Tema a cubrir
- Cos'è l'analisi esplorativa dei dati?
- ¿Cuál es la necesidad de automatizar el análisis de datos exploratorios?
- Bibliotecas de Python para automatizar el análisis de datos exploratorios
Analisi esplorativa dei dati
es una técnica de exploración de datos para comprender los diversos aspectos de los datos. Es una especie de resumen de datos. Es uno de los pasos más importantes antes de realizar cualquier tarea de aprendizaje automático o apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute....
Los científicos de datos llevan a cabo procedimientos de análisis de datos exploratorios para explorar, diseccionar y resumir las cualidades fundamentales de los conjuntos de datos, utilizando regularmente enfoques de representación de información. Los procedimientos de EDA toman en consideración un control convincente de las fuentes de información, lo que permite a los científicos de datos descubrir las respuestas adecuadas que necesitan al encontrar diseños de información, detectar inconsistencias, verificar suposiciones o probar especulaciones.
Los científicos de datos utilizan análisis de datos exploratorios para observar qué conjuntos de datos pueden descubrir más allá de la demostración convencional de información o asignaciones de pruebas de especulación. Esto les permite adquirir información de arriba a abajo sobre los factores en los conjuntos de datos y sus conexiones. El análisis de datos exploratorio puede ayudar a reconocer errores claros, distinguir excepciones en conjuntos de datos, obtener conexiones, descubrir elementos significativos, descubra diseños con información privilegiada y brinde nuevos conocimientos.
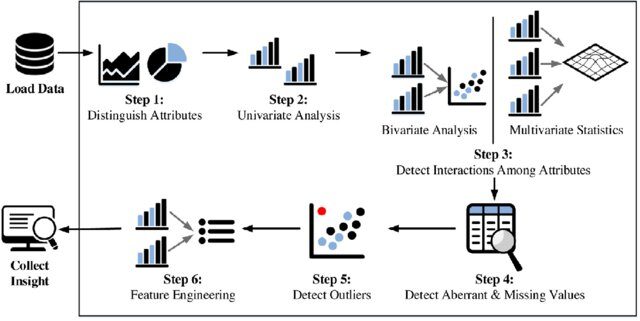
Fasi dell'analisi esplorativa dei dati
Necesidad de automatizar el análisis de datos exploratorios
El movimiento ampliado de los clientes en la web, los instrumentos refinados para controlar el tráfico web, la multiplicación de teléfonos móviles, los dispositivos habilitados para la web y los sensores de IoT son los elementos esenciales que aceleran el ritmo de la era de la información en la actualidad. En esta era computarizada, las asociaciones de todos los tamaños comprenden que la información puede asumir un papel crucial en la mejora de su competencia, rentabilidad y habilidades dinámicas, lo que genera mayores acuerdos, ingresos y beneficios.
Oggi, la mayoría de las organizaciones se acercan a inmensos conjuntos de datos, tuttavia, solo tener grandes medidas de información no mejora el negocio, excepto si las empresas investigan los datos accesibles e impulsan el desarrollo autorizado.

En el ciclo de vida de un proyecto de ciencia de datos o cualquier proyecto de aprendizaje automático, più di 60% de tu tiempo entra en cosas como análisis de datos, selección de características, ingegneria delle caratteristiche, eccetera. Debido a que es la parte más importante o la columna vertebral de un proyecto de ciencia de datos, es esa parte en particular en la que tiene que realizar muchas actividades como limpiar los datos, manejar los valores faltantes , manejar valores atípicos, manejar conjuntos de datos desequilibrados, cómo manejar características categóricas y mucho más. Así que si quieres ahorra tu tiempo en el análisis de datos exploratorios, podemos usar bibliotecas de Python como dtale, perfil de pandas, sweetviz y autoviz para automatizar nuestras tareas.

Las bibliotecas automatizan el análisis de datos exploratorios
In questo blog, discutimos cuatro bibliotecas de Python importantes. Estos se enumeran a continuación:
- cuento
- perfil de pandas
- sweetviz
- autoviz
D-cuento
Es una biblioteca que se ha lanzado en febrero de 2020 que nos permite visualizar fácilmente el marco de datos de pandas. Tiene muchas características que son muy útiles para el análisis de datos exploratorios. Está hecho usando el backend del matraz y reacciona al frontend. Admite gráficos interactivos, Grafica 3D, mappe di calore, la correlación entre características, crea columnas personalizadas y muchos más. Es el más famoso y el favorito de todos.
Installazione
dtale se puede instalar usando el siguiente código:
pip install dtale
Análisis de datos exploratorios con D-tale
Profundicemos en el análisis de datos exploratorios utilizando esta biblioteca. Primo, tenemos que escribir un código para lanzar la aplicación interactiva d-tale localmente:
import dtale import pandas as pd df = pd.read_csv(‘data.csv’) d = dtale.show(df) d.open_browser()
Aquí estamos importando pandas y dtale. Estamos leyendo el conjunto de datos usando la función read_csv () y finalmente mostramos los datos en el navegador localmente usando la función mostrar y abrir el navegador.
Muestra los datos de la misma manera que lo hacen los pandas, pero tiene una característica adicional, tiene un menú en la esquina superior izquierda que nos permite hacer muchas cosas y muestra un recuento de columnas y filas en nuestro conjunto de datos.
L'output del codice sopra è mostrato di seguito:
Si hace clic en cualquier encabezado de columna, aparecerá el menú desplegable. Le brindará muchas opciones, como ordenar los datos, describir el conjunto de datos, análisis de columnas y muchas más. También puede comprobar esta función por su cuenta
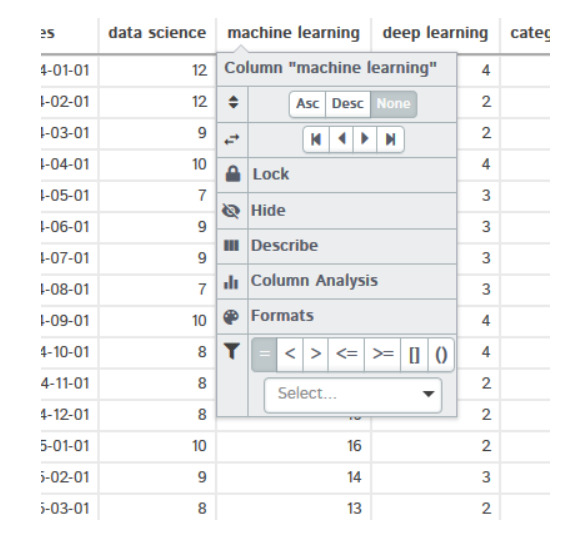
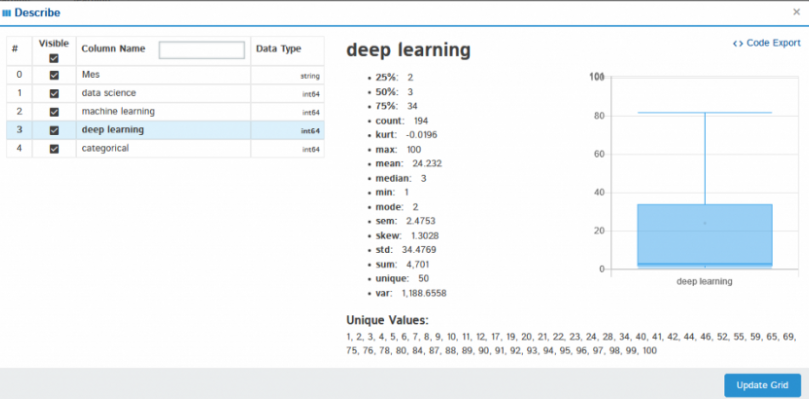
Si hace clic en Describir, muestra el análisis estadístico de la columna seleccionada como media, medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi...., massimo, mínima varianza, deviazione standard, cuartiles y muchos más.
Nello stesso modo, puede probar otras funciones por su cuenta, como análisis de columnas, formati, filtri.
Magic of dtale: haga clic en el botón de menú y encontrará todas las opciones disponibles
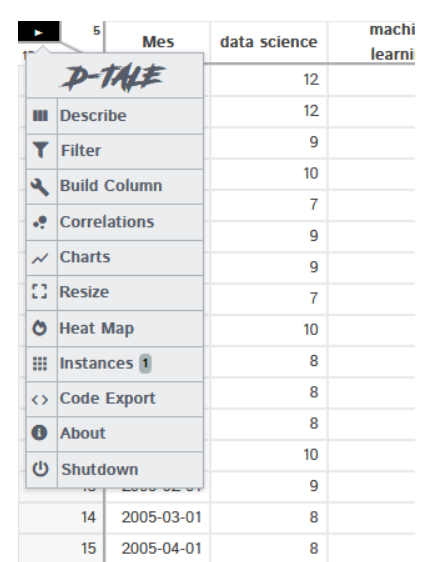
No es posible cubrir todas las características, pero estoy cubriendo la más interesante.
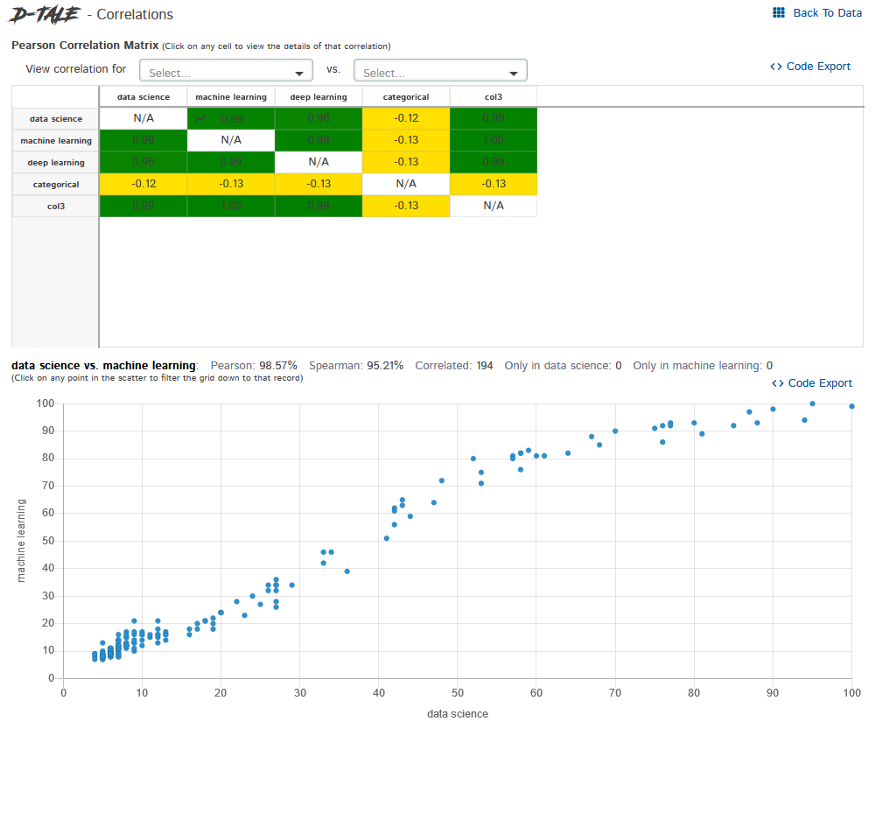
Correlaciones – Nos muestra cómo se correlacionan las columnas entre sí.
Grafica– Cree gráficos de aduanas como gráficos de líneas, grafici a barre, grafici a torta, gráficos apilados, diagrammi a dispersione, mapas geológicos, eccetera.
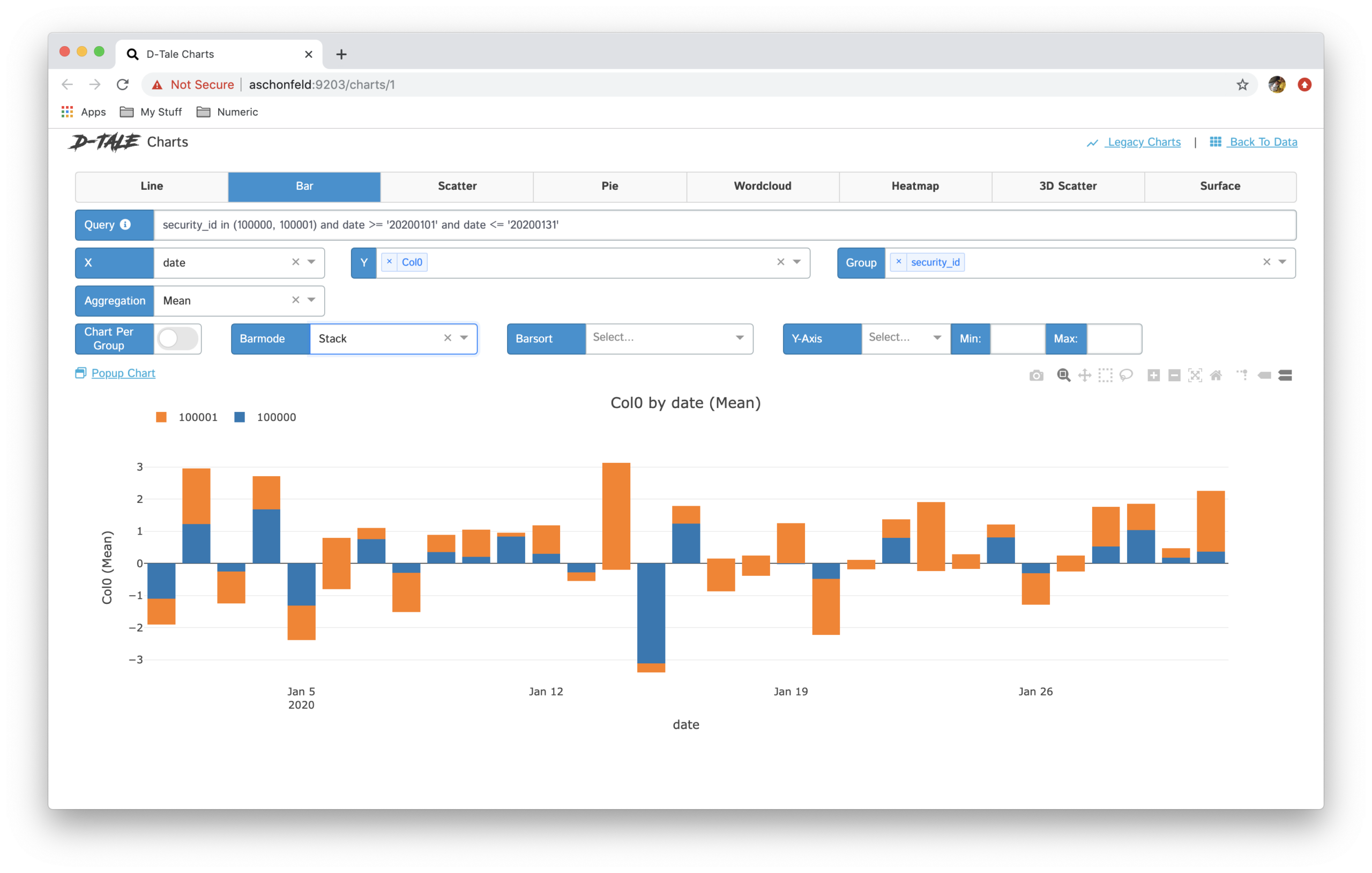
Hay muchos opcionales disponibles en esta biblioteca para el análisis de datos. Esta herramienta es muy útil y hace que el análisis de datos exploratorios sea mucho más rápido en comparación con el uso de bibliotecas tradicionales de aprendizaje automático como pandas, matplotlib, eccetera.
Para obtener documentación oficial, controlla questo link:
Perfilado de pandas

Es una biblioteca de código abierto escrita en Python y generó informes HTML interactivos y describe varios aspectos del conjunto de datos. Las funcionalidades clave incluyen el manejo de valores perdidos, estadísticas de conjuntos de datos como media, moda, mediano, asimetría, deviazione standard, eccetera., gráficos como istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline.... y correlaciones también.
Installazione
La creación de perfiles de pandas se puede instalar usando el siguiente código:
pip install pandas-profiling
Análisis de datos exploratorios mediante la creación de perfiles de Pandas
Profundicemos en el análisis de datos exploratorios utilizando esta biblioteca. Estoy usando un conjunto de datos de muestra para comenzar con la creación de perfiles de pandas, verifique el siguiente código:
#importing required packages import pandas as pd import pandas_profiling import numpy as np #importing the data df = pd.read_csv('sample.csv') #descriptive statistics pandas_profiling.ProfileReport(df)
A continuación se muestra la salida mágica del código anterior
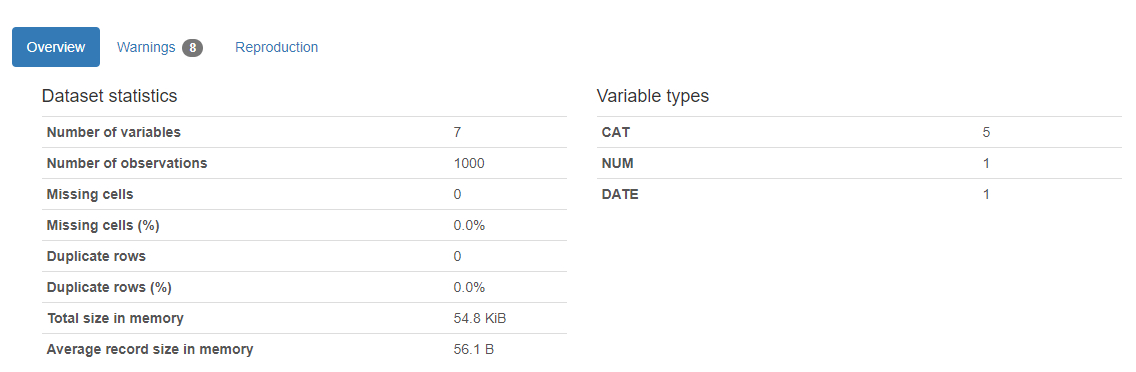
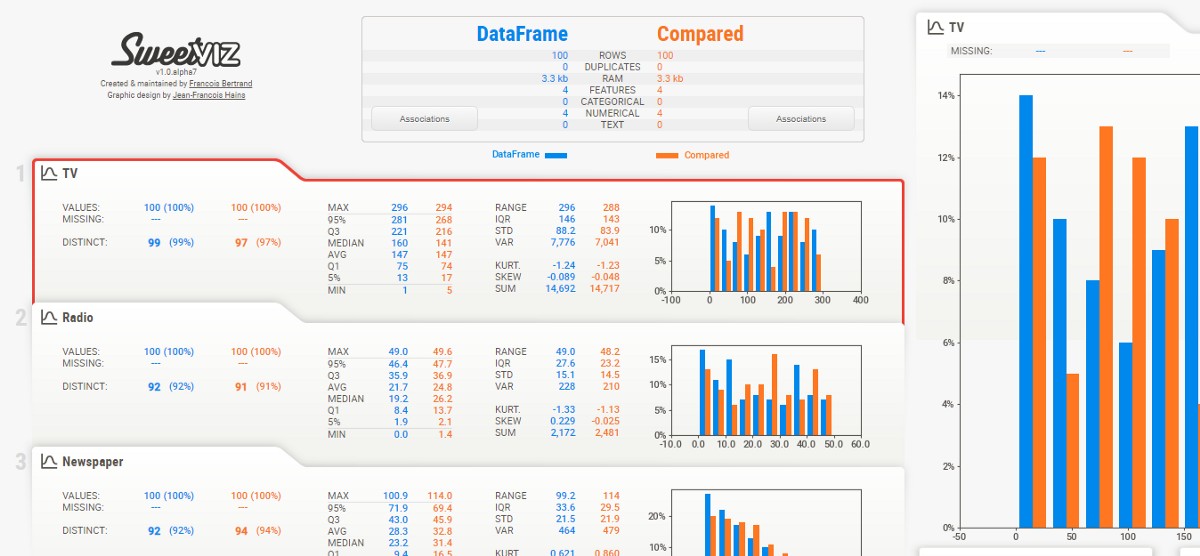
Aquí está el resultado. Aparecerá un informe y devolverá cuántas variables hay en nuestro conjunto de datos, el número de filas, las celdas que faltan en el conjunto de datos, el porcentaje de celdas que faltan, el número y el porcentaje de filas duplicadas. Los datos de celdas faltantes y duplicadas son muy importantes para nuestro análisis, ya que describen la imagen más amplia del conjunto de datos. El informe también muestra el tamaño total de la memoria. También muestra los tipos de variables en el lado derecho de la salida.
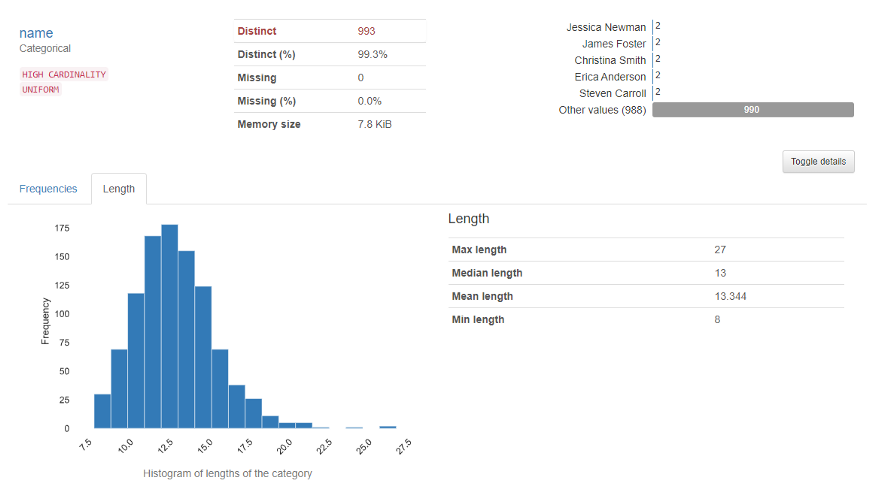
La sección de variables muestra el análisis de una columna en particular. Por ejemplo para el variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... Categorico, aparecerá la siguiente salida.
Per lui variable numérica, aparecerá la siguiente salida
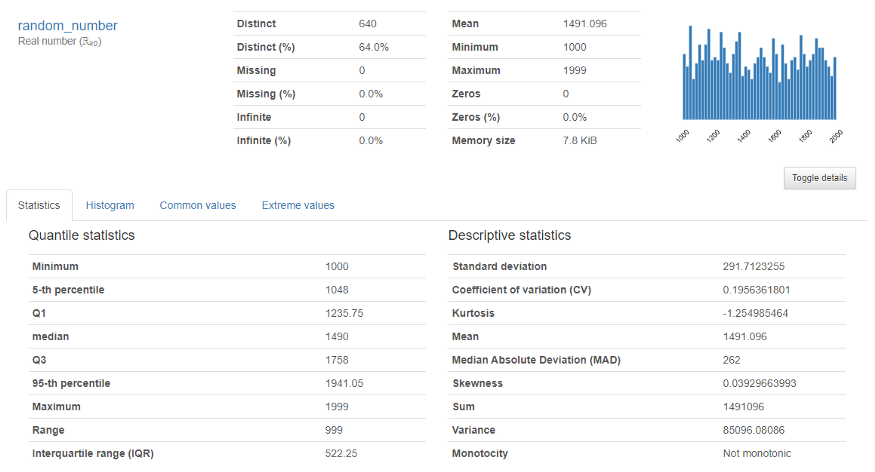
Proporciona un análisis en profundidad de variables numéricas como cuantil, media, suma mediana, varianza, monotonicidad, classifica, curtosis, rango intercuartílico y muchas más.
Correlaciones e interacción: Describe cómo se correlacionan las variables entre sí mediante. Estos datos son muy necesarios para los científicos de datos.
Per maggiori informazioni, consulta la documentazione ufficiale:
Sweetviz
Es una biblioteca de Python de código abierto que solía obtener visualizaciones, lo que es útil en el análisis de datos exploratorios con solo unas pocas líneas de códigos. La biblioteca se puede utilizar para visualizar las variables y comparar el conjunto de datos.
Installazione
Esta biblioteca se puede instalar usando el siguiente código:
pip install sweetviz
Análisis de datos exploratorios con SweetViz
Profundicemos en el análisis de datos exploratorios utilizando esta biblioteca. Estoy usando un conjunto de datos de muestra para comenzar, verifique el siguiente código
import sweetviz import pandas as pd df = pd.read_csv('sample.csv') my_report = sweetviz.analyze([df,'Treno'], target_feat="SalePrice") my_report.show_html('FinalReport.html')
Reporte final:
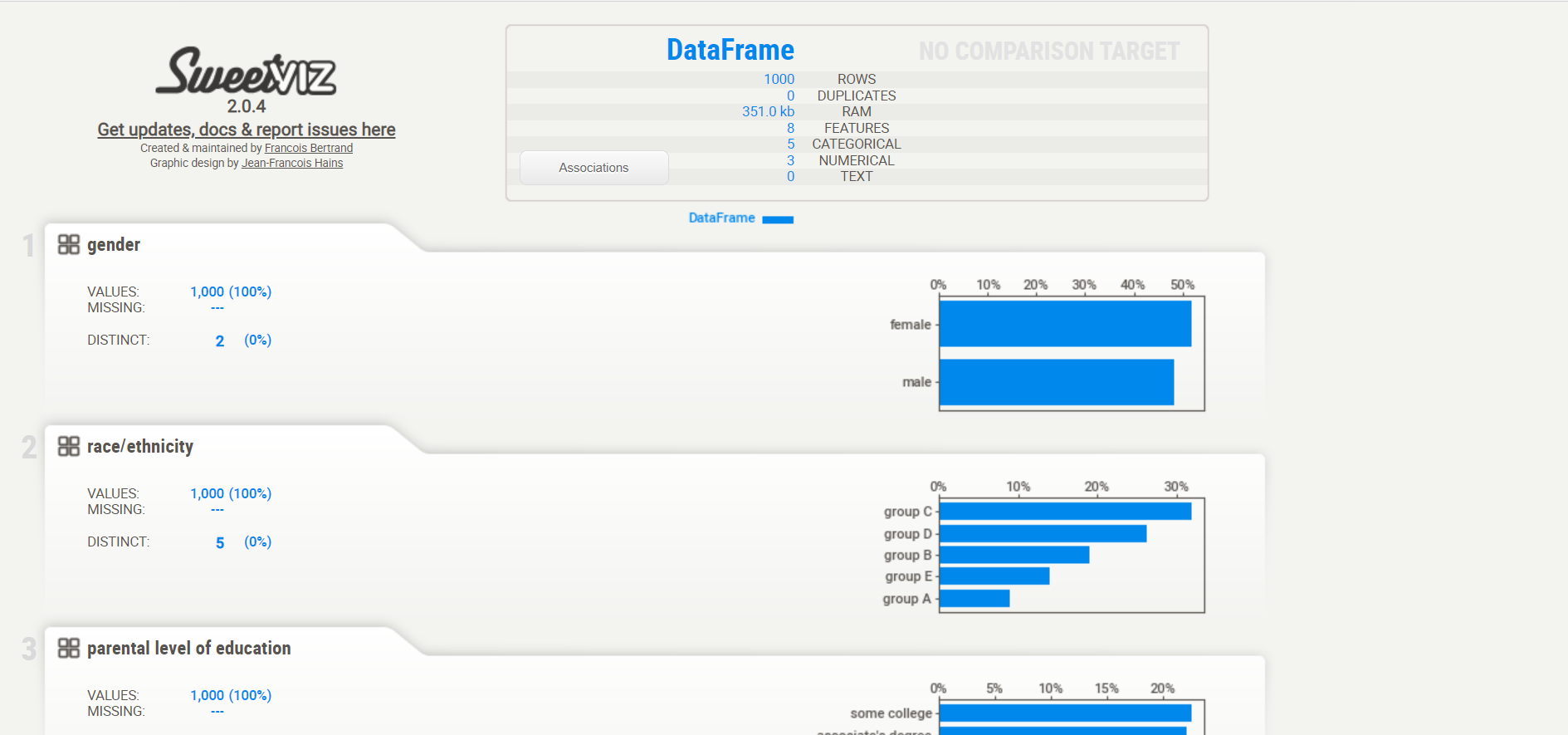
Per maggiori informazioni, consulta la documentazione ufficiale:
Autoviz
Significa Visualizar automáticamente. La visualización es posible con cualquier tamaño del conjunto de datos con unas pocas líneas de código.

Installazione
pip installare autoviz
Schermo
Código de muestra:
from autoviz.AutoViz_Class import AutoViz_Class AV = AutoViz_Class() df = AV.AutoViz('sample.csv')
Histograma de variable continua:
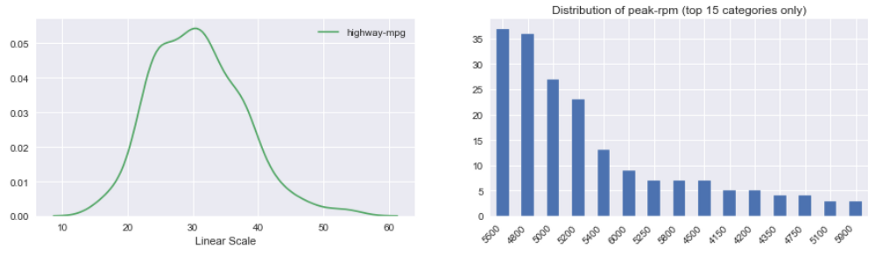
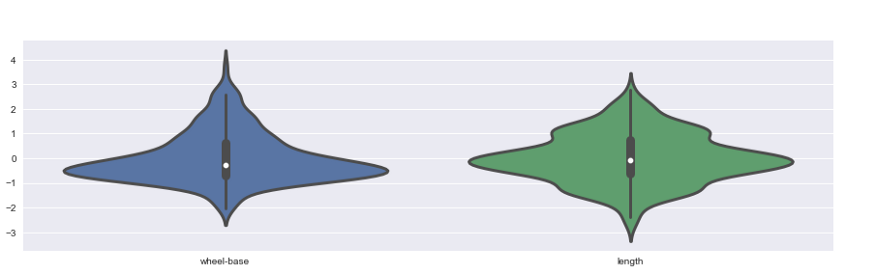
Cornici per violino:
Mappa di caloreun "mappa di calore" è una rappresentazione grafica che utilizza i colori per mostrare la densità dei dati in un'area specifica. Comunemente usato nell'analisi dei dati, Marketing e studi comportamentali, Questo tipo di visualizzazione consente di identificare rapidamente modelli e tendenze. Attraverso variazioni cromatiche, Le mappe di calore facilitano l'interpretazione di grandi volumi di informazioni, aiutando a prendere decisioni informate....:
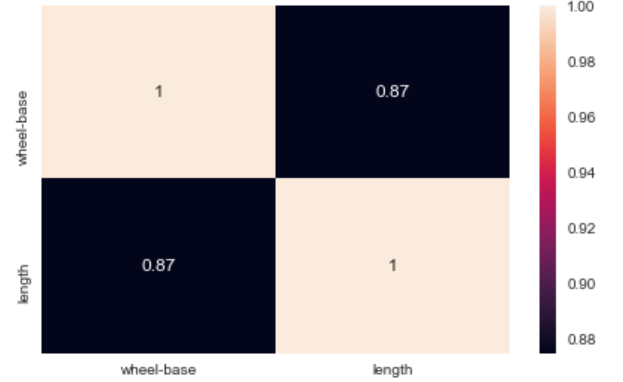
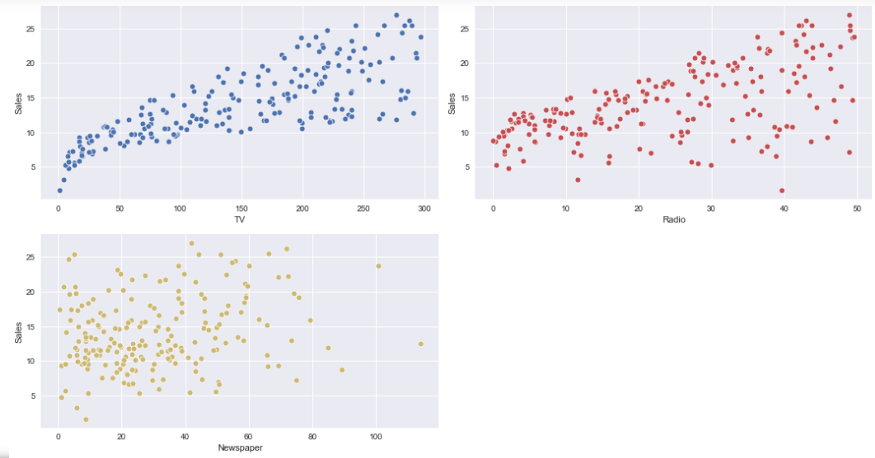
Grafico a dispersioneUn grafico a dispersione è una rappresentazione visiva che mostra la relazione tra due variabili numeriche utilizzando punti su un piano cartesiano. Ogni asse rappresenta una variabile, e la posizione di ciascun punto indica il suo valore in relazione ad entrambi. Questo tipo di grafico è utile per identificare i modelli, Correlazioni e tendenze nei dati, facilitare l'analisi e l'interpretazione delle relazioni quantitative....:
Per maggiori informazioni, consulta la documentazione ufficiale:
Grazie per aver letto questo. se ti piace questo articolo, Condividi con i tuoi amici. In caso di qualsiasi suggerimento / dubbio, commenta qui sotto.
Identificazione e-mail: [e-mail protetta]
Seguimi su LinkedIn: LinkedIn
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





