introduzione
Oggi, una delle piattaforme di social media alla moda è .... indovina un po? Un solo WhatsApp😅. È una delle piattaforme di social media preferite da tutti noi grazie alle sue caratteristiche interessanti. Ha più di 2 un miliardo di utenti in tutto il mondo e “Secondo un sondaggio, un utente medio spende più di 195 minuti a settimana su WhatsApp”. Quanto è terribile l'affermazione di cui sopra. Lascia perdere tutte queste cose e capiamo cosa significa veramente l'analizzatore di WhatsApp.
WhatsApp Analyzer significa che stiamo analizzando le nostre attività di gruppo WhatsApp. Tieni traccia della nostra conversazione e analizza quanto tempo trascorriamo o diciamo che “sprechiamo” su whatsapp. Lo scopo di questo articolo è fornire una guida passo passo per creare il nostro parser WhatsApp utilizzando Python.. Qui ho usato diverse librerie Python che mi aiutano a estrarre informazioni utili dai dati grezzi. Qui scelgo il mio gruppo whatsApp ufficiale dell'università per analizzare il modello che gli studenti stavano seguendo, quindi in alcune delle istantanee elimino le informazioni di contatto dei miei professori universitari e dei miei compagni di classe, scusate. Iniziamo...
Librerie richieste:
- Regex
- panda
- Matplotlib
- Numpy
- Seaborn
- Data e ora
- Emoji
- Wordcloud
- Heatmapz
- NLTK
- trama
Importiamo tutte queste librerie:
import re import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from datetime import * import datetime as dt from matplotlib.ticker import MaxNLocator import regex import emoji from seaborn import * from heatmap import heatmap from wordcloud import WordCloud , STOPWORDS , ImageColorGenerator from nltk import * da Plotly Import Express come PX
WhatsApp ci dà la funzione di esportare le chat, así que exportemos el chat y guardemos el archivo. al passo 2, crearemos un programa de Python que extraerá la fecha, el nombre de usuario del autor, Il tempo, i messaggi dal file di chat esportato e creare un frame di dati, e memorizzerà tutti i dati al suo interno. In realtà, la raccolta dei dati e la parte di pre-elaborazione sono trattate nel passaggio 2 e nei passaggi successivi.
Estraiamo tutte le informazioni utili. dal file di chat utilizzando regex:
### Codice Python per estrarre la data dal file di chat
def inizia con data e ora (S):
modello = '^ ([0-9]+) (/) ([0-9]+) (/) ([0-9][0-9]), ([0-9]+) :([0-9][0-9]) (SONO | pomeridiano) – ‘
risultato = ri.match (Modello, S)
se il risultato:
restituire vero
falso ritorno
### Modello Regex per estrarre il nome utente dell'autore.
def TrovaAutore(S):
modelli = [
'([w]+):', # First Name
'([w]+[S]+[w]+):', # Nome di battesimo + Last Name
'([w]+[S]+[w]+[S]+[w]+):', # Nome di battesimo + Secondo nome + Last Name
'([+]D{2} D{5} D{5}):', # Numero di cellulare (India no.)
'([+]D{2} D{3} D{3} D{4}):', # Numero di cellulare (Us no.)
'([w]+)[U263A-U0001f999]+:', # Nome ed Emoji
]
pattern = '^' + '|'.join(Modelli)
risultato = re.match(modello, S)
se risultato:
return True
return False
### Data di estrazione, Ore, Autore e messaggio dal file di chat.
def getDataPoint(linea):
splitLine = line.split(' - ')
dateTime = splitLine[0]
Data, ora = dateTime.split(', ')
messaggio=" ".aderire(splitLine[1:])
se FindAuthor(Messaggio):
splitMessage = message.split(': ')
autore = splitMessage[0]
messaggio=" ".aderire(splitMessage[1:])
altro:
author = None
return date, tempo, autore, Messaggio
### Infine creare un dataframe e memorizzare tutti i dati all'interno di quel dataframe.
parsedData = [] # Elenco per tenere traccia dei dati in modo che possano essere utilizzati da un dataframe Pandas ### Uploading exported chat file conversationPath="WhatsApp Chat con TE Comp 20-21 Ufficiale.txt" # chat file with open(conversationPath, codifica="utf-8") come fp: ### Skipping first line of the file because contains information related to something about end-to-end encryption fp.readline() messageBuffer = [] Data, tempo, autore = Nessuno, Nessuno, None while True: linea = fp.readline() se non linea: break line = line.strip() se inizia con data e ora(linea): se len(messaggioBuffer) > 0: parsedData.append([Data, tempo, autore, ' '.aderire(messaggioBuffer)]) messageBuffer.clear() Data, tempo, autore, messaggio = getDataPoint(linea) messageBuffer.append(Messaggio) altro: messageBuffer.append(linea) df = pd.DataFrame(parsedData, colonne=['Data', 'Tempo', 'Autore', 'Messaggio']) # Inizializzazione di un Dataframe panda. ### modifica del tipo di dati di "Data" colonna. df["Data"] = pd.to_datetime(df["Data"])
Primo, guarda il nostro set di dati appena nato:
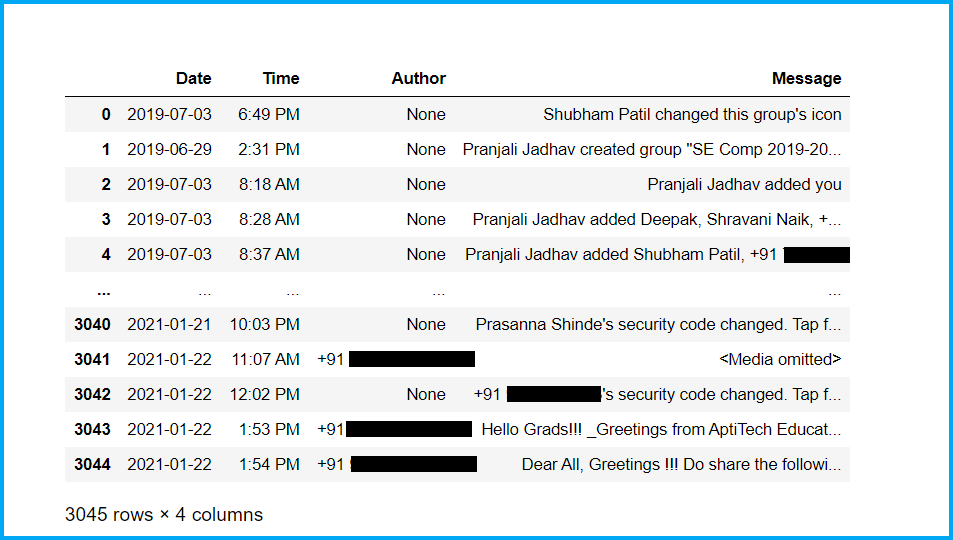
Ora, controlliamo le informazioni di base del nostro set di dati e ripuliamo il set di dati:
### Controllo della forma di set di datiun "set di dati" o dataset è una raccolta strutturata di informazioni, che può essere utilizzato per l'analisi statistica, Apprendimento automatico o ricerca. I set di dati possono includere variabili numeriche, categorico o testuale, e la loro qualità è fondamentale per ottenere risultati affidabili. Il suo utilizzo si estende a varie discipline, come la medicina, Economia e scienze sociali, facilitare il processo decisionale informato e lo sviluppo di modelli predittivi..... forma df ### Controllo delle informazioni di base del set di dati df.info() ### Controllo no. di nulloIl termine "NULLO" Viene utilizzato nella programmazione e nei database per rappresentare un valore nullo o inesistente. La sua funzione principale è quella di indicare che a una variabile non è assegnato un valore o che un dato non è disponibile. e SQL, ad esempio, Utilizzato per gestire i record che mancano di informazioni in determinate colonne. Comprendere l'uso di "NULLO" È essenziale evitare errori nella manipolazione dei dati e... Valori nel set di dati df.isnull().somma() ### Controllo della parte principale del set di dati df.head(50) ### Controllo della parte di coda del set di dati df.coda(50) ### Eliminazione dei valori Nan dal set di dati df = df.dropna() df = df.reset_index(drop=Vero) forma df ### Controllo no. di autori del gruppo df['Autore'].Ora() ### Controllo degli autori del gruppo df['Autore'].unico()
Ora, pre-processiamo il nostro set di dati e cerchiamo di estrarre informazioni utili da esso:
### Aggiungendo un'altra colonna di "Giorno" per una migliore analisi, qui usiamo la libreria datetime che ci aiuta a svolgere facilmente questo compito.
settimane = {
0 : 'Lunedì',
1 : 'Martedì',
2 : 'Mercoledì',
3 : 'giovedì',
4 : 'Venerdì',
5 : 'Il sabato',
6 : 'Domenica'
}
df['Giorno'] = df['Data'].dt.weekday.map(settimane)
### Riorganizzare le colonne per una migliore comprensione
df = df[['Data','Giorno','Tempo','Autore','Messaggio']]
### Modifica del tipo di dati della colonna "Giorno".
df['Giorno'] = df['Giorno'].come tipo('categoria')
### Guardando il set di dati del neonato.
df.head()
### Conteggio del numero di lettere in ogni messaggio
df['Lettera'] = df['Messaggio'].applicare(lambda s : len(S))
### Conteggio del numero di parole in ogni messaggio
df['Parola'] = df['Messaggio'].applicare(lambda s : len(s.split(' ')))
### Funzione per contare il numero di collegamenti nel set di dati, Aggiungerà una colonna aggiuntiva e memorizzerà le informazioni al suo interno.
URLPATTERN = r'(https?://S+)'
df['Url_Count'] = df. Message.apply(lambda x: re.trovare(URLPATTERN, X)).str.len()
collegamenti = np.sum(Df. Url_Count)
### Funzione per contare il numero di media in chat.
MEDIAPATTERN = r'<Media omessi>'
df['Media_Count'] = df. Message.apply(lambda x : re.trovare(MEDIAPATTERN, X)).str.len()
media = np.sum(Df. Media_Count)
### Ricerca di set di dati aggiornati
df
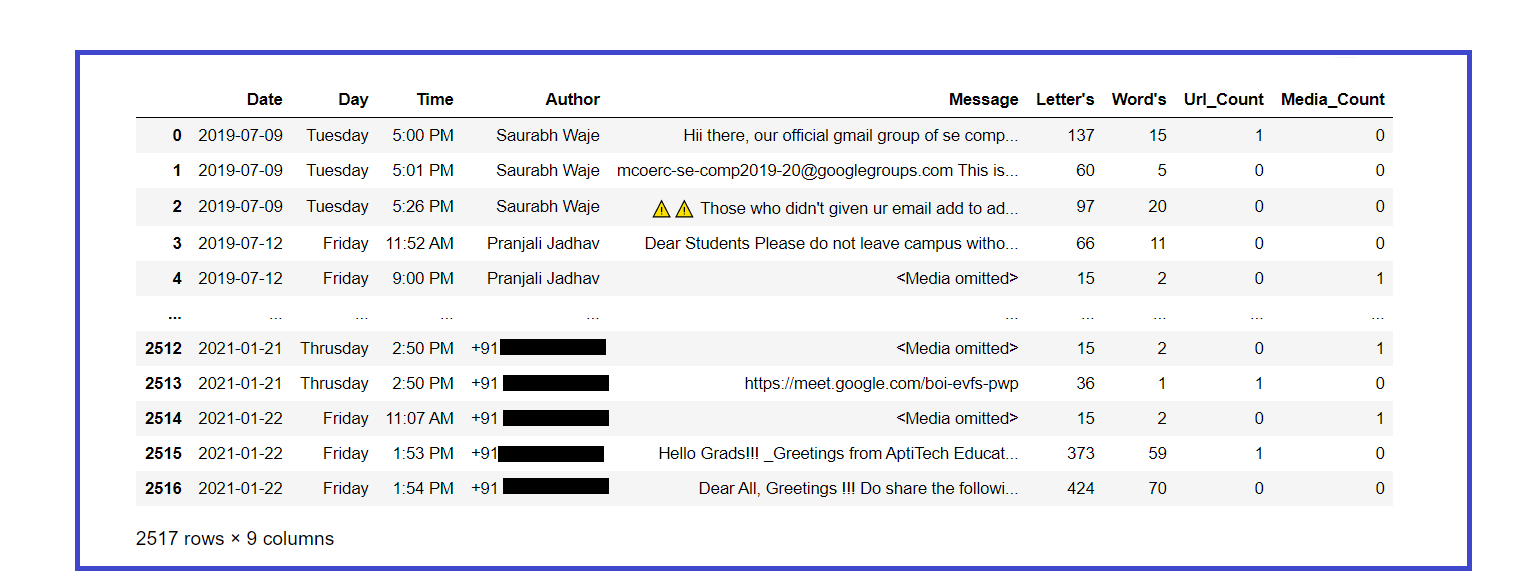
Extraer estadísticas básicas del conjunto de datos:
total_messages = df.shape[0]
media_messages = df[df['Messaggio'] == '<Media omessi>'].forma[0]
collegamenti = np.sum(Df. Url_Count)
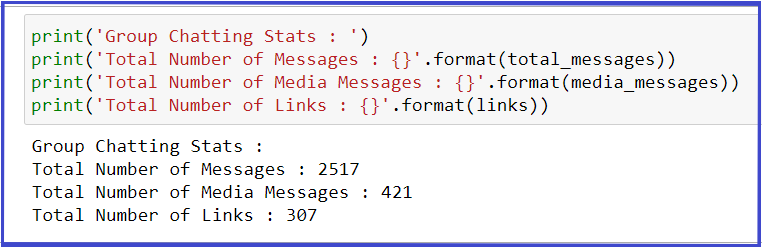
Stampa("Statistiche chat di gruppo" : ')
Stampa("Numero totale di messaggi" : {}'.formato(total_messages))
Stampa("Numero totale di messaggi multimediali" : {}'.formato(media_messages))
Stampa("Numero totale di collegamenti" : {}'.formato(link))
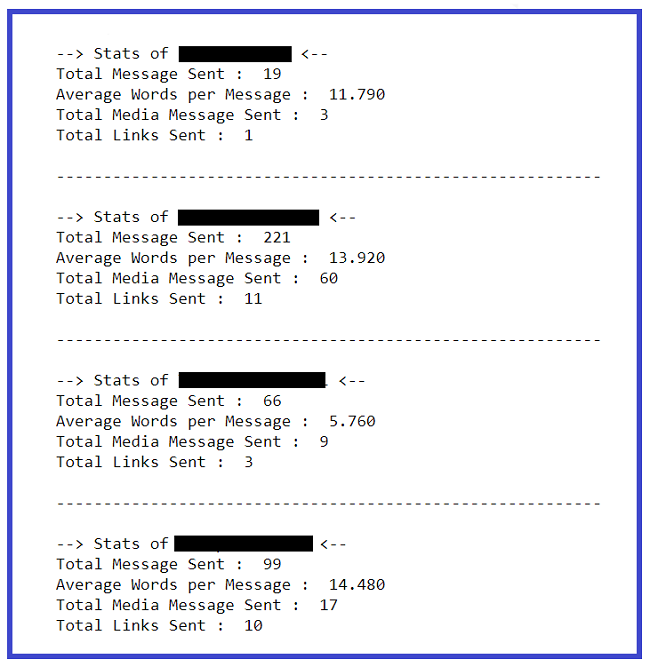
Estrazione di statistiche di base da ciascun utente:
l = df.Autore.unico()
per io nel raggio d'azione(len(io)):
### Filtrare i messaggi di un particolare utente
req_df = df[df["Autore"] == l[io]]
### req_df conterrà i messaggi di un solo particolare utente
Stampa(F'--> Statistiche di {io[io]} <-- ')
### shape stamperà il numero di righe che indirettamente significa il numero di messaggi
Stampa("Totale messaggio inviato" : ', req_df.shape[0])
### Word_Count contiene parole totali in un messaggio. La somma di tutte le parole/Messaggi totali produrrà parole per messaggio
parole_per_messaggio = (np.sum(req_df['Parola']))/req_df.shape[0]
w_p_m = ("%.3F" % il giro(parole_per_messaggio, 2))
Stampa("Parole medie per messaggio" : ', w_p_m)
### i media sono costituiti da messaggi dei media
media = somma(req_df["Conteggio_media"])
Stampa("Totale messaggio multimediale inviato" : ', media)
### i collegamenti sono costituiti da collegamenti totali
link = somma(req_df["Url_Count"])
Stampa("Totale link inviati" : ', link)
Stampa()
Stampa('------------------------------------------------- ---------n')
Creiamo una nuvola di parole con le parole più usate in chat:
### Word Cloud delle parole più usate nel nostro Gruppo
testo = " ".aderire(recensione per la revisione in df.Message)
wordcloud = WordCloud(stopword=STOPWORD, background_color="bianco").creare(testo)
### Visualizza l'immagine generata:
plt.figure( figsize=(10,5))
plt.imshow(nuvola di parole, interpolazione='bilineare')
asse.plt("spento")
plt.mostra()
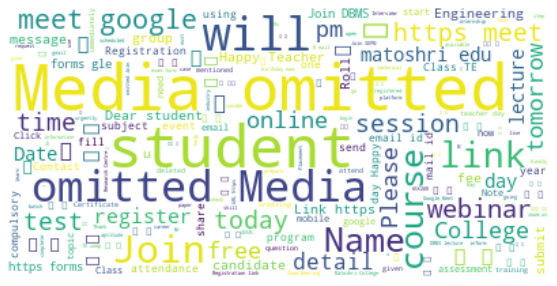
Stampiamo il totale n.. di messaggi inviati da ciascun utente:
### Crea un elenco di autori unici l = df.Autore.unico() per io nel raggio d'azione(len(io)): ### Filtrare i messaggi di un particolare utente req_df = df[df["Autore"] == l[io]] ### req_df conterrà i messaggi di un solo particolare utente Stampa(io[io],'-> ',req_df.shape[0])
Stampiamo il totale dei messaggi inviati ogni giorno della settimana:
l = df.Giorno.unico() per io nel raggio d'azione(len(io)): ### Filtrare i messaggi di un particolare utente req_df = df[df["Giorno"] == l[io]] ### req_df conterrà i messaggi di un solo particolare utente Stampa(io[io],'-> ',req_df.shape[0])
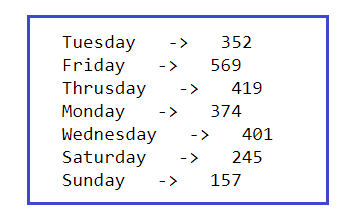
Finalmente, abbiamo estratto abbastanza informazioni di testo dal file di chat, Ora iniziamo la parte di visualizzazione dei dati che ci aiuterà per una migliore analisi e comprensione di tutte le analisi che abbiamo fatto sul nostro file di chat esportato. Al posto dei numeri di contatto, Ho usato gli alfabeti per motivi di sicurezza, molto dispiaciuto.
Vediamo chi è l'autore più attivo del gruppo:
### Autore più attivo nel gruppo
plt.figure(figsize=(9,6))
principalmente_attivo = df['Autore'].value_counts()
### Superiore 10 persone che sono maggiormente attive nel nostro Gruppo è :
m_a = perlopiù_attivo.testa(10)
barre = ['UN','B','C','D',"E",'F','G','H','IO','J']
x_pos = np.arange(len(barre))
m_a.plot.bar()
plt.xlabel("Autori",fontdict={'dimensione del font': 14,'fontweight': 10})
plt.ylabel('No. di messaggi',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.titolo("Membro per lo più attivo del gruppo",fontdict={'dimensione del font': 20,'fontweight': 8})
plt.xticks(x_pos, barre)
plt.mostra()
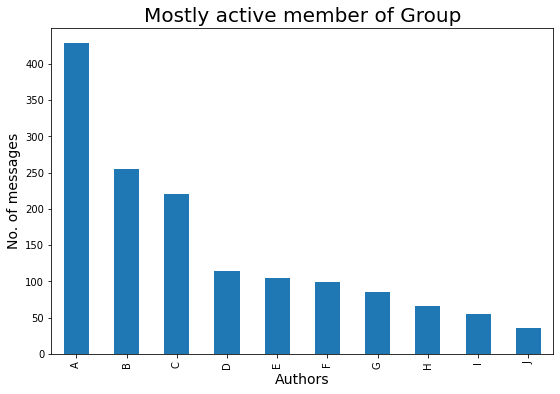
Diamo un'occhiata al giorno più attivo in una settimana:
### Giornata prevalentemente attiva nel gruppo
plt.figure(figsize=(8,5))
active_day = df['Giorno'].value_counts()
### Superiore 10 persone che sono maggiormente attive nel nostro Gruppo è :
a_d = active_day.head(10)
a_d.plot.bar()
plt.xlabel('Giorno',fontdict={'dimensione del font': 12,'fontweight': 10})
plt.ylabel('No. di messaggi',fontdict={'dimensione del font': 12,'fontweight': 10})
plt.titolo("Giorno della settimana più attivo nel gruppo",fontdict={'dimensione del font': 18,'fontweight': 8})
plt.mostra()
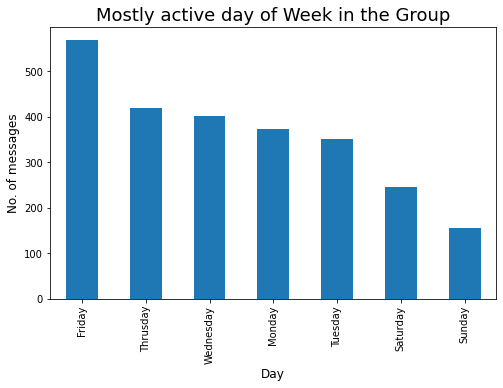
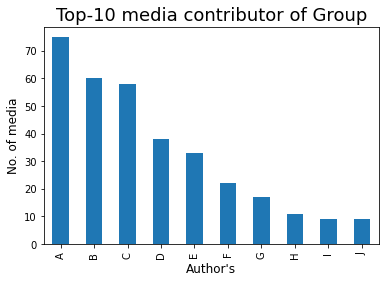
Diamo un'occhiata al contributore media Top-10 nel gruppo:
### Top-10 Media Contributor del Gruppo
mm = df[df['Messaggio'] == '<Media omessi>']
mm1 = mm['Autore'].value_counts()
barre = ['UN','B','C','D',"E",'F','G','H','IO','J']
x_pos = np.arange(len(barre))
top10 = mm1.testa(10)
top10.plot.bar()
plt.xlabel("Autore",fontdict={'dimensione del font': 12,'fontweight': 10})
plt.ylabel('No. dei media',fontdict={'dimensione del font': 12,'fontweight': 10})
plt.titolo('Top-10 contributori mediatici del Gruppo',fontdict={'dimensione del font': 18,'fontweight': 8})
plt.xticks(x_pos, barre)
plt.mostra()
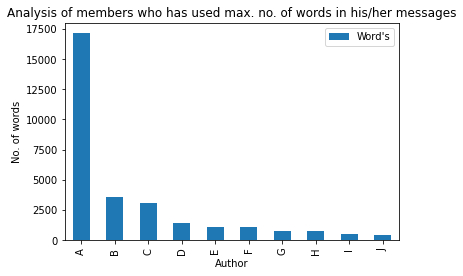
Le parole sono, Certo, l'arma più potente del mondo, quindi vediamo chi ha quest'arma potente nel gruppo😅:
max_words = df[['Autore','Parola']].raggruppare per('Autore').somma()
m_w = max_words.sort_values('Parola',ascendente=Falso).testa(10)
barre = ['UN','B','C','D',"E",'F','G','H','IO','J']
x_pos = np.arange(len(barre))
m_w.plot.bar(marciume=90)
plt.xlabel('Autore')
plt.ylabel('No. di parole')
plt.titolo('Analisi dei membri che hanno utilizzato max. no. di parole nei suoi messaggi')
plt.xticks(x_pos, barre)
plt.mostra()
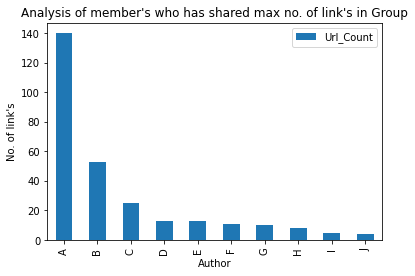
Diamo un'occhiata all'autore Top-10 che ha condiviso il numero massimo. di link nel gruppo:
### Membro che ha condiviso un numero massimo di link nel gruppo
max_words = df[['Autore','Url_Count']].raggruppare per('Autore').somma()
m_w = max_words.sort_values('Url_Count',ascendente=Falso).testa(10)
barre = ['UN','B','C','D',"E",'F','G','H','IO','J']
x_pos = np.arange(len(barre))
m_w.plot.bar(marciume=90)
plt.xlabel('Autore')
plt.ylabel('No. di link')
plt.titolo('Analisi del membro che ha condiviso max no. di link nel Gruppo')
plt.xticks(x_pos, barre)
plt.mostra()
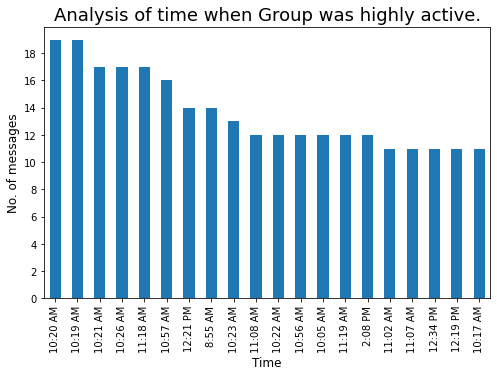
Vediamo l'ora ogni volta che il gruppo era molto attivo:
### Ora ogni volta che il nostro gruppo è molto attivo
plt.figure(figsize=(8,5))
t = df['Tempo'].value_counts().testa(20)
tx = t.plot.bar()
tx.yaxis.set_major_locator(MaxNLocator(integer=True)) #Converting y axis data to integer
plt.xlabel('Tempo',fontdict={'dimensione del font': 12,'fontweight': 10})
plt.ylabel('No. di messaggi',fontdict={'dimensione del font': 12,'fontweight': 10})
plt.titolo("Analisi del tempo in cui il Gruppo era molto attivo.",fontdict={'dimensione del font': 18,'fontweight': 8})
plt.mostra()
La conversión de formato de 12 ore a 24 horas nos ayudará a realizar un mejor análisis:
lst = []
per i in df['Tempo'] :
out_time = datetime.strftime(datetime.strptime(io,"%io:%M %p"),"%h:%m")
lst.append(out_time)
df['24H_Time'] = lst
df['Ore'] = df['24H_Time'].applicare(lambda x : x.split(':')[0])
Revisemos la hora más adecuada del día cuando haya más posibilidades de obtener una respuesta de los miembros del grupo:
### Ora del giorno più adatta, ogni volta che ci saranno più possibilità di ottenere risposta dai membri del gruppo.
plt.figure(figsize=(8,5))
std_time = df['Ore'].value_counts().testa(15)
s_T = std_time.plot.bar()
s_T.yaxis.set_major_locator(MaxNLocator(integer=True)) #Converting y axis data to integer
plt.xlabel(«Orari di apertura (24-Ora)',fontdict={'dimensione del font': 12,'fontweight': 10})
plt.ylabel('No. di messaggi',fontdict={'dimensione del font': 12,'fontweight': 10})
plt.titolo("Ora del giorno più adatta.",fontdict={'dimensione del font': 18,'fontweight': 8})
plt.mostra()
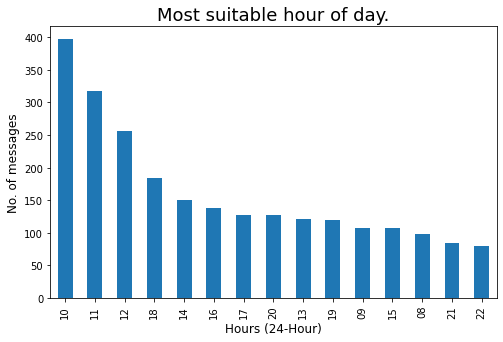
Creemos una nube de palabras de los 10 miembros más activos:
active_m = [elenco dei membri Top-10 altamente attivi]
per io nel raggio d'azione(len(active_m)) :
# Filtering out messages of particular user
m_chat = df[df["Autore"] == active_m[io]]
Stampa(F'--- Autore : {active_m[io]} --- ')
# Word Cloud of mostly used word in our Group
msg = ' '.join(x per x in m_chat. Messaggio)
wordcloud = WordCloud(stopword=STOPWORD, background_color="bianco").creare(msg)
plt.figure(figsize=(10,5))
plt.imshow(nuvola di parole, interpolazione='bilineare')
asse.plt("spento")
plt.mostra()
Stampa('____________________________________________________________________________________n')
Veamos la fecha en la que nuestro grupo estuvo muy activo:
### Data in cui il nostro Gruppo è stato molto attivo.
plt.figure(figsize=(8,5))
df['Data'].value_counts().testa(15).trama.bar()
plt.xlabel('Data',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.ylabel('No. di messaggi',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.titolo("Analisi della data in cui il gruppo era molto attivo",fontdict={'dimensione del font': 18,'fontweight': 8})
plt.mostra()
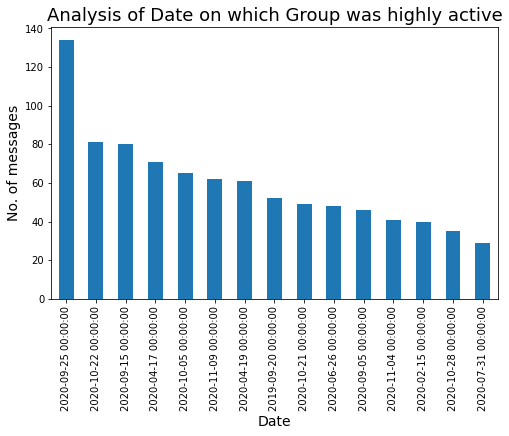
Creemos una gráfica de series de tiempo wrt no. de mensajes:
z = df['Data'].value_counts()
z1 = z.to_dict() #converts to dictionary
df['Msg_count'] = df['Data'].carta geografica(z1 ·)
### Trama di Timeseries
fig = px.line(x=df['Data'],y=df['Msg_count'])
fig.update_layout(titolo="Analisi del numero di messaggi"s usando la trama di TimeSeries.',
xaxis_title="Mese",
yaxis_title="No. di Messaggi")
fig.update_xaxes(nticks=20)
fig.mostra()
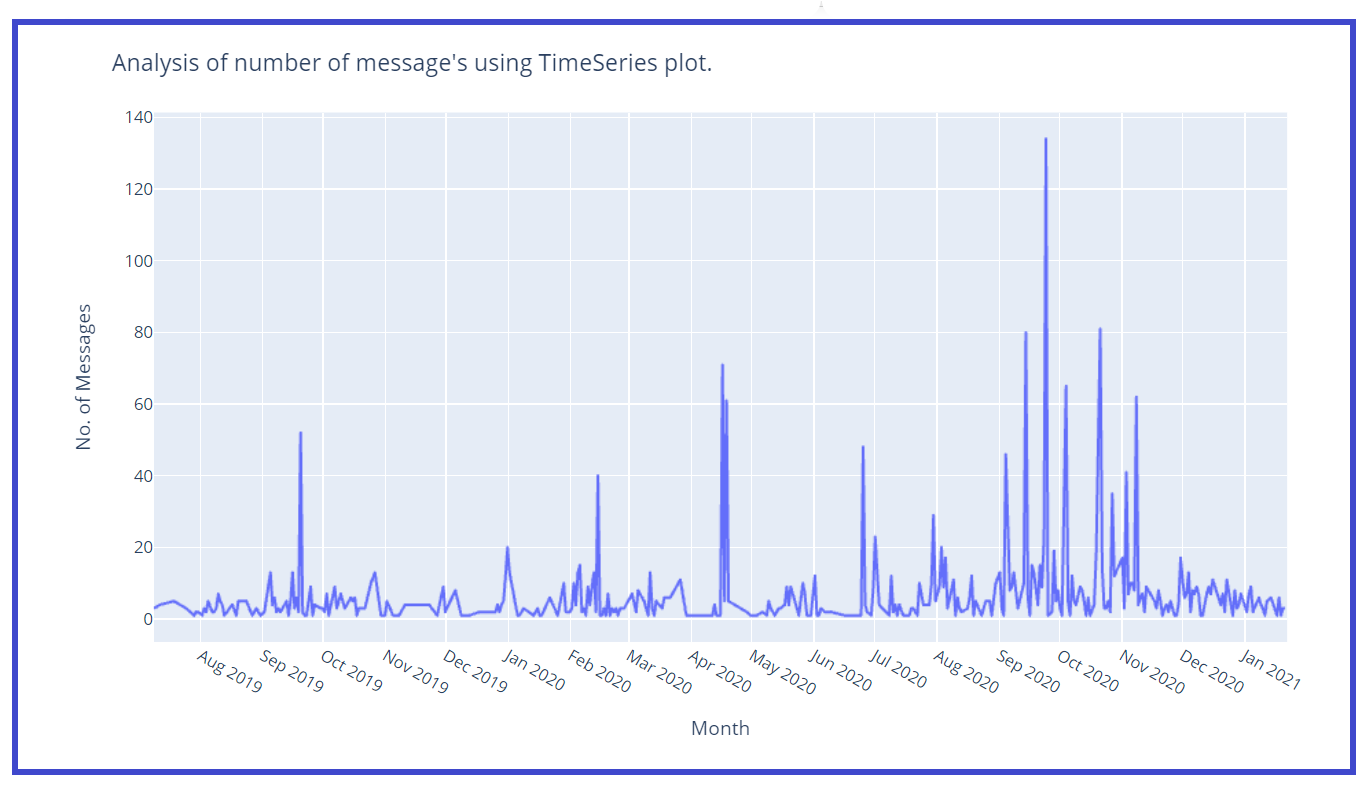
Creemos una columna separada para Mes y Año para un mejor análisis:
df['Anno'] = df['Data'].dt.year df['Lun'] = df['Data'].dt.month months = { 1 : 'Gennaio', 2 : 'Feb', 3 : 'Mar', 4 : 'Apr', 5 : 'Maggio', 6 : 'Giu', 7 : 'Lug', 8 : 'Ago', 9 : 'Set', 10 : 'Ott', 11 : 'Nov', 12 : 'Dicembre' } df['Mese'] = df['Lun'].carta geografica(mesi) df.drop('Lun',asse = 1, posto = vero)
Veamos el mes mayormente activo:
### Mese per lo più attivo
plt.figure(figsize=(12,6))
active_month = df['Month_Year'].value_counts()
a_m = active_month
a_m.plot.bar()
plt.xlabel('Mese',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.ylabel('No. di messaggi',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.titolo("Analisi del mese per lo più attivo.",fontdict={'dimensione del font': 20,
'fontweight': 8})
plt.mostra()
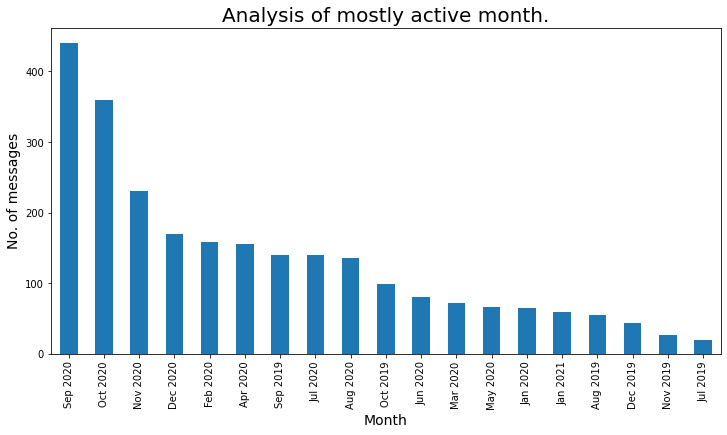
Analicemos el mes más activo usando un diagrama de líneas:
z = df['Month_Year'].value_counts()
z1 = z.to_dict() #converts to dictionary
df['Msg_count_monthly'] = df['Month_Year'].carta geografica(z1 ·)
plt.figure(figsize=(18,9))
sns.set_style("darkgrid")
sns.lineplot(dati=df,x='Month_Year',y='Msg_count_monthly',marcatori=Vero,marcatore="oh")
plt.xlabel('Mese',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.ylabel('No. di messaggi',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.titolo("Analisi del mese per lo più attivo utilizzando il grafico a linee.",fontdict={'dimensione del font': 20,'fontweight': 8})
plt.mostra()
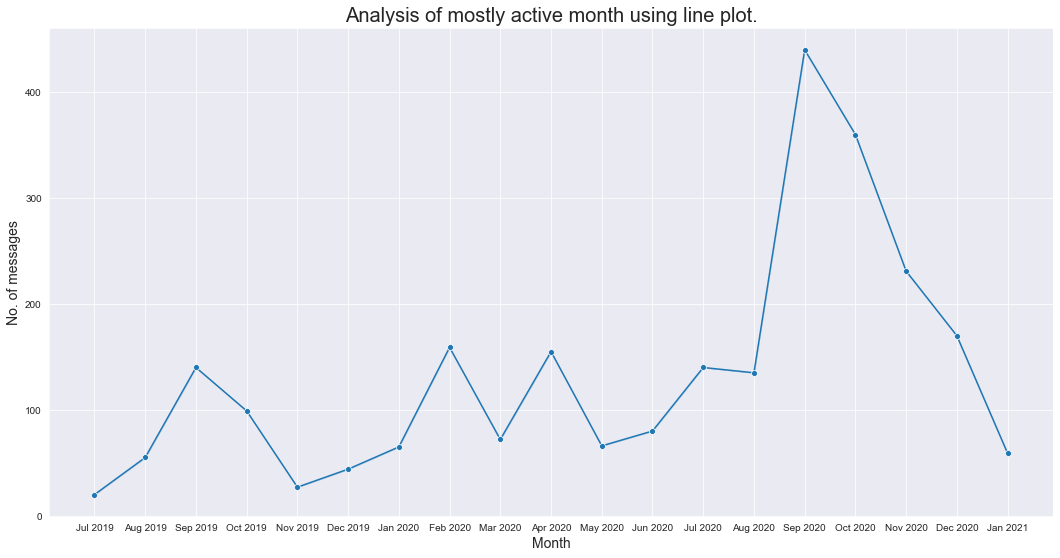
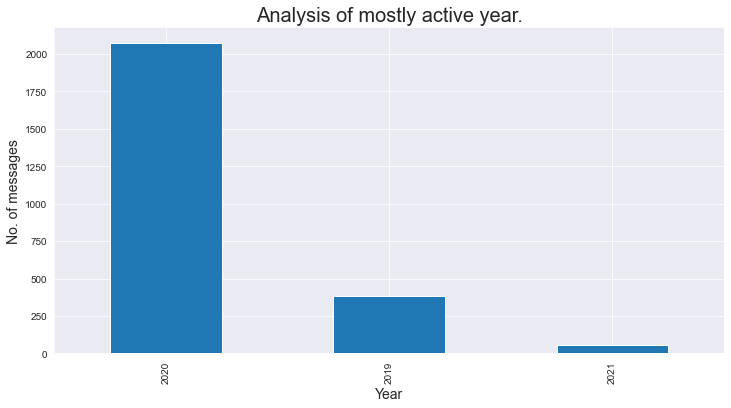
Rivediamo il messaggio totale all'anno:
### Messaggio totale all'anno
### Mentre analizziamo che il gruppo è stato creato a metà 2019, ecco perché numero di messaggi in 2019 è meno.
plt.figure(figsize=(12,6))
active_month = df['Anno'].value_counts()
a_m = active_month
a_m.plot.bar()
plt.xlabel('Anno',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.ylabel('No. di messaggi',fontdict={'dimensione del font': 14,'fontweight': 10})
plt.titolo('Analisi dell'anno per lo più attivo.',fontdict={'dimensione del font': 20,'fontweight': 8})
plt.mostra()
Usemos un mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate.... y analicemos la hora del día con gran actividad:
df2 = df.groupby(['Ore', 'Giorno'], as_index=Falso)["Messaggio"].contare()
df2 = df2.dropna()
df2.reset_index(goccia = vero,al posto = vero)
### Analizzare su quale fascia oraria è maggiormente attiva in base alle ore e al giorno.
analysis_2_df = df.groupby(['Ore', 'Giorno'], as_index=Falso)["Messaggio"].contare()
### Eliminazione di valori nulli
analysis_2_df.dropna(inplace=Vero)
analysis_2_df.sort_values(per=['Messaggio'],ascendente=Falso)
giorno_della_settimana = ['Lunedì', 'Martedì', 'Mercoledì', 'giovedì', 'Venerdì', 'Il sabato', 'Domenica']
plt.figure(figsize=(15,8))
mappa di calore(
x=analisi_2_df['Ore'],
y=analisi_2_df['Giorno'],
size_scale = 500,
dimensione = analisi_2_df['Messaggio'],
y_order = giorno_della_settimana[::-1],
colore = analisi_2_df['Messaggio'],
tavolozza = sns.cubehelix_palette(128)
)
plt.mostra()
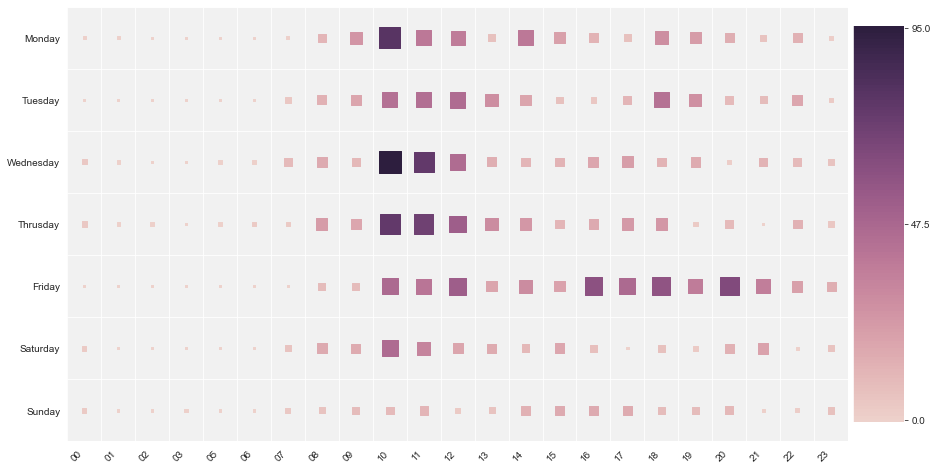
Dalla mappa di calore sopra, analizziamo che il “lunedì” tra i 10:00 e il 10:59, il nostro gruppo era
molto attivo, allo stesso modo il “mercoledì” tra i 10:00 e il 10:59, il nostro gruppo era
molto attivo. Tra i 00:00 e il 08:00 il gruppo era meno attivo.
Nota finale:
Spero che questo articolo ti aiuti davvero a creare il tuo analizzatore di chat WhatsApp e ad analizzare lo schema nel gruppo.
Spero che questo articolo ti sia piaciuto. Qualsiasi domanda? Mi sono perso qualcosa?? Per favore contattami al mio LinkedIn. E infine, … Non c'è bisogno di dire,
Grazie per aver letto!
Salute!!!
Ronil
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





