La sfida di far capire alle macchine il testo
“La lingua è un meraviglioso mezzo di comunicazione”
Io e te avremmo capito quella frase in una frazione di secondo. Ma le macchine non possono elaborare i dati di testo in forma grezza. Hanno bisogno di noi per scomporre il testo in un formato numerico che la macchina possa facilmente leggere (l'idea dietro Elaborazione del linguaggio naturale!).
È qui che entrano in gioco i concetti di Bag-of-Words. (Arco) y TF-IDF. Sia BoW che TF-IDF sono tecniche che ci aiutano a convertire frasi di testo in vettori numerici.
Parlerò di Bag-of-Words e TF-IDF in questo articolo. Useremo un esempio intuitivo e generale per comprendere ogni concetto in dettaglio.
Novità nell'elaborazione del linguaggio naturale (PNL)? Abbiamo i corsi perfetti per iniziare:
Facciamo un esempio per capire il sacco delle parole (Arco) y TF-IDF
Prenderò un esempio popolare per spiegare Bag-of-Words (Arco) e TF-DF in questo articolo.
Tutti noi amiamo guardare i film (a vari gradi). Guardo sempre le recensioni di un film prima di impegnarmi a vederlo.. So che molti di voi fanno lo stesso! Quindi, userò questo esempio qui.

Ecco un esempio di recensioni su un particolare film horror:
- Revisione 1: questo film è molto spaventoso e lungo
- Revisione 2: questo film non fa paura ed è lento
- Revisione 3: questo film è inquietante e bello
Puoi vedere che ci sono alcune recensioni contrastanti sul film, così come la lunghezza e il ritmo del film. Immagina di guardare migliaia di recensioni come queste. Chiaramente, ci sono molti spunti interessanti che possiamo estrarre e sviluppare per valutare come il film si è comportato bene.
tuttavia, come abbiamo visto in precedenza, non possiamo semplicemente dare queste frasi a un modello di apprendimento automatico e chiedergli di dirci se una recensione è stata positiva o negativa. Dobbiamo eseguire alcuni passaggi di pre-elaborazione del testo.
Bag-of-Words e TF-IDF sono due esempi di come farlo. Capiamo in dettaglio.
Crea vettori da testo
Riesci a pensare ad alcune tecniche che potremmo usare per vettorizzare una frase all'inizio?? I requisiti di base sarebbero:
- Non dovrebbe risultare in una matrice sparsa poiché le matrici sparse comportano un costo computazionale elevato
- Dovremmo essere in grado di conservare la maggior parte delle informazioni linguistiche presenti nella frase.
L'incorporamento di parole è una di quelle tecniche in cui possiamo rappresentare il testo usando i vettori. Le forme più popolari di intarsi di parole sono:
- Arco, cosa significa borsa di parole?
- TF-IDF, Cosa significa Termine Frequenza-Frequenza Documento Inverso
Ora, vediamo come possiamo rendere le recensioni di film precedenti come intarsi e prepararle per un modello di apprendimento automatico.
Modello di borsa di parole (Arco)
El modelo Bag of Words (Arco) è il modo più semplice per rappresentare il testo in numeri. Come il termine stesso, possiamo rappresentare una frase come un vettore di parole (una stringa di numeri).
Ricorda i tre tipi di recensioni di film che abbiamo visto prima:
- Revisione 1: questo film è molto spaventoso e lungo
- Revisione 2: questo film non fa paura ed è lento
- Revisione 3: questo film è inquietante e bello
Prima costruiremo un vocabolario da tutte le parole uniche nelle tre revisioni precedenti. Il vocabolario è composto da questi 11 parole: 'Questo', 'film', 'è', 'molto', 'allarmante', 'e', 'lungo', 'no', 'Lento', 'Strisciante', 'bene '.
Ora possiamo prendere ciascuna di queste parole e contrassegnare la loro apparizione nelle tre precedenti recensioni di film con 1 e 0. Questo ci darà 3 vettori per 3 recensioni:
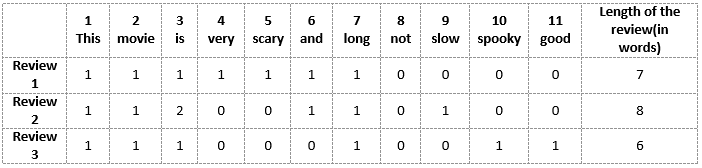
Recensione vettoriale 1: [1 1 1 1 1 1 1 0 0 0 0]
Recensione vettoriale 2: [1 1 2 0 0 1 1 0 1 0 0]
Recensione vettoriale 3: [1 1 1 0 0 0 1 0 0 1 1]
E questa è l'idea centrale dietro il modello Bag of Words. (Arco).
Svantaggi dell'utilizzo di un modello di borsa di parole (Arco)
Nell'esempio sopra, possiamo avere vettori di lunghezza 11. tuttavia, iniziamo ad affrontare problemi quando troviamo nuove frasi:
- Se le nuove frasi contengono nuove parole, allora la dimensione del nostro vocabolario aumenterebbe e, così, anche la lunghezza dei vettori aumenterebbe.
- Cosa c'è di più, i vettori conterrebbero anche molti zeri, che risulterebbe in una matrice sparsa (cosa vorremmo evitare)
- Non conserviamo informazioni sulla grammatica delle frasi o sull'ordine delle parole nel testo.
Termine Frequenza-Frequenza inversa dei documenti (TF-IDF)
Mettiamo prima una definizione formale intorno a TF-IDF. È così che la mette Wikipedia:
“La frequenza dei termini, la frequenza inversa dei documenti, è una statistica numerica che cerca di riflettere l'importanza di una parola per un documento in una raccolta o corpus”.
Frequenza del termine (TF)
Per prima cosa comprendiamo il termine frequente (TF). Si tratta di un misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... de la frecuencia con la que aparece un término, T, in un documento, D:
![]()
Qui, al numeratore, n è il numero di volte in cui il termine appare “T” nel documento “D”. Perciò, ogni documento e termine avrebbe il proprio valore TF.
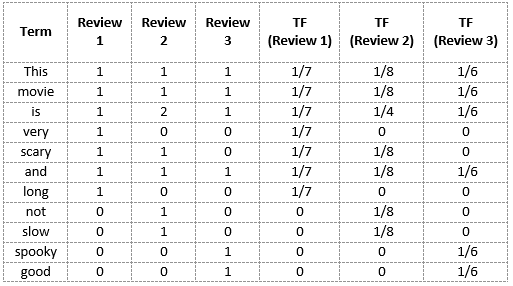
Ancora una volta utilizzeremo lo stesso vocabolario che avevamo costruito nel modello Bag-of-Words per mostrare come calcolare il TF per la revisione # 2:
Revisione 2: questo film non fa paura ed è lento
Qui,
- Vocabolario: 'Questo', 'film', 'è', 'molto', 'Terrificante', 'e', 'Lungo', 'no', 'Lento', 'Strisciante', 'Buona’
- Numero di parole nella recensione 2 = 8
- TF per la parola "questo"’ = (numero di volte che appare’ in revisione 2) / (numero di termini nella recensione 2) = 1/8
Simile,
- TF ('film') = 1/8
- TF ('è') = 2/8 = 1/4
- TF ('molto') = 0/8 = 0
- TF ('allarmante') = 1/8
- TF ('e') = 1/8
- TF ('lungo') = 0/8 = 0
- TF ('no') = 1/8
- TF ('Lento') = 1/8
- TF ('Strisciante') = 0/8 = 0
- TF ('bene') = 0/8 = 0
Possiamo calcolare le frequenze dei termini per tutti i termini e tutte le revisioni in questo modo:
Inverti la frequenza del documento (IDF)
IDF è una misura dell'importanza di un termine. Abbiamo bisogno del valore IDF perché calcolare il TF da solo non è sufficiente per capire l'importanza delle parole:
![]()
Possiamo calcolare i valori IDF per tutte le parole nella Review 2:
IDF ('questo') = log (numero di documenti / numero di documenti contenenti la parola "questo") = log (3/3) = log (1) = 0
Simile,
- IDF ('film',) = log (3/3) = 0
- IDF ('è') = log (3/3) = 0
- IDF ('no') = log (3/1) = log (3) = 0.48
- IDF ('allarmante') = log (3/2) = 0.18
- IDF ('e') = log (3/3) = 0
- IDF ('Lento') = log (3/1) = 0.48
Possiamo calcolare i valori IDF per ogni parola in questo modo. Perciò, i valori IDF per l'intero vocabolario sarebbero:
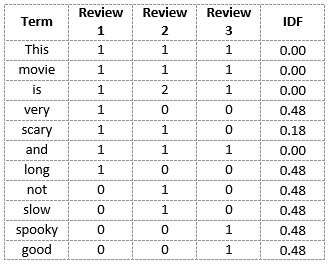
Perciò, vediamo che parole come "es", "questo", "e", eccetera., si riducono a 0 e hanno poca importanza; mentre parole come "spaventoso", "lungo", "bene", eccetera. sono parole con più importanza e quindi hanno maggior valore.
Ora possiamo calcolare il punteggio TF-IDF per ogni parola nel corpus. Le parole con un punteggio più alto sono più importanti e quelle con un punteggio più basso sono meno importanti:
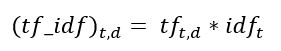
Ora possiamo calcolare il punteggio TF-IDF per ogni parola nella recensione 2:
TF-IDF ('questo', Revisione 2) = TF ('questo', Revisione 2) * IDF ('questo') = 1/8 * 0 = 0
Simile,
- TF-IDF ('film', Revisione 2) = 1/8 * 0 = 0
- TF-IDF ('è', Revisione 2) = 1/4 * 0 = 0
- TF-IDF ('no', Revisione 2) = 1/8 * 0.48 = 0.06
- TF-IDF ('allarmante', Revisione 2) = 1/8 * 0.18 = 0.023
- TF-IDF ('e', Revisione 2) = 1/8 * 0 = 0
- TF-IDF ('Lento', Revisione 2) = 1/8 * 0.48 = 0.06
Nello stesso modo, possiamo calcolare i punteggi TF-IDF per tutte le parole rispetto a tutte le recensioni:
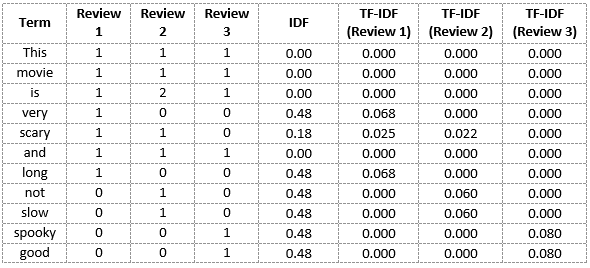
Ora abbiamo ottenuto i punteggi TF-IDF per il nostro vocabolario. TF-IDF fornisce anche valori più grandi per parole meno frequenti ed è alto quando i valori IDF e TF sono alti, vale a dire, la parola è rara in tutti i documenti combinati ma frequente in un unico documento.
Note finali
Permettetemi di riassumere ciò che abbiamo trattato nell'articolo:
- Bag of Words crea semplicemente un insieme di vettori contenenti il conteggio delle occorrenze di parole nel documento (recensioni), mentre il modello TF-IDF contiene anche informazioni sulle parole più importanti e meno importanti.
- I vettori Bag of Words sono facili da interpretare. tuttavia, TF-IDF di solito funziona meglio nei modelli di apprendimento automatico.
Mentre sia Bag-of-Words che TF-IDF sono stati popolari nel loro senso, c'era ancora una lacuna nella comprensione del contesto delle parole. Rileva la somiglianza tra le parole raccapriccianti’ e "spaventoso", o traduci i nostri documenti forniti in un'altra lingua, richiede molte più informazioni nei documenti.
È qui che entrano in gioco le tecniche di word embedding come Word2Vec., Borsa continua di parole (CBOW), Skipgram, eccetera. Puoi trovare una guida dettagliata a queste tecniche qui:





