Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Questo ha funzionato convenzionalmente con il piano aziendale e le tendenze delle notizie. Con l'avvento della scienza dei dati e dell'apprendimento automatico, Diversi approcci di ricerca sono stati progettati per automatizzare questo processo manuale. Questo processo di trading automatizzato aiuterà a dare suggerimenti al momento giusto con calcoli migliori.. Una strategia di trading automatizzata che offra il massimo profitto è altamente auspicabile per i fondi comuni di investimento e gli hedge fund.. Il tipo di rendimento redditizio previsto comporterà un potenziale rischio. Progettare una strategia di trading automatizzato redditizia è un compito complesso.
Ogni essere umano vuole guadagnare il suo massimo potenziale in borsa. È molto importante progettare una strategia equilibrata ea basso rischio che possa avvantaggiare la maggior parte delle persone.. Uno de estos enfoques habla sobre el uso de agentes de Apprendimento per rinforzoL'apprendimento per rinforzo è una tecnica di intelligenza artificiale che consente a un agente di imparare a prendere decisioni interagendo con un ambiente. Attraverso il feedback sotto forma di premi o punizioni, L'agente ottimizza il proprio comportamento per massimizzare le ricompense accumulate. Questo approccio viene utilizzato in una varietà di applicazioni, Dai videogiochi alla robotica e ai sistemi di raccomandazione, distinguendosi per la sua capacità di apprendere strategie complesse.... para proporcionarnos estrategias comerciales automatizadas basadas en datos históricos.
Apprendimento rinforzato
L'apprendimento per rinforzo è un tipo di apprendimento automatico in cui sono presenti ambienti e agenti. Questi agenti intraprendono azioni per massimizzare i premi. L'apprendimento per rinforzo ha un potenziale enorme se utilizzato per le simulazioni per addestrare un modello di intelligenza artificiale. Non ci sono tag associati a nessun dato, l'apprendimento per rinforzo può imparare meglio con pochissimi punti dati. Tutte le decisioni, in questo caso, sono presi in sequenza. L'esempio migliore si trova in Robotica e giochi.
Q – Apprendimento
Il Q-learning è un algoritmo di apprendimento per rinforzo senza modello. Informa l'agente quale azione intraprendere in base alle circostanze. È un metodo basato sul valore che viene utilizzato per fornire informazioni a un agente per un'azione imminente. È considerato un algoritmo al di fuori della politica, poiché la funzione q-learning apprende da azioni che sono al di fuori della politica attuale, come eseguire azioni casuali e, così, nessuna politica necessaria.
Q qui significa Qualità. La qualità si riferisce alla qualità dell'azione in termini di vantaggio che tale ricompensa sarà basata sull'azione intrapresa.. Viene creata una tabella Q con le dimensioni [stato,azione]Un agente interagisce con l'ambiente in due modi: esplodi ed esplora. Un'opzione di sfruttamento suggerisce di considerare tutte le azioni e di intraprendere quella che dà il massimo valore all'ambiente. Un'opzione di esplorazione è quella in cui viene considerata un'azione casuale senza considerare la massima ricompensa futura.
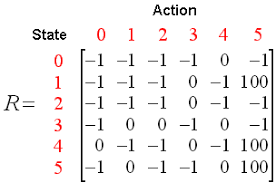

Q di st e at è rappresentato da una formula che calcola la massima ricompensa futura scontata quando un'azione viene eseguita in uno stato s.
La función definida nos proporcionará la recompensa máxima al final del número n de ciclos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... o iteraciones.
Il commercio può avere le seguenti chiamate: comprare, vendere o tenere
Q-learning valuterà ciascuna delle azioni e verrà selezionata quella con il valore massimo. Q-Learning si basa sull'apprendimento dei valori della Q-table. Funziona bene senza le funzioni di ricompensa e le probabilità di transizione dello stato.
Apprendimento rafforzato nella compravendita di azioni
L'apprendimento per rinforzo può risolvere vari tipi di problemi. Il trading è un'attività continua senza alcun endpoint. La negoziazione è anche un processo decisionale di Markov parzialmente osservabile., poiché non disponiamo di informazioni complete sui trader sul mercato. Come non conosciamo la funzione di ricompensa e la probabilità di transizione, usiamo l'apprendimento per rinforzo senza un modello, cos'è Q-Learning.
Passaggi per eseguire un agente RL:
-
Installa librerie
-
Ottieni i dati
-
Definire l'agente Q-Learning
-
Formare l'agente
-
Testare l'agente
-
Traccia i segnali
Installa librerie
Installare e importare le librerie finanziarie NumPy necessarie, panda, matplotlib, seaborn e yahoo.
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set() !pip install yfinance --upgrade --no-cache-dir from pandas_datareader import data as pdr import fix_yahoo_finance as yf from collections import deque import random Import tensorflow.compat.v1 as tf tf.compat.v1.disable_eager_execution()
Ottieni i dati
Utilizzare la libreria di Yahoo Finance per ottenere i dati per un particolare titolo. Le azioni utilizzate qui per la nostra analisi sono le azioni di Infosys.
yf.pdr_override()
df_full = pdr.get_data_yahoo("INFY", inizio="2018-01-01").reset_index()
df_full.to_csv('INFY.csv',indice=Falso)
df_full.head()
Questo codice creerà un framework di dati chiamato df_full che conterrà i prezzi delle azioni di INFY nel corso del 2 anni.
Definire l'agente Q-Learning
La prima funzione è la classe agente che definisce la dimensione dello stato, dimensione della finestra, Dimensione del lotto, deque qual è la memoria utilizzata, inventario come elenco. Definisci anche alcune variabili statiche come epsilon, decadimento, gamma, eccetera. Se definen dos capas de neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. para la compra, metti in attesa e vendi chiamate. Viene utilizzato anche GradientDescentOptimizer.
L'agente ha funzioni definite per le opzioni call e put. La funzione get_state e act utilizza la rete neurale per generare lo stato successivo della rete neurale. I premi vengono successivamente calcolati sommando o sottraendo il valore generato dall'esecuzione dell'opzione call. L'azione intrapresa nello stato successivo è influenzata dall'azione intrapresa nello stato precedente. 1 si riferisce a una chiamata di acquisto, mentre 2 si riferisce a una chiamata di vendita. In ogni iterazione, el estado se determina sobre la base del cual se toma una acción que comprará o venderá algunas acciones. Las recompensas generales se almacenan en la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... de beneficio total.
df= df_full.copy()
nome="Agente Q-learning"
classe Agent:
def __init__(se stesso, state_size, window_size, tendenza, saltare, dimensione del lotto):
self.state_size = state_size
self.window_size = window_size
self.half_window = window_size // 2
self.trend = trend
self.skip = skip
self.action_size = 3
self.batch_size = batch_size
self.memory = deque(maxlen = 1000)
self.inventory = []
self.gamma = 0.95
self.epsilon = 0.5
self.epsilon_min = 0.01
self.epsilon_decay = 0.999
tf.reset_default_graph()
self.sess = tf. InteractiveSession()
stesso. X = tf.segnaposto(tf.float32, [Nessuno, self.state_size])
stesso. Y = tf.segnaposto(tf.float32, [Nessuno, self.action_size])
feed = tf.layers.dense(stesso. X, 256, attivazione = tf.nn.relu)
self.logits = tf.layers.dense(Nutrire, self.action_size)
self.cost = tf.reduce_mean(tf.quadrato(stesso. Y - self.logits))
self.optimizer = tf.train.GradientDescentOptimizer(1e-5 ·).minimizzare(
self.cost
)
self.sess.run(tf.global_variables_initializer())
def atto(se stesso, stato):
se random.random() <= self.epsilon:
restituire random.randrange(self.action_size)
restituire np.argmax(
self.sess.run(self.logits, feed_dict = {stesso. X: stato})[0]
)
def get_state(se stesso, T):
window_size = self.window_size + 1
d = t - window_size + 1
blocco = self.trend[D : T + 1] se d >= 0 else -d * [self.trend[0]] + self.trend[0 : T + 1]
res = []
per io nel raggio d'azione(window_size - 1):
res.append(blocco[io + 1] - blocco[io])
restituire np.array([res])
def replay(se stesso, dimensione del lotto):
mini_batch = []
l = len(self.memory)
per io nel raggio d'azione(io - dimensione del lotto, io):
mini_batch.append(self.memory[io])
replay_size = len(mini_batch)
X = np.empty((replay_size, self.state_size))
Y = np.empty((replay_size, self.action_size))
states = np.array([un[0][0] per un in mini_batch])
new_states = np.array([un[3][0] per un in mini_batch])
Q = self.sess.run(self.logits, feed_dict = {stesso. X: stati})
Q_new = self.sess.run(self.logits, feed_dict = {stesso. X: new_states})
per io nel raggio d'azione(len(mini_batch)):
stato, azione, ricompensa, next_state, fatto = mini_batch[io]
target = Q[io]
obbiettivo[azione] = reward
if not done:
obbiettivo[azione] += self.gamma * np.amax(Q_new[io])
X[io] = state
Y[io] = target
cost, _ = self.sess.run(
[self.cost, self.optimizer], feed_dict = {stesso. X: X, stesso. Y: E}
)
se self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
return cost
def buy(se stesso, initial_money):
starting_money = initial_money
states_sell = []
states_buy = []
inventario = []
stato = self.get_state(0)
per t nell'intervallo(0, len(self.trend) - 1, self.skip):
azione = self.act(stato)
next_state = self.get_state(T + 1)
se azione == 1 e initial_money >= self.trend inventory.append(self.trend initial_money -= self.trend states_buy.append print(«giorno %d: comprare 1 unità al prezzo %f, saldo totale %f'% (T, self.trend elif azione == 2 e len(inventario):
bought_price = inventory.pop(0)
initial_money += self.trend states_sell.append prova:
investire = ((chiudi tranne:
investire = 0
Stampa(
«giorno %d, vendere 1 unità al prezzo %f, investimento %f %%, saldo totale %f,'
% (T, chiudere
)
state = next_state
invest = ((initial_money - starting_money) / starting_money) * 100
total_gains = initial_money - starting_money
return states_buy, states_sell, total_gains, invest
def train(se stesso, Iterazioni, posto di blocco, initial_money):
per io nel raggio d'azione(Iterazioni):
total_profit = 0
inventario = []
stato = self.get_state(0)
starting_money = initial_money
for t in range(0, len(self.trend) - 1, self.skip):
azione = self.act(stato)
next_state = self.get_state(T + 1)
se azione == 1 e starting_money >= self.trend inventory.append(self.trend starting_money -= self.trend elif action == 2 e len(inventario) > 0:
bought_price = inventory.pop(0)
total_profit += self.trend starting_money += self.trend invest = ((starting_money - initial_money) / initial_money)
self.memory.append((stato, azione, investire,
next_state, starting_money < initial_money))
state = next_state
batch_size = min(self.batch_size, len(self.memory))
costo = self.replay(dimensione del lotto)
Se (i+1) % checkpoint == 0:
Stampa('epoca: %D, ricompense totali: %f.3, costo: %F, denaro totale: %f'%(io + 1, total_profit, costo,
starting_money))
Formare l'agente
Una vez definido el agente, inicialícelo. Especifique el número de iteraciones, dinero inicial, eccetera. para capacitar al agente para que decida las opciones de compra o venta.
close = df. Chiudi.valori.tolist()
initial_money = 10000
window_size = 30
salta = 1
batch_size = 32
agente = Agente(state_size = window_size,
window_size = window_size,
trend = chiudi,
skip = salta,
batch_size = batch_size)
agent.train(iterazioni = 200, checkpoint = 10, initial_money = initial_money)
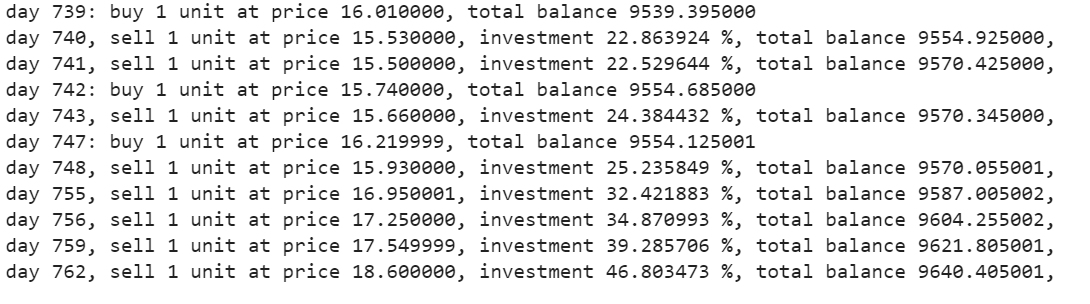
Produzione –

Testare l'agente
La función de compra devolverá las cifras de compra, saldi, profitto e investimento.
States_buy, states_sell, total_gains, investi = agente.acquista(initial_money = initial_money)
Traccia le chiamate
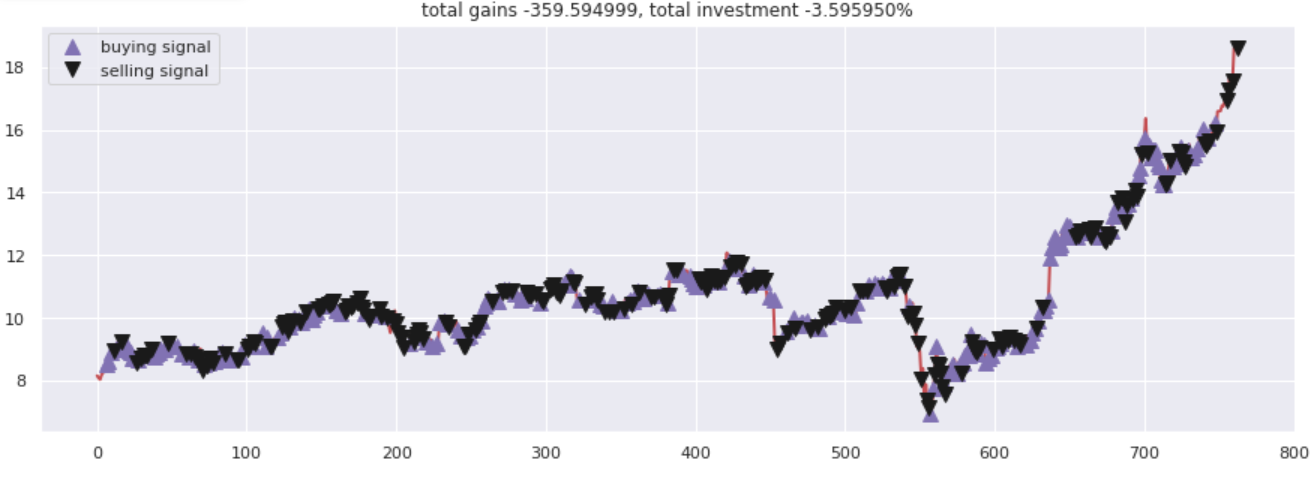
Traccia i guadagni totali rispetto alle cifre investite. Tutte le chiamate di acquisto e vendita sono state contrassegnate correttamente in base alle opzioni di acquisto / vendita suggerita dalla rete neurale.
fig = plt.figure(dimensione del fico = (15,5))
plt.trama(chiudere, colore="R", lw=2.)
plt.trama(chiudere, '^', dimensione dell'indicatore = 10, colore="m", etichetta="segnale di acquisto", markevery = States_buy)
plt.trama(chiudere, 'v', dimensione dell'indicatore = 10, colore="K", etichetta="segnale di vendita", markevery = States_sell)
plt.titolo('guadagno totale %f, investimento totale %f%%'%(total_gains, investire))
plt.legend()
plt.savefig(nome+'.png')
plt.mostra()
Produzione –
Note finali
Q-Learning è una tecnica che ti aiuta a sviluppare una strategia di trading automatizzata. Può essere utilizzato per sperimentare opzioni call o put. Ci sono molti altri agenti di apprendimento per rinforzo commerciale con cui sperimentare. Prova a giocare con i diversi tipi di agenti RL con azioni diverse.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





