introduzione
Negli ultimi decenni, Deep Learning ha dimostrato di essere uno strumento molto potente grazie alla sua capacità di gestire grandi quantità di dati. L'interesse per l'utilizzo dei livelli nascosti ha superato le tecniche tradizionali, soprattutto nel riconoscimento di modelli. Una delle reti neurali profonde più popolari sono le reti neurali convoluzionali.
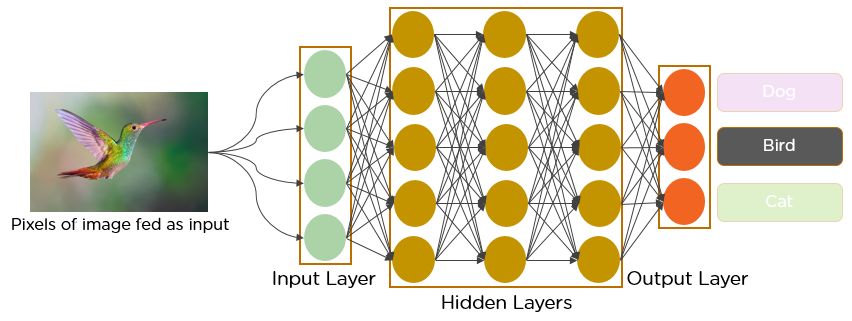
Dal decennio di 1950, i primi giorni di AI, i ricercatori hanno lottato per creare un sistema in grado di comprendere i dati visivi. Negli anni successivi, questo campo divenne noto come Computer Vision. Sopra 2012, la visión por computadora dio un salto cuántico cuando un grupo de investigadores de la Universidad de Toronto desarrolló un modelo de inteligencia artificial que superó los mejores algoritmos de reconocimiento de imágenes y eso también por un amplio margineMargine è un termine usato in una varietà di contesti, come la contabilità, Economia e stampa. In contabilità, si riferisce alla differenza tra ricavi e costi, che permette di valutare la redditività di un'impresa. Nel campo dell'editoria, Il margine è lo spazio bianco intorno al testo di una pagina, che lo rende facile da leggere e fornisce una presentazione estetica. La sua corretta gestione è fondamentale...
Il sistema di intelligenza artificiale, che divenne noto come AlexNet (prende il nome dal suo principale creatore, Alex Krizhevsky), ha vinto il concorso di visione artificiale ImageNet da 2012 con sorprendente precisione di 85 per cento. Il secondo classificato ha guadagnato un modesto 74 per cento sul test.
Al centro di AlexNet c'erano le reti neurali convoluzionali, un tipo especial de neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. que imita aproximadamente la visión humana. Negli anni, Le CNN sono diventate una parte molto importante di molte applicazioni di visione artificiale e, così, in una parte di qualsiasi corso di visione artificiale in linea. Quindi diamo un'occhiata a come funziona la CNN.
Sfondo CNN
Le CNN sono state sviluppate e utilizzate per la prima volta intorno al decennio di 1980. Il massimo che una CNN potesse fare all'epoca era riconoscere le cifre scritte a mano. Era utilizzato principalmente nei settori postali per leggere i codici postali, codici pin, eccetera. Lo importante a recordar sobre cualquier modelo de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... es que requiere una gran cantidad de datos para entrenar y también requiere una gran cantidad de recursos informáticos. Questo è stato un grosso inconveniente per la CNN in quel periodo e, così, Le CNN erano limitate solo ai settori postali e non erano in grado di entrare nel mondo del machine learning.
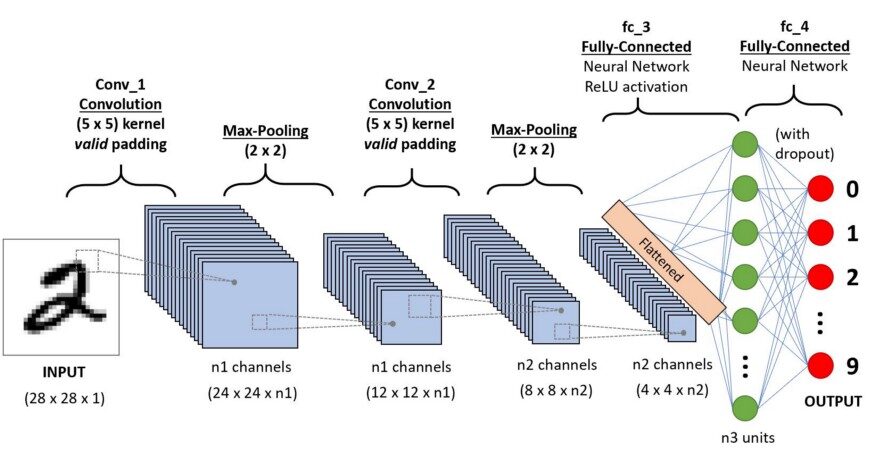
Sopra 2012, Alex Krizhevsky si rese conto che era giunto il momento di riportare in vita il ramo del deep learning che utilizza le reti neurali multistrato. La disponibilità di grandi set di dati, per essere più specifici set di dati ImageNet con milioni di immagini taggate e un'abbondanza di risorse informatiche, ha permesso ai ricercatori di far rivivere la CNN.
Che cos'è esattamente una CNN?
Sopra apprendimento profondo, un convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. (CNN / ConvNet) è una specie di reti neurali profonde, più comunemente applicato per analizzare le immagini visive. Ora, quando pensiamo a una rete neurale, pensiamo alle moltiplicazioni matriciali, ma non è il caso di ConvNet. Utilizza una tecnica speciale chiamata convoluzione. ora in matematica convoluzione è un'operazione matematica su due funzioni che produce una terza funzione che esprime come la forma di una viene modificata dall'altra.
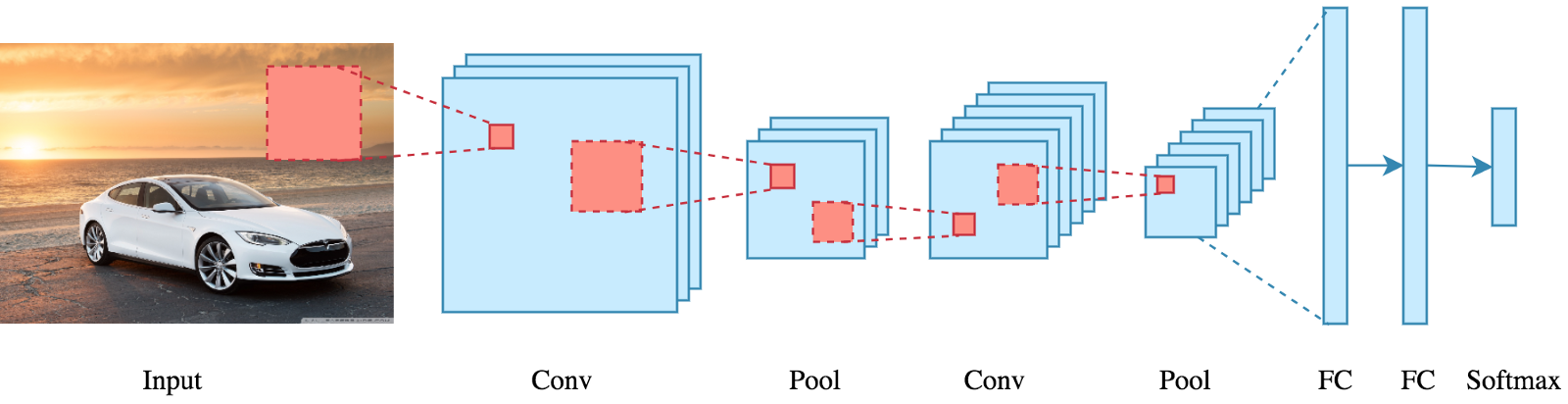
Ma non abbiamo davvero bisogno di andare oltre la parte matematica per capire cos'è una CNN o come funziona..
La linea di fondo è che il ruolo di ConvNet è ridurre le immagini a una forma più facile da elaborare, senza perdere caratteristiche fondamentali per ottenere un buon pronostico.
Come funziona?
Prima di andare al funzionamento della CNN, copriamo le basi, come cos'è un'immagine e come viene rappresentata. Un'immagine RGB non è altro che una matrice di valori di pixel che ha tre piani, mentre un'immagine in scala di grigi è la stessa ma ha un solo piano. Dai un'occhiata a questa immagine per capirne di più.
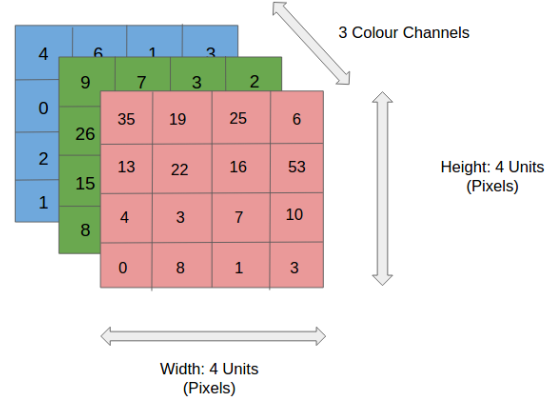
Per semplificare, andiamo avanti con le immagini in scala di grigi mentre cerchiamo di capire come funziona la CNN.
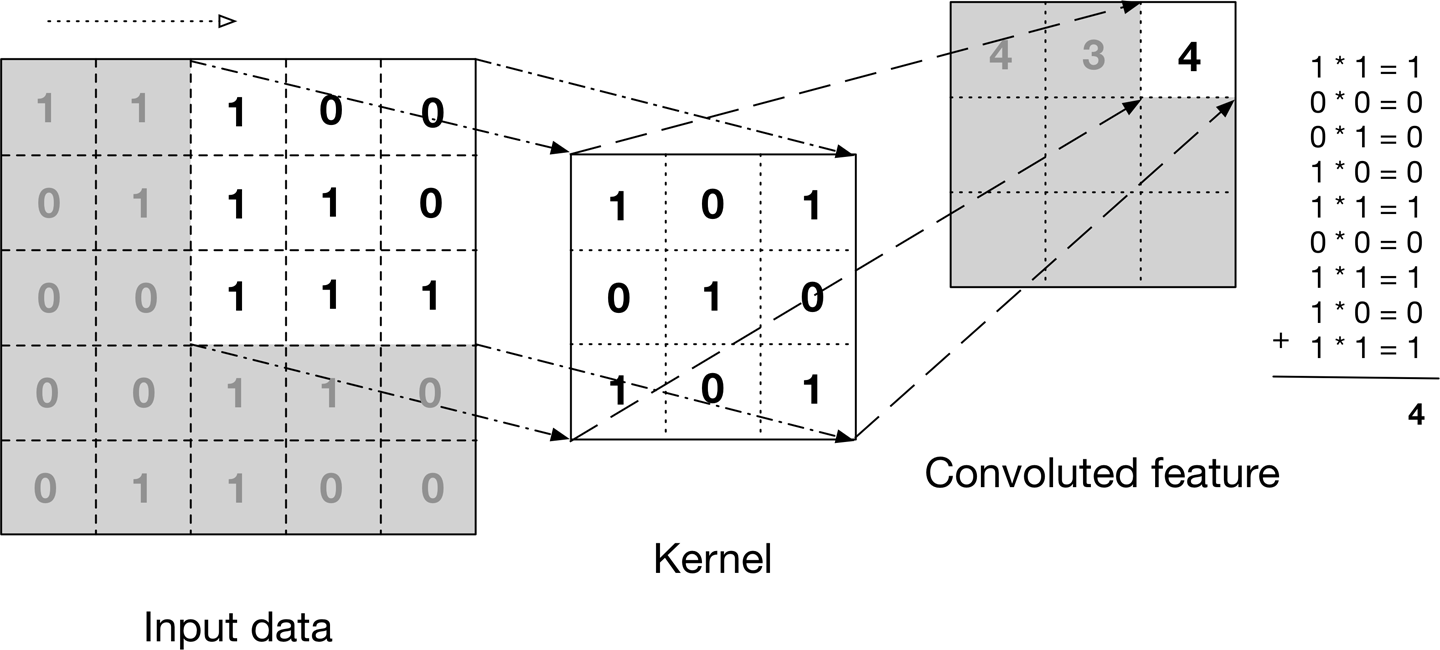
L'immagine sopra mostra cos'è una convoluzione. Prendiamo un filtro / nucleo (matrice di 3 × 3) e lo applichiamo all'immagine di input per ottenere la funzione convoluta. Questa caratteristica convoluta viene passata al livello successivo.
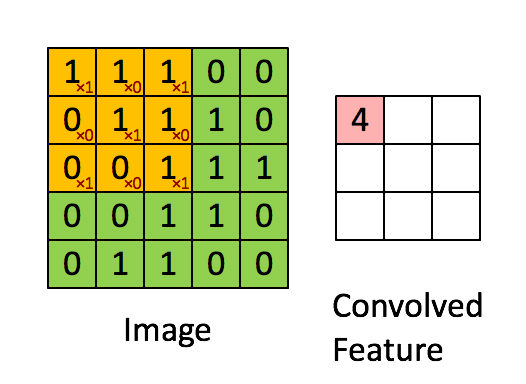
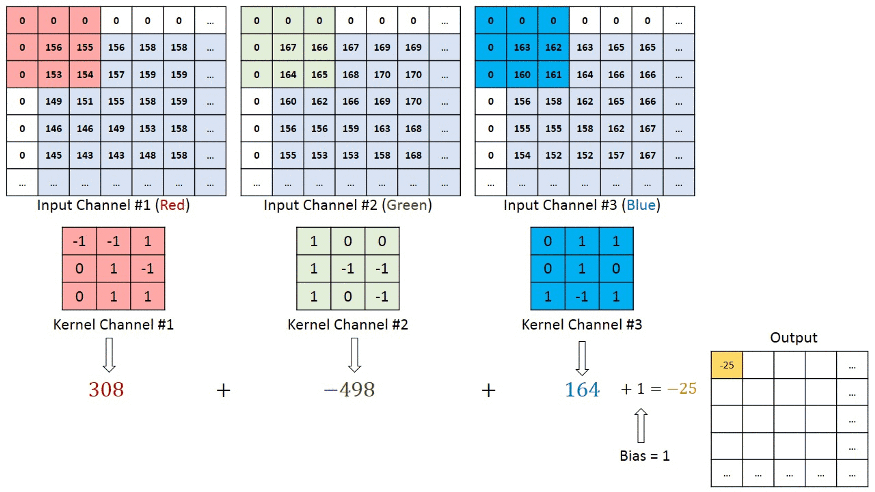
Nel caso del colore RGB, il canale dai un'occhiata a questa animazione per capire come funziona.
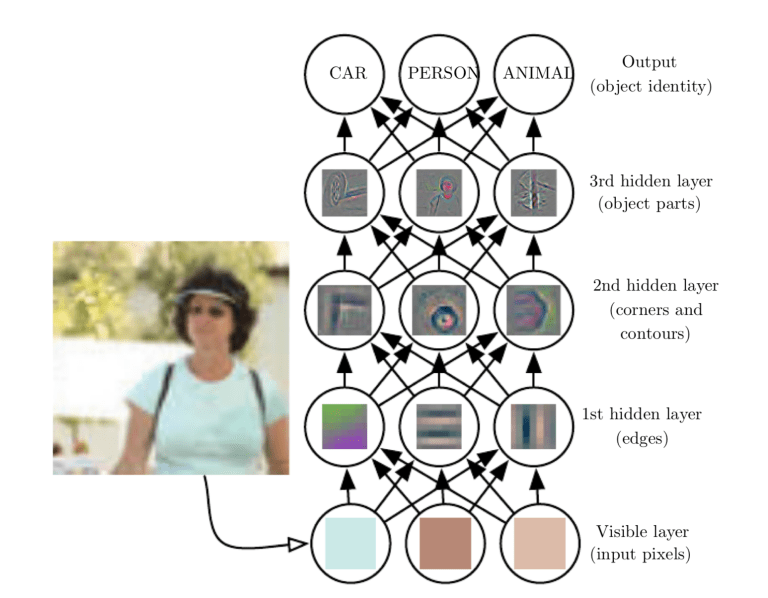
Le reti neurali convoluzionali sono composte da più strati di neuroni artificiali. neuroni artificiali, una rozza imitazione delle loro controparti biologiche, sono funzioni matematiche che calcolano la somma ponderata di più ingressi e uscite di un valore di trigger. Quando inserisci un'immagine in una ConvNet, ogni livello genera diverse funzioni di attivazione che vengono passate al livello successivo.
Il primo livello di solito estrae le caratteristiche di base come i bordi orizzontali o diagonali. Questo output viene passato al livello successivo, che rileva caratteristiche più complesse, come angoli o bordi combinati. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que nos adentramos en la red, possiamo identificare caratteristiche ancora più complesse, come oggetti, facce, eccetera.

Secondo la mappa di attivazione dello strato di convoluzione finale, il livello di classificazione genera una serie di punteggi di confidenza (valori tra 0 e 1) che specificano la probabilità che l'immagine appartenga ad a “classe”. Ad esempio, se hai un ConvNet che rileva i gatti, cani e cavalli, l'output del livello finale è la possibilità che l'immagine di input contenga uno di questi animali.
Che cos'è un livello di raggruppamento??
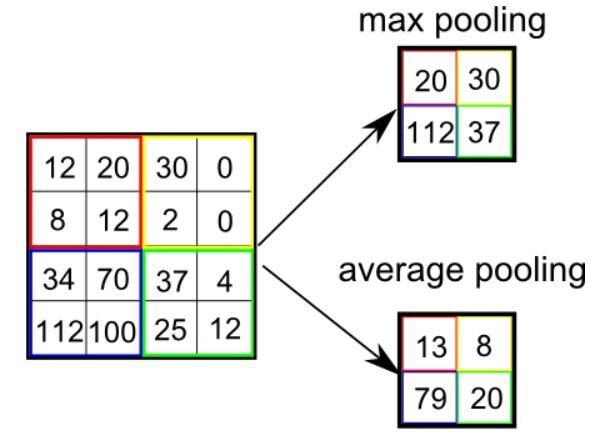
Similar a la copertina convolutivaIl livello convoluzionale, Fondamentale nelle reti neurali convoluzionali (CNN), Viene utilizzato principalmente per l'elaborazione dei dati con strutture a griglia, come immagini. Questo livello applica filtri che estraggono le caratteristiche rilevanti, come bordi e trame, Consentire al modello di riconoscere modelli complessi. La sua capacità di ridurre la dimensionalità dei dati e di mantenere le informazioni essenziali lo rende uno strumento chiave nelle attività di visione artificiale.., il livello di raggruppamento è responsabile della riduzione della dimensione spaziale dell'entità convoluta. Questo è per Diminuire la potenza di calcolo richiesta per elaborare i dati. dimensioni ridotte. Esistono due tipi di raggruppamento, raggruppamento medio e raggruppamento massimo. Finora ho avuto solo esperienza con Max Pooling e non ho riscontrato alcuna difficoltà.
Quindi, quello che facciamo in Max Pooling è trovare il valore massimo di un pixel di una parte dell'immagine coperta dal kernel. Max Pooling funziona anche come Soppressore del rumore. Esclude completamente i trigger rumorosi ed esegue anche il denoising insieme alla riduzione della dimensionalità.
D'altra parte, Raggruppamento medio restituire il media di tutti i valori della parte dell'immagine coperta dal kernel. Il raggruppamento medio esegue semplicemente la riduzione della dimensionalità come meccanismo di soppressione del rumore. Perciò, possiamo dire che La piscina massima funziona molto meglio della piscina media.
Limitazioni
Nonostante la potenza e la complessità delle risorse della CNN, fornire risultati dettagliati. Alla radice di tutto, si tratta semplicemente di riconoscere schemi e dettagli così piccoli e poco appariscenti da passare inosservati all'occhio umano. Ma quando si tratta di comprensione il contenuto dell'immagine fallisce.
Diamo un'occhiata a questo esempio. Quando passiamo l'immagine qui sotto a una CNN, rileva una persona intorno 30 anni e un bambino probabilmente in giro 10 anni. Ma quando guardiamo la stessa immagine, abbiamo iniziato a pensare in più scenari diversi. Forse è il giorno di padre e figlio, un picnic o forse sono in campeggio. Forse è una scuola e il ragazzo ha segnato un gol e suo padre è felice, quindi lo raccoglie.

Queste limitazioni sono più che evidenti quando si tratta di applicazioni pratiche. Ad esempio, Le CNN sono state ampiamente utilizzate per moderare i contenuti sui social media. Ma nonostante le vaste risorse di immagini e video su cui sono stati addestrati, non puoi ancora bloccare e rimuovere completamente i contenuti inappropriati. A quanto pare hai segnato una statua di 30.000 anni con la nudità su Facebook.
Diversi studi hanno dimostrato che le CNN addestrate da ImageNet e altri set di dati popolari non riescono a rilevare gli oggetti se visualizzati in condizioni di illuminazione diverse e da nuove angolazioni..
Questo significa che la CNN è inutile?? tuttavia, nonostante i limiti delle reti neurali convoluzionali, non si può negare che hanno causato una rivoluzione nell'intelligenza artificiale. Oggi, Le CNN sono usate in molti applicazioni di visione artificiale come il riconoscimento facciale, ricerca e modifica di immagini, realtà aumentata e non solo. Come mostrano i progressi nelle reti neurali convoluzionali, i nostri risultati sono notevoli e utili, ma siamo ancora lontani da replicare componenti chiave dell'intelligenza umana.

Grazie per aver letto! Se ti è piaciuto leggere questo articolo, Per favore condividi per aiutare gli altri a trovarlo! Sentiti libero di lasciare un commento qui sotto. Puoi connetterti con me su GitHub, LinkedIn
Hai commenti?? Diventiamo amici in Twitter.
Tutta la migliore e felice codifica! ?
Il supporto mostrato in questo articolo non è di proprietà di Analytics Vidhya e viene utilizzato a discrezione dell'autore.





