Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
w
- Este artículo le dará una comprensión básica de cómo funciona el análisis de texto.
- Conozca los distintos pasos del proceso de PNL
- Derivación del sentimiento general del texto.
- Tablero que muestra las estadísticas generales y el análisis de sentimientos del texto.
Abstracto
En esta era digital moderna, se genera una gran cantidad de información por segundo. La mayoría de los datos que los humanos generan a través de mensajes, tweet, blog, articoli di notizie, recomendaciones de productos y reseñas de WhatsApp no están estructurados. Quindi, para obtener información útil de estos datos altamente desestructurados, primero debemos convertirlos en forma estructurada y normalizada.
Elaborazione del linguaggio naturale (PNL) es una clase de inteligencia artificial que realiza una serie de procesos sobre estos datos no estructurados para obtener información significativa. El procesamiento del lenguaje es de naturaleza completamente no determinista porque el mismo lenguaje puede tener diferentes interpretaciones. Se vuelve tedioso porque algo adecuado para una persona no es adecuado para otra. Cosa c'è di più, el uso de lenguaje coloquial, acrónimos, hashtags con palabras adjuntas, emoticonos posee una sobrecarga para su preprocesamiento.
Si le interesa el poder de la analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche.... de redes sociales, este artículo es el punto de partida para usted. Este artículo cubre los conceptos básicos de análisis de texto y le proporciona un tutorial paso a paso para realizar el procesamiento del lenguaje natural sin el requisito de ningún conjunto de datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.....
Introducción a la PNL
El procesamiento del lenguaje natural es el subcampo de la inteligencia artificial que comprende procesos sistemáticos para convertir datos no estructurados en información significativa y extraer conocimientos útiles de los mismos. La PNL se clasifica además en dos categorías amplias: PNL basada en reglas y PNL estadístico. La PNL basada en reglas utiliza un razonamiento básico para procesar tareas, por lo que se requiere un esfuerzo manual sin mucho entrenamiento del conjunto de datos. La PNL estadística, In secondo luogo, entrena una gran cantidad de datos y obtiene información a partir de ellos. Utiliza algoritmos de aprendizaje automático para entrenar el mismo. In questo articolo, aprenderemos la PNL basada en reglas.
Applicazioni PNL:
- Riepilogo del testo
- Macchina del traduttore
- Sistemas de preguntas y respuestas
- Revisiones ortográficas
- Completamento automatico
- Analisi del sentimento
- Riconoscimento vocale
- SegmentazioneLa segmentazione è una tecnica di marketing chiave che comporta la divisione di un ampio mercato in gruppi più piccoli e omogenei. Questa pratica consente alle aziende di adattare le proprie strategie e i propri messaggi alle caratteristiche specifiche di ciascun segmento, migliorando così l'efficacia delle tue campagne. Il targeting può essere basato su criteri demografici, psicografico, geografico o comportamentale, facilitando una comunicazione più pertinente e personalizzata con il pubblico di destinazione.... de temas
Canalización de PNL:

La canalización de PNL se divide en cinco subtareas:
1. Análisis léxico: El análisis léxico es el proceso de analizar la estructura de palabras y frases presentes en el texto. El léxico se define como el fragmento identificable más pequeño del texto. Podría ser una palabra, frase, eccetera. Implica identificar y dividir todo el texto en oraciones, párrafos y palabras.
2. Analisi sintattica: El análisis sintáctico es el proceso de ordenar las palabras de una manera que muestre la relación entre las palabras. Implica analizarlos en busca de patrones gramaticales. Ad esempio, la oración “La universidad va para la niña”. es rechazado por el analizador sintáctico.
3. Analisi semantica: El análisis semántico es el proceso de analizar el texto para determinar su significado. Considera estructuras sintácticas para mapear los objetos en el dominio de la tarea. Ad esempio, la frase “Quiere comer helado caliente” es rechazada por el analizador semántico.
4. Integración de divulgación: La integración de la divulgación es el proceso de estudiar el contexto del texto. Las oraciones están organizadas en un orden significativo para formar un párrafo, lo que significa que la oración antes de una oración en particular es necesaria para comprender el significado general. Cosa c'è di più, la oración que sigue a la oración depende de la anterior.
5. Análisis pragmático: El análisis pragmático se define como el proceso de reconfirmar que lo que el texto realmente significaba es lo mismo que lo derivado.
Leyendo el archivo de texto:
filename = "C:UsersDellDesktopexample.txt" text = open(nome del file, "R").leggere()
Imprimir el texto:
Stampa(testo)

Instalación de la biblioteca para PNL:
Usaremos la biblioteca spaCy para este tutorial. spazio es una biblioteca de software de código abierto para PNL avanzada escrita en los lenguajes de programación Python y Cython. La biblioteca se publica bajo una licencia del MIT. A diferencia de NLTK, que se usa ampliamente para la enseñanza y la investigación, spaCy se enfoca en proporcionar software para uso en producción. spaCy también admite flujos de trabajo de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... que permiten conectar modelos estadísticos entrenados por bibliotecas de aprendizaje automático populares como TensorFlow, Pytorch a través de su propia biblioteca de aprendizaje automático Thinc.[Wikipedia]
pip install -U pip setuptools wheel
pip install -U spacy
Ya que estamos tratando con el idioma inglés. Entonces necesitamos instalar el en_core_web_sm paquete para ello.
python -m spacy download en_core_web_sm
Verificando que la descarga fue exitosa e importando el paquete spacy:
import spacy
nlp = spacy.load('en_core_web_sm')
Después de la creación exitosa del objeto NLP, podemos pasar al preprocesamiento.
Tokenizzazione:
La tokenización es el proceso de convertir todo el texto en una serie de palabras conocidas como tokens. Este es el primer paso en cualquier proceso de PNL. Divide todo el texto en unidades significativas.
text_doc = nlp(testo) Stampa ([token.text for token in text_doc])

Como podemos observar en los tokens, hay muchos espacios en blanco, virgole, palabras vacías que no sirven de nada desde una perspectiva de análisis.
Identificación de la oración
Identificar las oraciones del texto es útil cuando queremos configurar partes significativas del texto que ocurren juntas. Por eso es útil encontrar frases.
about_doc = nlp(about_text) sentences = list(about_doc.sents)

Rimozione di parole irrilevanti
Las palabras vacías se definen como palabras que aparecen con frecuencia en el lenguaje. No tienen ningún papel significativo en el análisis de texto y obstaculizan el análisis de distribución de frecuenciasLa distribución de frecuencias es una herramienta estadística que organiza y resume datos en intervalos o categorías, facilitando su análisis. Permite visualizar la frecuencia con la que ocurren diferentes valores en un conjunto de datos, ya sea mediante tablas o gráficos. Esta técnica es fundamental en la estadística descriptiva, ya que ayuda a identificar patrones, tendencias y la dispersión de los datos, apoyando la toma de decisiones informadas..... Ad esempio, il, un, un, oh, eccetera. Perciò, deben eliminarse del texto para obtener una imagen más clara del texto.
normalized_text = [token for token in text_doc if not token.is_stop] Stampa (normalized_text)

Eliminación de puntuación:
Como podemos ver en el resultado anterior, hay signos de puntuación que no nos sirven. Así que eliminémoslos.
clean_text = [token for token in normalized_text if not token.is_punct] Stampa (testo_pulito)

Lematizzazione:
La lematización es el proceso de reducir una palabra a su forma original. Lema es una palabra que representa un grupo de palabras llamadas lexemas. Ad esempio: participar, participar, participar. Todos se reducen a un lema común, vale a dire, participar.
for token in clean_text: Stampa (gettone, token.lemma_)
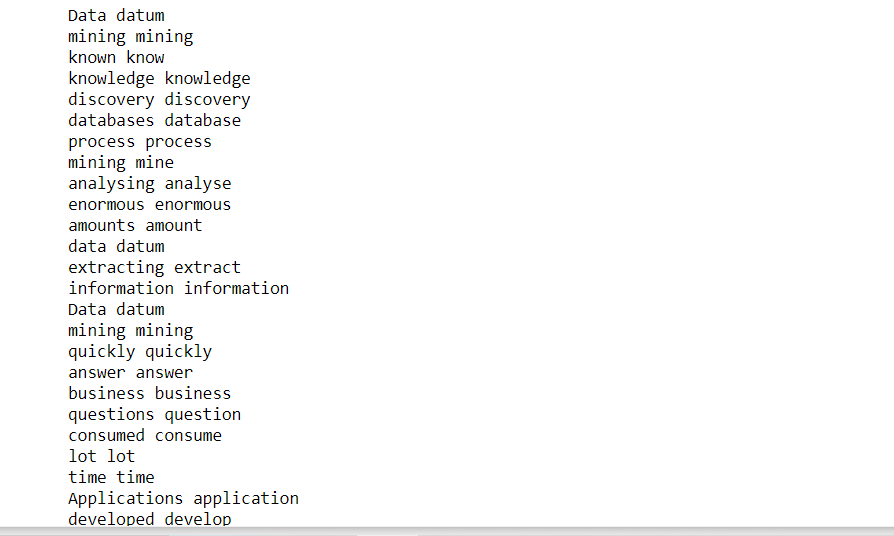
Recuento de frecuencia de palabras:
Realicemos ahora un análisis estadístico del texto. Encontraremos las diez primeras palabras según su frecuencia en el texto.
from collections import Counter words = [token.text for token in clean_text if not token.is_stop and not token.is_punct] word_freq = Counter(parole) # 10 commonly occurring words with their frequencies common_words = word_freq.most_common(10) Stampa (common_words)

Analisi del sentimento
El análisis de sentimiento es el proceso de analizar el sentimiento del texto. Una forma de hacerlo es a través de la polaridad de las palabras, ya sean positivas o negativas.
VADER (Valence Aware Dictionary and Sentiment Reasoner) es una biblioteca de análisis de sentimientos basada en reglas y léxico en Python. Utiliza una serie de léxicos de sentimientos. Un léxico de sentimiento es una serie de palabras que se asignan a sus respectivas polaridades, vale a dire, positivo, negativa y neutra de acuerdo con su significado semántico.
Ad esempio:
1. Palabras como bueno, grandioso, asombroso, fantástico son de polaridad positiva.
2. Palabras como malo, peor, patético son de polaridad negativa.
El analizador de sentimientos VADER encuentra los porcentajes de palabras de diferente polaridad y da puntuaciones de polaridad de cada una de ellas respectivamente. La salida del analizador se puntúa de 0 un 1, que se puede convertir en porcentajes. No solo habla de las puntuaciones de positividad o negatividad, sino también de lo positivo o negativo que es un sentimiento.
Primero descarguemos el paquete usando pip.
pip install vaderSentiment
Dopo, analice las puntuaciones de sentimiento.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
vs = analizzatore.polarity_scores(testo)
vs

PannelloUn panel è un gruppo di esperti che si riunisce per discutere e analizzare un argomento specifico. Questi forum sono comuni alle conferenze, seminari e dibattiti pubblici, dove i partecipanti condividono le loro conoscenze e prospettive. I pannelli possono riguardare una varietà di aree, Dalla scienza alla politica, e il suo obiettivo è quello di favorire lo scambio di idee e la riflessione critica tra i partecipanti.... de control del analizador de texto
Los pasos anteriores se pueden resumir para crear un tablero para el analizador de texto. Incluye la cantidad de palabras, la cantidad de caracteres, la cantidad de números, las N palabras principales, la intención del texto, la opinión general, la puntuación de la opinión positiva, la puntuación de la opinión negativa, la puntuación de la opinión neutral y el recuento de palabras de la opinión.
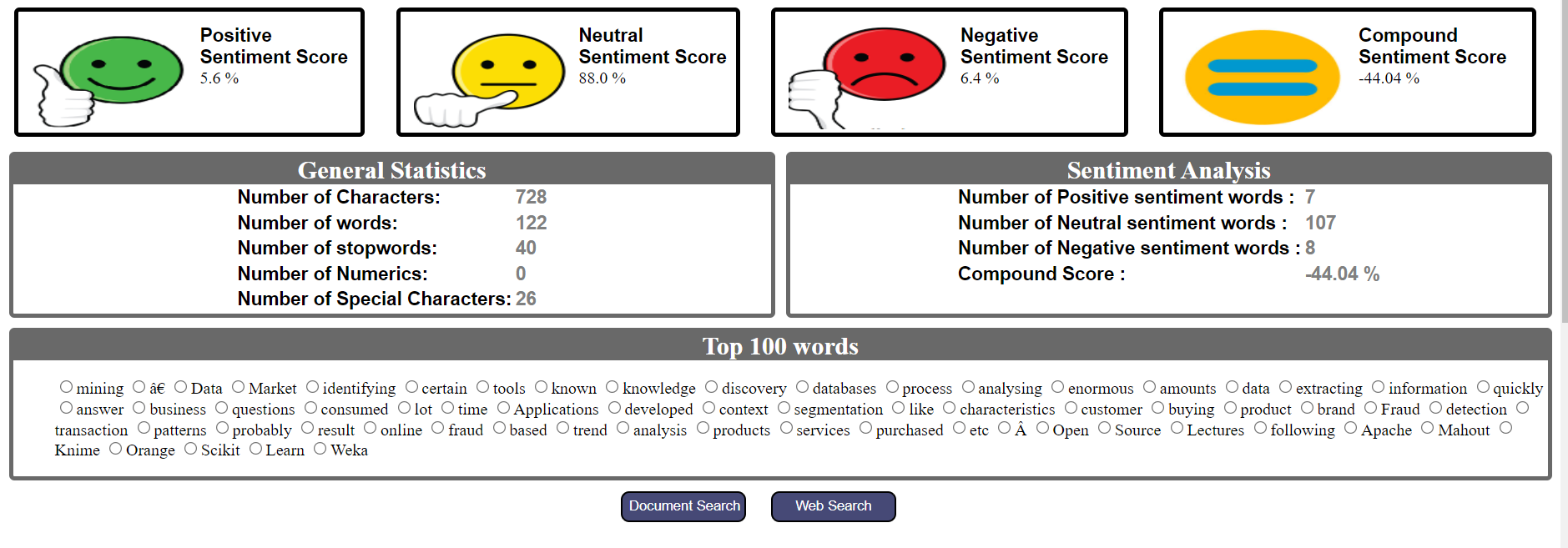
conclusione
La PNL ha tenido un gran impacto en campos como el análisis de reseñas de productos, consigli, analisi dei social media, traducción de texto y, così, ha obtenido enormes beneficios para las grandes empresas.
Espero que este artículo le ayude a comenzar su viaje en el campo de la PNL.
E infine, … Non c'è bisogno di dire,
Grazie per aver letto!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





