Nota: este post se publicó originalmente en 13 settembre 2015 e aggiornato il 11 settembre 2017
Panoramica
- Comprender uno de los algoritmos de clasificación de aprendizaje automático más populares y simples, el algoritmo Naive Bayes
- Se basa en el teorema de Bayes para calcular probabilidades y probabilidades condicionales.
- Aprenda a poner en práctica el clasificador Naive Bayes en R y Python
introduzione
Aquí hay una situación en la que te has metido en tu Scienza dei dati brutta copia:
Está trabajando en un obstáculo de clasificación y ha generado su conjunto de hipótesis, creado características y discutido la relevancia de las variables. En una hora, las partes interesadas quieren ver el primer corte del modelo.
¿Qué vas a hacer? Tienes cientos de cientos de puntos de datos y bastantes variables en tu conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina..... In una situazione del genere, si estuviera en tu lugar, habría usado ‘Bayes ingenuo', que puede ser extremadamente rápido en vinculación con otros algoritmos de clasificación. Funciona con el teorema de probabilidad de Bayes para predecir la clase de conjuntos de datos desconocidos.
In questo post, explicaré los conceptos básicos de este algoritmo, para que la próxima vez que se encuentre con grandes conjuntos de datos, pueda poner este algoritmo en acción. Allo stesso tempo, si eres un novato en Python il R, no debe sentirse abrumado por la presencia de códigos disponibles en este post.
Si prefiere aprender el teorema de Naive Bayes desde los conceptos básicos hasta la implementación de manera estructurada, puoi iscriverti a questo corso gratuitamente:
¿Eres un principiante en Machine Learning? ¿Pretendes dominar los algoritmos de aprendizaje automático como Naive Bayes? Aquí hay un curso completo que cubre el aprendizaje automático y los algoritmos de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... in dettaglio:
Proyecto para aplicar Naive BayesDichiarazione problemaL'analisi delle risorse umane sta rivoluzionando il modo in cui operano i dipartimenti delle risorse umane, portando a una maggiore efficienza e migliori risultati in generale. Los recursos humanos han estado usando la analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche.... durante gli anni. Nonostante questo, la collezione, l'elaborazione e l'analisi dei dati sono state in gran parte misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... manuale e, Data la natura delle dinamiche delle risorse umane e KPIKPI, o Indicatori chiave di prestazione, Si tratta di metriche utilizzate dalle organizzazioni per valutare il loro successo nel raggiungimento di obiettivi specifici. Questi indicatori consentono di monitorare i progressi e prendere decisioni informate. Esistono diversi tipi di KPI, che possono variare a seconda del settore e degli obiettivi strategici dell'azienda. La sua corretta attuazione è essenziale per migliorare l'efficienza e l'efficacia delle operazioni.... Risorse umane, l'approccio è stato quello di limitare le risorse umane. Perché, è sorprendente che i dipartimenti delle risorse umane si siano resi conto dell'utilità dell'apprendimento automatico così tardi nel gioco. Esta es una posibilidad para probar el análisis predictivo para identificar a los trabajadores con más probabilidades de ser promovidos. |
Sommario
- ¿Qué es el algoritmo Naive Bayes?
- ¿Cómo funcionan los algoritmos Naive Bayes?
- ¿Cuáles son los pros y los contras de utilizar Naive Bayes?
- 4 Aplicaciones del algoritmo Naive Bayes
- Pasos para construir un modelo Naive Bayes básico en Python
- Consejos para impulsar la potencia del modelo Naive Bayes
¿Qué es el algoritmo Naive Bayes?
È un tecnica di classificazione basado en el teorema de Bayes con un supuesto de independencia entre predictores. In parole povere, un clasificador Naive Bayes asume que la presencia de una característica particular en una clase no está relacionada con la presencia de ninguna otra característica.
Come esempio, una fruta puede considerarse una manzana si es roja, redonda y tiene aproximadamente 3 pulgadas de diámetro. Inclusive si estas características dependen unas de otras o de la existencia de otras características, todas estas propiedades contribuyen de forma independiente a la probabilidad de que esta fruta sea una manzana y es por esto que se la conoce como ‘Naive’.
El modelo Naive Bayes es fácil de construir y concretamente útil para conjuntos de datos muy grandes. Junto con la simplicidad, se sabe que Naive Bayes supera inclusive a los métodos de clasificación altamente sofisticados.
El teorema de Bayes proporciona una forma de calcular la probabilidad posterior P (C | X) a partir de P (C), P (X) y P (X | C). Mira la próxima ecuación:
 Encima,
Encima,
- PAG(C | X) es la probabilidad posterior de classe (C, obbiettivo) dado vaticinador (X, attributi).
- PAG(C) es la probabilidad previa de classe.
- PAG(X | C) es la probabilidad que es la probabilidad de vaticinador dado classe.
- PAG(X) es la probabilidad previa de vaticinador.
¿Cómo funciona el algoritmo Naive Bayes?
Capiamo con un esempio. A continuación tengo un conjunto de datos de entrenamiento del clima y la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... objetivo respectivo ‘Jugar’ (que sugiere posibilidades de juego). Ora, debemos categorizar si los jugadores jugarán o no según las condiciones climáticas. Sigamos los pasos a continuación para realizarlo.
passo 1: convierta el conjunto de datos en una tabla de frecuencias
passo 2: Cree una tabla de probabilidad encontrando las probabilidades como la probabilidad de Nublado = 0.29 y la probabilidad de jugar es 0.64.
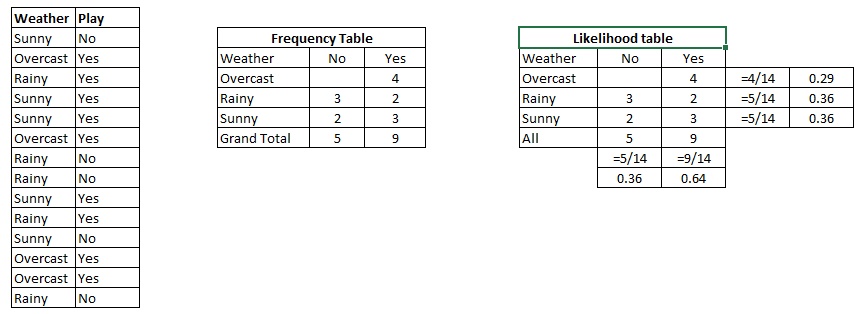
passo 3: Ora, usa Ingenuo bayesiano ecuación para calcular la probabilidad posterior para cada clase. La clase con la probabilidad posterior más alta es el resultado de el pronóstico.
Problema: Los jugadores jugarán si el clima es soleado. ¿Esta afirmación es correcta?
Podemos resolverlo usando el método de probabilidad posterior discutido previamente.
P (sì | Soleado) = P (Soleado | sì) * P (sì) / P (Soleado)
Aquí tenemos P (Soleado | sì) = 3/9 = 0.33, P (Soleado) = 5/14 = 0.36, P (sì) = 9/14 = 0.64
Ora, P (sì | Soleado) = 0.33 * 0.64 / 0.36 = 0.60, que tiene mayor probabilidad.
Naive Bayes utiliza un método equivalente para predecir la probabilidad de diferentes clases en función de varios atributos. Este algoritmo se utiliza principalmente en la clasificación de texto y con problemas que disponen múltiples clases.
¿Cuáles son los pros y los contras de Naive Bayes?
Professionisti:
- Es fácil y rápido predecir la clase de conjunto de datos de prueba. Además funciona bien en el pronóstico de clases múltiples.
- Cuando se cumple el supuesto de independencia, un clasificador Naive Bayes funciona mejor en comparación con otros modelos como la regresión logística y necesita menos datos de entrenamiento.
- Funciona bien en el caso de variables de entrada categóricas en comparación con variables numéricas. Para la variable numérica, se asume una distribución normal (campana curva, que es una suposición sólida).
Contro:
- Si la variable categórica dispone de una categoría (en el conjunto de datos de prueba), que no se observó en el conjunto de datos de entrenamiento, entonces el modelo asignará una probabilidad 0 (zero) y no podrá hacer una predicción. Esto a menudo se conoce como “Frecuencia cero”. Para arreglar esto, podemos usar la técnica de suavizado. Una de las técnicas de suavizado más simples se llama estimación de Laplace.
- D'altra parte, Bayes ingenuo además se conoce como un mal stimatoreIl "Estimatore" è uno strumento statistico utilizzato per dedurre le caratteristiche di una popolazione da un campione. Si basa su metodi matematici per fornire stime accurate e affidabili. Esistono diversi tipi di stimatori, come l'imparzialità e la coerenza, che vengono scelti in base al contesto e all'obiettivo dello studio. Il suo corretto utilizzo è essenziale nella ricerca scientifica, Sondaggi e analisi dei dati...., por lo que las salidas de probabilidad de predecir_proba no deben tomarse demasiado en serio.
- Otra limitación de Bayes ingenuo es el supuesto de predictores independientes. En la vida real, es casi imposible que obtengamos un conjunto de predictores que sean totalmente independientes.
4 Aplicaciones de los algoritmos ingenuos de Bayes
- Predicción en tiempo real: Naive Bayes es un clasificador de aprendizaje ávido y seguro que es rápido. Perciò, podría utilizarse para realizar predicciones en tiempo real.
- Predicción de clases múltiples: Este algoritmo además es bien conocido por su función de predicción de clases múltiples. Aquí podemos predecir la probabilidad de múltiples clases de variable objetivo.
- Classificazione del testo / filtrado de spam / análisis de opiniones: Los clasificadores Naive Bayes que se usan principalmente en la clasificación de texto (debido a un mejor resultado en problemas de clases múltiples y la regla de independencia) disponen una mayor tasa de éxito en comparación con otros algoritmos. Dovuto, se utiliza ampliamente en el filtrado de correo no deseado (identifica el email no deseado) y el análisis de sentimientos (en el análisis de redes sociales, para identificar los sentimientos positivos y negativos de los clientes).
- Sistema di raccomandazione: Clasificador Naive Bayes y Filtraggio collaborativo juntos construyen un sistema de recomendación que utiliza técnicas de aprendizaje automático y minería de datos para filtrar información invisible y predecir si un usuario desea un recurso determinado o no
¿Cómo construir un modelo básico usando Naive Bayes en Python y R?
Ancora, scikit impara (Libreria Python) ayudará aquí a construir un modelo Naive Bayes en Python. Hay tres tipos de modelo Naive Bayes en la biblioteca scikit-learn:
-
Gaussiano: Se utiliza en la clasificación y asume que las características siguen una distribución normal.
-
Multinomial: Se utiliza para recuentos discretos. Come esempio, digamos que tenemos un obstáculo de clasificación de texto. Aquí podemos considerar los ensayos de Bernoulli, que es un paso más allá y en lugar de “palabra que aparece en el documento”, avere “contar con qué frecuencia aparece la palabra en el documento”, puede pensar en ello como “número de veces que se observa el resultado número x_i durante los n ensayos ”.
-
Bernoulli: El modelo binomial es útil si sus vectores de características son binarios (In altre parole, ceros y unos). Una aplicación sería la clasificación de texto con el modelo de ‘bolsa de palabras’ donde los 1 e 0 figlio “la palabra aparece en el documento” e “la palabra no aparece en el documento”, rispettivamente.
Codice Python:
¡Pruebe el siguiente código en la ventana de codificación y verifique sus resultados sobre la marcha!
Código R:
richiedere(e1071 ·) #Holds the Naive Bayes Classifier Train <- leggi.csv(file.scegli()) Test <- leggi.csv(file.scegli()) #Make sure the target variable is of a two-class classification problem only levels(Train$Item_Fat_Content) modello <- naiveBayes(Item_Fat_Content~., data = Train) classe(modello) pred <- prevedere(modello,Test) tavolo(pred)
In precedenza, analizamos el modelo básico de Naive Bayes, puede mejorar la potencia de este modelo básico ajustando los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... y manejando las suposiciones de manera inteligente. Veamos los métodos para impulsar el rendimiento del modelo Naive Bayes. Te sugiero que pases por este documento para obtener más detalles sobre la clasificación de texto usando Naive Bayes.
Consejos para impulsar la potencia del modelo Naive Bayes
Prossimo, se ofrecen algunos consejos para impulsar la potencia de Bayes ingenuo Modello:
- Si las entidades continuas no disponen distribución normal, deberíamos utilizar transformación o diferentes métodos para convertirlas en distribución normal.
- Si el conjunto de datos de prueba tiene un obstáculo de frecuencia cero, aplique técnicas de suavizado “Corrección de Laplace” para predecir la clase de conjunto de datos de prueba.
- Elimine las características correlacionadas, puesto que las características altamente correlacionadas se votan dos veces en el modelo y pueden dar lugar a una relevancia exagerada.
- Los clasificadores Naive Bayes disponen opciones limitadas para el ajuste de parámetros como alpha = 1 para suavizar, fit_prior =[Vero|falso] para aprender las probabilidades previas de la clase o no y algunas otras opciones (ver detalles qui). Recomendaría centrarse en el procesamiento previo de datos y la selección de funciones.
- Podrías pensar en aplicar algunos técnica de combinación de clasificador como impostare, ensacado y refuerzo, pero estos métodos no ayudarían. In realtà, “ensamblar, impulsar, embolsar” no ayudará, puesto que su objetivo es reducir la variación. Naive Bayes no tiene ninguna variación que minimizar.
Note finali
In questo post, analizamos uno de los algoritmos de aprendizaje automático supervisados ”Ingenuo Bayes” que se utiliza principalmente para la clasificación. Felicidades, si ha entendido bien este post, ya ha dado el primer paso para dominar este algoritmo. Da ora in poi, todo lo que necesitas es practicar.
Allo stesso tempo, le sugiero que se centre más en el preprocesamiento de datos y la selección de características antes de aplicar el algoritmo Naive Bayes.0 En una publicación futura, hablaré sobre la clasificación de textos y documentos usando bayes ingenuos con más detalle.
Questo post è stato utile?? Condividi le tue opinioni / pensieri nella sezione commenti qui sotto.
Puede usar el siguiente recurso sin costes para aprender- Ingenuo Bayes-





