della sigla di 'Natural Language Processing Toolkit'. Questa è una delle migliori librerie per fare analisi del sentimento o qualsiasi progetto di apprendimento automatico basato su testo. Quindi, con l'aiuto di questa libreria, prima rimuoverò i segni di punteggiatura e poi rimuoverò le parole che non aggiungono un tocco al testo. Per prima cosa uso una funzione chiamata 'punc_clean’ che rimuove i segni di punteggiatura da ogni recensione. Il codice per implementare lo stesso è il seguente:
import nltk def punc_clean(testo): import string as st a=[W per W nel testo se W non in St.Punctuation] restituisci ''.join(un) dati['recensione'] = dati['recensione'].applicare(punc_clean) data.head(2)
Perciò, Il codice precedente rimuove i segni di punteggiatura. Ora, prossimo, dobbiamo rimuovere le parole che non aggiungono un sentimento alla frase. Queste parole sono chiamate “parole vuote”. L'elenco di quasi tutte le parole vuote potrebbe essere trovato qui. Prossimo, se controlliamo l'elenco delle parole vuote, possiamo scoprire che contiene anche la parola “no”. Perciò, è necessario che non rimuoviamo il “no” da “revisione”, in quanto aggiunge valore al sentimento perché contribuisce al sentimento negativo. Perciò, dobbiamo scrivere il codice in modo tale da rimuovere altre parole tranne il “no”. Il codice per implementare lo stesso è:
def remove_stopword(testo):
stopword=nltk.corpus.stopwords.words('inglese')
stopword.rimuovi('non')
a=[w per w in nltk.word_tokenize(testo) se non in stopword]
ritorna ' '.unisci(un)
dati['recensione'] = dati['recensione'].applicare(remove_stopword)
Perciò, ora abbiamo solo un passo indietro rispetto alla costruzione di modelli. Il motivo successivo è assegnare a ogni parola in ogni recensione un punteggio di sentimento. Quindi, per implementarlo, dobbiamo usare un'altra libreria dal "modulo sklearn"’ cos'è il "TfidVectorizer"’ che è presente all'interno di "feature_extraction.text". Si consiglia vivamente di passare attraverso il "TfidVectorizer"’ documenti per ottenere una chiara comprensione della biblioteca. Ha molti parametri come input, codificazione, min_df, max_df, ngram_range, binario, dtype, use_idf e molti altri parametri, ognuno con il proprio caso d'uso. Perciò, si consiglia di passare attraverso questo Blog per ottenere una chiara comprensione di come funziona 'TfidVectorizer'. Il codice che lo implementa è:
from sklearn.feature_extraction.text import TfidfVectorizer
vectr = TfidfVectorizer(ngram_range=(1,2),min_df=1)
vectr.fit(dati['recensione'])
vect_X = vectr.transform(dati['recensione'])
Ora è il momento di costruire il modello. Poiché si tratta di un'analisi del sentiment di classificazione delle classi binarie, vale a dire, '1’ si riferisce a una recensione positiva e ‘0’ si riferisce a una recensione negativa. Quindi, è chiaro che dobbiamo utilizzare uno qualsiasi degli algoritmi di classificazione. Quello usato qui è la regressione logistica. Perciò, abbiamo bisogno di importare 'LogisticRegression’ per usarlo come modello. Dopo, dobbiamo regolare tutti i dati in quanto tali perché ho ritenuto che sia bene testare i dati da dati completamente nuovi piuttosto che dal set di dati disponibile. Quindi ho regolato l'intero set di dati. Quindi uso la funzione '.score' ()’ Per prevedere il punteggio del modello. Il codice che implementa le attività sopra menzionate è il seguente:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
clf=modello.fit(vect_X,dati['sentimento'])
clf.score(vect_X,dati['sentimento'])*100
Se eseguiamo lo snippet di codice sopra e controlliamo il punteggio del modello, ci troviamo tra 96 e 97%, Poiché il set di dati cambia ogni volta che si esegue il codice, poiché consideriamo i dati in modo casuale. Perciò, abbiamo costruito con successo il nostro modello che anche con un buon punteggio. Quindi, Perché aspettare per testare come funziona il nostro modello nello scenario del mondo reale?? Quindi ora passiamo all'ultimo e ultimo passaggio della "Previsione"’ per testare le prestazioni del nostro modello.
5. Predizione:
Quindi, per chiarire le prestazioni del modello, Ho usato due semplici frasi "Amo il gelato" e "Odio il gelato" che si riferiscono chiaramente a sentimenti positivi e negativi.. il risultato è il seguente:

Qui il '1’ e il ‘0’ fare riferimento rispettivamente al sentimento positivo e negativo. Perché alcune recensioni del mondo reale non vengono testate?? Chiedo a voi lettori di verificare e dimostrare lo stesso. La maggior parte delle volte otterresti l'output desiderato, ma se non funziona, Vi chiedo di provare a modificare i parametri del 'TfidVectorizer’ e imposta il modello su "LogisticRegression"’ per ottenere l'output richiesto. Quindi, per cui ho allegato il link al codice e al dataset qui.
Ti connetti con me attraverso linkato. Spero che questo blog sia utile per capire come l'analisi del sentimento viene eseguita praticamente con l'aiuto dei codici Python. Grazie per aver visto il blog.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





