Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
L'intelligenza artificiale è stata notevolmente migliorata senza la necessità di modificare l'infrastruttura hardware sottostante. Gli utenti possono eseguire un programma di intelligenza artificiale su un vecchio sistema informatico. In secondo luogo, l'effetto benefico dell'apprendimento automatico è illimitato. L'elaborazione del linguaggio naturale è uno dei rami dell'intelligenza artificiale che dà alle macchine la capacità di leggere, comprendere e fornire significato. La PNL ha avuto molto successo nel settore sanitario, i media, finanza e risorse umane.
La forma più comune di dati non strutturati sono testi e discorsi. è abbondante, ma difficile, estrarre informazioni utili. Altrimenti, ci vorrebbe molto tempo per estrarre le informazioni. Il testo scritto e il parlato contengono informazioni preziose. è perché noi, come esseri intelligenti, usiamo la scrittura e il parlato come la principale forma di comunicazione. La PNL può analizzare questi dati per noi ed eseguire attività come l'analisi del sentiment, assistente cognitivo, filtraggio a intervalli, identificazione di notizie false e traduzione linguistica in tempo reale.
Questo articolo tratterà come la PNL comprende testi o parti del discorso. Ci concentreremo principalmente sull'analisi di parole e sequenze. Include la classificazione del testo, semantica vettoriale e incorporamento di parole, modello probabilistico del linguaggio, etichettatura sequenziale e riorganizzazione del parlato. Vedremo l'analisi del sentimento di cinquantamila critici cinematografici di IMDB. Il nostro obiettivo è identificare se la recensione pubblicata sul sito IMDB dal tuo utente è positiva o negativa..
Elenco degli argomenti
- Hai capito cos'è la PNL??
- A cosa serve la PNL?
- Parole e sequenze
- Classificazione del testo
- Incorporamento di parole vettoriali e semantica
- Modelli probabilistici del linguaggio
- Etichettatura della sequenza
- Analizzatori
- Semantica
- Esecuzione dell'analisi semantica sul progetto IMDB Movie Review Data
La PNL è stata ampiamente utilizzata nelle automobili, smartphone, Altoparlanti, computer, siti web, eccetera. Google Translator usa il traduttore automatico, cos'è il sistema PNL. Google Translator ha scritto e parlato in linguaggio naturale per la lingua che gli utenti vogliono tradurre. La PNL aiuta Google Translate a capire la parola nel contesto, rimuovi il rumore extra e crea la CNN per capire la voce nativa.
La PNL è popolare anche nei chatbot. I chatbot sono molto utili perché riducono il lavoro umano di chiedere di cosa ha bisogno il cliente. I chatbot della PNL pongono domande sequenziali come qual è il problema dell'utente e dove trovare la soluzione. Apple e AMAZON hanno un robusto chatbot sul loro sistema. Quando l'utente fa alcune domande, il chatbot li converte in frasi comprensibili nel sistema interno.
Si chiama toke. Dopo, il token viene passato alla PNL per avere un'idea di cosa chiedono gli utenti. La PNL viene utilizzata nel recupero delle informazioni (IR). IR è un programma software che si occupa di storage di grandi dimensioni, valutazione delle informazioni da documenti di testo di grandi dimensioni da repository. Recupererà solo le informazioni rilevanti. Ad esempio, utilizzato nel rilevamento vocale di Google per eliminare le parole non necessarie.
Applicazione PNL
- Traduzione automatica, vale a dire, Google Traduttore
- Recupero di informazioni
- Risposta alle domande, vale a dire, ChatBot
- Riepilogo
- Analisi del sentimento
- Analisi dei social network
- Big data mining
Parole e sequenze
Il sistema di PNL deve comprendere correttamente il testo, segni e semantica. Molti metodi aiutano il sistema PNL a comprendere testo e simboli. Sono la classificazione del testo, semantica vettoriale, incorporamento di parole, modello probabilistico del linguaggio, tagging di sequenze e riorganizzazione del parlato.
-
Classificazione del testo
La chiarificazione del testo è il processo di categorizzazione del testo in un gruppo di parole. Quando si usa la PNL, la classificazione del testo può analizzare automaticamente il testo e quindi assegnare un insieme di tag o categorie predefiniti in base al contesto. La PNL viene utilizzata per l'analisi delle opinioni, rilevamento dell'argomento e rilevamento della lingua. Ci sono principalmente tre approcci alla classificazione del testo:
- Sistema basato su regole,
- sistema macchina
- Sistema ibrido.
Nell'approccio basato sulle regole, i testi sono separati in un gruppo organizzato utilizzando una serie di regole linguistiche artigianali. Queste regole linguistiche artigianali contengono utenti per definire un elenco di parole caratterizzate da gruppi. Ad esempio, parole come Donald Trump e Boris Johnson sarebbero da classificare in politica. Persone come LeBron James e Ronaldo si qualificherebbero per lo sport.
Il classificatore basato sulla macchina impara a fare una classificazione basata su osservazioni passate dei set di dati. I dati utente sono pre-etichettati come dati tarin e test. Raccogli la strategia di ranking dai post precedenti e impara continuamente. Il classificatore basato su macchine utilizza un contenitore di una sola parola per l'estensione delle funzionalità.
In un sacco di parole, un vettore rappresenta la frequenza delle parole in un dizionario predefinito da un elenco di parole. Possiamo eseguire la PNL utilizzando i seguenti algoritmi di apprendimento automatico: Bayer ingenuo, SVM e Deep Learning.

Il terzo approccio alla classificazione del testo è l'approccio ibrido. L'utilizzo dell'approccio ibrido combina un approccio basato su regole e basato su macchine. Utilizzo di un approccio al sistema ibrido basato su regole per creare un'etichetta e utilizzare l'apprendimento automatico per addestrare il sistema e creare una regola. Dopo, l'elenco delle regole basate su macchine viene confrontato con l'elenco delle regole basate su regole. Se qualcosa non corrisponde sulle etichette, gli umani migliorano l'elenco manualmente. È il metodo migliore per implementare la classificazione del testo.
-
Semantica vettoriale
Vector Semantic è un'altra forma di analisi di parole e sequenze. La semantica vettoriale definisce la semantica e interpreta il significato delle parole per spiegare caratteristiche come parole simili e parole opposte. L'idea principale alla base della semantica vettoriale è che due parole sono uguali se sono state utilizzate in un contesto simile.. La semantica vettoriale divide le parole in uno spazio vettoriale multidimensionale. La semantica vettoriale è utile nell'analisi del sentiment.
-
Incorporamento di parole
L'incorporamento di parole è un altro metodo di analisi di parole e sequenze. L'incorporamento traduce i vettori di prenotazione in uno spazio a bassa dimensionalità che preserva le relazioni semantiche. L'incorporamento di parole è un tipo di rappresentazione di parole che consente a parole con un significato simile di avere una rappresentazione simile. Esistono due tipi di incorporamenti di parole:
Word2Vec è un metodo statistico per apprendere in modo efficiente un'inclusione di parole indipendenti da un corpus di testo.
Doc2Vec è simile a Doc2Vec, ma analizza un gruppo di testo come pagine.
-
Modello probabilistico del linguaggio
Un altro approccio all'analisi di parole e sequenze è il modello linguistico probabilistico.. L'obiettivo del modello linguistico probabilistico è calcolare la probabilità di una frase da una sequenza di parole. Ad esempio, la probabilità che la parola “un” apparire in una data parola “un” è 0.00013131 per cento.
-
Etichettatura della sequenza
L'etichettatura della sequenza è una tipica attività NLP che assegna una classe o un'etichetta a ciascun token in una determinata sequenza di input. Se qualcuno dice “metti sul film di Tom Hanks”. In sequenza, l'etichettatura è [giocare a, film, Tom Hanks]. Il gioco determina un'azione. I film sono un esempio di azione. Tom Hanks cerca un'entità di ricerca. Dividi l'input in più token e usa LSTM per analizzarlo. Ci sono due modi per etichettare le sequenze. Stanno taggando i token e le tranche.
L'analisi è una fase della PNL in cui il parser determina la struttura sintattica di un testo analizzando le parole che lo costituiscono in base a una grammatica sottostante. Ad esempio, "Tom ha mangiato una mela" sarà diviso nel suo stesso nome tom, verbo fino a, determinante , sostantivo mela. Il miglior esempio è Amazon Alexa.
Discutiamo come il testo è classificato e come dividere la parola e la sequenza in modo che l'algoritmo possa capirlo e categorizzarlo.. In questo progetto, scopriamo un'analisi del sentimento di cinquantamila critici cinematografici di IMDB. Il nostro obiettivo è identificare se la recensione pubblicata sul sito IMDB dal tuo utente è positiva o negativa..
Questo progetto copre le tecniche di estrazione del testo come l'incorporamento del testo, sacchetti di parole, contesto di parole e altre cose. Tratteremo anche l'introduzione di un classificatore di sentiment LSTM bidirezionale.. Vedremo anche come importare automaticamente un dataset taggato da TensorFlow. Questo progetto copre anche passaggi come la pulizia dei dati, elaborazione di testi, bilanciare i dati campionando, addestrando e testando un modello di deep learning per classificare il testo.
Analizzando
Il parser determina la struttura sintattica di un testo analizzando le sue parole costitutive sulla base di una grammatica sottostante. Dividi le parole nel gruppo in parti componenti e separa le parole.
Per maggiori dettagli sull'analisi, vedere Questo articolo.
Semantico
Il testo è al centro di come comunichiamo. ¿Lo que es realmente difícil es comprender lo que se dice en una conversación escrita o hablada? Comprender libros y artículos extensos es aún más difícil. La semántica es un proceso que busca comprender el significado lingüístico mediante la construcción de un modelo del principio que el hablante utiliza para transmitir significado. Se ha utilizado en análisis de comentarios de clientes, análisis de artículos, rilevamento di notizie false, análisis semántico, eccetera.
Aplicación de ejemplo
Aquí está el ejemplo de código:
Importando la biblioteca necesaria
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python # For example, here's several helpful packages to load import numpy as np # linear algebra import pandas as pd # elaborazione dati, CSV file I/O (ad esempio. pd.read_csv) # Input data files are available in the read-only "../input/" directory # For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory import os for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: Stampa(os.path.join(dirname, nome del file)) # You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All" # You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session #Importing require Libraries import os import matplotlib.pyplot as plt import nltk from tkinter import * import seaborn as sns import matplotlib.pyplot as plt sns.set() import scipy import tensorflow as tf import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.python import keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Incorporamento, LSTM from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report
Descargando el archivo necesario
# this cells takes time, please run once # Split the training set into 60% e 40%, so we'll end up with 15,000 examples # for training, 10,000 examples for validation and 25,000 examples for testing. original_train_data, original_validation_data, original_test_data = tfds.load( nome="imdb_reviews", split=('train[:60%]', 'train[60%:]', 'test'), as_supervised=True)
Obtener el índice de palabras de los conjuntos de datos de Keras
#tokanizing by tensorflow word_index = tf.keras.datasets.imdb.get_word_index( percorso="imdb_word_index.json"
)
Sopra [8]:
{K:v for (K,v) in word_index.items() se v < 20}
Fuori da[8]:
{'insieme a': 16, 'io': 10, 'come': 14, 'esso': 9, 'è': 6, 'in': 8, 'ma': 18, 'di': 4, 'questo': 11, 'un': 3, 'per': 15, 'br': 7, 'il': 1, 'era': 13, 'e': 2, 'a': 5, 'film': 19, 'film': 17, 'Quello': 12}
Confronto tra recensioni positive e negative
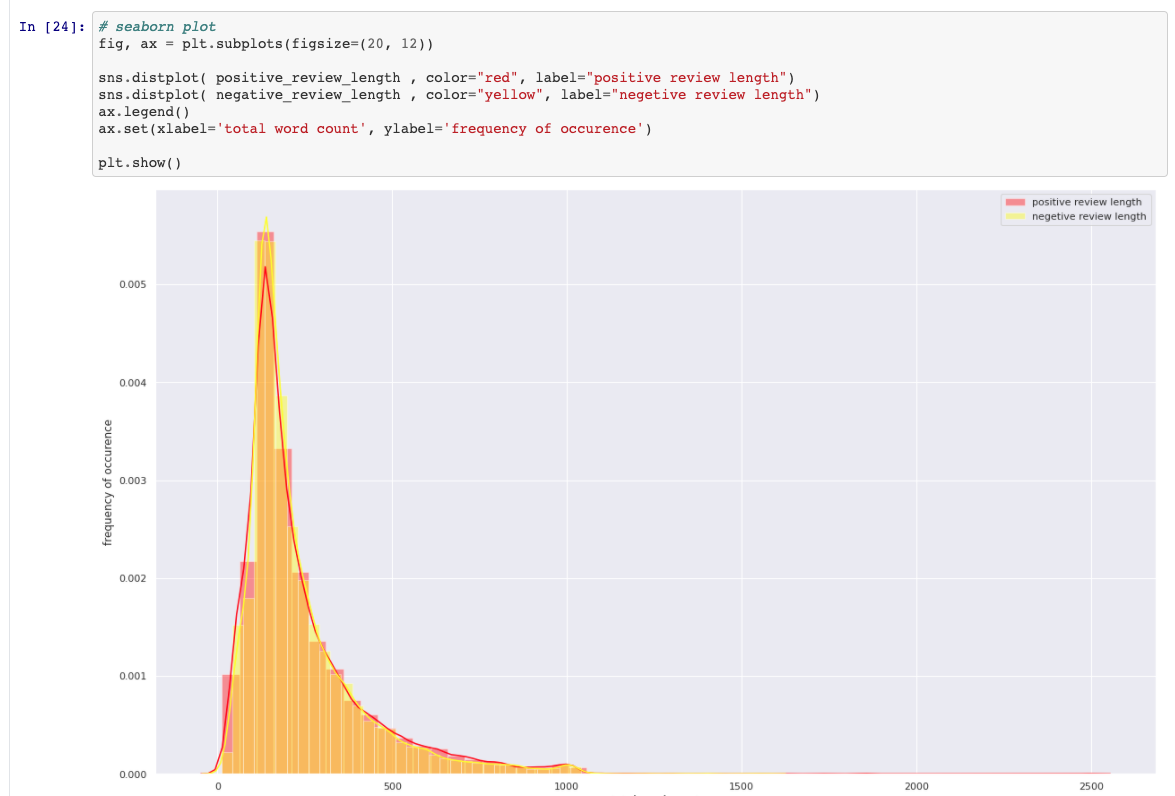
Crea treno, dati di test

Modello e riepilogo del modello
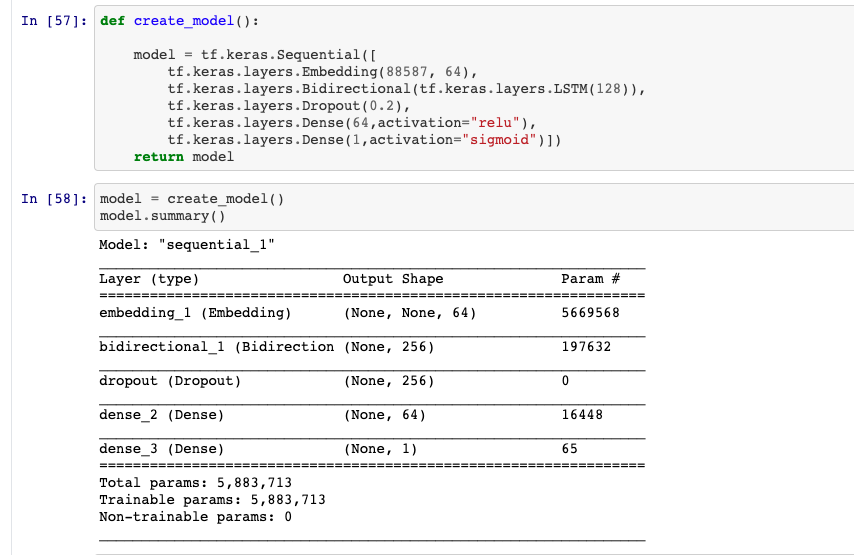
Dividi i dati e adatta il modello
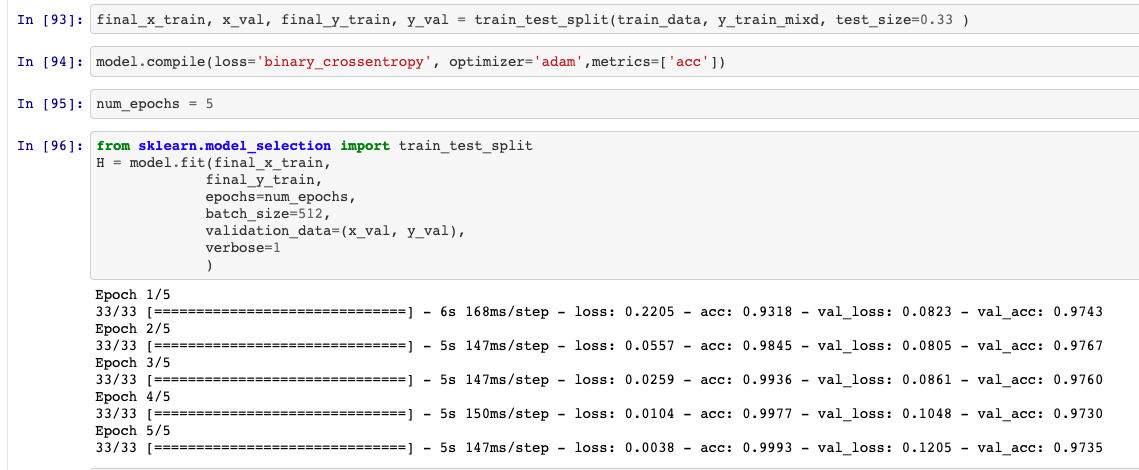
Panoramica dell'effetto modello
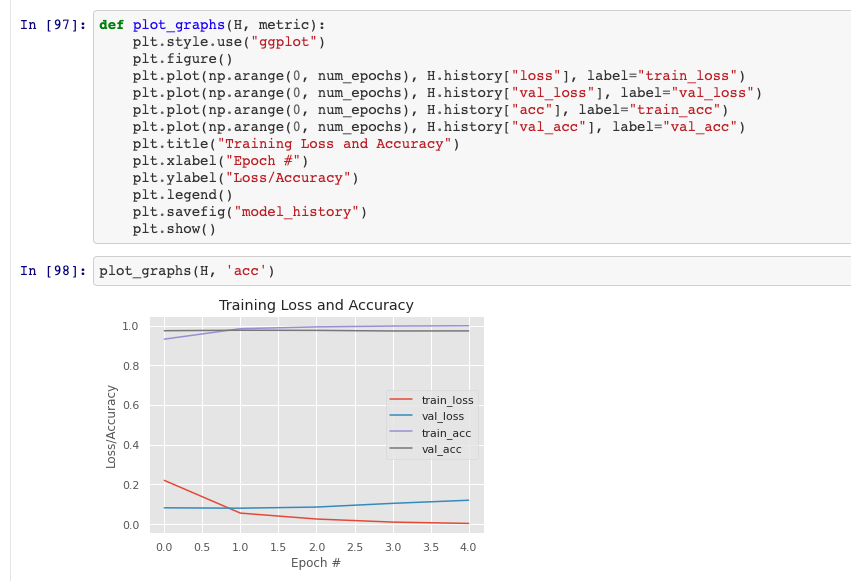
Matrice di confusione e rapporto di correlazione
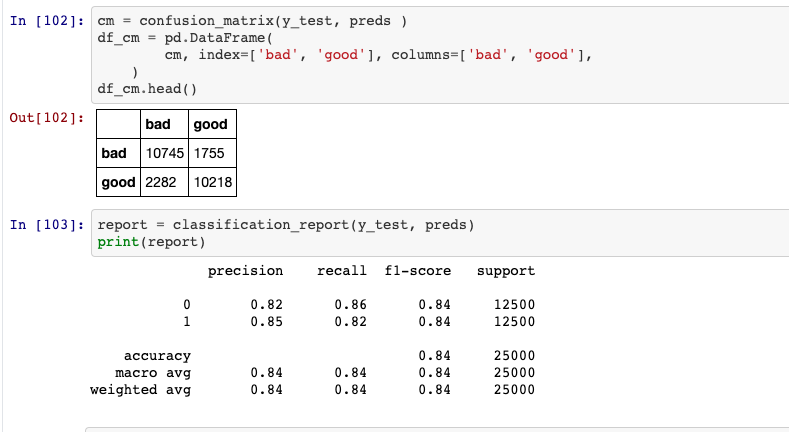
Nota: L'origine dati e i dati per questo modello sono disponibili pubblicamente e accessibili tramite Tensorflow.
Per ottenere il codice completo e i dettagli, Segui questo Archivio GitHub.
In conclusione, La PNL è un campo pieno di opportunità. La PNL ha un enorme effetto su come analizzare testi e discorsi. La PNL migliora ogni giorno. L'estrazione della conoscenza dal grande set di dati era impossibile cinque anni fa. L'ascesa della tecnica della PNL lo ha reso possibile e facile. Ci sono ancora molte opportunità da scoprire in PNL.





