In questo articolo, impareremo come possiamo gestire più variabili di categoria utilizzando la tecnica di ingegneria della funzione One Hot Encoding.
Ma prima di continuare, facciamo una breve discussione sull'ingegneria delle funzioni e su One Hot Encoding.
Ingegneria delle funzioni
Quindi, L'ingegneria delle funzionalità è il processo di estrazione delle funzionalità dai dati grezzi utilizzando la conoscenza del dominio del problema. Queste funzioni possono essere utilizzate per migliorare le prestazioni degli algoritmi di apprendimento automatico e, se le prestazioni aumentano, fornirà la migliore precisione. Possiamo anche dire che l'ingegneria delle funzioni è la stessa dell'apprendimento automatico applicato. L'ingegneria delle funzionalità è l'arte più importante nell'apprendimento automatico che crea un'enorme differenza tra un buon modello e un cattivo modello. Questo è il terzo passo nel ciclo di vita di qualsiasi progetto di data science.
Il concetto di trasparenza per i modelli di machine learning è alquanto complicato, poiché modelli diversi richiedono spesso approcci diversi per diversi tipi di dati. Come:-
- Dati continui
- Caratteristiche categoriali
- Valori mancanti
- Normalizzazione
- Date e ora
Ma qui parleremo solo delle caratteristiche categoriche, le caratteristiche categoriali sono quelle caratteristiche in cui il tipo di dati è un tipo di oggetto. Il valore del punto dati in qualsiasi caratteristica categorica non è in forma numerica, ma sotto forma di oggetto.
Esistono molte tecniche per gestire le variabili categoriali, alcuni sono:
- Codifica tag o codifica ordinale
- Una codifica a caldo
- Codifica fittizia
- Codifica degli effetti
- Codifica binaria
- Codifica di Basilea
- Codifica hash
- Codifica della destinazione
Quindi, qui gestiamo le caratteristiche categoriche di One Hot Encoding, così, primo, discutiremos One Hot Encoding.
Una codifica a caldo
Sappiamo che le variabili categoriali contengono i valori dell'etichetta anziché i valori numerici. Il numero di valori possibili è spesso limitato a un insieme fisso. Le variabili categoriali sono spesso chiamate nominali. Molti algoritmi di apprendimento automatico non possono operare direttamente sui dati dei tag. Richiedi che tutte le variabili di input e output siano numeriche.
Ciò significa che i dati categoriali devono essere convertiti in una forma numerica. Se la variabile categoriale è una variabile di output, potresti anche voler convertire le previsioni del modello in forma categorica da presentare o utilizzare in alcune applicazioni.
ad esempio i dati sul genere sono sotto forma di 'maschile’ e 'donna'.
Ma se usiamo la codifica one-hot, codificare e consentire al modello di assumere un ordine naturale tra le categorie può comportare prestazioni scadenti o risultati imprevisti.
La codifica one-hot può essere applicata alla rappresentazione di numeri interi. Qui è dove la variabile codificata intera viene rimossa e viene aggiunta una nuova variabile binaria per ogni valore intero univoco.
Ad esempio, codifichiamo la variabile colore,
| colore rosso | Colore blu |
| 0 | 1 |
| 1 | 0 |
| 0 | 1 |
Ora inizieremo il nostro viaggio. Nel primo passo, prendiamo una serie di dati di previsione dei prezzi delle case.
Set di dati
Qui utilizzeremo il set di dati di house_price che viene utilizzato per prevedere il prezzo della casa in base alle dimensioni dell'area.
Se vuoi scaricare il set di dati di previsione dei prezzi delle case, clicca su qui.
Importazione modulo
Ora, dobbiamo importare importanti moduli Python da utilizzare per la codifica one-hot
# importare i panda importa panda come pd # importando numpy importa numpy come np # importazione di OneHotEncoder da sklearn.preprocessing import OneHotEncoder()
Qui, usiamo panda che vengono utilizzati per l'analisi dei dati, NumPyusato per array n-dimensionali, e da sklearn, useremo un codificatore a caldo di classe uno importante per la codifica categorica.
Ora dobbiamo leggere questi dati usando Python.
Leggi set di dati
In genere, il set di dati è in formato CSV, e anche il set di dati che usiamo è in formato CSV. Per leggere il file CSV utilizzeremo la funzione panda read_csv (). vedi sotto:
# lettura del set di dati
df = pd.read_csv('prezzo_casa.csv')
df.head()
produzione:-

Ma dobbiamo usare solo variabili categoriali per un codificatore attivo e proveremo solo a spiegare con variabili categoriali per una facile comprensione.
per partizionare le variabili categoriali dai dati, dobbiamo verificare quante caratteristiche hanno valori categorici.
Controllo dei valori categoriali
Per verificare i valori utilizziamo la funzione pandas select_dtypes che serve per selezionare i tipi di dati della variabile.
# controllo delle caratteristiche cat = df.select_dtypes(includi="oh").chiavi() # visualizzare le variabili gatto
produzione:-

Ora dobbiamo rimuovere quelle colonne numeriche dal set di dati e useremo questa variabile categoriale per il nostro utilizzo. Usiamo solo 3-4 colonne categoriali del set di dati per applicare la codifica one-hot.
Crea un nuovo frame di dati
Ora, usare variabili categoriali, creeremo un nuovo frame di dati dalle colonne categoriali selezionate.
# creazione di un nuovo df
# impostando le colonne che usiamo
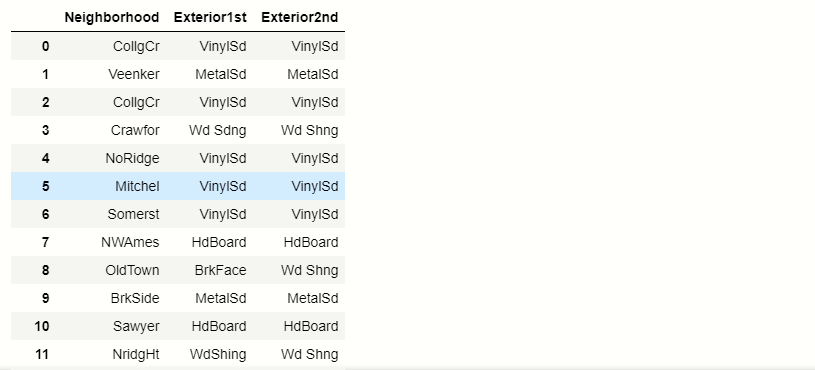
new_df = pd.read_csv('prezzo_casa.csv',usecols =['Quartiere','Esterno1° ','Exterior2nd'])
new_df.head()
produzione:-
Ora dobbiamo scoprire quante categorie uniche sono presenti in ogni colonna categoriale.
Trova valori unici
Per trovare valori univoci utilizzeremo la funzione unica dei panda ().
# valori univoci in ogni colonna
per x in new_df.columns:
#stampa di valori univoci
Stampa(X ,':', len(new_df[X].unico()))
produzione:-
| Quartiere: 25 |
| Esterno 1°: 15 |
| Esterno 2°: 16 |
Ora, useremo la nostra tecnica per applicare la codifica one-hot su variabili multicategoria.
Tecnica per variabili multicategoria
La tecnica consiste nel limitare la codifica one-hot a 10 etichette più frequenti della variabile. Ciò significa che faremmo una variabile binaria solo per ciascuno dei 10 tag più frequenti, questo equivale a raggruppare tutti gli altri tag in una nuova categoria, che in questo caso verrà eliminato. A) Sì, il 10 nuove variabili fittizie indicano se una delle 10 i tag più frequenti sono presenti è 1 o no allora 0 per un'osservazione particolare.
Variabili più frequenti
Qui selezioneremo il 20 variabili più frequenti.
Supponiamo di prendere una variabile categoriale Quartiere.
# trovare il top 20 categorie new_df.Neighborhood.value_counts().sort_values(ascendente=Falso).testa(20)
produzione:

Quando vedi in questa immagine di output, noterai che nomi L'etichetta si ripete 225 volte nelle colonne del quartiere e scendiamo questo numero sta diminuendo.
Quindi prendiamo il 10 i migliori risultati dall'alto e convertiamo questo risultato migliore 10 nella codifica one-hot e le etichette a sinistra diventano zero.
produzione:-
Elenco delle variabili categoriali più frequenti
# fare lista con top 10 variabili top_10 = [x per x in new_df.Neighborhood.value_counts().sort_values(ascendente=Falso).testa(10).indice] top_10
produzione:-
["Nomi",
'CollgCr',
'Città vecchia',
"Edoardo",
'sommerso',
'Gilberto',
'NridgHt',
'Sawyer',
'NWAmes',
'SawyerW']
Ci sono i 10 Etichette delle categorie principali nella colonna Quartiere.
Crea binario
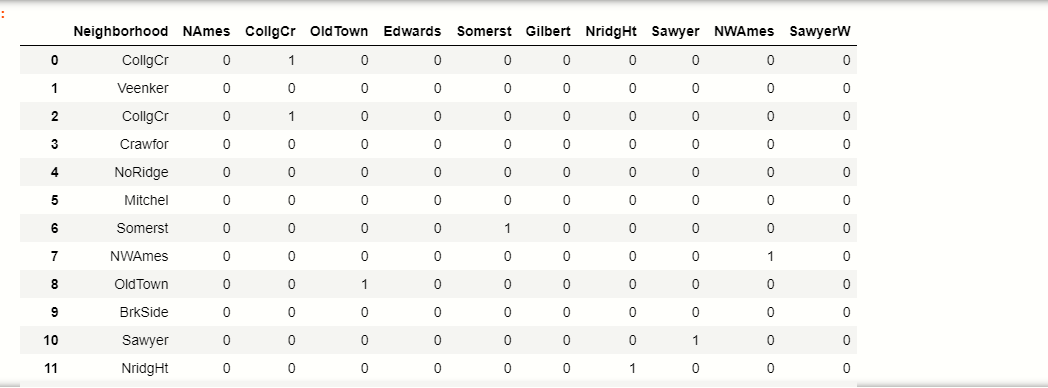
Ora, dobbiamo fare il 10 variabili binarie delle etichette top_10:
# creare etichette binarie
per tag in top_10:
new_df[etichetta] = np.dove (new_df['Quartiere']== etichetta, 1,0)
new_df[['Quartiere']+ top_10]
produzione:-
| nomi | CollgCr | Città vecchia | Edwards | Somerst | Gilbert | NridgHt | Sawyer | NWAmes | SawyerW | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CollgCr | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | Veenker | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | CollgCr | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | Crawfor | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | NoRidge | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | mitchell | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | Somerst | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7 | NWAmes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 8 | Città vecchia | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | BrkSide | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | Sawyer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 11 | NridgHt | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
Puoi vedere come i tag top_10 vengono ora convertiti in formato binario.
Facciamo un esempio, vedi nella tabella dove 1 indice Veenker che non apparteneva al nostro tag top_10 categorie, quindi risulterà in 0 tutte le colonne.
Ora lo faremo per tutte le variabili categoriali che abbiamo selezionato in precedenza.
Tutte le variabili selezionate in OneHotEncoding
# per tutte le variabili categoriali che abbiamo selezionato
def top_x(df2, variabile,top_x_labels):
per l'etichetta in top_x_labels:
df2[variabile+'_'+etichetta] = np.dove(dati[variabile]==etichetta,1,0)
# rileggi i dati
data = pd.read_csv('D://xdatasets/train.csv',usecols = ['Quartiere','Esterno1°','Esterno2°'])
#codificare il quartiere nel 10 categorie più frequenti
top_x(dati,'Quartiere',top_10)
# mostra dati
data.head()
Produzione:-

Ora, qui applichiamo la codifica one-hot su tutte le variabili multicategoria.
Ora vedremo i vantaggi e gli svantaggi di One Hot Encoding per più variabili.
Vantaggio
- Facile da implementare
- Non richiede molto tempo per l'esplorazione delle variabili.
- Non espande enormemente lo spazio delle funzionalità.
Svantaggi
- Non aggiunge alcuna informazione che potrebbe rendere la variabile più predittiva
- Non salvare informazioni sulle variabili ignorate.
Note finali
Quindi, il riassunto di questo è che impariamo come gestire le variabili di più categorie. Se riscontri questo problema, quindi questo è un compito molto difficile. Quindi grazie per aver letto questo articolo..
Connettiti con me su Linkedin: Profilo
Leggi i miei altri articoli: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Grazie
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





