Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Ricorrente neuronale rossoReti neurali ricorrenti (RNN) sono un tipo di architettura di rete neurale progettata per elaborare flussi di dati. A differenza delle reti neurali tradizionali, Le RNN utilizzano connessioni interne che consentono di ricordare le informazioni delle voci precedenti. Questo li rende particolarmente utili in attività come l'elaborazione del linguaggio naturale, Traduzione automatica e analisi di serie storiche, dove il contesto e la sequenza sono centrali per il... (RNN) fue uno de los mejores conceptos introducidos que podría hacer uso de elementos de memoria en nuestra neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti... Prima di ciò, avevamo una rete neurale che poteva propagarsi avanti e indietro per aggiornare i pesi e ridurre gli errori nella rete. Ma, come sappiamo, molti problemi nel mondo reale sono di natura temporanea e altamente dipendenti dal tempo.
Molte app linguistiche sono sempre sequenziali e la parola successiva in una frase dipende dalla precedente. Questi problemi sono stati risolti da un semplice RNN. Ma se capiamo RNN, apprezziamo il fatto che anche RNN non possa aiutarci quando vogliamo tenere traccia delle parole che sono state precedentemente utilizzate nella nostra frase. In questo articolo, Discuterò alcuni dei principali svantaggi di RNN e perché utilizziamo un modello migliore per la maggior parte delle applicazioni basate sul linguaggio.
Comprendere la retropropagazione nel tempo (BPTT)
RNN utiliza una técnica llamada Propagazione inversaLa retropropagación es un algoritmo fundamental en el entrenamiento de redes neuronales artificiales. Se basa en el principio del descenso del gradiente, permitiendo ajustar los pesos de la red para minimizar el error en las predicciones. A través de la propagación del error desde la capa de salida hacia las capas anteriores, este método optimiza el aprendizaje de la red, mejorando su capacidad para generalizar en datos no vistos.... a través del tiempo para retropropagar a través de la red para ajustar sus pesos para que podamos reducir el error en la red. Ha preso il suo nome “attraverso il tempo”, visto che in RNN ci occupiamo di dati sequenziali e ogni volta che torniamo indietro è come tornare indietro nel tempo al passato. Ecco come funziona BPTT:
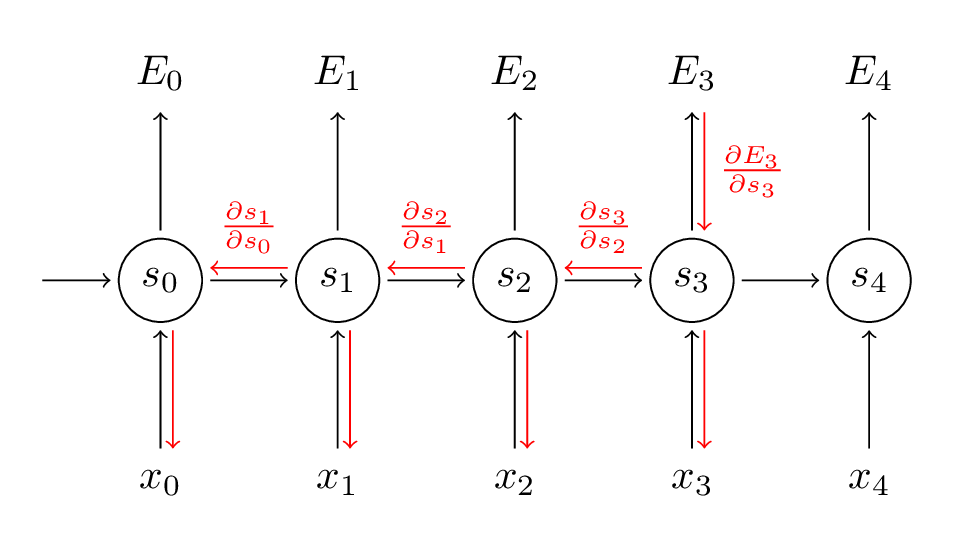
Fonte: (http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/)
Nella fase BPTT, calcoliamo la derivata parziale in ogni peso nella rete. Quindi, se siamo nel tempo t = 3, allora consideriamo la derivata di E3 rispetto a quella di S3. Ora, x3 è anche connesso a s3. Quindi, si considera anche la sua derivata. Ora, se vediamo che s3 è connesso a s2, allora s3 dipende dal valore di s2 e qui si considera anche la derivata di s3 rispetto a s2. Questo agisce come una regola della catena e accumuliamo tutta la dipendenza con le sue derivate e la usiamo per calcolare l'errore.
En E3 tenemos un gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in... que es de S3 y su ecuación en ese momento es:
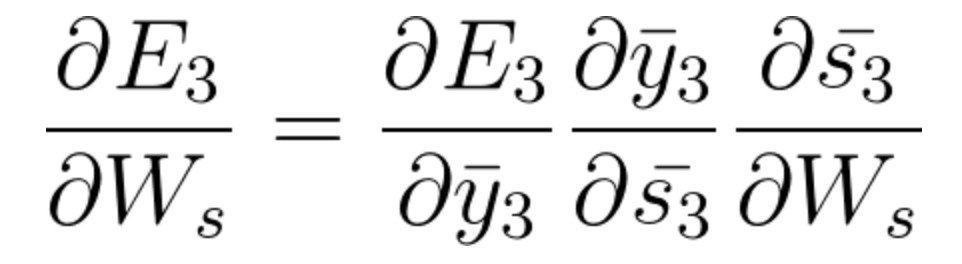
Ora abbiamo anche s2 associato a s3 quindi,
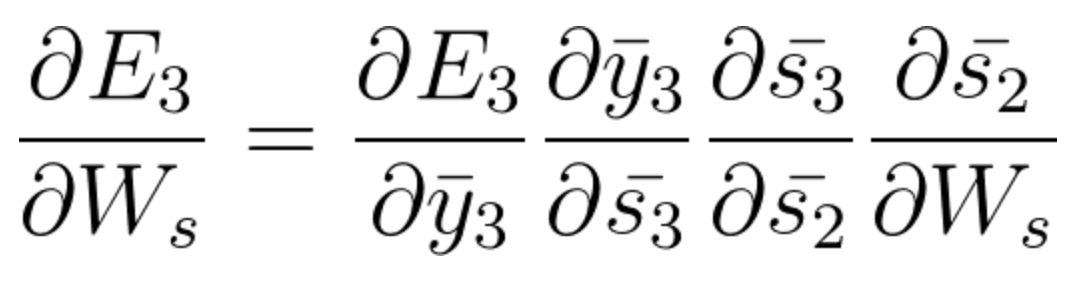
E s1 è anche associato a s2 e, così, ora tutto s1, s2, s3 e ha effetto su E3,
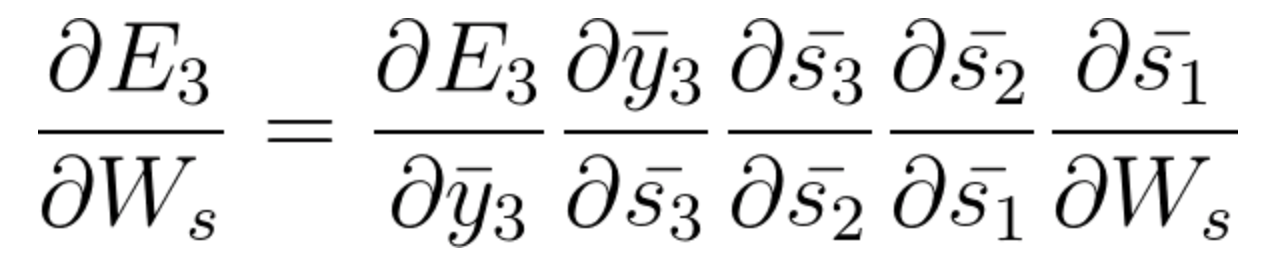
Accumulando tutto, finiamo per ottenere la seguente equazione che ha contribuito con Ws a quella rete al tempo t = 3,
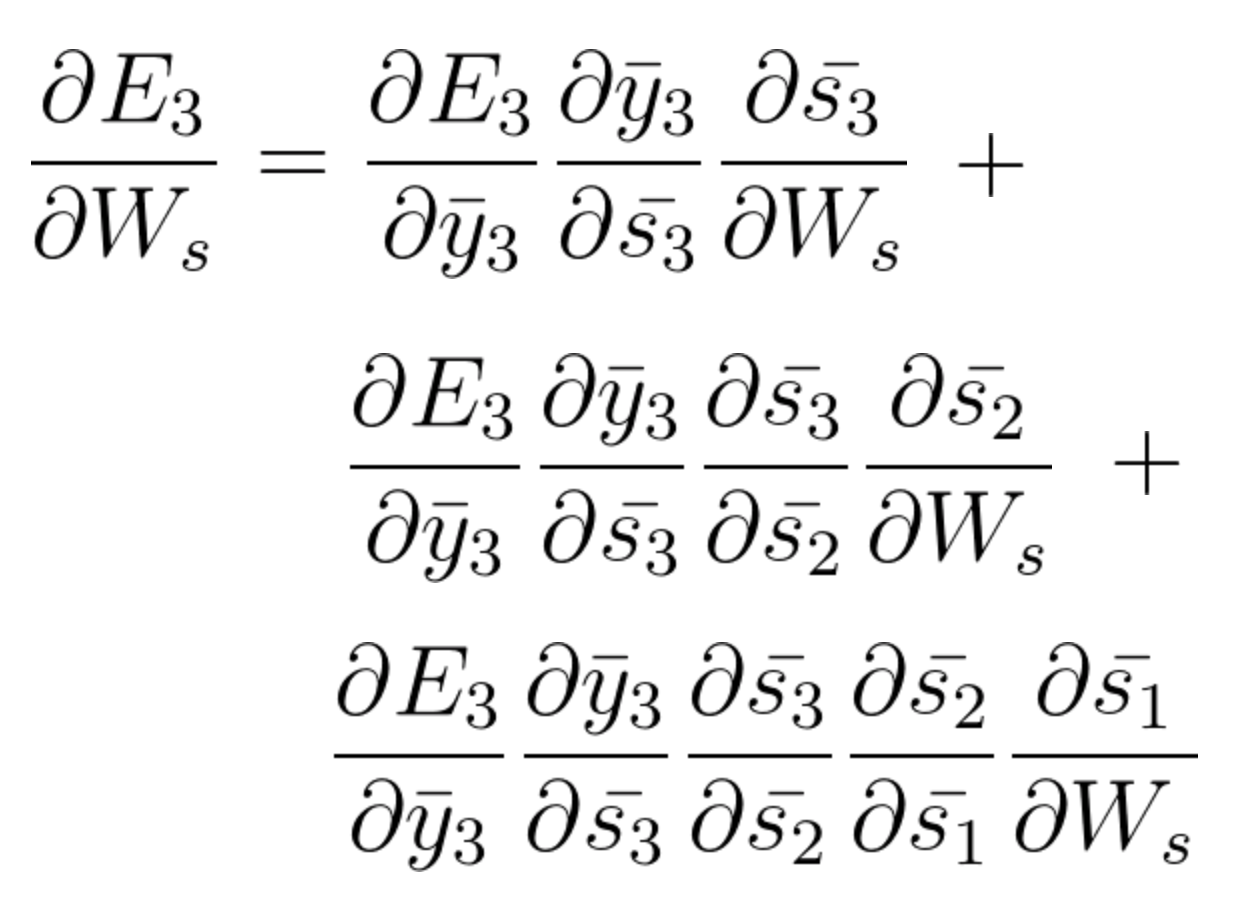
L'equazione generale per la quale adattiamo Ws nella nostra rete BPTT può essere scritta come,
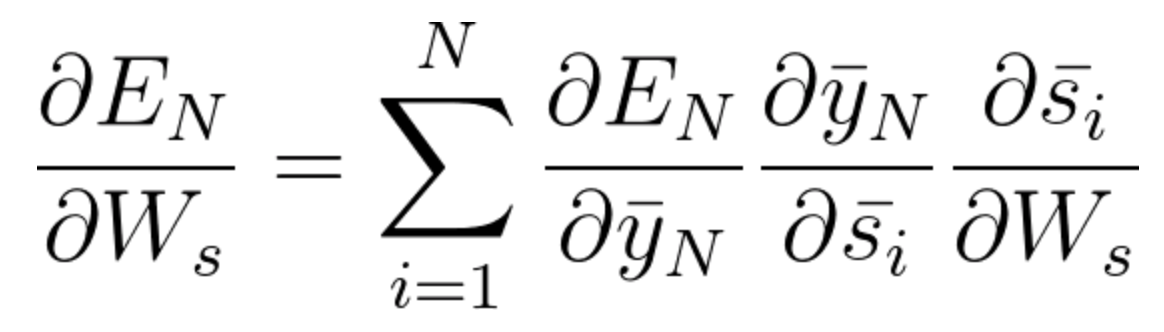
Ora, come abbiamo notato, Wx è anche associato alla rete. Quindi, facendo lo stesso, di solito possiamo scrivere,
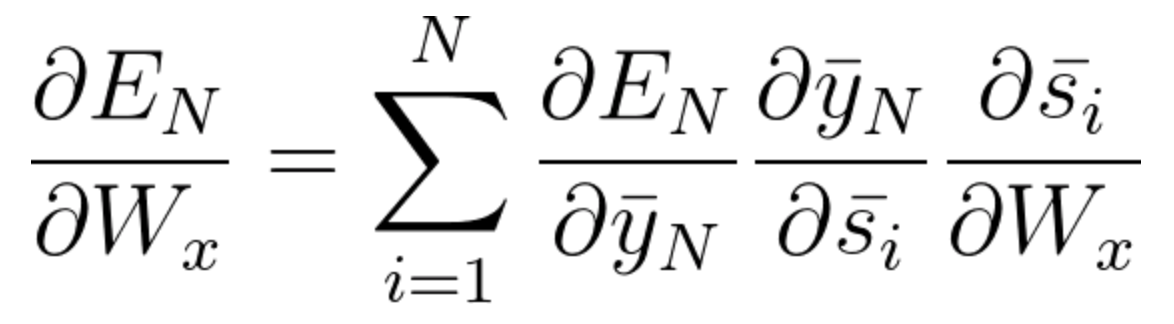
Ora che hai capito come funziona BPTT, si tratta fondamentalmente di come RNN regola i suoi pesi e riduce l'errore. Ora, il difetto principale qui è che questo è fondamentalmente solo per una piccola rete con 4 copertine. Ma immagina se avessimo centinaia di strati e, subito, diciamo t = 100, finiremmo per calcolare tutte le derivate parziali associate alla rete e questa è una moltiplicazione enorme e questo può ridurre il valore complessivo ad un valore molto piccolo o minuto tale che potrebbe essere inutile correggere l'errore. Questo problema si chiama Il problema del gradiente sta scomparendo.
Il problema del gradiente sta scomparendo
Come sappiamo tutti, en RNN para predecir una salida usaremos una funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.... sigmoidea para que podamos obtener la salida de probabilidad para una clase en particular. Come abbiamo visto nella sezione precedente quando si tratta di dire E3, c'è una dipendenza a lungo termine. Il problema si verifica quando prendiamo la derivata e la derivata del sigmoide è sempre inferiore 0.25 e, così, quando moltiplichiamo insieme molte derivate secondo la regola della catena, ci ritroviamo con un valore di perdita tale che non possiamo usarli per il calcolo dell'errore. .
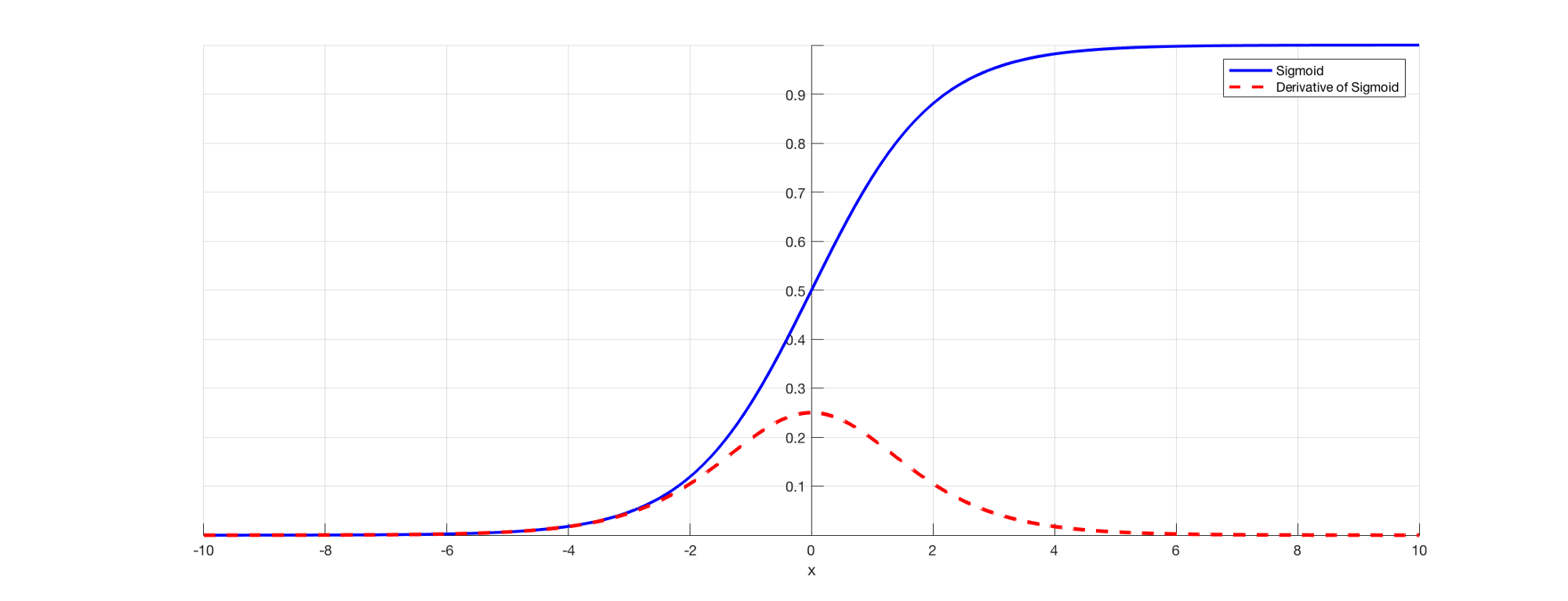
Fonte: (https://versodatascience.com/the-vanishing-gradient-problem-69bf08b15484)
Perciò, i pesi e le distorsioni non si aggiorneranno correttamente e, un misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que las capas continúan aumentando, siamo caduti ulteriormente in questo e il nostro modello non funziona correttamente e genera imprecisioni in tutta la rete.
Algunas formas de resolver este problema son inicializar la matriz de peso correctamente o optar por algo como un riprendereLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. Definito come ( F(X) = massimo(0, X) ), ReLU consente ai neuroni di attivarsi solo quando l'input è positivo, che aiuta a mitigare il problema dello sbiadimento del gradiente. È stato dimostrato che il suo utilizzo migliora le prestazioni in varie attività di deep learning, rendendo ReLU un'opzione.. en lugar de funciones sigmoideas o tanh.
Problema di gradiente esplosivo
L'esplosione del gradiente è un problema in cui il valore del gradiente diventa molto grande e questo accade spesso quando inizializziamo pesi più grandi e potremmo finire con NaN. Se il nostro modello ha sofferto di questo problema, non possiamo aggiornare affatto i pesi. Ma per fortuna, il ritaglio del gradiente è un processo che possiamo usare per questo. Ad un valore soglia predefinito, tagliamo il gradiente. Ciò impedirà al valore del gradiente di superare la soglia e non finiremo mai con numeri grandi o NaN.
Dipendenza a lungo termine dalle parole
Ora, consideriamo una frase come, "Le nuvole sono nel ____". Il nostro modello RNN può facilmente prevedere "Sky"’ qui e questo è dovuto al contesto delle nuvole e molto presto arriva come input al tuo livello precedente. Ma potrebbe non essere sempre così.
Immagina se avessimo una frase come: "Jane è nata in Kerala. Jane giocava per la squadra di calcio femminile e ha anche superato gli esami di stato. Jane parla ____ fluentemente “.
Questa è una frase molto lunga e il problema qui è che, da umano, posso dire che, da quando Jane è nata in Kerala e ha superato l'esame di stato, è ovvio che dovresti padroneggiare il “malayalam” molto fluente. Ma, Come fa la nostra macchina a saperlo?? Nel punto in cui il modello vuole prevedere le parole, potresti aver dimenticato il contesto del Kerala e altro su qualcos'altro. Questo è il problema della dipendenza a lungo termine da RNN.
Unidirezionale in RNN
Come abbiamo già commentato, RNN prende i dati in sequenza e parola per parola o lettera per lettera. Ora, quando proviamo a prevedere una parola particolare, non stiamo pensando al suo contesto futuro. Vale a dire, diciamo che abbiamo qualcosa del tipo: "Il mouse è davvero buono. Il mouse serve a ____ per facilitare l'uso dei computer “. Ora, se possiamo viaggiare in modo bidirezionale e possiamo anche vedere il contesto futuro, possiamo dire che "Spostamento"’ è la parola appropriata qui. Ma, se è unidirezionale, il nostro modello non ha mai visto computer, poi, Come fai a sapere se stiamo parlando del topo animale o del mouse del computer??
Questi problemi vengono risolti in seguito utilizzando modelli linguistici come BERT, dove possiamo inserire frasi complete e utilizzare il meccanismo dell'auto-attenzione per comprendere il contesto del testo.
Usa la memoria a breve termine a lungo termine (LSTM)
Un modo per risolvere il problema del gradiente di dispersione e della dipendenza a lungo termine da RNN è optare per le reti LSTM. LSTM ha un'introduzione a tre porte chiamate porte d'ingresso, uscita e oblio. In cui le porte dell'oblio sono responsabili delle informazioni che devono passare attraverso la rete. così, possiamo avere memoria a breve e lungo termine. Possiamo passare le informazioni attraverso la rete e recuperarle anche in una fase molto successiva per identificare il contesto di previsione. Il diagramma seguente mostra la rete LSTM.
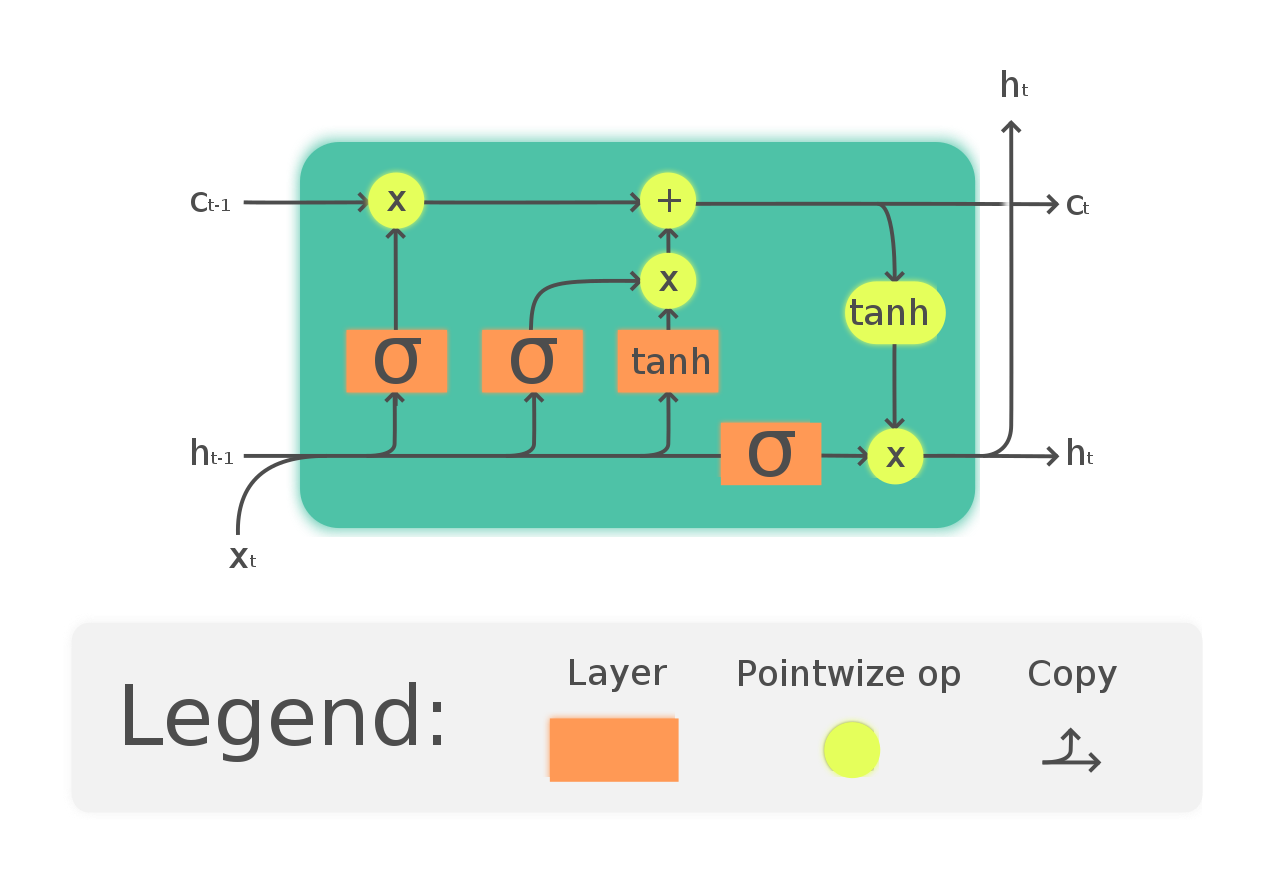
(https://en.wikipedia.org/wiki/Long_short-term_memory#/media/File:The_LSTM_Cell.svg)
Segui questo tutorial per una migliore comprensione e un esempio intuitivo di LSTM: https://versodatascience.com/illustrated-guide-to-lstms-and-gru-sa-step-by-step-explanation-44e9eb85bf21
Auspicabilmente, ora hai capito i problemi dell'utilizzo di un RNN e perché abbiamo optato per reti più complesse come LSTM.
Riferimenti
1.http: //www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
2. https://analyticsindiamag.com/quali-sono-le-sfide-della-formazione-recurrent-neural-networks/
3. https://versodatascience.com/the-vanishing-gradient-problem-69bf08b15484
4. https://en.wikipedia.org/wiki/Long_short-term_memory
5. https://www.udacity.com/course/deep-learning-nanodegree–nd101
6. Anteprima immagine: https://unsplash.com/photos/Sot0f3hQQ4Y
conclusione
Sentiti libero di connetterti con me su:
1. https://www.linkedin.com/in/siddharth-m-426a9614a/
2. https://github.com/Siddharth1698
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





