Introduzione:
Dati non strutturati in formato strutturato? È qui che entra in gioco il Web Scraping.
Cos'è il web scraping??
In linguaggio semplice, Raschiatura del nastro, Raccolta Web, oh Estrazione dati web è un processo automatizzato di raccolta di big data (non strutturato) di siti web. L'utente può estrarre tutti i dati su siti particolari o i dati specifici secondo il requisito. I dati raccolti possono essere memorizzati in un formato strutturato per ulteriori analisi.
Usi del web scraping:
Nel mondo reale, Il web scraping ha guadagnato molta attenzione e ha una vasta gamma di usi. Alcuni di loro sono elencati di seguito:
- Analisi del sentiment sui social media
- Generazione di lead nel settore del marketing
- Analisi di mercato, Confronto prezzi online nel dominio e-commerce
- Recopile datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y prueba en aplicaciones de aprendizaje automático
Passaggi coinvolti nel web scraping:
- Trova l'URL della pagina web che desideri raschiare
- Selezionare gli elementi particolari ispezionando
- Scrivi il codice per ottenere il contenuto degli elementi selezionati
- Memorizza i dati nel formato richiesto
Ecco quanto sono semplici i ragazzi .. !!
Biblioteche / Gli strumenti più diffusi utilizzati per il web scraping sono:
- Selenio: Un framework per il test delle applicazioni web
- bellazuppa: Libreria Python per ottenere dati da HTML, XML e altri linguaggi di markup
- panda: Libreria Python per la manipolazione e l'analisi dei dati
In questo articolo, creeremo il nostro set di dati estraendo le recensioni di Domino's Pizza dal sito web. consumeraffairs.com/food.
Noi useremo richieste e Bella zuppa di Raschiatura e analisi i dati.
passo 1: trova l'URL della pagina web che desideri raschiare
Apri l'URL “consumeraffairs.com/foodE cerca Domino's Pizza nella barra di ricerca e premi Invio.
Di seguito è riportato l'aspetto della nostra pagina delle recensioni.
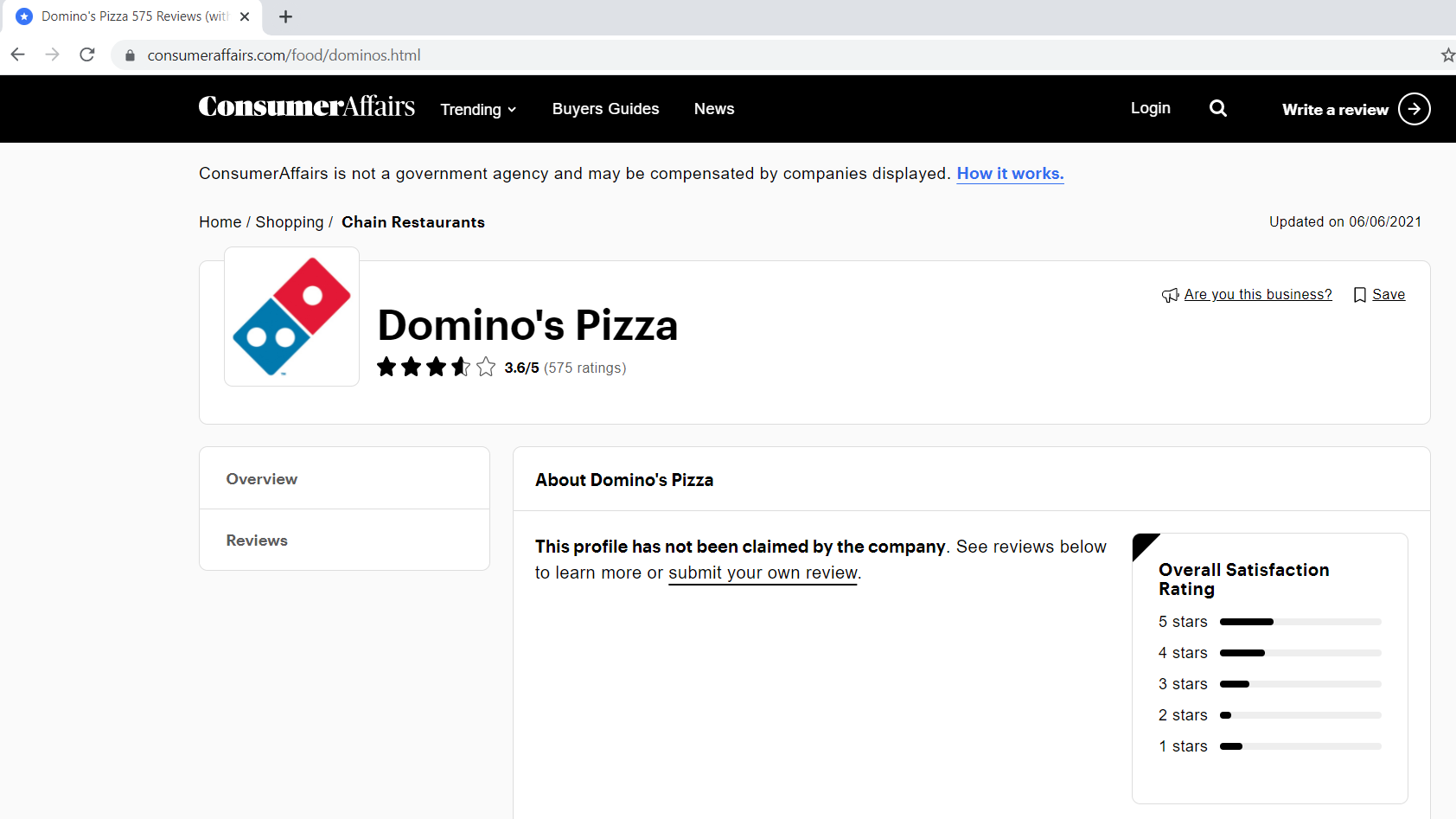
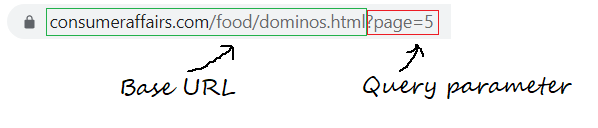
passo 1.1: Definizione dell'URL di base, parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... de consulta
L'URL di base è la parte coerente del tuo indirizzo web e rappresenta il percorso della funzione di ricerca del sito web.
base_url = "https://www.consumeraffairs.com/food/dominos.html?pagina="
I parametri di query rappresentano valori aggiuntivi che possono essere dichiarati nel campo.
query_parameter = "?pagina="+str(io) # i rappresenta il numero di pagina
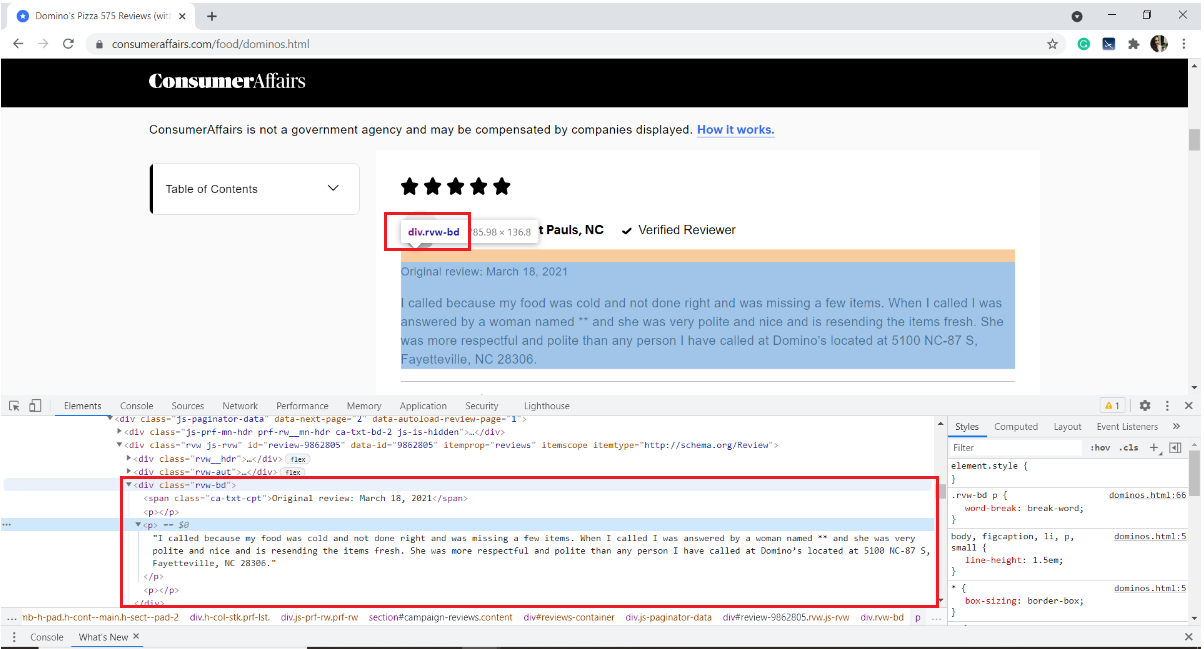
passo 2: Selezionare gli elementi particolari ispezionando
Di seguito è riportata un'immagine di un esempio di recensione. Ogni recensione ha molti elementi: la valutazione data dall'utente, il nome utente, la data della recensione e il testo della recensione insieme ad alcune informazioni su quante persone l'hanno apprezzata.

Il nostro interesse è quello di estrarre solo il testo della recensione. Per quello, dobbiamo ispezionare la pagina e ottenere i tag HTML, I nomi degli attributi dell'elemento di destinazione.
Per esaminare una pagina Web, Fare clic con il pulsante destro del mouse sulla pagina, selezionare Ispeziona o utilizzare la scorciatoia da tastiera Ctrl + Spostare + io.
Nel nostro caso, il testo di revisione viene memorizzato nel tag HTML
del div con il nome della classe "RVW-BD“
Con questo, Facciamo conoscenza con il sito web. Passiamo rapidamente allo scraping.
passo 3: Scrivi il codice per ottenere il contenuto degli elementi selezionati
Inizia installando i moduli / Pacchetti necessari
pip install pandas richiede BeautifulSoup4
Importa le librerie richieste
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
panda – Per creare un frame di dati
Richieste: per inviare richieste HTTP e accedere al contenuto HTML dalla pagina web di destinazione
bellazuppa: è una libreria Python per l'analisi di dati HTML strutturati
Crea un elenco vuoto per archiviare tutte le recensioni estratte
all_pages_reviews = []
Definire una funzione raschiatore
Difendi Raschietto():
All'interno della funzione raschietto, Scrivi un in modo che il ciclo attraversi il numero di pagine che desideri raschiare. Vorrei raschiare via le recensioni di cinque pagine.
per io nel raggio d'azione(1,6):
Creando una lista vacía para almacenar las reseñas de cada página (a partire dal 1 un 5)
pagewise_reviews = []
Construye la URL
url = base_url + query_parameter
Envíe la solicitud HTTP a la URL mediante solicitudes y almacene la respuesta
risposta = request.get(URL)
Cree un objeto de sopa y analice la página HTML
soup = bs(response.content, 'html.parser')
Encuentre todos los elementos div del nombre de clase “rvw-bd” y guárdelos en una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi....
rev_div = soup.findAll("Div",attrs={"classe","rvw-bd"})
Recorra todo el rev_div y agregue el texto de revisión a la lista pagewise
per j nell'intervallo(len(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[J].trova("P").testo)
Anexar todas las reseñas de páginas a una sola lista “all_pages about”
per k nell'intervallo(len(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[K])
Al final de la función, devuelve la lista final de reseñas.
return all_pages_reviews
Call the function scraper() and store the output to a variable 'reviews'
# Driver code
reviews = scraper()
passo 4: almacene los datos en el formato requerido
4.1 almacenamiento en un marco de datos de pandas
i = range(1, len(recensioni)+1) reviews_df = pd.DataFrame({'review':recensioni}, index=i)
Now let us take a glance of our dataset
Stampa(reviews_df)

4.2 Escribir el contenido del marco de datos en un archivo de texto
reviews_df.to_csv('reviews.txt', sep='t')
Con questo, terminamos de extraer las reseñas y almacenarlas en un archivo de texto. Mmm, es bastante simple, no?
Código Python completo:
# !pip install pandas requests BeautifulSoup4
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
base_url = "https://www.consumeraffairs.com/food/dominos.html"
all_pages_reviews =[]
-
Difendi Raschietto(): per io nel raggio d'azione(1,6): # fetching reviews from five pages pagewise_reviews = [] query_parameter = "?pagina="+str(io) url = base_url + query_parameter response = requests.get(URL) soup = bs(response.content, 'html.parser') rev_div = soup.findAll("Div",attrs={"classe","rvw-bd"}) per j nell'intervallo(len(rev_div)): # finding all the p tags to fetch only the review text pagewise_reviews.append(rev_div[J].trova("P").testo) per k nell'intervallo(len(pagewise_reviews)): all_pages_reviews.append(pagewise_reviews[K]) return all_pages_reviews # Driver code reviews = scraper() i = range(1, len(recensioni)+1) reviews_df = pd.DataFrame({'review':recensioni}, index=i) reviews_df.to_csv('reviews.txt', sep='t')
Note finali:
Alla fine di questo articolo, Abbiamo appreso il processo passo dopo passo per estrarre contenuti da qualsiasi pagina web e archiviarli in un file di testo.
- Ispezionare l'elemento di destinazione utilizzando gli strumenti di sviluppo del browser
- utilizzare le richieste per scaricare il contenuto HTML
- analizzare il contenuto HTML utilizzando BeautifulSoup per estrarre i dati richiesti
Possiamo sviluppare ulteriormente questo esempio raschiando i nomi utente, Correzione di bozze di testo. Esegui la vettorializzazione su un testo di revisione pulito e raggruppa gli utenti in base alle revisioni scritte. Podemos usar Word2Vec o CounterVectorizer para convertir texto en vectores y aplicar cualquiera de los algoritmos de raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. de Machine Learning.
Riferimenti:
Biblioteca BeautifulSoup: Documentazione, Esercitazione video
Collegamento al repository GitHub per scaricare il codice sorgente
Spero che questo blog ti aiuti a capire il web scraping in Python utilizzando la libreria BeautifulSoup. Buon apprendimento !! ?
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





