Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Nel mio articolo precedente, hablo sobre los conceptos teóricos sobre los valores atípicos y trato de encontrar la respuesta a la pregunta: “¿Cuándo tenemos que eliminar los valores atípicos y cuándo mantener los valores atípicos?”.
Para comprender mejor este artículo, primero debe leer que Articolo y luego continúe con esto para que tenga una idea clara sobre el análisis de valores atípicos en Proyectos de ciencia de datos.
In questo articolo, intentaremos dar respuesta a las siguientes preguntas junto con la Chiodo implementazione,
? ¿Cómo tratar los valores atípicos?
? ¿Cómo detectar valores atípicos?
? ¿Cuáles son las técnicas para la detección y eliminación de valores atípicos?
Cominciamo
¿Cómo tratar los valores atípicos?
? Guarnición: Excluye los valores atípicos. de nuestro análisis. Aplicando esta técnica nuestro los datos se vuelven delgados cuando hay más valores atípicos presentes en el conjunto de datos. Su principal ventaja es su lo más rápido natura.
?Taponamiento: In questa tecnica, Cap nuestro datos atípicos y haga el límite vale a dire, por encima de un valor particular o por debajo de ese valor, todos los valores se considerarán valores atípicos, y el número de valores atípicos en el conjunto de datos da ese número de límite.
Ad esempio, Si está trabajando en la función de ingresos, es posible que las personas que superen un cierto nivel de ingresos se comporten de la misma manera que las que tienen ingresos más bajos. In questo caso, puede limitar el valor de los ingresos a un nivel que lo mantenga intacto y, Di conseguenza, tratar los valores atípicos.
?Trate los valores atípicos como un valor faltante: Di suponiendo valores atípicos como las observaciones faltantes, trátelos en consecuencia, vale a dire, iguales a los valores faltantes.
Puede consultar el artículo de valor faltante qui
? Discretizzazione: In questa tecnica, al hacer los grupos incluimos los valores atípicos en un grupo en particular y los obligamos a comportarse de la misma manera que los de otros puntos de ese grupo. Questa tecnica è anche conosciuta come Binning.
Puedes aprender más sobre discretización qui.
¿Cómo detectar valores atípicos?
? Para distribuciones normales: Utilice relaciones empíricas de distribución normal.
– Los puntos de datos que se encuentran debajo media-3 * (sigma) o por encima media + 3 * (sigma) son valores atípicos.
donde mean y sigma son los valor promedio e Deviazione standard de una columna en particular.
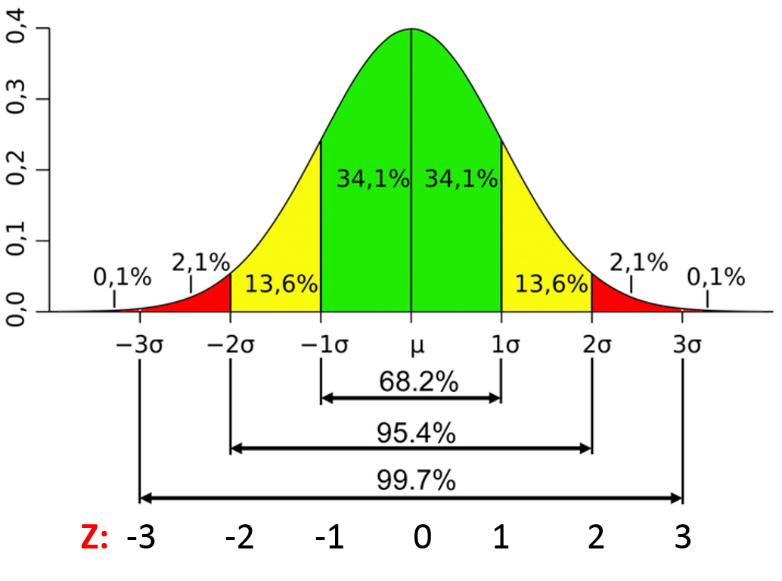
Fig. Características de una distribución normal
Fonte immagine: Collegamento
? Para distribuciones sesgadas: Utilice la regla de proximidad Inter-Quartile Range (IQR).
– Los puntos de datos que se encuentran debajo Q1 – 1.5 IQR o por encima Q3 + 1.5 IQR son valores atípicos.
donde Q1 y Q3 son los 25 e Percentile 75 del conjunto de datos respectivamente, y IQR representa el rango intercuartil y está dado por Q3 – Q1.
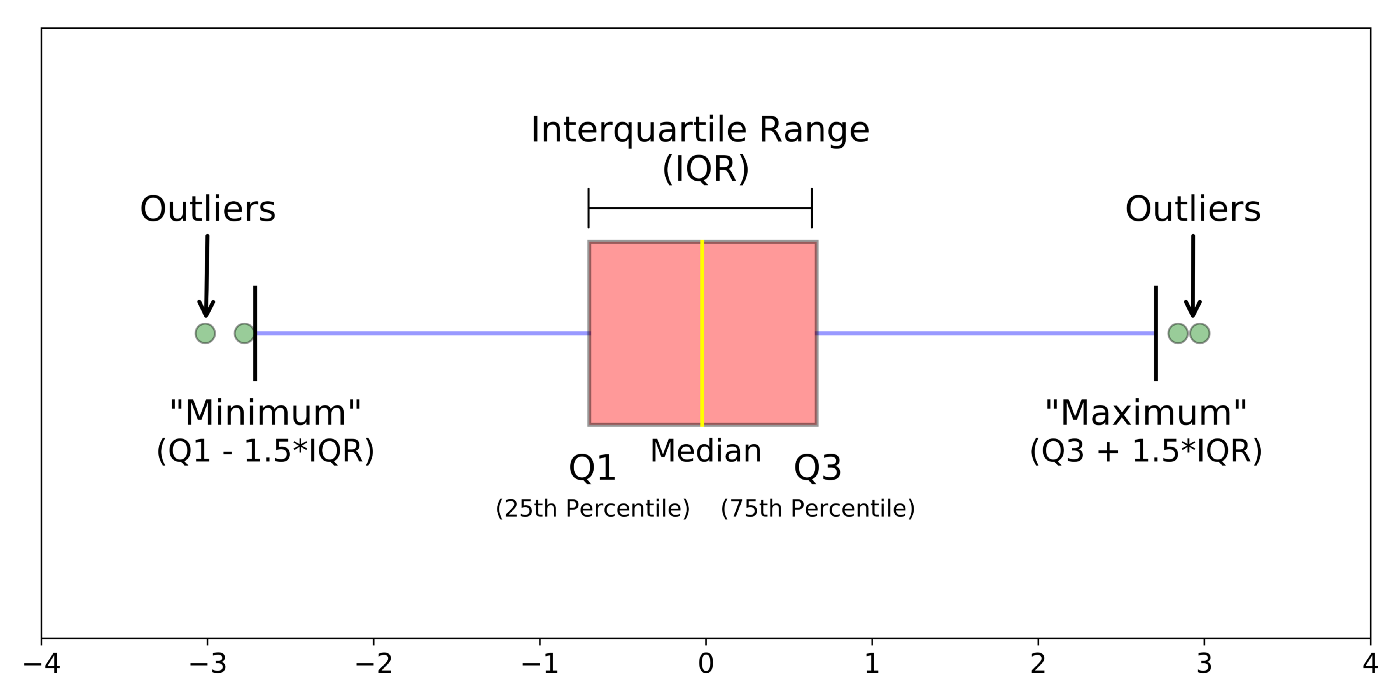
Fig. IQR per rilevare valori anomali
Fonte immagine: Collegamento
? Para otras distribuciones: Usare enfoque basado en percentiles.
Ad esempio, Los puntos de datos que están lejos del percentil 99% y menos del percentil 1 se consideran valores atípicos.
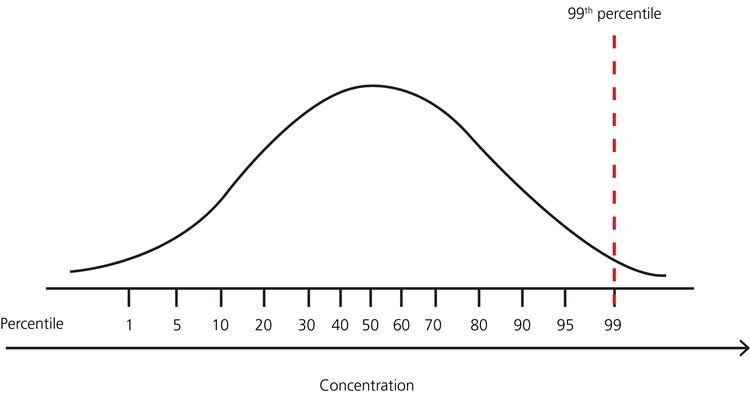
Fig. Representación percentil
Fonte immagine: Collegamento
Técnicas para la detección y eliminación de valores atípicos:
? Tratamiento de puntuación Z:
Suposición– Las características están distribuidas normal o aproximadamente normalmente.
passo 1: Importación de las dependencias necesarias
importa numpy come np importa panda come pd importa matplotlib.pyplot come plt import seaborn come sns
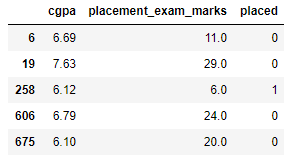
passo 2: leer y cargar el conjunto de datos
df = pd.read_csv('placement.csv')
df.campione(5)
passo 3: Trace las gráficas de distribución para las características
import warnings warnings.filterwarnings('ignorare') plt.figure(figsize=(16,5)) plt.sottotrama(1,2,1) sns.distplot(df['cgpa']) plt.sottotrama(1,2,2) sns.distplot(df['placement_exam_marks']) plt.mostra()
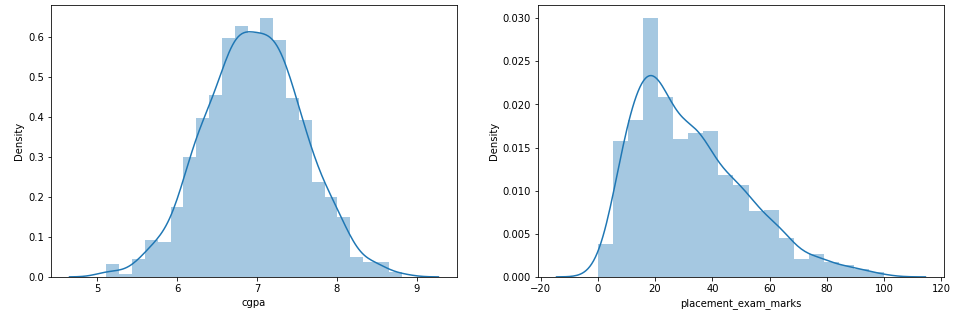
passo 4: encontrar los valores límite
Stampa("Highest allowed",df['cgpa'].Significare() + 3*df['cgpa'].standard())
Stampa("Lowest allowed",df['cgpa'].Significare() - 3*df['cgpa'].standard())
Produzione:
Highest allowed 8.808933625397177 Lowest allowed 5.113546374602842
passo 5: encontrar los valores atípicos
df[(df['cgpa'] > 8.80) | (df['cgpa'] < 5.11)]
passo 6: Recorte de valores atípicos
new_df = df[(df['cgpa'] < 8.80) & (df['cgpa'] > 5.11)] new_df
passo 7: limitación de valores atípicos
upper_limit = df['cgpa'].Significare() + 3*df['cgpa'].standard() lower_limit = df['cgpa'].Significare() - 3*df['cgpa'].standard()
passo 8: Ora, aplique la tapa
df['cgpa'] = np.dove( df['cgpa']>upper_limit, upper_limit, np.dove( df['cgpa']<lower_limit, lower_limit, df['cgpa'] ) )
passo 9: ahora vea las estadísticas usando la función “Describir”
df['cgpa'].descrivere()
Produzione:
contare 1000.000000
Significare 6.961499
standard 0.612688
min 5.113546
25% 6.550000
50% 6.960000
75% 7.370000
max 8.808934
Nome: cgpa, dtype: float64
¡Esto completa nuestra técnica basada en puntaje Z!
? Filtrado basado en IQR:
Se usa cuando nuestra distribución de datos está sesgada.
passo 1: Importare le dipendenze necessarie
importa numpy come np importa panda come pd importa matplotlib.pyplot come plt import seaborn come sns
passo 2: leer y cargar el conjunto de datos
df = pd.read_csv('placement.csv')
df.head()
passo 3: Trace la gráfica de distribución de las características.
plt.figure(figsize=(16,5)) plt.sottotrama(1,2,1) sns.distplot(df['cgpa']) plt.sottotrama(1,2,2) sns.distplot(df['placement_exam_marks']) plt.mostra()
passo 4: Forme un diagrama de caja para la característica sesgada
sns.boxplot(df['placement_exam_marks'])
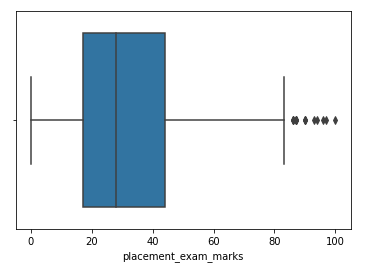
passo 5: Encontrar el IQR
percentile25 = df['placement_exam_marks'].Quantile(0.25) percentile75 = df['placement_exam_marks'].Quantile(0.75)
passo 6: Encontrar el límite superior e inferior
upper_limit = percentile75 + 1.5 * iqr lower_limit = percentile25 - 1.5 * iqr
passo 7: encontrar valores atípicos
df[df['placement_exam_marks'] > upper_limit] df[df['placement_exam_marks'] < lower_limit]
passo 8: Ritagliare
new_df = df[df['placement_exam_marks'] < upper_limit] new_df.shape
passo 9: Compare las parcelas después de recortar
plt.figure(figsize=(16,8)) plt.sottotrama(2,2,1) sns.distplot(df['placement_exam_marks']) plt.sottotrama(2,2,2) sns.boxplot(df['placement_exam_marks']) plt.sottotrama(2,2,3) sns.distplot(new_df['placement_exam_marks']) plt.sottotrama(2,2,4) sns.boxplot(new_df['placement_exam_marks']) plt.mostra()
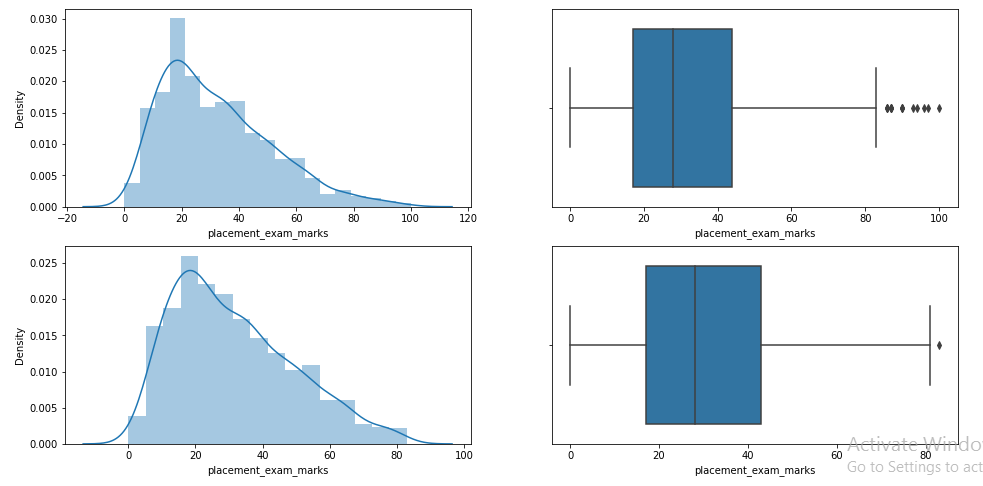
passo 10: taponado
new_df_cap = df.copy() new_df_cap['placement_exam_marks'] = np.dove( new_df_cap['placement_exam_marks'] > upper_limit, upper_limit, np.dove( new_df_cap['placement_exam_marks'] < lower_limit, lower_limit, new_df_cap['placement_exam_marks'] ) )
passo 11: Compare las parcelas después de la limitación
plt.figure(figsize=(16,8)) plt.sottotrama(2,2,1) sns.distplot(df['placement_exam_marks']) plt.sottotrama(2,2,2) sns.boxplot(df['placement_exam_marks']) plt.sottotrama(2,2,3) sns.distplot(new_df_cap['placement_exam_marks']) plt.sottotrama(2,2,4) sns.boxplot(new_df_cap['placement_exam_marks']) plt.mostra()
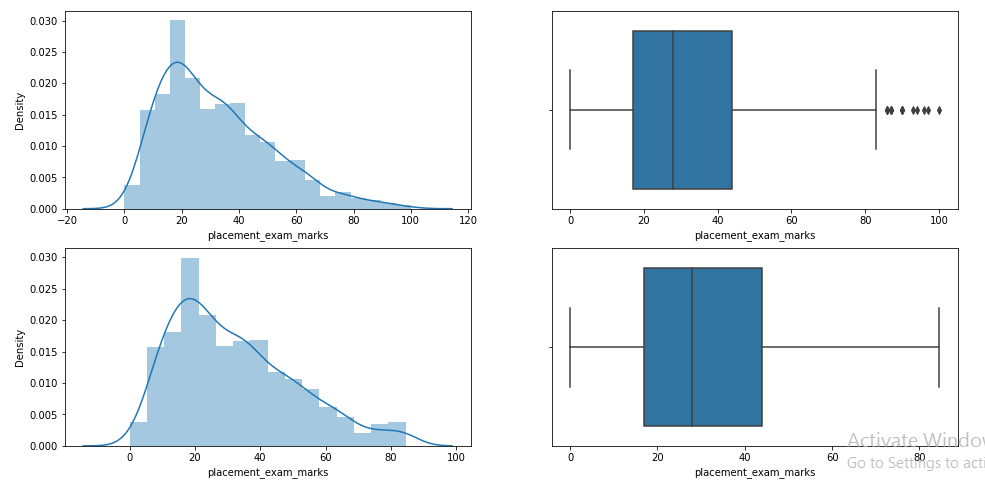
¡Esto completa nuestra técnica basada en IQR!
? Percentile:
– Esta técnica funciona estableciendo un valor de umbral particular, que decide en función de nuestro planteamiento del problema.
– Si bien eliminamos los valores atípicos mediante la limitación, ese método en particular se conoce como Winsorización.
– Aquí siempre mantenemos simetría en ambos lados significa que si eliminamos el 1% de la derecha, entonces en la izquierda también disminuimos un 1%.
passo 1: Importare le dipendenze necessarie
importa numpy come np importa panda come pd
passo 2: leer y cargar el conjunto de datos
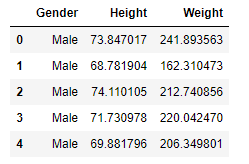
df = pd.read_csv('weight-height.csv')
df.campione(5)
passo 3: Trace la gráfica de distribución de la característica de “altezza”
sns.distplot(df['Altezza'])
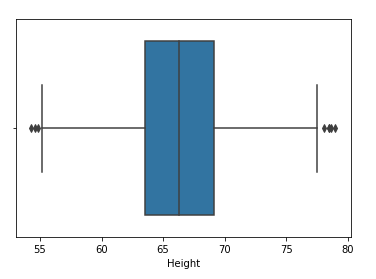
passo 4: Trace el diagrama de caja de la característica de “altezza”
sns.boxplot(df['Altezza'])
passo 5: Encontrar el límite superior e inferior
upper_limit = df['Altezza'].Quantile(0.99) lower_limit = df['Altezza'].Quantile(0.01)
passo 7: aplique el recorte
new_df = df[(df['Altezza'] <= 74.78) & (df['Altezza'] >= 58.13)]
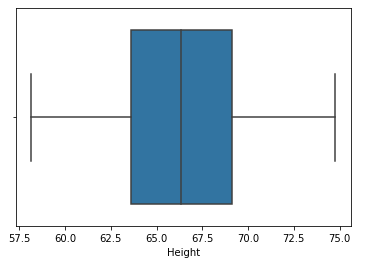
passo 8: Compare la distribución y el diagrama de caja después de recortar
sns.distplot(new_df['Altezza']) sns.boxplot(new_df['Altezza'])
? Winsorización:
passo 9: Aplicar limitación (Winsorización)
df['Altezza'] = np.dove(df['Altezza'] >= upper_limit, upper_limit, np.dove(df['Altezza'] <= lower_limit, lower_limit, df['Altezza']))
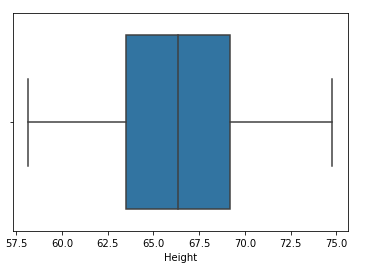
passo 10: Compare la distribución y el diagrama de caja después de la limitación
sns.distplot(df['Altezza']) sns.boxplot(df['Altezza'])
¡Esto completa nuestra técnica basada en percentiles!
Note finali
Grazie per aver letto!
Se ti è piaciuto e vuoi saperne di più, visita gli altri miei articoli sulla scienza dei dati e sull'apprendimento automatico facendo clic su Collegamento
Sentiti libero di contattarmi a Linkedin, E-mail.
Tutto ciò che non è stato menzionato o vuoi condividere i tuoi pensieri? Sentiti libero di commentare qui sotto e ti ricontatterò.
Circa l'autore
Chirag Goyal
Attualmente, Sto perseguendo il mio Bachelor of Technology (B.Tech) in informatica e ingegneria da Istituto indiano di tecnologia Jodhpur (IITJ). Sono molto entusiasta dell'apprendimento automatico, il apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... e intelligenza artificiale.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





