Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Ordine del giorno
Tutti noi abbiamo costruito una regressione logistica ad un certo punto della nostra vita. Anche se non abbiamo mai costruito un modello, Abbiamo sicuramente imparato questa tecnica di modellazione predittiva teoricamente. Due concetti semplici e sottovalutati utilizzati nella fase di pre-elaborazione per costruire un modello di regressione logistica sono il peso dell'evidenza e il valore delle informazioni. Vorrei riportarli sotto i riflettori attraverso questo articolo.
Questo articolo è strutturato come segue:
- Introduzione alla regressione logistica
- Importanza della selezione delle caratteristiche
- Necessità di un buon imputer per le caratteristiche categoriali
- AFFLIZIONE
- IV
Cominciamo!
1. Introduzione alla regressione logistica
Il primo è il primo, Sappiamo tutti che la regressione logistica è un problema di classificazione. In particolare, Consideriamo qui i problemi della classificazione binaria.
I modelli di regressione logistica prendono come input e output sia dati categorici che numerici per la probabilità di accadimento dell'evento.
Esempi di affermazioni di problemi che possono essere risolte con questo metodo sono:
- Dati i dati del cliente, Qual è la probabilità che il cliente acquisti un nuovo prodotto presentato da un'azienda??
- Dati i dati richiesti, Qual è la probabilità che un cliente bancario non rimborsi un prestito??
- Dati i dati meteorologici dell'ultimo mese, Qual è la possibilità di pioggia domani??
Tutte le affermazioni di cui sopra hanno avuto due risultati. (Compra e non compra, Default e non default, pioggia e non pioggia). Perciò, È possibile costruire un modello di regressione logistica binaria. La regressione logistica è un metodo parametrico. Cosa significa?? Un metodo parametrico ha due passaggi.
1. Primo, assumiamo una forma o una forma funzionale. In caso di regressione logistica, Partiamo dal presupposto che

2. Dobbiamo prevedere i pesi / coefficienti BI in modo che, La probabilità di un evento per un'osservazione X è vicina a 1 Se il valore effettivo dell'obiettivo è 1 e la probabilità è vicina a 0 Se il valore effettivo dell'obiettivo è 0.
Con questa comprensione di base, Cerchiamo di capire perché abbiamo bisogno della selezione delle funzionalità.
2. Importanza della selezione delle caratteristiche
Nell'era digitale, Siamo dotati di un'enorme quantità di dati. tuttavia, Non tutte le funzioni a nostra disposizione sono utili in tutte le previsioni del modello. Abbiamo tutti sentito il detto "Entra nella spazzatura, la spazzatura esce!". Perciò, La scelta delle caratteristiche giuste per il nostro modello è della massima importanza. Le funzioni vengono selezionate in base alla forza predittiva della funzione.
Ad esempio, Supponiamo di voler prevedere la probabilità che una persona acquisti una nuova ricetta di pollo nel nostro ristorante. Se abbiamo un: “Preferenze alimentari” con valori {Vegetariano, Non vegetariano, Eggetariano}, Siamo quasi certi che questa funzione separerà chiaramente le persone che hanno maggiori possibilità di acquistare questo nuovo piatto da quelle che non lo acquisteranno mai. . Perciò, Questa funzione ha un elevato potere predittivo.
Possiamo quantificare il potere predittivo di una feature utilizzando il concetto di valore informativo che verrà qui descritto.
3. Necessità di un buon imputer per le funzioni categoriali
La regressione logistica è un metodo parametrico che richiede di calcolare un'equazione lineare. Ciò richiede che tutte le caratteristiche siano numeriche. tuttavia, Potremmo avere caratteristiche categoriche nei nostri set di dati che sono nominali o ordinali. Esistono molti metodi di imputazione, come la codifica one-hot o semplicemente l'assegnazione di un numero a ciascuna classe di caratteristiche categoriche. Ognuno di questi metodi ha i suoi meriti e demeriti. tuttavia, Non parlerò della stessa cosa qui.
In caso di regressione logistica, possiamo usare il concetto di WoE (Peso dell'evidenza) per imputare caratteristiche categoriali.
4. Forza probatoria
Dopo tutte le informazioni di base fornite, Siamo finalmente arrivati all'argomento del giorno!
La formula per calcolare il peso probante dell'evidenza di una caratteristica è data da
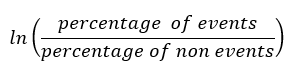
Prima di passare a spiegare l'intuizione alla base di questa formula, Facciamo un esempio fittizio:
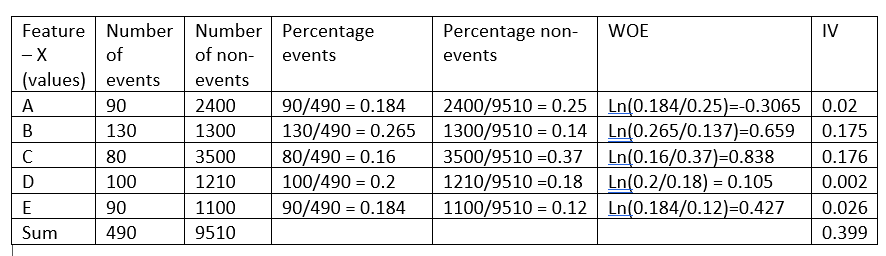
Il peso dell'evidenza indica il potere predittivo di una singola caratteristica rispetto alla sua caratteristica indipendente. Se una delle categorie / I contenitori di una feature hanno un'elevata percentuale di eventi rispetto alla proporzione di non eventi, otterremo un alto valore di WoE che a sua volta dice che questo tipo di funzionalità separa gli eventi dai non-eventi. .
Ad esempio, si consideri la categoria C della caratteristica X nell'esempio precedente, la proporzione degli eventi (0,16) è molto piccola rispetto alla percentuale di non-eventi (0,37). Ciò implica che se il valore della caratteristica X è C, È più probabile che il valore target sia 0 (Nessun evento). Il valore WoE ci dice solo quanto siamo sicuri che la funzione ci aiuterà a prevedere correttamente la probabilità di un evento.
Ora che sappiamo che WoE misura il potere predittivo di ogni contenitore / Categoria di una feature, Quali sono gli altri vantaggi di WoE?
1. Los valores de WoE para las diversas categorías de una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... categórica se pueden utilizar para imputar una característica categórica y convertirla en una característica numérica, poiché un modello di regressione logistica richiede che tutte le sue caratteristiche siano numeriche.
Esaminando attentamente la formula WoE e l'equazione di regressione logistica da risolvere, vediamo che WoE di una caratteristica ha una relazione lineare con le probabilità logaritmiche. Ciò garantisce che il requisito che le caratteristiche abbiano una relazione lineare con le probabilità logaritmiche sia soddisfatto.
2. Per lo stesso motivo del precedente, se una caratteristica continua non ha una relazione lineare con le probabilità di registrazione, la funzione può essere raggruppata in gruppi e una funzione appena creata può essere utilizzata sostituendo ogni contenitore con il suo valore WoE invece della funzione originale. Perciò, WoE è un buon metodo per trasformare le variabili per la regressione logistica.
3. Disponendo un elemento numerico in ordine crescente, se i valori di WoE sono tutti lineari, Sappiamo che l'elemento ha la corretta relazione lineare con l'obiettivo. tuttavia, se il WoE della funzione non è lineare, dobbiamo scartarlo o prendere in considerazione qualche altra trasformazione di variabile per garantire la linearità. Perciò, WoE ci fornisce uno strumento per verificare la relazione lineare con la caratteristica dipendente.
4. WoE è migliore della codifica one-hot poiché la codifica one-hot richiederà la creazione di nuove funzionalità h-1 per ospitare una funzionalità categorica con categorie h. Ciò implica che il modello non dovrà prevedere i coefficienti h-1 (con un) invece di 1. tuttavia, nella trasformazione della variabile WoE, Dovremo calcolare un coefficiente univoco per la caratteristica in esame.
5. Valore delle informazioni
Dopo aver discusso il valore di WoE, il valore WoE ci dice il potere predittivo di ogni bin di una feature. tuttavia, Un singolo valore che rappresenta la potenza predittiva dell'intera funzionalità sarà utile nella selezione delle caratteristiche.
L'equazione per IV è
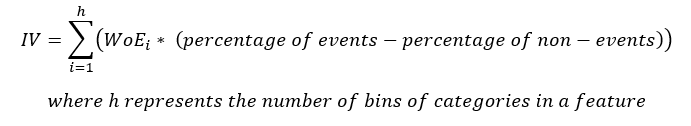
Si noti che il termine (Percentuale di eventi – la percentuale di non-eventi) segue lo stesso segno di WoE, così, fa in modo che l'IV sia sempre un numero positivo.
Come interpretiamo il valore di IV??
La tabella seguente fornisce un righello fisso per aiutarti a selezionare le caratteristiche migliori per il tuo modello
| Valore delle informazioni | Potere predittivo |
| <0.02 | Inutile |
| 0,02 fino a 0,1 | Predittori deboli |
| 0,1 fino a 0,3 | Predittori medi |
| 0,3 fino a 0,5 | Forti predittori |
| > 0,5 | Sospettoso |
Come si vede nell'esempio precedente, L'elemento X ha un valore informativo pari a 0.399, rendendolo un forte predittore e, così, verrà utilizzato nel modello.
6. conclusione
Come si vede nell'esempio precedente, il calcolo di WoE e IV sono utili e ci aiutano ad analizzare più punti come elencato di seguito.
1. WoE consente di verificare la relazione lineare di una feature con la feature dipendente da utilizzare nel modello.
2. WoE è un buon metodo per trasformare le variabili per funzionalità continue e categoriche.
3. WoE è meglio dell'hot coding, poiché questo metodo di trasformazione delle variabili non aumenta la complessità del modello.
4. IV es una buena misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... del poder predictivo de una característica y también ayuda a señalar la característica sospechosa.
Anche se WoE e IV sono molto utili, Assicurarsi sempre che venga utilizzato solo con la regressione logistica. A differenza di altri metodi di selezione delle feature disponibili, le feature selezionate da IV potrebbero non essere il miglior set di feature per la costruzione di un modello non lineare.
Spero che questo articolo ti abbia aiutato a intuire come funzionano WoE e IV.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





