introduzione
Sta diventando molto difficile tenere il passo con i recenti sviluppi che si stanno verificando nel apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute.... Non passa giorno senza che arrivi una nuova innovazione o una nuova app di deep learning. tuttavia, La maggior parte di questi progressi sono nascosti in un gran numero di articoli di ricerca pubblicati su media come ArXiv / Springer.

Per tenerci aggiornati, abbiamo creato un piccolo gruppo di lettura per condividere i nostri apprendimenti internamente in DataPeaker. Uno di quegli insegnamenti che vorrei condividere con la comunità è uno studio di architetture avanzate che sono state sviluppate dalla comunità di ricerca.
Questo articolo contiene alcuni dei recenti progressi nell'apprendimento profondo insieme ai codici per l'implementazione nella libreria keras. Ho anche fornito collegamenti agli articoli originali, nel caso foste interessati a leggerli o voleste farvi riferimento.
Per mantenere l'articolo conciso, Ho considerato solo architetture che hanno avuto successo nel dominio della Computer Vision.
Se sei interessato, continua a leggere!
PD: Questo articolo presuppone la conoscenza delle reti neurali e la familiarità con keras. Se hai bisogno di recuperare il ritardo su questi argomenti, Consiglio vivamente di leggere prima i seguenti articoli:
Sommario
- Cosa intendiamo per architettura avanzata?
- Tipi di attività di visione artificiale
- Elenco delle architetture di deep learning
Cosa intendiamo per architettura avanzata?
Gli algoritmi di deep learning sono costituiti da un insieme così diversificato di modelli rispetto a un singolo algoritmo di machine learning tradizionale. Ciò è dovuto alla flessibilità fornita dal neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. Quando si crea un modello end-to-end completo.
La rete neurale a volte può essere paragonata ai blocchi lego, dove puoi costruire quasi tutte le strutture semplici o complesse che la tua immaginazione ti aiuta a costruire.
Possiamo definire un'architettura avanzata come un'architettura che ha una comprovata esperienza di essere un modello di successo.. Questo si vede principalmente in sfide come ImageNet, dove il tuo compito è risolvere un problema, diciamo riconoscimento delle immagini, utilizzando i dati forniti. Chi non sa cos'è ImageNet, è il set di dati fornito nella sfida ILSVR (Riconoscimento visivo su larga scala ImageNet).
Anche come descritto nelle architetture sotto menzionate, ognuno di loro ha una sfumatura che li differenzia dai soliti modelli; dando loro un vantaggio quando vengono utilizzati per risolvere un problema. Anche queste architetture rientrano nella categoria dei modelli “profondo”, quindi è probabile che si comportino meglio delle loro controparti superficiali.
Tipi di attività di visione artificiale
Questo articolo è principalmente incentrato sulla visione artificiale, quindi è naturale descrivere l'orizzonte delle attività di visione artificiale. Visione computerizzata; Come suggerisce il nome, si tratta semplicemente di creare modelli artificiali in grado di replicare i compiti visivi svolti da un essere umano. Ciò significa essenzialmente che ciò che possiamo vedere e ciò che percepiamo è un processo che può essere compreso e implementato in un sistema artificiale..
I principali tipi di attività in cui è possibile classificare la visione artificiale sono i seguenti:
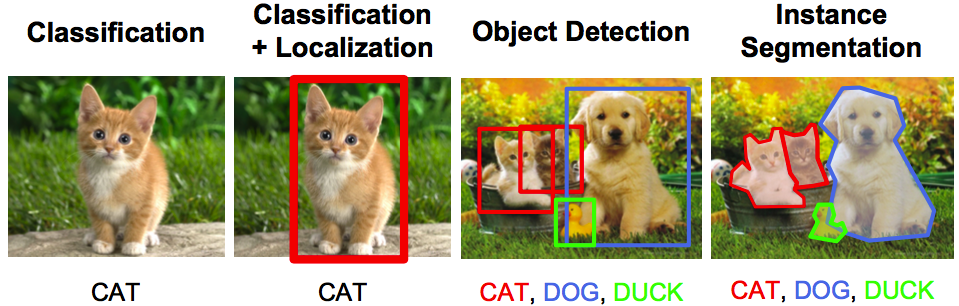
- Riconoscimento / classificazione degli oggetti – Nel riconoscimento degli oggetti, ti viene data un'immagine grezza e il tuo compito è identificare a quale classe appartiene l'immagine.
- Classificazione + Posizione – Se c'è un solo oggetto nell'immagine e il tuo compito è trovare la posizione di quell'oggetto, un termine più specifico per questo problema è problema di posizione.
- Rilevamento di oggetti – Al rilevamento di oggetti, il tuo compito è identificare dove si trovano gli oggetti nell'immagine. Questi oggetti possono essere della stessa classe o di una classe completamente diversa.
- SegmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione.... Immagine – La segmentazione delle immagini è un compito un po' sofisticato, dove l'obiettivo è mappare ogni pixel alla sua classe legittima.
Elenco delle architetture di deep learning
Ora che abbiamo capito cos'è l'architettura avanzata e abbiamo esplorato i compiti della computer vision, elenchiamo le architetture più importanti e le loro descrizioni:
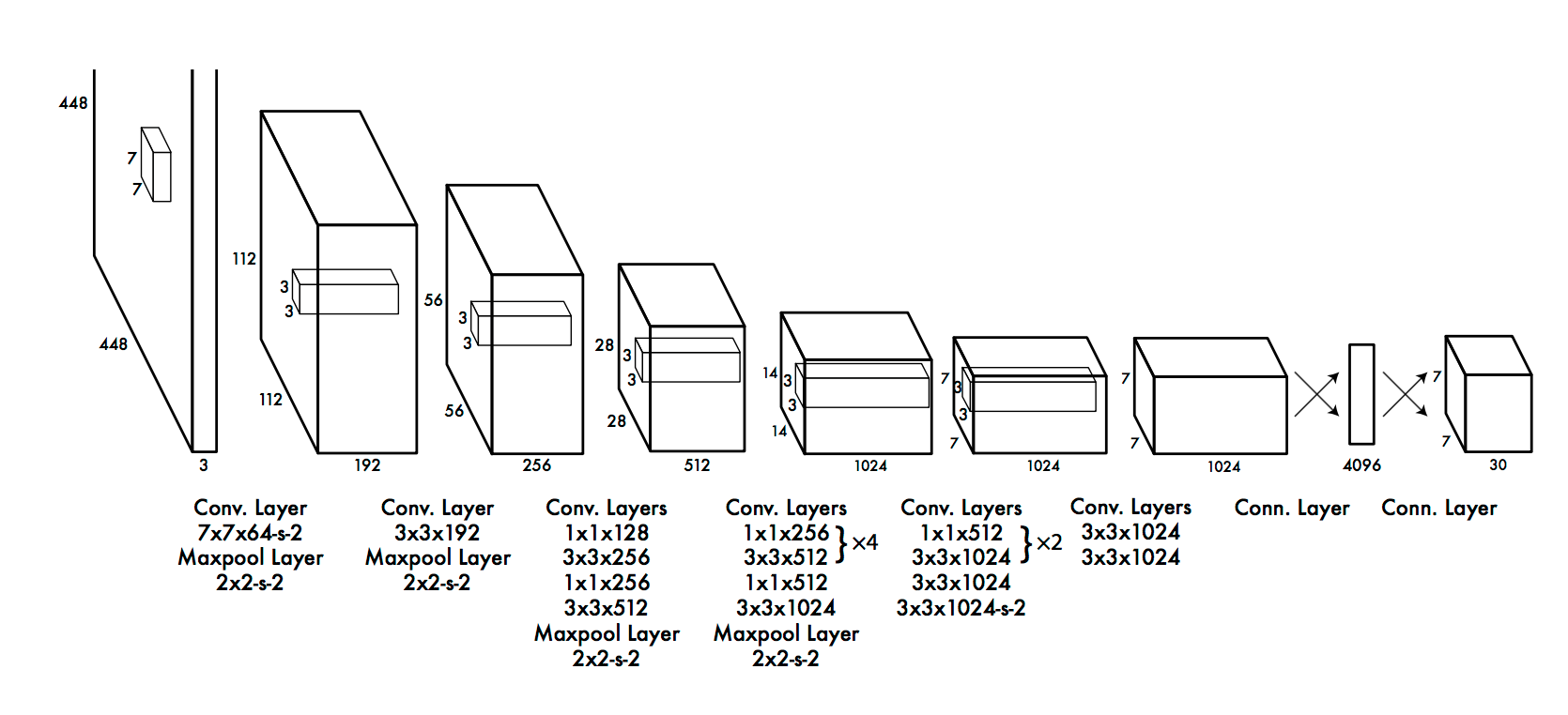
1. AlexNet
AlexNet è la prima architettura profonda introdotta da uno dei pionieri del deep learning: Geoffrey Hinton e i suoi colleghi. È un'architettura di rete semplice ma potente, che ha contribuito a spianare la strada alla rivoluzionaria ricerca sull'apprendimento profondo così com'è ora. Ecco una rappresentazione dell'architettura proposta dagli autori.
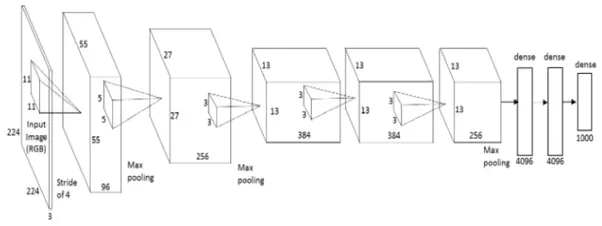
Quando si rompe, AlexNet sembra un'architettura semplice con strati convolutivi e raggruppati uno sopra l'altro, seguito da strati completamente collegati in alto. Questa è un'architettura molto semplice, che è stato concettualizzato nel decennio di 1980. Ciò che distingue questo modello è la scala con cui esegue il compito e l'uso della GPU per il addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina..... Nel decennio di 1980, la CPU è stata utilizzata per addestrare una rete neurale. Mentre AlexNet velocizza la formazione 10 volte solo con l'uso di GPU.
Anche se un po' datato al momento, AlexNet è ancora utilizzato come punto di partenza per applicare reti neurali profonde per tutte le attività, o visione artificiale o riconoscimento vocale.
2. Rete VGG
La rete VGG è stata presentata dai ricercatori del Visual Graphics Group di Oxford (da qui il nome VGG). Questa rete è particolarmente caratterizzata dalla sua forma piramidale, dove gli strati inferiori più vicini all'immagine sono larghi, mentre gli strati superiori sono profondi.
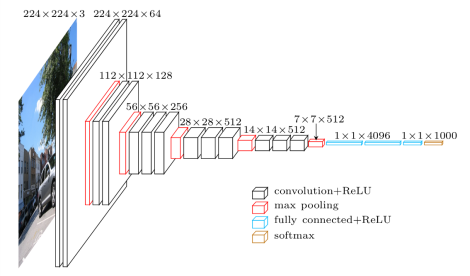
Come mostra l'immagine, VGG contiene strati convoluzionali posteriori seguiti da strati raggruppati. Gli strati di raggruppamento sono responsabili del restringimento degli strati. Nel tuo articolo, proposto più tipi di reti di questo tipo, con cambiamenti nella profondità dell'architettura.
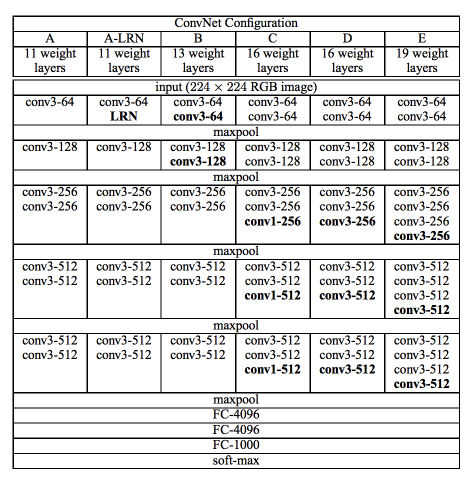
I vantaggi di VGG sono:
- È un'ottima architettura per il benchmarking su un compito particolare.
- Cosa c'è di più, le reti pre-abilitate per VGG sono disponibili gratuitamente su Internet, quindi è comunemente usato per varie applicazioni.
In secondo luogo, il suo principale svantaggio è che è molto lento allenarsi se ti alleni da zero. Incluso con una GPU decente, ci vorrebbe più di una settimana per farlo funzionare.
3. GoogleNet
GoogleNet (o Rete iniziale) è un corso di architettura progettato dai ricercatori di Google. GoogleNet è stato il vincitore di ImageNet 2014, dove ha dimostrato di essere un modello potente.
In questa architettura, oltre ad approfondire (contiene 22 strati rispetto a VGG che aveva 19 copertine), i ricercatori hanno anche realizzato un nuovo approccio chiamato modulo Inception.
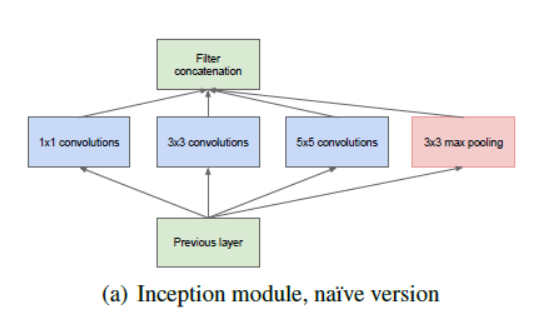
Come visto sopra, è un cambiamento drastico rispetto alle architetture sequenziali che abbiamo visto prima. In un unico strato, vari tipi di “estrattori di caratteristiche”. Questo aiuta indirettamente la rete a funzionare meglio, poiché la rete in formazione ha molte opzioni tra cui scegliere quando si risolve il compito. Puoi scegliere di convolure l'input o raggrupparlo direttamente.
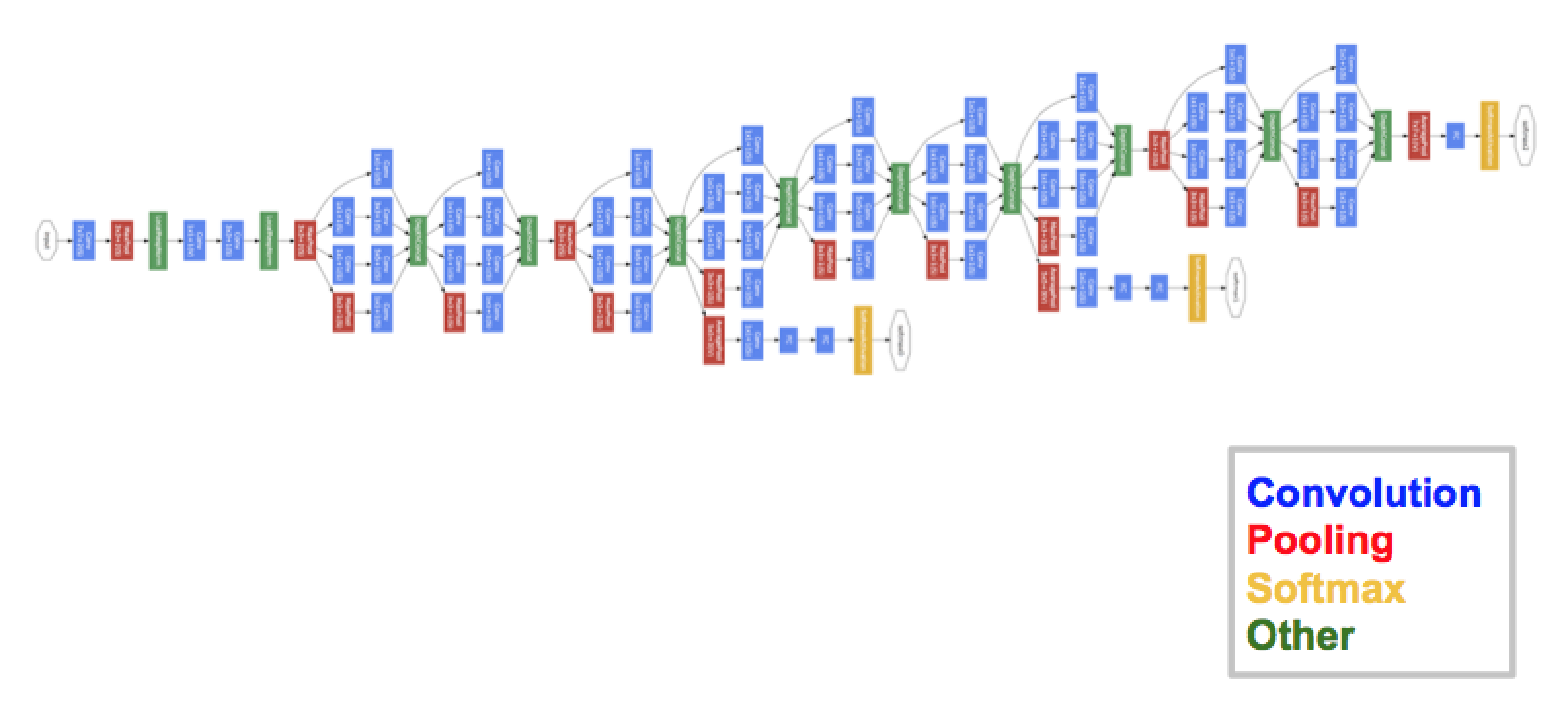
L'architettura finale contiene molti di questi moduli iniziali impilati uno sopra l'altro.. Anche la formazione è leggermente diversa su GoogleNet, poiché la maggior parte degli strati superiori ha i propri Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati..... Questa sfumatura aiuta il modello a convergere più velocemente, poiché esiste un allenamento congiunto e un allenamento parallelo per gli strati stessi.
I vantaggi di GoogleNet sono:
- GoogleNet si allena più velocemente di VGG.
- La dimensione di una rete Google precedentemente addestrata è relativamente più piccola di quella di VGG. Un modello VGG può avere> 500 MB, mentre GoogleNet ha una dimensione di soli 96 MB
GoogleNet non ha uno svantaggio immediato di per sé, ma vengono proposte ulteriori modifiche all'architettura, che fanno funzionare meglio il modello. Uno di questi cambiamenti si chiama Red Xception, in cui viene aumentato il limite di divergenza del modulo iniziale (4 su GoogleNet come abbiamo visto nell'immagine sopra). Ora teoricamente può essere infinito (Quindi si chiama avvio estremo!)
4. ResNet
ResNet è una delle architetture mostruose che definisce davvero quanto può essere profonda un'architettura di deep learning.. Reti residue (ResNet in breve) è costituito da più moduli residui successivi, quali sono gli elementi costitutivi di base dell'architettura ResNet. Una rappresentazione del modulo residuo è la seguente
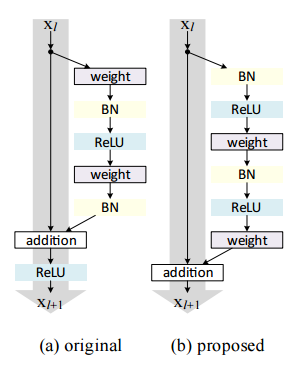
In parole semplici, un modulo residuo ha due opzioni, puoi eseguire una serie di funzioni sull'input o puoi saltare del tutto questo passaggio.
Ora simile a GoogleNet, questi moduli residui sono impilati uno sopra l'altro per formare una rete end-to-end completa.

Alcune tecniche più recenti introdotte da ResNet includono:
- Utilizzo di SGD standard invece di tecniche di apprendimento adattivo di fantasia. Questo viene fatto insieme a una ragionevole funzione di inizializzazione che mantiene intatto l'addestramento..
- Modifiche alla preelaborazione dell'input, dove l'input viene prima patchato e poi inviato alla rete.
Il vantaggio principale di ResNet è che centinaia, anche migliaia di questi livelli residui possono essere utilizzati per creare una rete e quindi addestrare. Questo è un po' diverso dalle solite reti sequenziali, dove si notano miglioramenti delle prestazioni ridotti a misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... che aumenta il numero di strati.
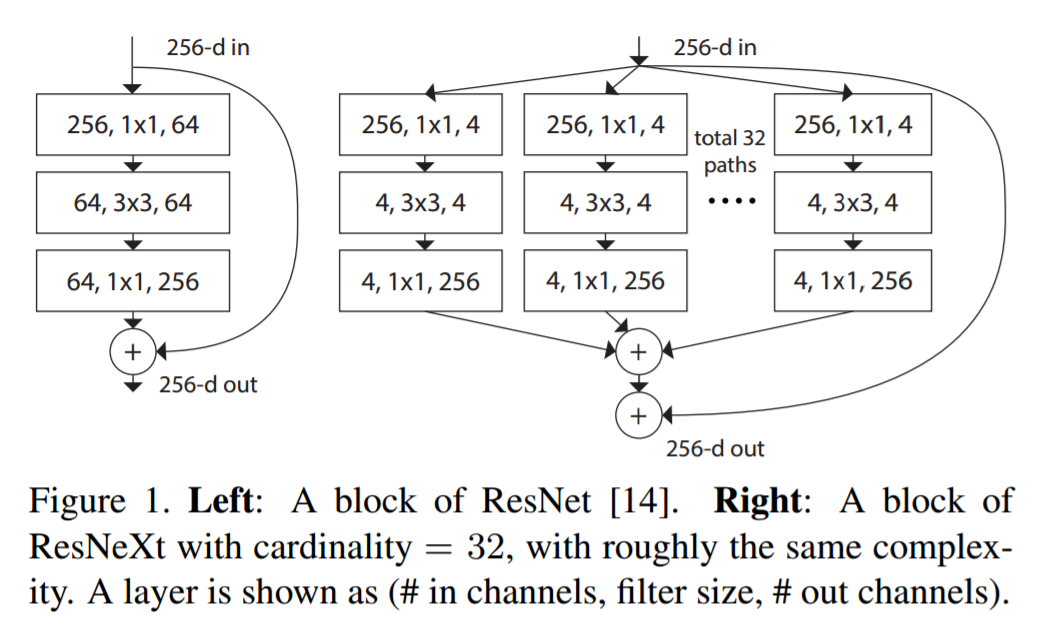
5. ResNeXt
Si dice che ResNeXt sia la tecnica attuale più avanzata per il riconoscimento degli oggetti. Si basa sui concetti di startup e resnet per generare un'architettura nuova e migliorata. L'immagine seguente è un riepilogo di come appare un modulo residuo del modulo ResNeXt.
6. RCNN (CNN regionale)
Si dice che l'architettura CNN basata sulla regione sia la più influente di tutte le architetture di deep learning che sono state applicate al problema del rilevamento degli oggetti.. Per risolvere il problema di rilevamento, ciò che fa RCNN è provare a disegnare un riquadro di delimitazione su tutti gli oggetti presenti nell'immagine e quindi riconoscere quale oggetto è nell'immagine. Funziona nel modo seguente:
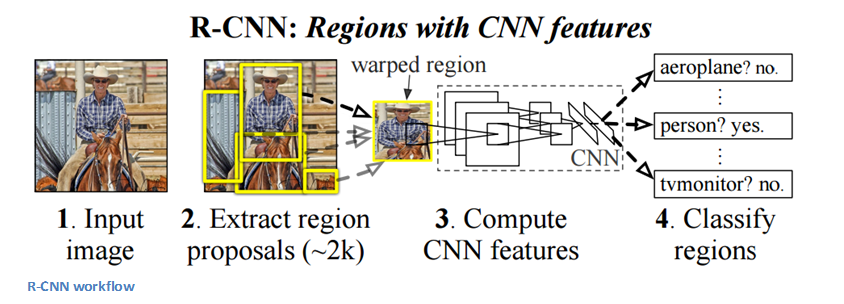
La struttura di RCNN è la seguente:
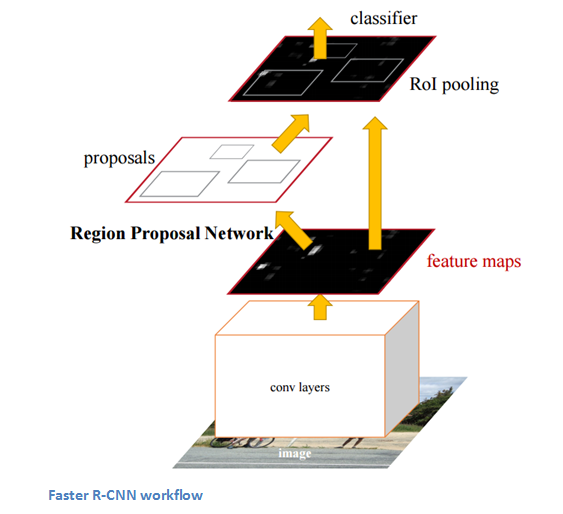
7. YOLO (guardi una volta sola)
YOLO è l'attuale sistema all'avanguardia basato sul deep learning in tempo reale per la risoluzione dei problemi di rilevamento delle immagini. Come si vede nell'immagine qui sotto, prima suddivide l'immagine in riquadri di delimitazione definiti e quindi esegue un algoritmo di riconoscimento in parallelo per tutti questi riquadri per identificare a quale classe di oggetti appartengono. Dopo aver identificato queste classi, continua a unire abilmente questi riquadri per formare un riquadro di delimitazione ottimale attorno agli oggetti.

Tutto questo viene fatto in parallelo, quindi può funzionare in tempo reale; elaborazione 40 immagini in un secondo.
Sebbene offra prestazioni ridotte rispetto alla sua controparte RCNN, ha ancora il vantaggio di essere in tempo reale per essere fattibile per l'uso nei problemi quotidiani. Ecco un rendering dell'architettura YOLO.
8. SqueezeNet
L'architettura squeezeNet è un'architettura più potente ed è estremamente utile in scenari a bassa larghezza di banda come le piattaforme mobili.. Questa architettura occupa solo 4,9 MB di spazio, In secondo luogo, L'inizio occupa ~ 100 MB! Questo drastico cambiamento è determinato da una struttura specializzata chiamata modulo antincendio.. L'immagine sotto è una rappresentazione del modulo antincendio.
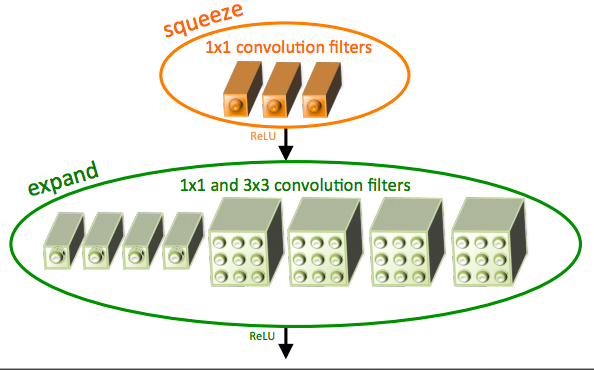
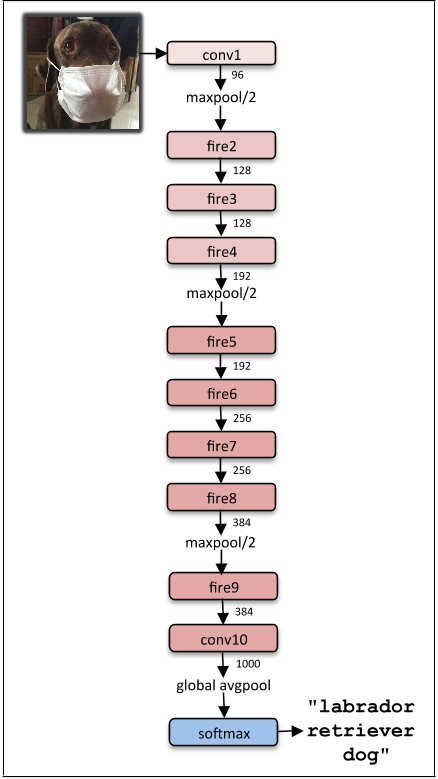
L'architettura finale di squeezeNet è la seguente:
9. SegNet
SegNet è un'architettura di deep learning applicata per risolvere problemi di segmentazione delle immagini. Consiste in una sequenza di livelli di elaborazione (codificatori) seguito da un corrispondente set di decodificatori per una classificazione dei pixel. L'immagine seguente riassume il funzionamento di SegNet.
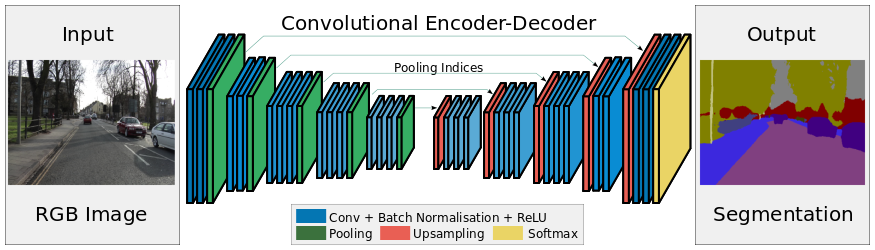
Una caratteristica fondamentale di SegNet è che conserva i dettagli ad alta frequenza nell'immagine segmentata, in quanto gli indici di clustering della rete di codificatori sono collegati agli indici di clustering delle reti di decodificatori. In sintesi, il trasferimento delle informazioni è diretto piuttosto che contorto. SegNet è uno dei migliori modelli da utilizzare quando si tratta di problemi di segmentazione delle immagini.
10. GAN (Rete avversaria generativa)
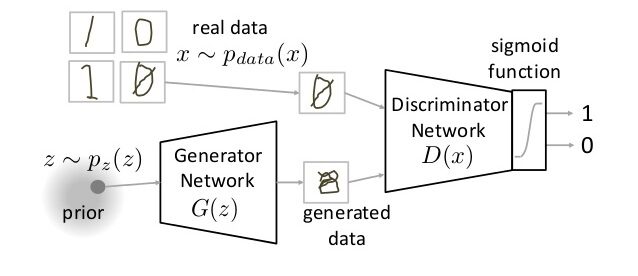
GAN è una classe completamente diversa di architetture di reti neurali, in cui viene utilizzata una rete neurale per generare un'immagine completamente nuova che non è presente nel set di dati di addestramento, ma è abbastanza realistico da essere nel set di dati. Ad esempio, l'immagine sotto è una ripartizione del GAN. Ho spiegato come funzionano i GAN in questo articolo.. Dai un'occhiata se sei curioso.
Note finali
In questo articolo, Ho coperto una panoramica delle principali architetture di deep learning con cui dovresti avere familiarità. Se hai domande sulle architetture di deep learning, sentiti libero di condividerlo con me attraverso i commenti.





