Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
I Big Data sono spesso caratterizzati da: –
un) Volume: – Volume significa un'enorme ed enorme quantità di dati che devono essere elaborati.
B) Velocità: – La velocità con cui i dati arrivano come elaborazione in tempo reale.
C) veridicità: – Veridicità significa qualità dei dati (che in realtà deve essere ottimo per generare report di analisi, eccetera.)
D) Varietà: – Significa i diversi tipi di dati come
* Dati strutturati: – Dati in formato tabella.
* Dati non strutturati: – Dati non in formato tabella
* Dati semistrutturati: – Combinazione di dati strutturati e non strutturati.
Per lavorare con grandi byte di dati, Per prima cosa dobbiamo archiviare o scaricare i dati da qualche parte. Perciò, La soluzione a questo è HDFSHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni.. (sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestione di grandi volumi di informazioni. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Cosa c'è di più, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... Hadoop).
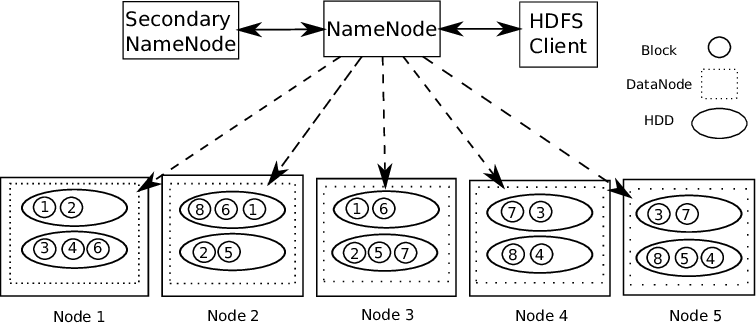
Supporto Hadoop Architettura master-slave. È un tipo di sistema distribuito in cui viene eseguita l'elaborazione parallela dei dati. Hadoop è costituito da 1 Padrone e diversi schiavi.
NodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... de regla de nombre: – Per ogni blocco di dati memorizzato, ci sono 2 Copie presenti. Uno su diversi nodi di dati e una seconda copia su un altro nodo di dati. così, Risolve il problema della tolleranza ai guasti.
Il nodo del nome contiene le seguenti informazioni: –
1) Informazioni sui metadati per i file archiviati nei nodi di dati. I metadati sono costituiti da 2 record: FsImage e EditLogs. FsImage è costituito dallo stato completo del file system dall'inizio del nodo Name. Gli editlog contengono le modifiche recenti apportate al file system.
2) Posizione del blocco di file memorizzato nel nodo dati.
3) Dimensioni dei file.
Il nodo dati contiene i dati effettivi.
Perciò, Supporti HDFS l'integrità dei dati. I dati memorizzati vengono verificati se sono corretti o meno confrontando i dati con il loro checksum. Se vengono rilevati guasti, Il nodo del nome è informato. Perciò, Crea copie aggiuntive degli stessi dati ed elimina le copie danneggiate.
HDFS è costituito da Nodo del nome secondario che funziona contemporaneamente al nodo principale del nome come demone ausiliario. Non è un nodo del nome di backup. Legge costantemente tutti i file system e i metadati della RAM dal nodo del nome al disco rigido. È responsabile della combinazione di EditLogs con FSImage di Name Node.
Perciò, HDFS è come un archivio dati in cui possiamo scaricare qualsiasi tipo di dati. El procesamiento de estos datos requiere herramientas de Hadoop como AlveareHive è una piattaforma di social media decentralizzata che consente ai suoi utenti di condividere contenuti e connettersi con gli altri senza l'intervento di un'autorità centrale. Utilizza la tecnologia blockchain per garantire la sicurezza e la proprietà dei dati. A differenza di altri social network, Hive consente agli utenti di monetizzare i propri contenuti attraverso ricompense in criptovalute, che incoraggia la creazione e lo scambio attivo di informazioni.... (per la gestione dei dati strutturati), HBaseHBase è un database NoSQL progettato per gestire grandi volumi di dati distribuiti in cluster. In base al modello a colonne, Consente un accesso rapido e scalabile alle informazioni. HBase si integra facilmente con Hadoop, il che lo rende una scelta popolare per le applicazioni che richiedono un'elevata quantità di archiviazione ed elaborazione dei dati. La sua flessibilità e capacità di crescita lo rendono ideale per i progetti di big data.... (per la gestione di dati non strutturati), eccetera. Hadoop supporta il concetto “Scrivi una volta, Pronto per molti”.
Quindi, Facciamo un esempio e capiamo come possiamo elaborare un'enorme quantità di dati ed eseguire molte trasformazioni utilizzando Scala Language.
UN) Configurazione dell'IDE di Eclipse con le impostazioni di Scala.
Link per scaricare l'IDE eclipse – https://www.eclipse.org/downloads/
È necessario scaricare l'IDE Eclipse tenendo presente i requisiti del computer. Quando si avvia l'IDE eclipse, Vedrai questo tipo di schermo.

Vai a Aiuto -> Eclipse Marketplace -> Cercare -> Scala-ide -> Installa su PC
Dopodiché nell'IDE di Eclipse – Selezionare Prospettiva aperta -> Scala, Otterrai tutti i componenti SCALA nell'IDE da utilizzare.
Crea un nuovo progetto in eclipse e aggiorna il file pom con i seguenti passaggi:https://medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883
Modificare la versione della libreria scala facendo clic con il pulsante destro del mouse su Progetto -> Costruisci una strada -> Configurare il percorso di compilazione.
Aggiorna il progetto facendo clic con il pulsante destro del mouse su Progetto -> Intenditore -> Aggiorna progetto Maven -> Forza l'aggiornamento dello snapshot / versioni. Perciò, Il file POM viene salvato e tutte le dipendenze richieste vengono scaricate per il progetto.
Successivamente, scarica la versione Spark con Hadoop winutils posizionato nel percorso bin. Segui questo percorso per completare la configurazione: https://stackoverflow.com/questions/25481325/how-to-set-up-spark-on-windows
B) Creazione di sessioni Spark – 2 tipi.
Spark Session è il punto di ingresso o l'inizio per creare RDD, Frame di dati, Dataset. Per creare un'app Spark, primero necesitamos una sessioneIl "Sessione" È un concetto chiave nel campo della psicologia e della terapia. Si riferisce a un incontro programmato tra un terapeuta e un cliente, dove si esplorano i pensieri, Emozioni e comportamenti. Queste sessioni possono variare in durata e frequenza, e il suo scopo principale è quello di facilitare la crescita personale e la risoluzione dei problemi. L'efficacia delle sessioni dipende dalla relazione tra il terapeuta e il terapeuta.. de chispa.
Spark Session può essere 2 tipi: –
un) Sessione Spark normale: –
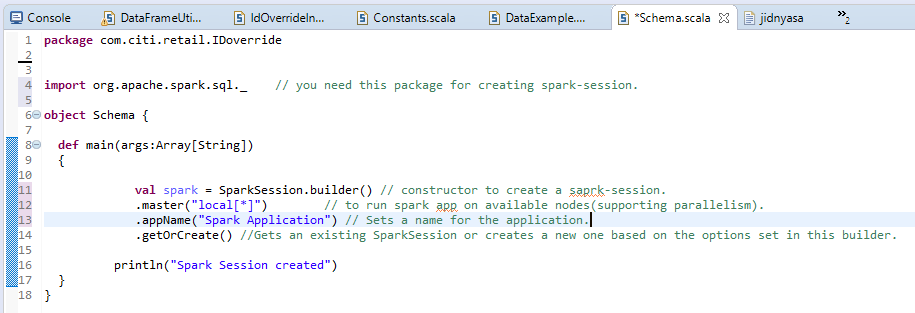
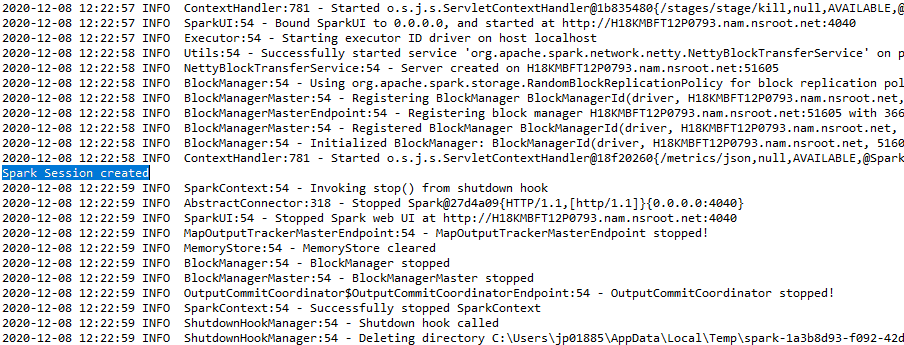
L'output verrà visualizzato come: –
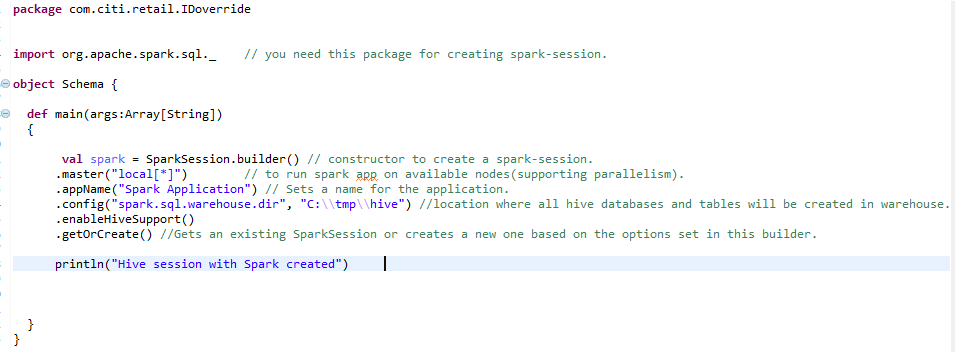
B) Sessione Spark per l'ambiente Hive: –
Per creare un ambiente hive su larga scala, Abbiamo bisogno della stessa sessione di scintilla con una linea aggiuntiva aggiunta. enableHiveSupport () – abilitare il supporto Hive, inclusa la connettività al metastore Hive persistente, supporto per le funzioni Hive serdes e Hive definite dall'utente.
C) Creación de RDD (Dataset distribuito resiliente)RDD (Dataset distribuito resiliente) è un'astrazione fondamentale in Apache Spark che consente l'elaborazione efficiente di grandi volumi di dati. Si caratterizza per la sua capacità di essere tollerante ai guasti, Abilitazione del recupero dei dati persi mediante la ricostruzione delle partizioni. Gli RDD non sono modificabili, Facilitare la parallelizzazione delle operazioni e migliorare le prestazioni nel calcolo distribuito. Il suo utilizzo è essenziale per l'analisi dei dati.. e trasformazione di RDD in DataFrame: –
Quindi, dopo il primo passaggio della creazione di Spark-Session, siamo liberi di creare RDD, Set di dati o frame di dati. Queste sono le strutture dati in cui possiamo archiviare grandi quantità di dati..
Elastico:- significa tolleranza ai guasti in modo che possano ricalcolare le partizioni mancanti o danneggiate a causa di errori dei nodi.
Partizionato:- significa che i dati sono distribuiti su più nodi (Potere del parallelismo).
Set di dati: – Dati che possono essere caricati esternamente e che possono essere in qualsiasi forma, vale a dire, JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software.., CSV o file di testo.
Le caratteristiche degli RDD includono: –
un) Calcolo in memoria: – Dopo aver eseguito trasformazioni sui dati, i risultati vengono memorizzati nella RAM anziché su un disco. Perciò, RDD non può utilizzare set di dati di grandi dimensioni. La soluzione a questo è, invece di usare RDD, l'uso di DataFrame è considerato / Datasetun "set di dati" o dataset è una raccolta strutturata di informazioni, che può essere utilizzato per l'analisi statistica, Apprendimento automatico o ricerca. I set di dati possono includere variabili numeriche, categorico o testuale, e la loro qualità è fondamentale per ottenere risultati affidabili. Il suo utilizzo si estende a varie discipline, come la medicina, Economia e scienze sociali, facilitare il processo decisionale informato e lo sviluppo di modelli predittivi.....
B) Valutazioni pigre: – Significa che le azioni delle trasformazioni eseguite vengono valutate solo quando il valore è necessario.
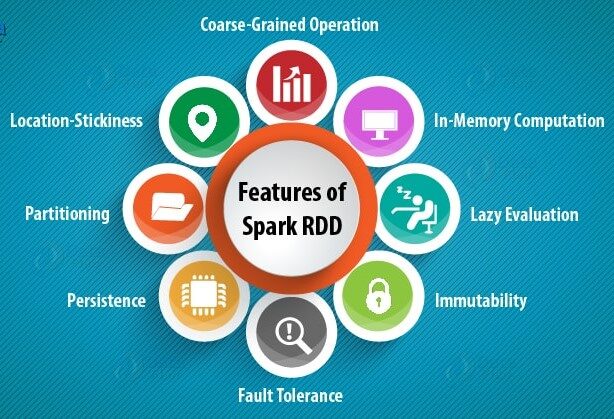
C) Tolleranza ai guasti: – Gli RDD Spark sono tolleranti ai guasti in quanto tengono traccia delle informazioni di derivazione dei dati per ricostruire automaticamente i dati persi in caso di guasto.
D) Immutabilità: – Dati immutabili (non modificabile) Sono sempre sicuri da condividere su più processi. Possiamo ricreare l'RDD in qualsiasi momento.
me) Frazionamento: – Significa dividere i dati, Quindi ogni partizione può essere eseguita da nodi diversi, In questo modo l'elaborazione dei dati diventa più veloce.
F) Persistenza:- Gli utenti possono scegliere quali RDD devono utilizzare e scegliere una strategia di archiviazione per loro.
grammo) Operazioni a grana grossa: – Significa che quando i dati vengono suddivisi in cluster diversi per operazioni diverse, podemos aplicar transformaciones una vez para todo el grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... y no para diferentes particiones por separado.
D) Utilizzo del framework di dati ed esecuzione di trasformazioni: –
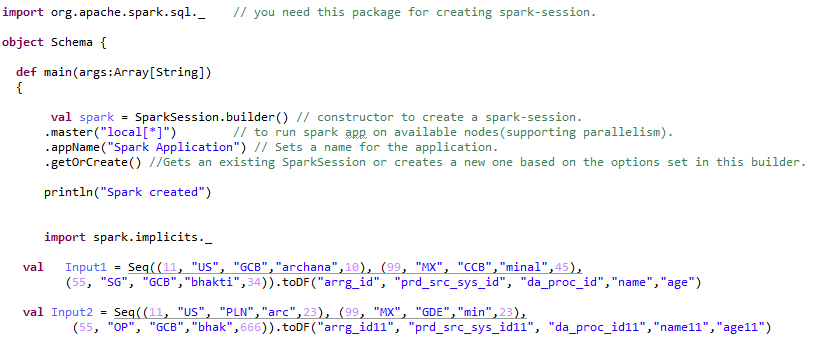
Durante la conversione di RDD in frame di dati, deve aggiungere Importazione spark.implicits._ Dopo la scintilla sessione.
Il framework di dati può essere creato in molti modi. Diamo un'occhiata alle diverse trasformazioni che possono essere applicate al frame di dati.
passo 1:- Creazione di un framework di dati: –
passo 2:- Esecuzione di diversi tipi di trasformazioni in un frame di dati: –
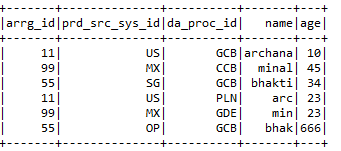
un) Si prega di selezionare:- Seleziona le colonne obbligatorie del frame di dati richieste dall'utente.
Input1.select (“arrg_id”, “da_proc_id”). Spettacolo ()

B) selectExpr: – Selezionare le colonne richieste e rinominare le colonne.
Input2.selectExpr (“arrg_id11”, “prd_src_sys_id11 come prd_src_new”, “da_proc_id11”). Spettacolo ()

C) con Colonna: – withColumns ayuda a agregar una nueva columna con el valor particular que el usuario desea en el marco de datos seleccionado.
Input1.withColumn (“New_col”, illuminato (nullo))

D) withColumnRenamed: – Cambia el nombre de las columnas del marco de datos particular que requiere el usuario.
Input1.withColumnRenamed (“da_proc_id”, “da_proc_id_newname”)

me) far cadere:- Elimina las columnas que el usuario no quiere.
Input2.drop (“arrg_id11 ″,” prd_src_sys_id11 ″, “da_proc_id11”)
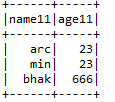
F) Per entrare:- Une 2 marcos de datos junto con claves de unión de ambos marcos de datos.
Input1.join (Input2, Input1.col (“arrg_id”) === Input2.col (“arrg_id11 ″),” Giusto “)
.conColonna (“prd_src_sys_id”, illuminato (nullo))
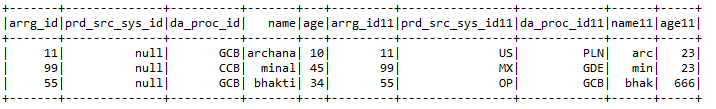
grammo) Funciones agregadas:- Algunas de las funciones agregadas incluyen
* Raccontare:- Da el recuento de una columna en particular o el recuento del marco de datos como un todo.
println (Input1.count ())
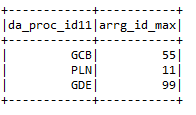
* Máx .: – Da el valor máximo de la columna según una condición particular.
input2.groupBy (“da_proc_id”). max (“arrg_id”). withColumnRenamed (“max (arrg_id)”,
“Arrg_id_max”)
* Min: – Da un valor mínimo de la columna del marco de datos.

h) filtro: – Filtra las columnas de un marco de datos ejecutando una condición particular.

io) printSchema: – Proporciona detalles como nombres de columna, tipos de datos de columnas y si las columnas pueden ser anulables o no.
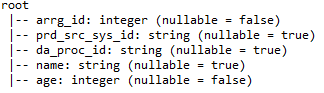
J) Unione: – Combina los valores de 2 marcos de datos siempre que los nombres de columna de ambos marcos de datos sean iguales.
ME) Alveare:-
Hive es una de las bases de datos más utilizadas en Big Data. Es una especie de Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... relacional donde los datos se almacenan en formato tabular. La base de datos predeterminada de la colmena es la Derby. Procesos de colmena estructurado y semiestructurado dati. En caso de datos no estructurados, primero cree una tabla en la colmena y cargue los datos en la tabla, así estructurada. Hive admite todos los tipos de datos primitivos de SQL.
Hive admite 2 tipos de tablas: –
un) Tavoli gestiti: – Es la tabla predeterminada en Hive. Cuando el usuario crea una tabla en Hive sin especificarla como externa, per impostazione predefinita, se crea una tabla interna en una ubicación específica en HDFS.
Per impostazione predefinita, se creará una tabla interna en una ruta de carpeta similar a / Nome utente / alveare / scorta directorio de HDFS. Podemos anular la ubicación predeterminada por la propiedad de ubicación durante la creación de la tabla.
Si descartamos la tabla o partición administrada, los datos de la tabla y los metadatos asociados con esa tabla se eliminarán del HDFS.
B) Mesa externa: – Las tablas externas se almacenan fuera del directorio del almacén. Pueden acceder a los datos almacenados en fuentes como ubicaciones HDFS remotas o volúmenes de almacenamiento de Azure.
Siempre que dejamos caer la tabla externa, solo se eliminarán los metadatos asociados con la tabla, los datos de la tabla permanecen intactos por Hive.
Podemos crear la tabla externa especificando el EXTERNO palabra clave en la instrucción de tabla de creación de Hive.
Comando para crear una tabla externa.
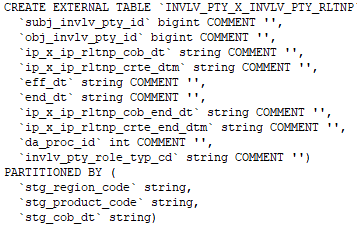
Comando para comprobar si la tabla creada es externa o no: –
desc con formato