Nel mio articolo precedente, abbiamo discusso “hCome usare QVD per rendere la tua applicazione QlikView più efficiente?". In questo articolo, faremo un passo avanti per rendere la nostra applicazione più efficiente quando si tratta di grandi dati transazionali. Come ho detto nel mio precedente articolo, Stavo lavorando su un'applicazione QlikView, dove dovevo mostrare le vendite su più canali per frequenze predefinite (ad esempio, Quotidiano, Mensile, Annualmente).
Inizialmente, Stavo ricaricando l'intera tabella delle transazioni su base giornaliera, anche se avevo già i dati fino a ieri con me. Questo non solo ha richiesto molto tempo, sino que también aumentó la carga en el servidor de la Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... y la red. È qui che il caricamento incrementale con QVD ha fatto una grande differenza caricando solo i dati nuovi o aggiornati dal database in una tabella.
Carichi incrementali:
Il carico incrementale è definito come l'attività di caricare solo record nuovi o aggiornati dal database in un QVD established stabilito. I carichi incrementali sono utili perché funzionano in modo molto efficiente rispetto ai carichi completi, in particolare per grandi set di dati.
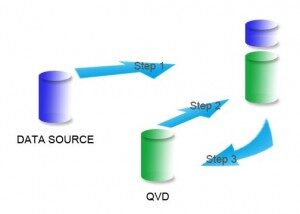
Il caricamento incrementale può essere implementato in diversi modi, i metodi comuni sono i seguenti:
- Inserisci solo (non convalidare per i record duplicati)
- Inserisci e aggiorna
- Inserire, aggiorna ed elimina
Comprendiamo ognuno di questi 3 scenari con un esempio
1. Inserisci solo:
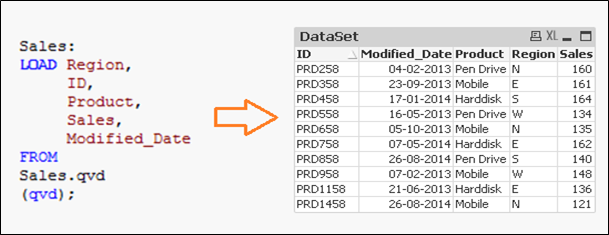
Diciamo che abbiamo dati di vendita grezzi (in excel) e ogni volta che viene registrata una nuova vendita, viene aggiornato con i dettagli di base sulla vendita entro la data di modifica. Dal momento che stiamo lavorando su QVD, Abbiamo già creato QVD fino a ieri (25 agosto 2014 in questo caso). Ora, Voglio caricare solo i record incrementali (evidenziato in giallo sotto).
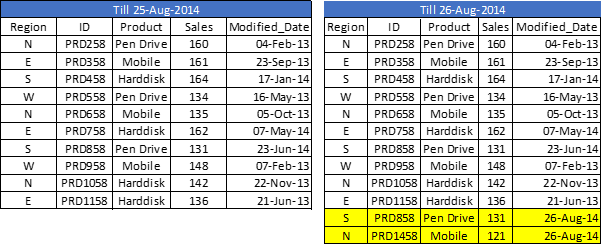
Per eseguire questo esercizio, prima creare un QVD per i dati fino a 25 agosto 2014. Per identificare nuovi record incrementali, dobbiamo sapere la data fino alla quale, QVD è già aggiornato. Questo può essere identificato controllando il massimo di Modified_date nel file QVD disponibile.
Come menzionato prima, ho pensato che “Saldi. qvd”È aggiornato con dati fino a 25 agosto 2014. Per identificare la data dell'ultima modifica del “Saldi. qvd", Il seguente codice può aiutare:
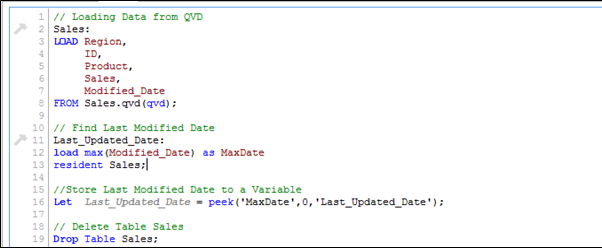
Qui, Ho caricato in memoria l'ultimo QVD aggiornato e poi ho individuato la data dell'ultima modifica memorizzando un massimo di “Data di modifica". Prossimo, almacenamos esta fecha en una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... “Last_Updated_Date“E lascia cadere il tavolo”Saldi". Nel codice sopra, ho usato Aspetto() funzione per memorizzare la data massima di modifica. Ecco la tua sintassi:
Sbirciare (nome del campo, numero di riga, nome della tabella)
Questa funzione restituisce il contenuto di un dato campo per una riga specificata dalla tabella interna. FieldName e TableName devono essere forniti come stringa e Row deve essere un numero intero. 0 denota il primo record, 1 il secondo e così via. I numeri negativi indicano l'ordine dalla fine della tabella. -1 denota l'ultimo record.
Poiché conosciamo la data dopo la quale i record saranno considerati nuovi record, possiamo caricare record incrementali dal set di dati (clausola In cui si"DOVE" è un termine in inglese che si traduce come "dove" in spagnolo. Utilizzato per porre domande sulla posizione delle persone, Oggetti o eventi. In contesti grammaticali, Può funzionare come avverbio di luogo ed è fondamentale nella formazione delle domande. La sua corretta applicazione è essenziale nella comunicazione quotidiana e nell'insegnamento delle lingue, facilitare la comprensione e lo scambio di informazioni su posizioni e direzioni.... en la instrucción Load) e uniscili con QVD . disponibile (guarda l'istantanea qui sotto).
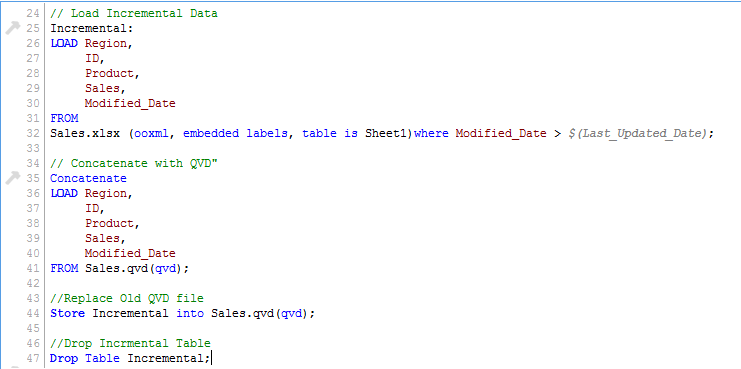
Ora, carica QVD aggiornato (Saldi), avrebbe record incrementali.
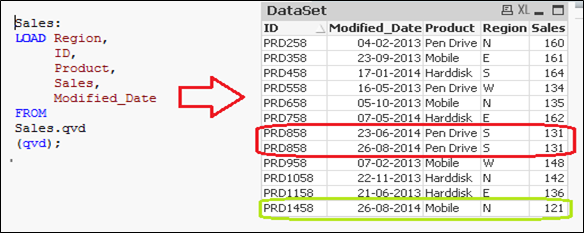
Come potete vedere, sono stati aggiunti due record da 26 agosto 2014. tuttavia, abbiamo anche inserito un record duplicato. Ora possiamo dire che un metodo solo INSERT non convalida i record duplicati perché non abbiamo avuto accesso ai record disponibili.
Cosa c'è di più, in questo metodo non possiamo aggiornare il valore dei record esistenti.
Per riassumere, los siguientes son los pasos para cargar solo los registros incrementales en QVD usando el método INSERIREIl termine "INSERIRE" se refiere a la acción de agregar datos en una base de datos o sistema. En el contexto de programación, se utiliza comúnmente en lenguajes SQL para insertar nuevas filas en una tabla. Este proceso es fundamental para mantener la integridad y actualización de la información. Un uso adecuado de la instrucción INSERT contribuye a la eficiencia y efectividad en la gestión de datos.... soltanto:
1) Identifica nuovi record e caricali
2) Concatena questi dati con un file QVD
3) Sostituisci il vecchio file QVD con una nuova tabella concatenata
2. Inserisci e aggiorna il metodo:
Come visto nell'esempio precedente, non siamo in grado di eseguire il controllo del record duplicato e aggiornare il record esistente. Qui è dove, il metodo di inserimento e aggiornamento viene in aiuto:
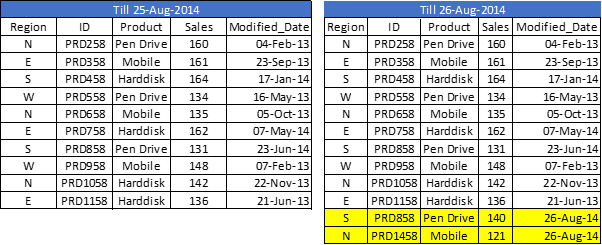
Nel set di dati sopra (tavolo giusto), abbiamo un record (ID = PRD1458) da aggiungere e un altro (ID = PRD858) attualizzare (valore di vendita di 131 un 140). Ora, per aggiornare e verificare i record duplicati, abbiamo bisogno di una chiave primaria nel nostro set di dati.
Supponiamo che id sia la chiave primaria e, secondo la data di modifica e l'identificazione, dovremmo essere in grado di identificare e classificare i record nuovi o modificati.
Per eseguire questo metodo, seguire passaggi simili per identificare i nuovi record come abbiamo fatto nel metodo INSERT only e concatenando i dati incrementali con uno esistente, applichiamo il controllo dei record duplicati o aggiorniamo il valore dei record esistenti.
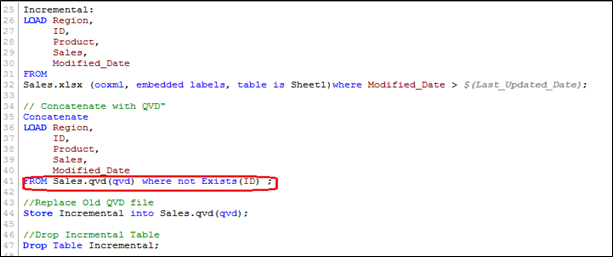
Qui, abbiamo caricato solo quei record in cui la chiave primaria (ID) è nuovo e utilizza la funzione Esiste () impedisce a QVD di caricare record obsoleti poiché la versione AGGIORNATA è attualmente in memoria, quindi i valori dei record esistenti vengono aggiornati automaticamente.
Ora, abbiamo tutti i record univoci disponibili in QVD con un valore di vendita aggiornato per ID (PRD858).
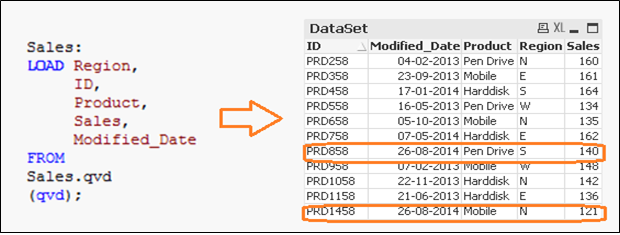
3. metodo INSERT, AGGIORNA ED ELIMINA:
Lo script per questo metodo è molto simile a INSERT & AGGIORNAREIl termine "AGGIORNARE" È comunemente usato in campo tecnologico e di comunicazione per riferirsi all'azione di aggiornamento delle informazioni, Software o sistemi. In un mondo in continua evoluzione, Gli aggiornamenti sono essenziali per migliorare la sicurezza, Correggi bug e aggiungi nuove funzionalità. Le aziende e gli utenti dovrebbero tenere d'occhio gli aggiornamenti disponibili per garantire prestazioni ottimali e mantenere l'integrità dei propri dispositivi e dati...., tuttavia, qui abbiamo un passaggio in più necessario per eliminare i record eliminati.
Caricheremo le chiavi primarie di tutti i record nel set di dati corrente e applicheremo un join interno con il set di dati concatenato (Antica + Incrementale). Il join interno manterrà solo i registri comuni e, così, cancellerà i record indesiderati. Supponiamo di voler eliminare un record da (ID PRD1058) nell'esempio sopra.
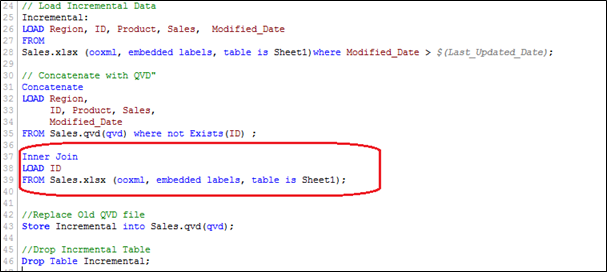
Qui, abbiamo un set di dati con l'aggiunta di un record (ID PRD1458), modificare un record (ID PRD158) e l'eliminazione di un record (ID PRD1058).
Note finali:
In questo articolo, abbiamo discusso di come i carichi incrementali siano migliori e forniscano un modo efficiente per caricare i dati rispetto al carico COMPLETO. Come buona pratica, dovresti avere un backup regolare dei tuoi dati perché potrebbe essere interessato o potrebbe verificarsi una perdita di dati, se ci sono problemi con il server del database e la rete.
A seconda del settore e della necessità dell'applicazione, puoi selezionare quale metodo funziona per te. La maggior parte delle applicazioni comuni nel settore BFSI si basa su Insert and Update. L'eliminazione dei record non viene normalmente utilizzata.
Hai affrontato una situazione simile o hai un altro trucco per migliorare l'efficienza delle applicazioni Qlikview sotto il tuo cappello?? Se è così, Mi piacerebbe sentire i tuoi pensieri attraverso i commenti qui sotto., in quanto avvantaggia anche qualcun altro che cerca di gestire una situazione simile.





