introduzione
Ti è mai capitato di imbatterti in un set di dati o in un'immagine e ti sei chiesto se potresti creare un sistema in grado di differenziare o identificare l'immagine??
Il concetto di classificazione delle immagini ci aiuterà in questo. La classificazione delle immagini è una delle applicazioni più popolari della visione artificiale e un concetto indispensabile per chiunque cerchi di svolgere un ruolo in questo campo..
In questo articolo, Vedremo un'applicazione molto semplice ma ampiamente utilizzata che è la classificazione delle immagini. Non vedremo solo come creare un modello semplice ed efficiente per classificare i dati, ma impareremo anche come implementare un modello precedentemente addestrato e confrontare le prestazioni dei due.
alla fine dell'articolo, sarai in grado di trovare il tuo set di dati e implementare facilmente la classificazione delle immagini.
Prerequisiti prima di iniziare:
Sembra interessante? Quindi preparati a creare il tuo classificatore di immagini!!
Sommario
- Classificazione delle immagini
- Comprendere l'affermazione del problema
- Impostazioni dati immagine
- Costruiamo il nostro modello di classificazione delle immagini
- Pretrattamento dei dati
- aumento dei dati
- Definizione e formazione del modello
- Valutazione dei risultati
- L'arte del transfer learning
- Importa il modello base MobileNetV2
- Ritocchi
- Addestramento
- Valutazione dei risultati
- Qual è il prossimo?
Cos'è la classificazione delle immagini?
La classificazione dell'immagine è il compito di assegnare un'immagine di input, un'etichetta da un insieme fisso di categorie. Questo è uno dei problemi centrali di Computer Vision che, nonostante la sua semplicità, ha un'ampia varietà di applicazioni pratiche.
Facciamo un esempio per capirlo meglio. Quando eseguiamo la classificazione delle immagini, il nostro sistema riceverà un'immagine come input, ad esempio, un gatto. Ora il sistema conoscerà un insieme di categorie e il suo obiettivo è assegnare una categoria all'immagine.
Questo problema può sembrare semplice o facile, ma è un problema molto difficile da risolvere per il computer. Come saprai?, il computer vede una griglia di numeri e non l'immagine di un gatto come lo vediamo noi. Le immagini sono matrici tridimensionali di numeri interi di 0 un 255, dimensioni Larghezza x Altezza x 3. Il 3 rappresenta i tre canali di colore rosso, Verde, Azul.
Quindi, come può il nostro sistema imparare a identificare questa immagine? Utilizzando reti neurali convoluzionali. Le reti neurali convoluzionali o CNN sono una classe di reti neurali di apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... che rappresentano una svolta nel riconoscimento delle immagini. Potresti già avere una conoscenza di base delle CNN, e sappiamo che le CNN sono costituite da strati convoluzionali, copertine riprendereLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. Definito come ( F(X) = massimo(0, X) ), ReLU consente ai neuroni di attivarsi solo quando l'input è positivo, che aiuta a mitigare il problema dello sbiadimento del gradiente. È stato dimostrato che il suo utilizzo migliora le prestazioni in varie attività di deep learning, rendendo ReLU un'opzione.., strati agglomerati e strati densi completamente collegati.
Per leggere in dettaglio la classificazione delle immagini e la CNN, puoi consultare le seguenti risorse: –
- https://www.analyticsvidhya.com/blog/2020/02/learn-image-classification-cnn-convolutional-neural-networks-3-datasets/
- https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/
Ora che comprendiamo i concetti, diamo un'occhiata a come può essere costruito un modello di classificazione delle immagini e come può essere implementato.
Comprendere l'affermazione del problema
Considera la seguente immagine:

Una persona esperta nello sport sarà in grado di riconoscere l'immagine come Rugby. Potrebbero esserci diversi aspetti dell'immagine che ti hanno aiutato a identificarla come Rugby, potrebbe essere la forma della palla o l'abito del giocatore. Ma hai notato che questa immagine potrebbe benissimo essere identificata come un'immagine di calcio?
Consideriamo un'altra immagine: –

Cosa pensi rappresenti questa immagine?? difficile da indovinare, verità? L'immagine per l'occhio umano inesperto può essere facilmente classificata erroneamente come calcio, ma veramente, è un'immagine di rugby, poiché possiamo vedere che il palo dietro non è una rete ed è più grande. La domanda ora è: possiamo creare un sistema in grado di classificare correttamente l'immagine?.
Questa è l'idea alla base del nostro progetto qui, vogliamo costruire un sistema che sia in grado di identificare lo sport rappresentato in quell'immagine. Le due classi di classificazione qui sono Rugby e Soccer. L'enunciazione del problema può essere un po' complicata poiché lo sport ha molti aspetti in comune, tuttavia, impareremo come affrontare il problema e creare un sistema ben performante.
Configurazione dei nostri dati immagine
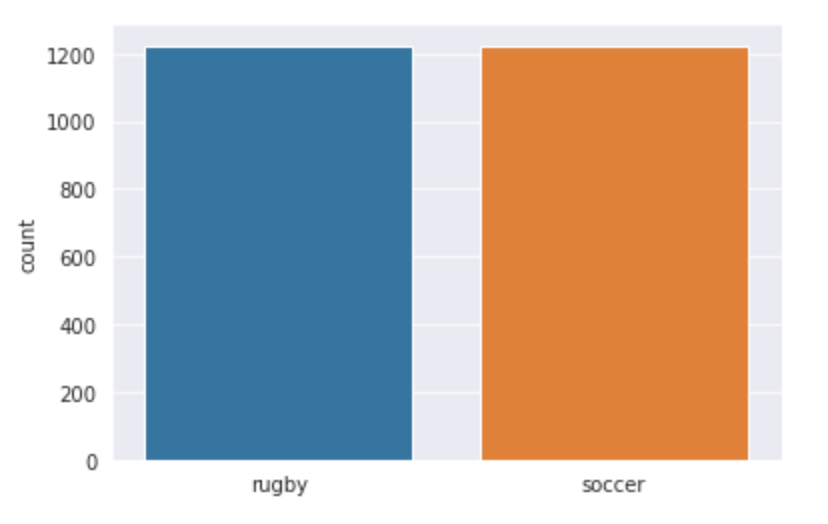
Poiché stiamo lavorando su un problema di classificazione delle immagini, Ho usato due delle più grandi fonti di dati di immagine, vale a dire, ImageNet e Google OpenImages. Ho implementato due script Python in modo da poter scaricare facilmente le immagini. Scaricato un totale di 3058 immagini, che erano divisi in treno e prova. Ho fatto una divisione 80-20 con la cartella del treno che avevo 2448 immagini e la cartella di prova ha 610. Entrambe le classi di rugby e calcio hanno 1224 immagini ciascuno.
La nostra struttura dei dati è la seguente: –
- Iscrizione – 3058
- Treno – 2048
- Rugby – 1224
- Calcio – 1224
- Treno – 2048
-
- Test – 610
- Rugby – 310
- Calcio – 310
- Test – 610
Costruiamo il nostro modello di classificazione delle immagini!!
passo 1: – Importa le librerie richieste
Qui useremo la libreria Keras per creare il nostro modello e addestrarlo. Utilizziamo anche Matplotlib e Seaborn per visualizzare il nostro set di dati e ottenere una migliore comprensione delle immagini che andremo a gestire.. Un'altra libreria importante per la gestione dei dati delle immagini è Opencv.
import matplotlib.pyplot as plt import seaborn as sns import keras from keras.models import Sequential from keras.layers import Dense, Conv2D , MaxPool2D , Appiattire , Dropout from keras.preprocessing.image import ImageDataGenerator from keras.optimizers import Adam from sklearn.metrics import classification_report,confusion_matrix import tensorflow as tf import cv2 import os import numpy as np
passo 2: – Caricamento dei dati
Prossimo, definiamo il percorso dei nostri dati. Definiamo una funzione chiamata get_data () che facilita la creazione del nostro set di dati di convalida e addestramento. Definiamo i due tag 'Rugby'’ e 'Calcio'’ cosa useremo. Utilizziamo la funzione di lettura di Opencv per leggere le immagini in formato RGB e ridimensionare le immagini alla larghezza e all'altezza desiderate, In questo caso entrambi sono 224.
etichette = ['rugby', 'calcio']
img_size = 224
def get_data(data_dir):
dati = []
per l'etichetta nelle etichette:
percorso = os.path.join(data_dir, etichetta)
class_num = labels.index(etichetta)
per img in os.listdir(il percorso):
Tentativo:
img_arr = cv2.imread(os.path.join(il percorso, img))[...,::-1] #convert BGR to RGB format
resized_arr = cv2.resize(img_arr, (img_size, img_size)) # Reshaping images to preferred size
data.append([resized_arr, class_num])
tranne Eccezione come e:
Stampa(e)
restituire np.array(dati)
Ora possiamo facilmente recuperare i nostri dati di treno e convalida.
treno = get_data('.. /input/traintestsports/Main/treno')
val = get_data('.. /input/traintestsports/Main/test')
passo 3: – Visualizza i dati
Visualizziamo i nostri dati e vediamo con cosa stiamo lavorando esattamente. Usiamo seaborn per tracciare il numero di immagini in entrambe le classi e puoi vedere come appare l'output.
l = []
per me in treno:
Se(io[1] == 0):
l.append("rugby")
else
l.append("calcio")
sns.set_style('darkgrid')
sns.countplot(io)
Produzione:
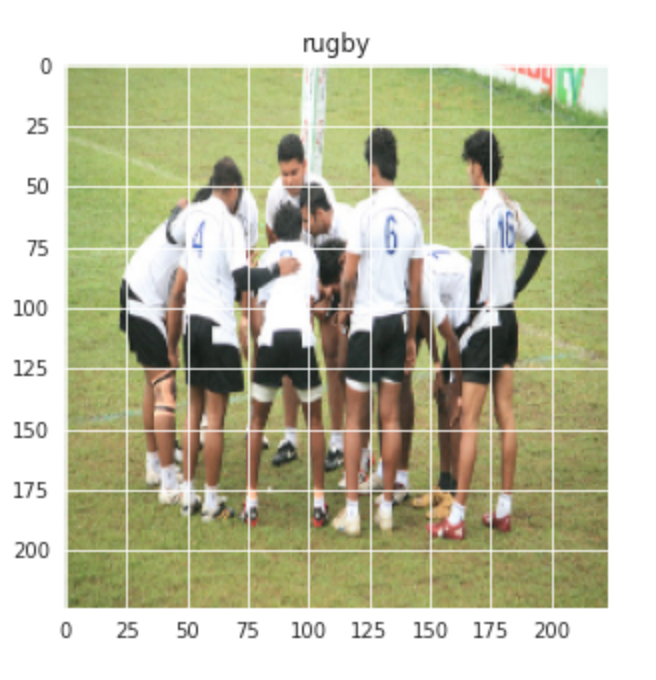
Visualizziamo anche un'immagine casuale delle classi di Rugby e Calcio: –
plt.figure(dimensione del fico = (5,5)) plt.imshow(treno[1][0]) plt.titolo(etichette[treno[0][1]])
Produzione:-
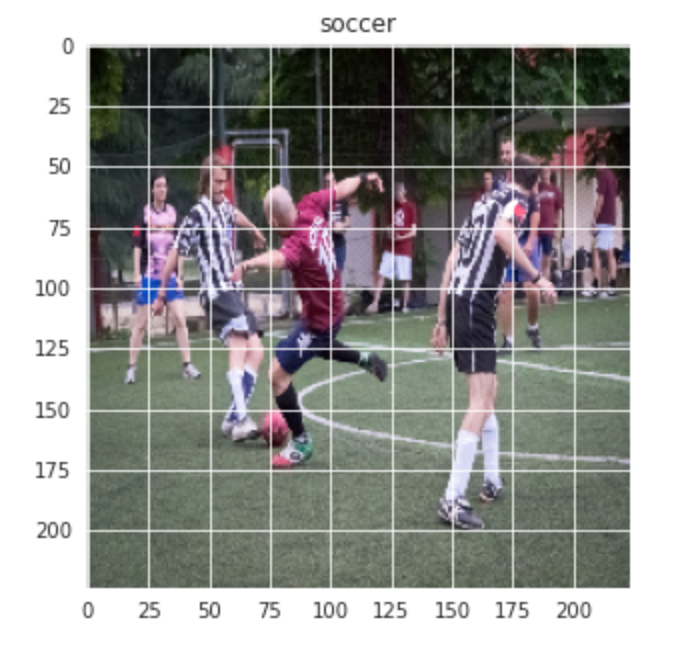
Allo stesso modo per l'immagine del calcio: –
plt.figure(dimensione del fico = (5,5)) plt.imshow(treno[-1][0]) plt.titolo(etichette[treno[-1][1]])
Produzione:-
passo 4: – Preprocesamiento y aumento de datos
Prossimo, realizamos un poco de preprocesamiento y aumento de datos antes de que podamos continuar con la construcción del modelo.
x_train = []
y_train = []
x_val = []
y_val = []
per funzionalità, etichetta in treno:
x_train.append(caratteristica)
y_train.append(etichetta)
per funzionalità, etichetta in val:
x_val.append(caratteristica)
y_val.append(etichetta)
# Normalize the data
x_train = np.array(x_treno) / 255
x_val = np.array(x_val) / 255
x_train.reshape(-1, img_size, img_size, 1)
y_train = np.array(y_train)
x_val.reshape(-1, img_size, img_size, 1)
y_val = np.array(y_val)
Aumento de datos sobre los datos del tren: –
datagen = ImageDataGenerator(
featurewise_center=Falso, # Impostare la media di input su 0 over the dataset
samplewise_center=False, # Impostare la media di ciascun campione su 0
featurewise_std_normalization=Falso, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range = 30, # ruotare casualmente le immagini nell'intervallo (Gradi, 0 a 180)
zoom_range = 0.2, # Randomly zoom image
width_shift_range=0.1, # sposta casualmente le immagini orizzontalmente (frazione della larghezza totale)
height_shift_range=0,1, # sposta casualmente le immagini verticalmente (frazione dell'altezza totale)
horizontal_flip = Vero, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(x_treno)
passo 5: – Definire il modello
Definiamo un semplice modello CNN con 3 livelli convoluzionali seguiti da livelli di raggruppamento massimi. Un drop layer viene aggiunto dopo la terza operazione maxpool per evitare l'overfitting.
modello = Sequenziale() modello.aggiungi(Conv2D(32,3,imbottitura="stesso", attivazione="riprendere", input_shape=(224,224,3))) modello.aggiungi(MaxPool2D()) modello.aggiungi(Conv2D(32, 3, imbottitura="stesso", attivazione="riprendere")) modello.aggiungi(MaxPool2D()) modello.aggiungi(Conv2D(64, 3, imbottitura="stesso", attivazione="riprendere")) modello.aggiungi(MaxPool2D()) modello.aggiungi(Ritirarsi(0.4)) modello.aggiungi(Appiattire()) modello.aggiungi(Denso(128,attivazione="riprendere")) modello.aggiungi(Denso(2, attivazione="softmax")) modello.riepilogo()
Compiliamo ora il modello utilizzando Adam come ottimizzatore e SparseCategoricalCrossentropy come Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e.... Stiamo utilizzando un tasso di apprendimento inferiore di 0.000001 per una curva più liscia.
opt = Adamo(lr=0,000001) modello.compila(ottimizzatore = opt , perdita = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=Vero) , metriche = ['precisione'])
Ora, esegniamo il nostro modello durante 500 epoche, poiché il nostro tasso di apprendimento è molto piccolo.
storia = modello.fit(x_treno,y_train,epoche = 500 , validation_data = (x_val, y_val))
passo 6: – Valutazione del risultato
Mapperemo la nostra precisione di addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... e convalida insieme alla perdita di formazione e convalida.
acc = storia.storia['precisione']
val_acc = storia.storia['val_accuratezza']
perdita = storia.storia['perdita']
val_loss = storia.storia['val_loss']
epochs_range = intervallo(500)
plt.figure(figsize=(15, 15))
plt.sottotrama(2, 2, 1)
plt.trama(epochs_range, acc, etichetta="Precisione dell'allenamento")
plt.trama(epochs_range, val_acc, etichetta="Precisione di convalida")
plt.legend(loc ="in basso a destra")
plt.titolo("Precisione di formazione e convalida")
plt.sottotrama(2, 2, 2)
plt.trama(epochs_range, perdita, etichetta="Perdita di allenamento")
plt.trama(epochs_range, val_loss, etichetta="Perdita di convalida")
plt.legend(loc ="In alto a destra")
plt.titolo("Perdita di formazione e convalida")
plt.mostra()
Vediamo come appare la curva: –
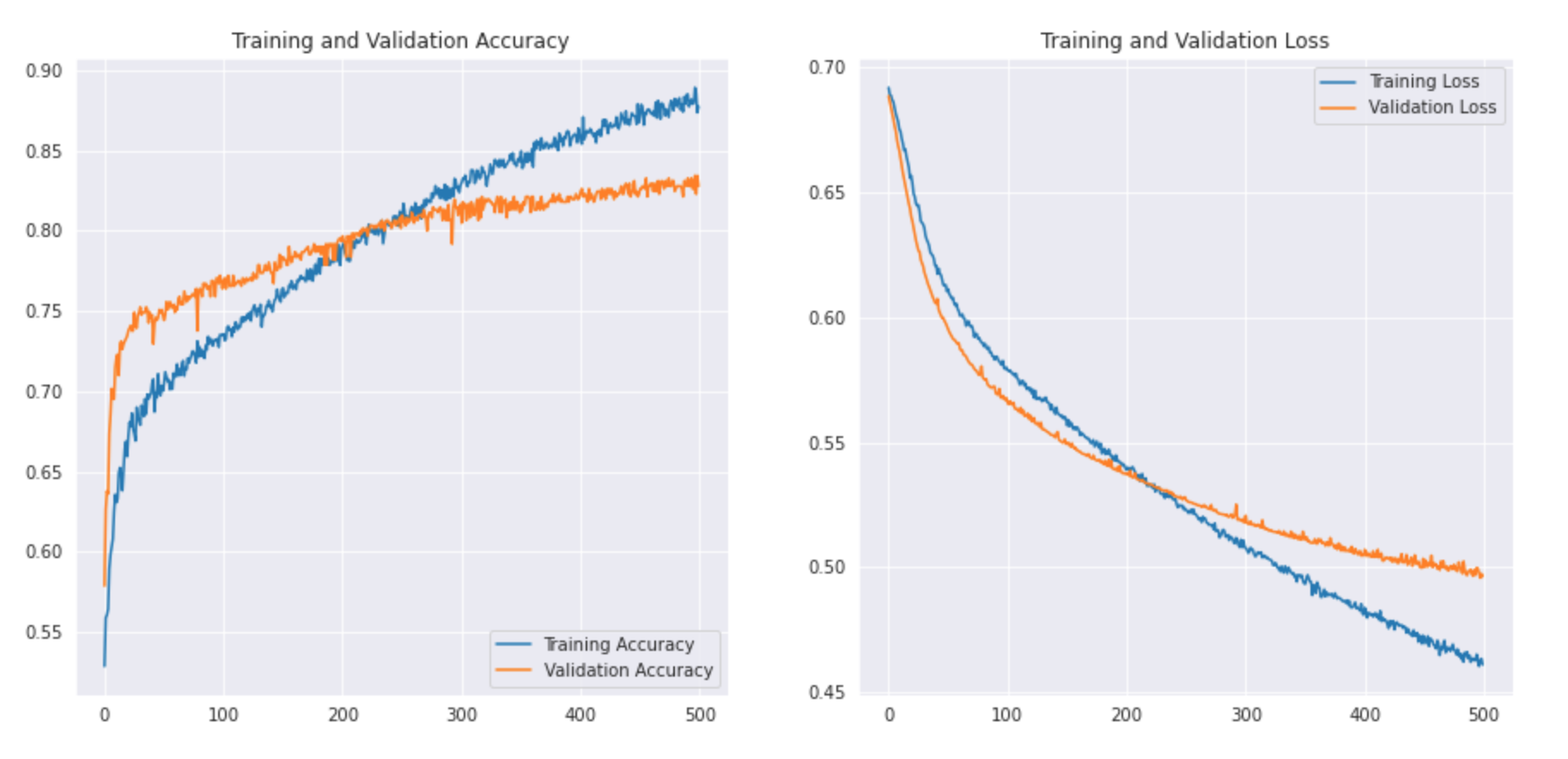
Possiamo stampare il rapporto di classificazione per vedere la precisione e l'accuratezza.
previsioni = model.predict_classes(x_val) previsioni = previsioni.rimodellare(1,-1)[0] Stampa(classificazione_report(y_val, predizioni, nomi_destinazione = ['Rugby (Classe 0)','Calcio (Classe 1)']))
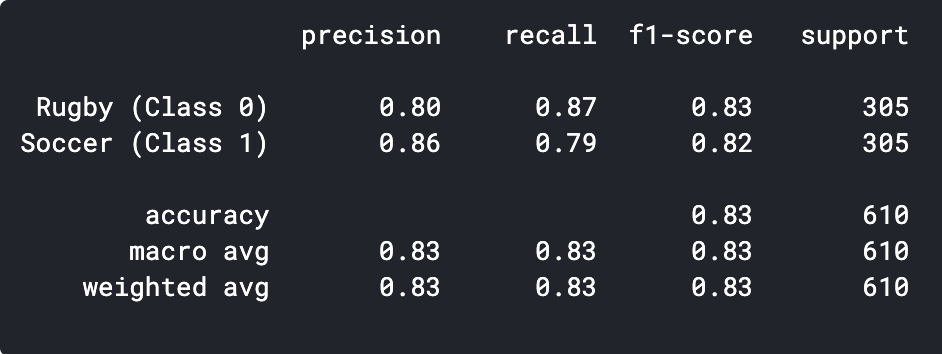
Come possiamo vedere, il nostro semplice modello CNN è stato in grado di ottenere una precisione di 83%. Con alcune regolazioni dell'iperparametro, potremmo ottenere una precisione di 2-3%.
Possiamo anche visualizzare alcune delle immagini previste in modo errato e vedere dove il nostro classificatore sta fallendo..
L'arte del transfer learning
Vediamo prima cosa è il transfer learning. Il transfer learning è una tecnica di machine learning in cui un modello addestrato su un compito viene riorientato su un secondo compito correlato.. Un'altra applicazione cruciale del transfer learning è quando il set di dati è piccolo., utilizzando un modello precedentemente addestrato su immagini simili possiamo facilmente ottenere prestazioni elevate. Poiché il nostro approccio al problema è una buona opzione per trasferire l'apprendimento, vediamo come possiamo implementare un modello pre-addestrato e quale precisione possiamo ottenere.
passo 1: – importa il modello
Creeremo un modello base dal modello MobileNetV2. Questo è pre-addestrato sul set di dati ImageNet, un grande set di dati composto da 1,4 milioni di immagini e 1000 Lezioni. Questa base di conoscenze ci aiuterà a classificare il rugby e il calcio dal nostro set di dati specifico.
Specificando l'argomento include_top = False, caricare una rete che non includa i livelli di classificazione in alto.
base_model = tf.keras.applications.MobileNetV2(input_forma = (224, 224, 3), include_top = Falso, pesi = "imagenet")
È importante congelare la nostra base prima di costruire e addestrare il modello. Il congelamento impedirà l'aggiornamento dei pesi del nostro modello base durante l'allenamento.
base_model.trainable = Falso
Prossimo, definiamo il nostro modello usando il nostro base_model seguito da una funzione GlobalAveragePooling per convertire le caratteristiche in un unico vettore per immagine. Aggiungiamo un dropout di 0.2 E la strato densoLo strato denso è una formazione geologica che si caratterizza per la sua elevata compattezza e resistenza. Si trova comunemente sottoterra, dove funge da barriera al flusso dell'acqua e di altri fluidi. La sua composizione varia, ma di solito include minerali pesanti, che gli conferisce proprietà uniche. Questo strato è fondamentale nell'ingegneria geologica e negli studi sulle risorse idriche, poiché influenza la disponibilità e la qualità dell'acqua.. finale con 2 neuroni e attivazione softmax.
modello = tf.keras.Sequenziale([modello_base,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dropout(0.2),
tf.strati.duri.Densi(2, attivazione="softmax")
])
Prossimo, Compiliamo il modello e iniziamo ad addestrarlo.
base_learning_rate = 0.00001
modello.compila(ottimizzatore=tf.hard.optimizers.Adam(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=Vero),
metriche=['precisione'])
storia = modello.fit(x_treno,y_train,epoche = 500 , validation_data = (x_val, y_val))
passo 2: – Valutazione del risultato.
acc = storia.storia['precisione']
val_acc = storia.storia['val_accuratezza']
perdita = storia.storia['perdita']
val_loss = storia.storia['val_loss']
epochs_range = intervallo(500)
plt.figure(figsize=(15, 15))
plt.sottotrama(2, 2, 1)
plt.trama(epochs_range, acc, etichetta="Precisione dell'allenamento")
plt.trama(epochs_range, val_acc, etichetta="Precisione di convalida")
plt.legend(loc ="in basso a destra")
plt.titolo("Precisione di formazione e convalida")
plt.sottotrama(2, 2, 2)
plt.trama(epochs_range, perdita, etichetta="Perdita di allenamento")
plt.trama(epochs_range, val_loss, etichetta="Perdita di convalida")
plt.legend(loc ="In alto a destra")
plt.titolo("Perdita di formazione e convalida")
plt.mostra()
Vediamo come appare la curva: –
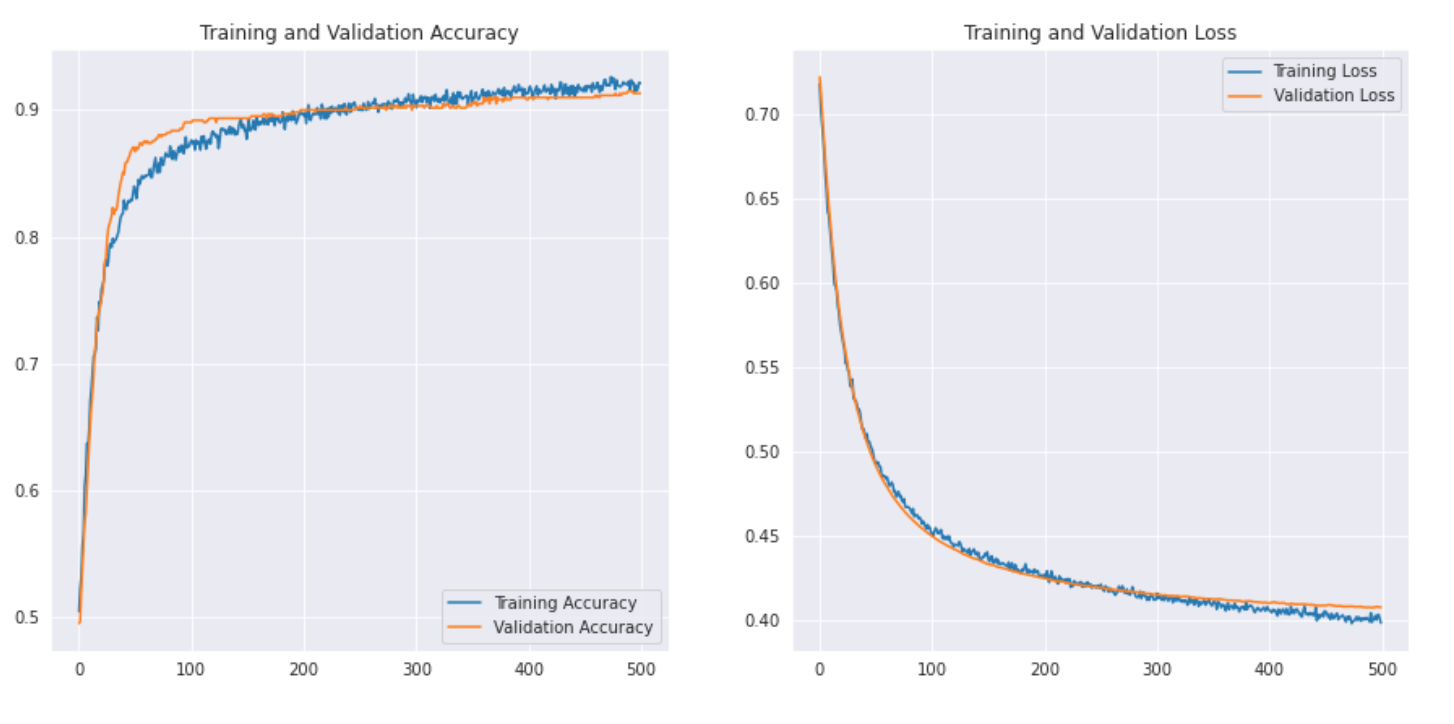
Stampiamo anche il rapporto sulla classifica per risultati più dettagliati.
previsioni = model.predict_classes(x_val) previsioni = previsioni.rimodellare(1,-1)[0] Stampa(classificazione_report(y_val, predizioni, nomi_destinazione = ['Rugby (Classe 0)','Calcio (Classe 1)']))
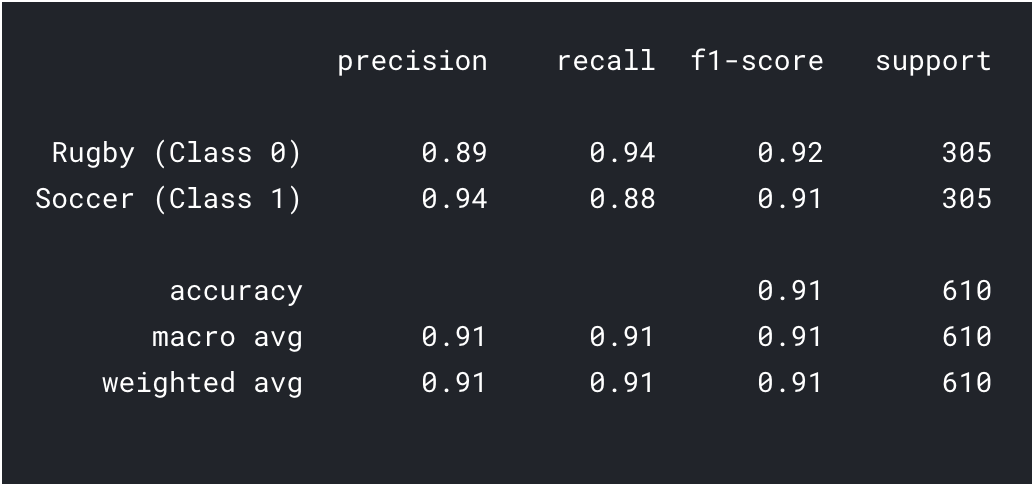
Come possiamo vedere con il trasferimento dell'apprendimento, siamo riusciti a ottenere un risultato molto migliore. Sia la precisione del rugby che quella del calcio sono superiori al nostro modello CNN e anche la precisione complessiva raggiunta 91%, che è davvero buono per un set di dati così piccolo. Con un po' di messa a punto degli iperparametri e modifiche di parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto...., potremmo anche ottenere prestazioni leggermente migliori!
Qual è il prossimo?
Questo è solo il punto di partenza nel campo della visione artificiale. Infatti, prova a migliorare i tuoi modelli CNN di base per eguagliare o superare le prestazioni del benchmark.
- Puoi imparare dalle architetture VGG16, eccetera. per alcuni suggerimenti sull'ottimizzazione degli iperparametri.
- Puoi utilizzare lo stesso ImageDataGenerator per aumentare le tue immagini e aumentare le dimensioni del set di dati.
- Cosa c'è di più, puoi provare a implementare architetture più nuove e migliori come DenseNet e XceptionNet.
- Puoi anche passare ad altre attività di visione artificiale, come l'individuazione e segmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione.... e consolidare un inventario ed eseguire la costruzione di una serie, che ti accorgerai in seguito può anche essere ridotto alla classificazione delle immagini.
Note finali
Congratulazioni, hai imparato come creare il tuo set di dati e creare un modello CNN o eseguire il trasferimento di apprendimento per risolvere un problema. Abbiamo imparato molto in questo articolo, dall'apprendimento di come recuperare i dati delle immagini alla creazione di un semplice modello CNN in grado di ottenere prestazioni ragionevoli. Abbiamo anche imparato l'applicazione del transfer learning per migliorare ulteriormente le nostre prestazioni..
non è la fine, abbiamo visto che i nostri modelli hanno classificato erroneamente molte immagini, il che significa che ci sono ancora margineMargine è un termine usato in una varietà di contesti, come la contabilità, Economia e stampa. In contabilità, si riferisce alla differenza tra ricavi e costi, che permette di valutare la redditività di un'impresa. Nel campo dell'editoria, Il margine è lo spazio bianco intorno al testo di una pagina, che lo rende facile da leggere e fornisce una presentazione estetica. La sua corretta gestione è fondamentale.. di miglioramento. Potremmo iniziare trovando più dati o persino implementando architetture più nuove e migliori che potrebbero essere più efficaci nell'identificare le funzionalità.
Trovi utile questo articolo? Condividi il tuo prezioso feedback nella sezione commenti qui sotto.. Sentiti libero di condividere anche i tuoi libri di codici completi, che sarà utile ai membri della nostra comunità.





