introduzione
Il neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. es una máquina de procesamiento de información y puede considerarse análoga al sistema nervioso humano. Come il sistema nervoso umano, che è costituito da neuroni interconnessi, una rete neurale è costituita da unità di elaborazione delle informazioni interconnesse. Le unità di elaborazione delle informazioni non funzionano in modo lineare. Infatti, la rete neurale trae la sua forza dall'elaborazione parallela delle informazioni, permettendoti di affrontare la non linearità. La rete neurale diventa utile per inferire significati e rilevare schemi da insiemi di dati complessi.
La red neuronal está considerada como una de las técnicas más útiles en el mundo de la analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche.... di dati. tuttavia, è complesso ed è spesso considerato una scatola nera, vale a dire, gli utenti vedono l'input e l'output di una rete neurale ma non hanno idea del processo di generazione della conoscenza. Speriamo che l'articolo aiuti i lettori a conoscere il meccanismo interno di una rete neurale e ad acquisire esperienza pratica per implementarlo in R.
Sommario
- Le basi della rete neurale
- Sintonizzazione della rete neurale in R
- Convalida incrociata di una rete neurale
Le basi della rete neurale
Una red neuronal es un modelo caracterizado por una funzione svegliaLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni...., che viene utilizzato dalle unità di elaborazione delle informazioni interconnesse per trasformare l'input in output. Una rete neurale è sempre stata paragonata al sistema nervoso umano. Le informazioni passano attraverso unità interconnesse in modo analogo al passaggio delle informazioni attraverso i neuroni negli esseri umani.. Il primo strato della rete neurale riceve l'input grezzo, lo elabora e passa le informazioni elaborate a livelli nascosti. Il livello nascosto passa le informazioni all'ultimo livello, che produce l'output. Il vantaggio della rete neurale è che è di natura adattiva. Impara dalle informazioni fornite, vale a dire, allenati dai dati, che hanno un esito noto e ne ottimizza i pesi per una migliore previsione in situazioni con esito sconosciuto.
un perceptron, vale a dire. rete neurale a strato singolo, è la forma più elementare di una rete neurale. Un perceptron riceve informazioni multidimensionali e le elabora attraverso una somma pesata e una funzione di attivazione. È addestrato da un algoritmo di apprendimento e dai dati taggati che ottimizzano i pesi nel processore di sommatoria. Una delle principali limitazioni del modello perceptron è la sua incapacità di affrontare la non linearità. Una rete neurale multistrato supera questa limitazione e aiuta a risolvere problemi non lineari.. Il livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche.... se conecta con la capa oculta, que a su vez se conecta a la Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati..... Le connessioni sono ponderate e i pesi sono ottimizzati utilizzando una regola di apprendimento.
Ci sono molte regole di apprendimento che vengono utilizzate con la rete neurale:
un) quadratico minimo;
B) descenso de gradienteGradiente è un termine usato in vari campi, come la matematica e l'informatica, per descrivere una variazione continua di valori. In matematica, si riferisce al tasso di variazione di una funzione, mentre in progettazione grafica, Si applica alla transizione del colore. Questo concetto è essenziale per comprendere fenomeni come l'ottimizzazione negli algoritmi e la rappresentazione visiva dei dati, consentendo una migliore interpretazione e analisi in...;
C) regola di Newton;
D) gradiente coniugato, eccetera.
Le regole di apprendimento possono essere utilizzate insieme al metodo dell'errore di propagazione inversa. La regola di apprendimento viene utilizzata per calcolare l'errore nell'unità di output. Questo errore si propaga all'indietro a tutte le unità in modo che l'errore in ciascuna unità sia proporzionale al contributo di tale unità all'errore totale nell'unità di uscita.. Gli errori in ciascuna unità vengono utilizzati per ottimizzare il peso ad ogni connessione. Il Figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... 1 mostra la struttura di un semplice modello di rete neurale per una migliore comprensione.
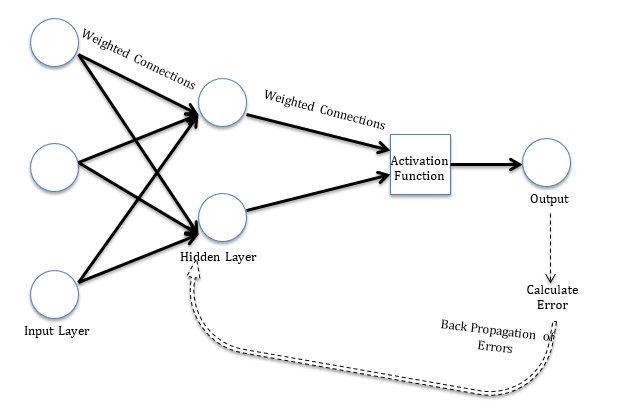
Figura 1 Un semplice modello di rete neurale
Sintonizzazione della rete neurale in R
Ora adatteremo un modello di rete neurale in R. In questo articolo, usiamo un sottoinsieme del set di dati sui cereali condiviso dalla Carnegie Mellon University (CMU). I dettagli del set di dati possono essere trovati al seguente link: http://lib.stat.cmu.edu/DASL/Datafiles/Cereals.html. L'obiettivo è prevedere la classificazione delle variabili dei cereali come calorie, proteina, grassi, eccetera. Lo script R viene fornito fianco a fianco e commentato per una migliore comprensione dell'utente. . I dati sono in formato .csv e possono essere scaricati facendo clic su: cereali.
Imposta la directory di lavoro in R usando set () funzione e mantieni cereal.csv nella directory di lavoro. Usamos la calificación como variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... dependiente y las calorías, proteina, grassi, sodio e fibra come variabili indipendenti. Dividimos los datos en addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y conjunto de prueba. Il training set viene utilizzato per trovare la relazione tra le variabili dipendenti e indipendenti, Mentre il gruppo di test valuta le prestazioni del modello. Usiamo il 60% del set di dati come set di training. L'assegnazione dei dati al set di formazione e test viene effettuata mediante campionamento casuale. Abbiamo eseguito un campionamento casuale in R utilizzando Spettacoli ( ) funzione. Abbiamo usato set.seme () per generare ogni volta lo stesso campione casuale e mantenere la coerenza. Useremo il indiceIl "Indice" È uno strumento fondamentale nei libri e nei documenti, che consente di individuare rapidamente le informazioni desiderate. In genere, Viene presentato all'inizio di un'opera e organizza i contenuti in modo gerarchico, compresi capitoli e sezioni. La sua corretta preparazione facilita la navigazione e migliora la comprensione del materiale, rendendolo una risorsa essenziale sia per gli studenti che per i professionisti in vari settori.... durante la regolazione della rete neurale per creare set di dati di test e training. Lo script R è il seguente:
## Creazione della variabile di indice # Read the Data data = read.csv("cereali.csv", intestazione=T) # Random sampling samplesize = 0.60 * ora(dati) set.seme(80) indice = campione( seq_len ( ora ( dati ) ), dimensione = dimensione del campione ) # Create training and test set datatrain = data[ indice, ] datatest = dati[ -indice, ]
Ora adattiamo una rete neurale ai nostri dati. Noi usiamo neuralnet libreria per l'analisi. Il primo passo è ridimensionare il set di dati sui cereali. La scala dei dati è essenziale perché, altrimenti, una variabile può avere un grande impatto sulla variabile predittiva proprio a causa della sua scala. L'uso senza scala può portare a risultati insignificanti. Le tecniche comuni per ridimensionare i dati sono: standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... mínima-máxima, Normalizzazione del punteggio Z, medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... y MAD y estimadores de tan-h. La normalizzazione minimo-massimo trasforma i dati in un intervallo comune, eliminando così l'effetto scala di tutte le variabili. A differenza della normalizzazione del punteggio Z e del metodo della mediana e MAD, il metodo minimo-massimo conserva la distribuzione originale delle variabili. Utilizziamo la normalizzazione minima-massima per scalare i dati. Lo script R per ridimensionare i dati è il seguente.
## Ridimensiona i dati per la rete neurale max = applica(dati , 2 , max) min = applica(dati, 2 , min) scaled = as.data.frame(scala(dati, centro = min, scala = max - min))
I dati scalati vengono utilizzati per adattarsi alla rete neurale. Visualizziamo la rete neurale con pesi per ciascuna delle variabili. Lo script R è il seguente.
## Adatta la rete neurale # install library install.packages("neuralnet ") # load library library(neuralnet) # creating training and test set trainNN = scaled[indice , ] testNN = ridimensionato[-indice , ] # fit neural network set.seed(2) NN = neuralnet(valutazione ~ calorie + proteina + GRASSO + sodio + fibra, trenoNN, nascosto = 3 , linear.output = T ) # plot neural network plot(NN)
La figura 3 visualizza la rete neurale calcolata. Il nostro modello ha 3 neuroni nel loro strato nascosto. Le linee nere mostrano connessioni con pesi. I pesi sono calcolati utilizzando l'algoritmo di backpropagation spiegato sopra. La linea blu mostra il termine di bias.
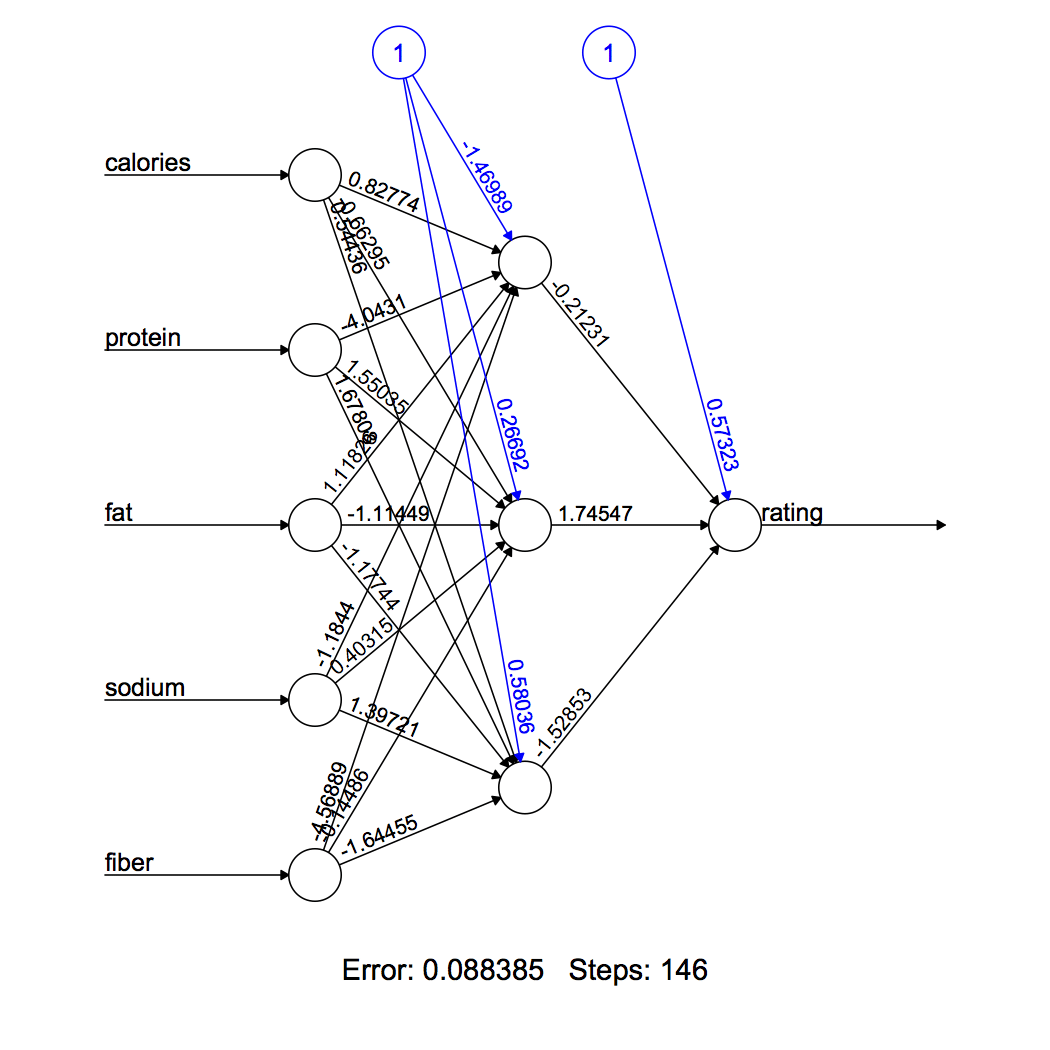
Figura 2 neuronale rosso
Prevediamo la valutazione utilizzando il modello di rete neurale. Il lettore deve ricordare che la valutazione prevista verrà ridimensionata e dovrà trasformarla per poter effettuare un confronto con la valutazione effettiva. Confrontiamo anche la valutazione prevista con la valutazione effettiva visualizzando. L'RMSE per il modello di rete neurale è 6.05. Il lettore può saperne di più su RMSE in un altro articolo, cui si accede cliccando qui. Lo script R è il seguente:
## Previsione tramite rete neurale forecast_testNN = calcola(NN, provaNN[,C(1:5)]) predit_testNN = (forecast_testNN$net.result * (max(valutazione dei dati) - min(valutazione dei dati))) + min(valutazione dei dati) complotto(datatest $ rating, forecast_testNN, col="blu", pch=16, ylab = "valutazione prevista NN", xlab = "valutazione reale") abline(0,1) # Calcola Root Mean Square Error (RMSE) RMSE.NN = (somma((datatest $ rating - forecast_testNN)^2) / ora(datatest)) ^ 0.5
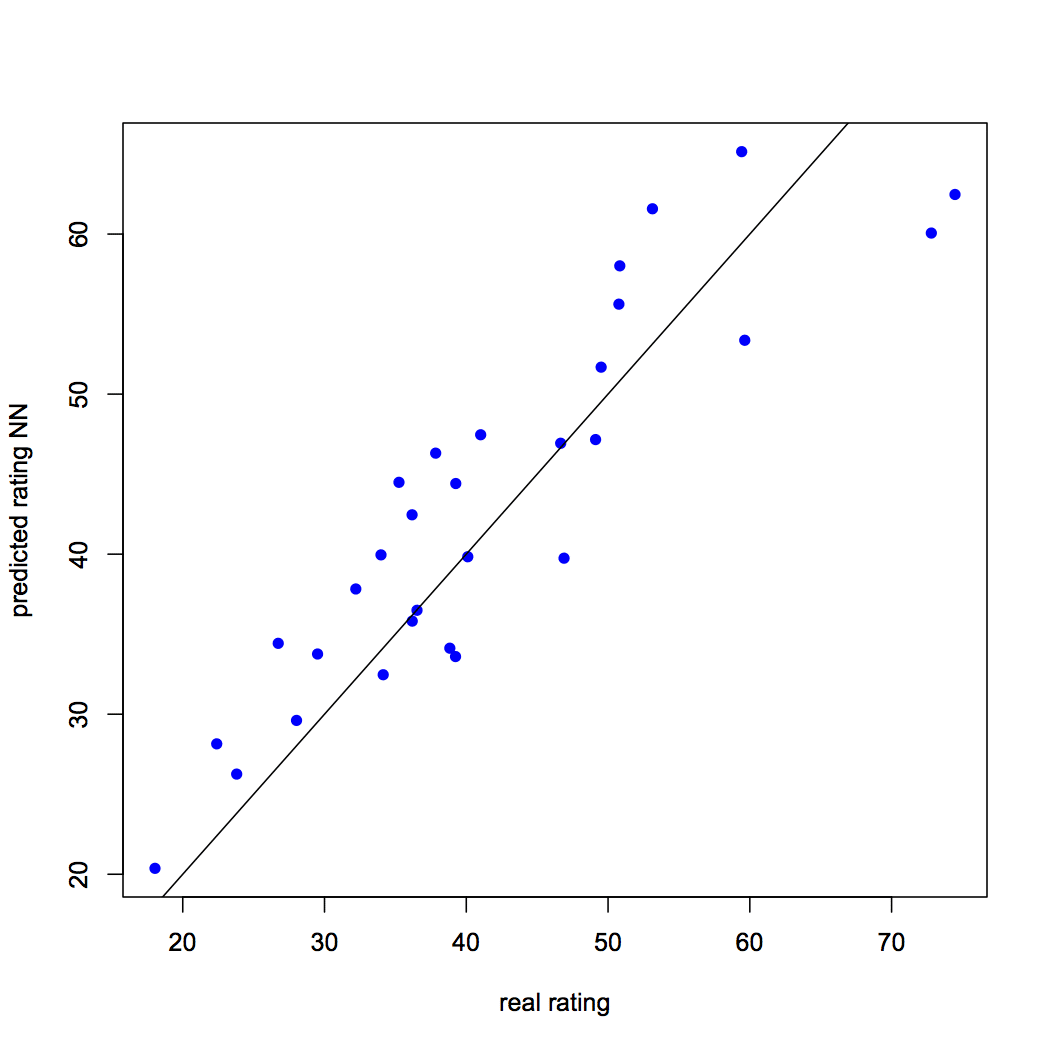
Figura 3: Valutazione prevista vs. effettiva utilizzando una rete neurale
Convalida incrociata di una rete neurale
Abbiamo valutato il nostro metodo di rete neurale utilizzando RMSE, cos'è un metodo di valutazione residuo. Il problema principale con i metodi di valutazione residua è che non ci informano sul comportamento del nostro modello quando vengono introdotti nuovi dati.. Cerchiamo di risolvere il problema di “nuovi dati” dividendo i nostri dati in training e test set, costruire il modello nel training set e valutare il modello calcolando RMSE per il test set. La suddivisione del test di addestramento non era altro che la forma più semplice di metodo di convalida incrociata noto come metodo di conservazione. Una limitazione del metodo di conservazione è la varianza della metrica di valutazione delle prestazioni, nel nostro caso RMSE, può essere elevato in base agli elementi assegnati al set di formazione e test.
La seconda tecnica di convalida incrociata comunemente è convalida incrociata di k-fold. Questo metodo può essere visto come ricorrente metodo di conservazione. I dati completi sono divisi in k sottoinsiemi uguali e ogni volta che un sottoinsieme viene assegnato come set di prova, altri servono per addestrare il modello. Ogni punto dati ha la possibilità di trovarsi nel set di test e nel set di allenamento, quindi questo metodo riduce la dipendenza delle prestazioni dalla divisione test-addestramento e riduce la varianza delle metriche delle prestazioni. Il caso estremo di convalida incrociata di k-fold si verificherà quando k è uguale al numero di punti dati. Significherebbe che il modello predittivo viene addestrato su tutti i punti dati tranne un punto dati, che assume il ruolo di test set. Questo metodo per lasciare un punto dati come set di prova è noto come lasciare una convalida incrociata.
Ora ci esibiremo convalida incrociata di k-fold nel modello di rete neurale che abbiamo costruito nella sezione precedente. Il numero di elementi nel training set, J, varia da 10 un 65 e per ogni J, Estratto 100 esempi di set di dati. Il resto degli elementi in ogni caso viene assegnato al set di test. Il modello viene addestrato in ciascuna delle opzioni 5600 Training dei set di dati e quindi testato rispetto ai set di test corrispondenti. Calcoliamo l'RMSE di ciascuno dei set di test. I valori RMSE per ciascuno dei set vengono archiviati in una matrice.[100 X 56]. Questo metodo garantisce che i nostri risultati siano privi di qualsiasi bias del campione e verifica la robustezza del nostro modello.. Usiamo il loop nidificato. Lo script R è il seguente:
## Convalida incrociata del modello di rete neurale # install relevant libraries install.packages("Stivale") install.packages("compensatore") # Load libraries library(Stivale) biblioteca(compensatore) # Initialize variables set.seed(50) k = 100 RMSE.NN = NULL List = list( ) # Fit neural network model within nested for loop for(j in 10:65){ per (io in 1:K) { indice = campione(1:ora(dati),J ) trainNN = scalato[indice,] testNN = ridimensionato[-indice,] datatest = dati[-indice,] NN = neuralnet(valutazione ~ calorie + proteina + GRASSO + sodio + fibra, trenoNN, nascosto = 3, lineare.output= T) forecast_testNN = calcola(NN,provaNN[,C(1:5)]) predit_testNN = (forecast_testNN$net.result*(max(valutazione dei dati)-min(valutazione dei dati)))+min(valutazione dei dati) RMSE.NN [io]<- (somma((datatest $ rating - forecast_testNN)^2)/ora(datatest))^ 0,5 } Elenco[[J]] = RMSE.NN } Matrix.RMSE = do.call(cbind, Elenco)
I valori RMSE sono accessibili tramite la variabile Matrix.RMSE. La dimensione della matrice è grande; così, cercheremo di dare un senso ai dati attraverso le visualizzazioni. Primo, prepareremo un box plot per una delle colonne in Matrix.RMSE, dove il training set ha una lunghezza pari a 65. Se pueden preparar estos box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati.... para cada una de las longitudes del conjunto de entrenamiento (10 un 65). Lo script R è il seguente.
## Preparare il boxplot trama a scatole(Matrix.RMSE[,56], ylab = "RMSE", principale = "RMSE BoxPlot (lunghezza del set di allenamento = 65)")
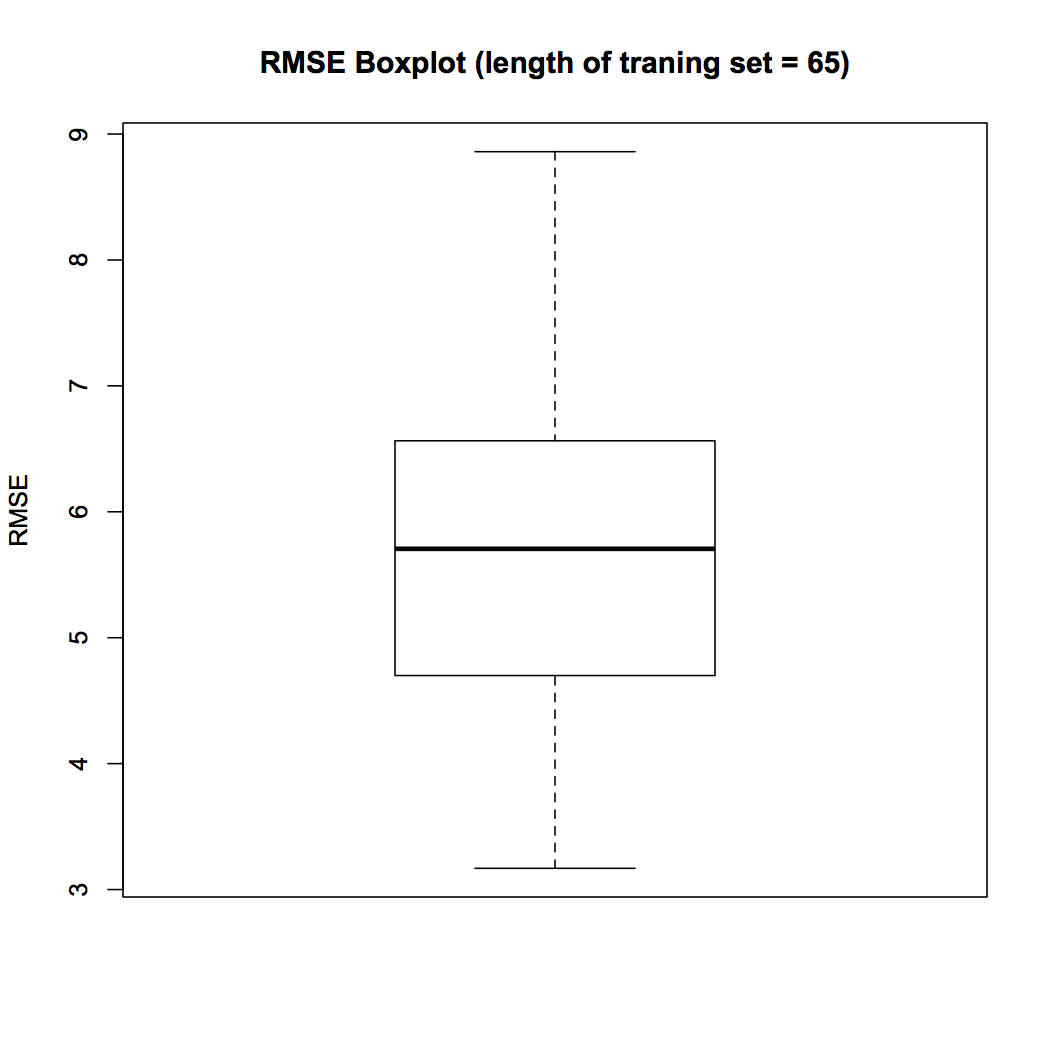
Figura 4 Trama scatola
Il box plot di Fig. 4 mostra che l'RMSE mediano in 100 campioni quando la durata del training set è impostata su 65 è 5.70. Nella seguente visualizzazione, studiamo la variazione di RMSE con la durata del training set. Calcoliamo l'RMSE mediano per ciascuna delle lunghezze del training set e le tracciamo utilizzando il seguente script R.
## Variazione dell'RMSE . mediano
install.packages("matriceStats")
biblioteca(matriceStats)
med = colMedians(Matrix.RMSE)
X = seq(10,65)
complotto (con ~X, tipo = "io", xlab = "durata del set di allenamento", ylab = "RMSE mediano", principale = "Variazione di RMSE con la durata del training set")
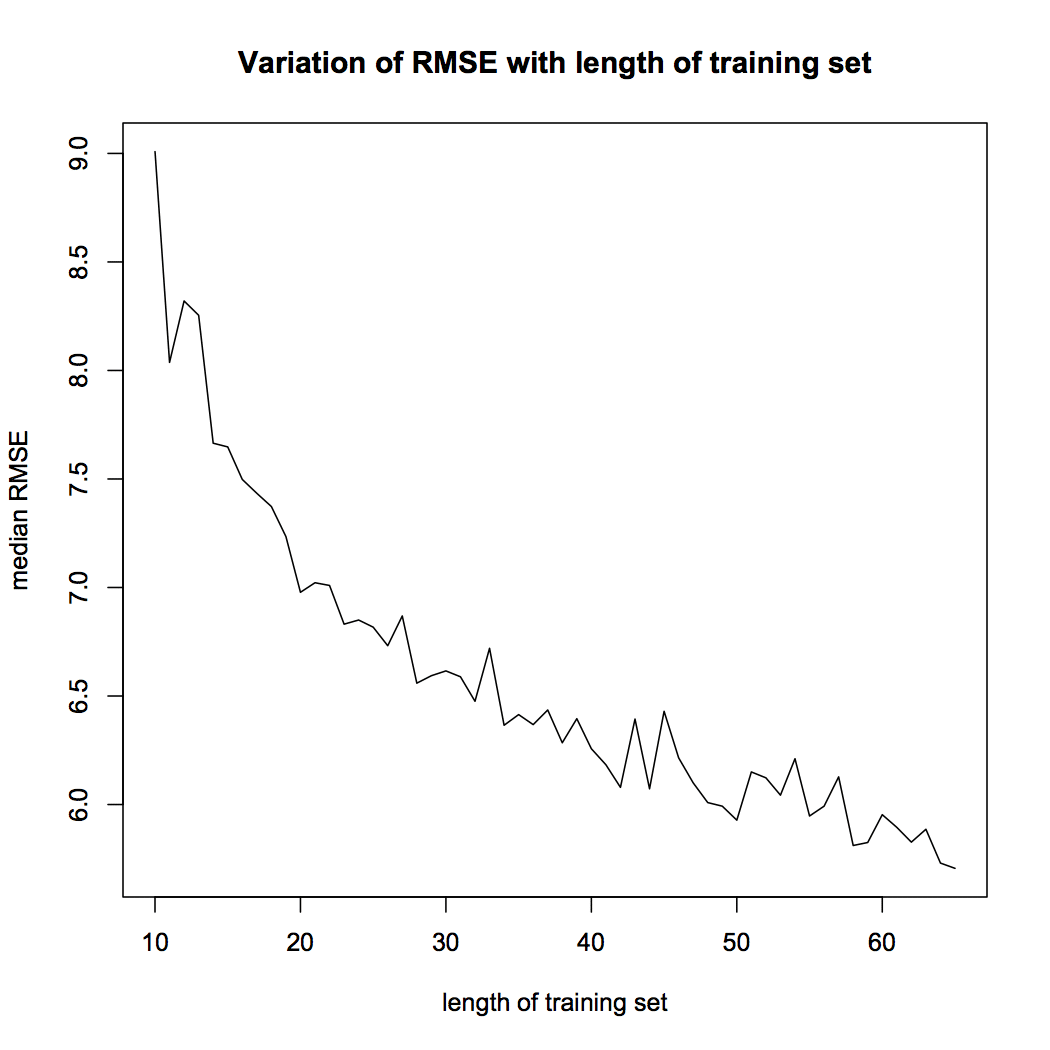
Figura 5 Variazione RMSE
La figura 5 muestra que la mediana de RMSE de nuestro modelo disminuye a misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que la duración del entrenamiento de la serie. Questo è un risultato importante. Il lettore dovrebbe ricordare che l'accuratezza del modello dipende dalla durata del training set.. Le prestazioni del modello di rete neurale sono sensibili alla divisione dei test di addestramento.
Note finali
L'articolo analizza gli aspetti teorici di una rete neurale, la sua attuazione nella valutazione R e post-formazione. La rete neurale è ispirata al sistema nervoso biologico. Simile al sistema nervoso, le informazioni passano attraverso strati di processori. L'importanza delle variabili è rappresentata dai pesi di ogni connessione. L'articolo fornisce una comprensione di base dell'algoritmo di backpropagation, che viene utilizzato per assegnare questi pesi. In questo articolo implementiamo anche una rete neurale in R. Utilizziamo un set di dati pubblicamente disponibile condiviso da CMU. L'obiettivo è prevedere la classificazione dei cereali utilizzando informazioni come le calorie, grassi, proteina, eccetera. Dopo aver costruito la rete neurale, valutiamo la precisione e la robustezza del modello. Calcoliamo RMSE ed eseguiamo analisi di convalida incrociata. In convalida incrociata, controlliamo la variazione nella precisione del modello al variare della durata del training set. Consideriamo training set con una lunghezza di 10 un 65. Per ogni lunghezza, sono selezionati casualmente 100 campioni e viene calcolato l'RMSE mediano. Mostriamo che la precisione del modello aumenta quando il training set è grande. Prima di utilizzare il modello per la previsione, è importante verificare la robustezza delle prestazioni mediante la convalida incrociata.
L'articolo fornisce una rapida rassegna della rete neurale ed è un utile riferimento per gli appassionati di dati.. Abbiamo fornito un codice R commentato in tutto l'articolo per aiutare i lettori con un'esperienza pratica utilizzando le reti neurali..
Bio: Chaitanya Sagar è il fondatore e CEO di Analisi percettiva. Perceptive Analytics è una delle principali società di analisi in India. Lavorare in Marketing Analytics per aziende di e-commerce, al dettaglio e farmaceutico.





