Foto di papà Mohlala su Unsplash
I dati sono acqua, purificarli per renderli commestibili è una funzione del data analyst: Kashish Rastogi
Sommario:
- Dichiarazione problema
- Descrizione dei dati
- Pulizia del testo con la PNL
- Trova se il testo ha: con spazio
- Pulizia del testo con la libreria del preprocessore
- Analisi del sentiment dei dati
- Visualizzazione dati
Sto prendendo i dati di Twitter che sono disponibili qui sulla piattaforma DataPeaker.
Importazione di librerie
importa panda come pd importare re import plotly.express come px import nltk importare spazio
Sto caricando un modello piccolo e spazioso. Ci sono 3 dimensioni del modello che puoi scaricare spacy (poco, medio e grande) secondo le vostre esigenze.
nlp = spacy.load('en_core_web_sm')
I dati sono così
df = pd.read_csv(r'posizione del file') da DF['ID'] df.head(5)
Dichiarazione problema
Il punto chiave è trovare il sentimento dei dati di testo. Il testo fornito proviene da clienti di varie aziende tecnologiche che producono telefoni, computer portatili, gadget, eccetera. Il compito è identificare se i tweet hanno un sentimento negativo, positivo o neutro nei confronti dell'azienda.
Descrizione dei dati
Etichetta: La colonna dell'etichetta ha 2 valori unici 0 e 1.
Pio: Le colonne dei tweet hanno il testo fornito dai clienti
Manipolazione di dati
Trova la forma dei dati
Ci sono 2 colonne e 7920 righe.
forma df
Classificazione dei tweet
fig = px.pie(df, nomi=df.label, foro=0.7, titolo="Classificazione dei Tweet",
altezza=250, color_discrete_sequence=px.colors.qualitative.T10)
fig.update_layout(margine=dict(t=100, b=40, l=60, r=40),
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(dimensione = 25, colore="#a5a7ab", famiglia="Lato, sans-serif"),
font=dict(colore="#8a8d93"),
)
Prenditi un momento e guarda i dati. Vedi?

Fonte immagine: https://unsplash.com/photos/LDcC7aCWVlo
- Non ci sono markup da analizzare, è un testo semplice (¡yaa!).
- Ci sono molte cose da filtrare come:
-
- L'identificatore di Twitter è mascherato (@Nome utente), cosa non ci serve?.
- etichette
- Link (modifica)
- Personaggi speciali
- Vediamo che il testo ha un valore numerico in loro.
- Ci sono molti errori di battitura e contrazioni nel testo.
- Ci sono molti nomi di aziende (Sony, Mela).
- Il testo non è in minuscolo
Ripuliamo il testo
Trova se il testo ha:
- Nomi utente Twitter
- etichette
- Valori numerici
- Link (modifica)
Eliminare se il testo ha:
- Nome utente Twitter perché non fornirai ulteriori informazioni in questo momento, poiché per motivi di sicurezza, il nome utente è stato cambiato in nomi fittizi
- Le parole hashtag non forniranno alcun significato utile al testo nell'analisi del sentimento.
- Neanche il collegamento URL aggiungerà informazioni al testo.
- Rimozione
- Punteggio per testo pulito
- Parole più corte di 3 sono sicuri da rimuovere dal testo perché le parole saranno come (soia, soia, è) che non hanno significato o funzione specifica nel testo
- Le stopword sono sempre l'opzione migliore per rimuovere
Rimozione Nome utente del testo
Crea una funzione per rimuovere il nome utente dal testo con il semplice trova tutto() funzione panda. Dove andremo a selezionare le parole che iniziano con '@'.
def remove_pattern(input_txt):
r = re.trovare(R"@(w+)", input_txt)
per io in r:
input_txt = re.sub(io, '', input_txt)
return input_txt
df['@_rimuovere'] = np.vettorizzare(remove_pattern)(df['twittare'])
df['@_rimuovere'][:3]

trovare etichette nel testo
Creare una funzione per estrarre hashtag dal testo con il semplice trova tutto() funzione panda. Dove andremo a selezionare le parole che iniziano con '#’ e memorizzarli in un frame di dati.
hashtag = []
def hashtag_extract(X):
# Ripassa le parole del tweet
per io in x:
ht = re.findall(R"#(w+)", io)
hashtag.append(ht)
hashtag di ritorno

Passando la funzione ed estraendo gli hashtag ora possiamo visualizzare quanti hashtag ci sono nei tweet positivi e negativi
# estrarre hashtag dai tweet neg/pos dff_0 = hashtag_extract(df['twittare'][df['etichetta'] == 0]) dff_1 = hashtag_extract(df['twittare'][df['etichetta'] == 1]) dff_all = hashtag_extract(df['twittare'][df['etichetta']]) # lista disannidamento dff_0 = somma(dff_0,[]) dff_1 = somma(dff_1,[]) dff_all = somma(dff_all,[])
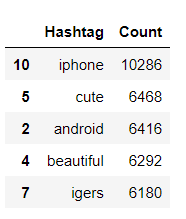
Conteggio degli hashtag frequenti utilizzati quando label = 0. FreqDist significa che ci dirà quante volte quella parola è apparsa nell'intero documento.
data_0 = nltk.DistFreq(dff_0)
data_0 = pd.DataFrame({"Hashtag": elenco(data_0.keys()),
'Contare': elenco(dati_0.valori())}).sort_values(per='Conta', ascendente=Falso)
data_0[:5]
Se vuoi saperne di più su Plotly e su come usarlo, visite è Blog. Ogni grafico è ben spiegato con diversi parametri da tenere a mente quando si tracciano i grafici.
fig = px.bar(data_0[:30], x='Hashtag', y='Conta', altezza=250,
titolo="Superiore 30 hashtag",
color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=Falso),
fig.update_xaxes(ordine di categoria ="discendente totale")
fig.update_traces(hovertemplate=Nessuno)
fig.update_layout(margine=dict(t=100, b=0, l=60, r=40),
modalità hover ="x unificato",
xaxis_tickangle = 300,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(dimensione = 25, colore="#a5a7ab", famiglia="Lato, sans-serif"),
font=dict(colore="#8a8d93")
)
Testo di passaggio
frasi = nlp(str(testo))
trovare Nordvalori numerici nel testo
spacy fornisce funzioni come_num che indica se il testo ha valori numerici o meno
per token in frasi:
if token.like_num:
text_num = token.testo
Stampa(text_num)
trovare Collegamento URL nel testo
spacy fornisce la funzione like_url che indica se il testo contiene o meno un collegamento all'URL
# trova i link
per token in frasi:
if token.like_url:
text_links = token.testo
Stampa(text_links)

C'è una libreria in Python che aiuta a ripulire il testo, puoi trovare la documentazione. qui
Attualmente, questa libreria supporta la pulizia, tokenizzazione e analisi
- URL
- etichette
- Menzioni
- Parole riservate (RT, FAV)
- emoji
- Emoticon
Importazione della libreria
!pip install tweet-preprocessor importa il preprocessore come p
Chiama una funzione per ripulire il testo
def preprocess_tweet(riga):
testo = riga['twittare']
testo = p.pulito(testo)
testo di ritorno
df['clean_tweet'] = df.applica(preprocess_tweet, asse=1) df[:6]

Come vediamo, le colonne clean_tweet hanno solo testo, tutti i nomi utente vengono rimossi, hashtag e link URL
Alcuni dei passaggi per la pulizia sono ancora come
- scaricando tutto il testo
- Rimozione dei punteggi
- Rimuovi i numeri
Codice:
def preprocessing_text(testo):
# Crea minuscolo
text = text.str.lower()
# Rimuovi la punteggiatura
text = text.str.replace('[^ w]', '', regex=Vero)
# Rimuovi cifre
text = text.str.replace('[D]+', '', regex=Vero)
testo di ritorno
pd.set_option('max_colwidth', 500)
df['clean_tweet'] = testo_pre-elaborazione(df['clean_tweet'])
df['clean_tweet'][:5]

Abbiamo il nostro testo pulito, rimuoviamo le parole vuote.
Cosa sono le parole vuote?? Hai bisogno di rimuovere le stopword??
Le stopword sono le parole più comuni in qualsiasi linguaggio naturale. Le parole vuote sono come me, soia, tuo, quando, eccetera., non aggiungere ulteriori informazioni al testo.
Non è necessario rimuovere le stopword ogni volta che dipende dal caso di studio, qui stiamo trovando il feeling del testo, quindi non abbiamo bisogno di fermare le parole.
da nltk.corpus importa parole non significative
# Rimuovi le parole di arresto
stop = stopwords.parole('inglese')
df['clean_tweet'] = df['clean_tweet'].applicare(lambda x: ' '.aderire([parola per parola in x.split() se la parola non è in (fermare)]))
df['clean_tweet'][:5]
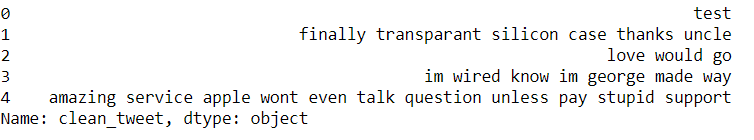
Dopo aver implementato tutti i passaggi, abbiamo ottenuto il nostro testo pulito. Ora, Cosa fare con il testo?
- Possiamo scoprire quali parole vengono usate frequentemente??
- Quali parole sono usate più negativamente? / positivamente nel testo?
Tokenizza le parole e calcola la frequenza e il conteggio delle parole e memorizzale in un frame di dati.
Una distribuzione di frequenza registra il numero di volte in cui ogni parola si è verificata. Ad esempio, una nuova parola è stata usata frequentemente nei dati completi seguita da altre parole iPhone, telefono, eccetera.
a = df['clean_tweet'].str.cat(settembre=' ')
parole = nltk.tokenize.word_tokenize(un)
word_dist = nltk.FreqDist(parole)
dff = pd.DataFrame(word_dist.most_common(),
colonne=['Parola', 'Frequenza'])
dff['Conteggio_parole'] = dff.Parola.applica(len)
dff[:5]
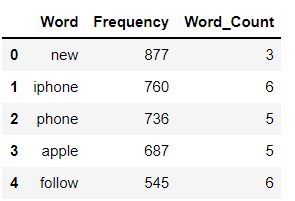
fig = px.istogramma(dff[:20], x='Parola', y='Frequenza', altezza=300,
titolo="Il più comune 20 parole nei tweet", color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=Falso),
fig.update_xaxes(ordine di categoria ="discendente totale")
fig.update_traces(hovertemplate=Nessuno)
fig.update_layout(margine=dict(t=100, b=0, l=70, r=40),
modalità hover ="x unificato",
xaxis_tickangle = 360,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(dimensione = 25, colore="#a5a7ab", famiglia="Lato, sans-serif"),
font=dict(colore="#8a8d93"),
)
fig = px.bar(dff.coda(10), x='Parola', y='Frequenza', altezza=300,
titolo="Meno comune 10 parole nei tweet", color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=Falso),
fig.update_xaxes(ordine di categoria ="discendente totale")
fig.update_traces(hovertemplate=Nessuno)
fig.update_layout(margine=dict(t=100, b=0, l=70, r=40),
modalità hover ="x unificato",
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(dimensione = 25, colore="#a5a7ab", famiglia="Lato, sans-serif"),
font=dict(colore="#8a8d93"),
)
fig = px.bar(un, altezza=300, titolo="Frequenza delle parole nei tweet",
color_discrete_sequence=px.colors.qualitative.T10)
fig.update_yaxes(showgrid=Falso),
fig.update_xaxes(ordine di categoria ="discendente totale")
fig.update_traces(hovertemplate=Nessuno)
fig.update_layout(margine=dict(t=100, b=0, l=70, r=40), showlegend=Falso,
modalità hover ="x unificato",
xaxis_tickangle = 360,
xaxis_title=" ", yaxis_title=" ",
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(dimensione = 25, colore="#a5a7ab", famiglia="Lato, sans-serif"),
font=dict(colore="#8a8d93"),
)
Analisi del sentimento
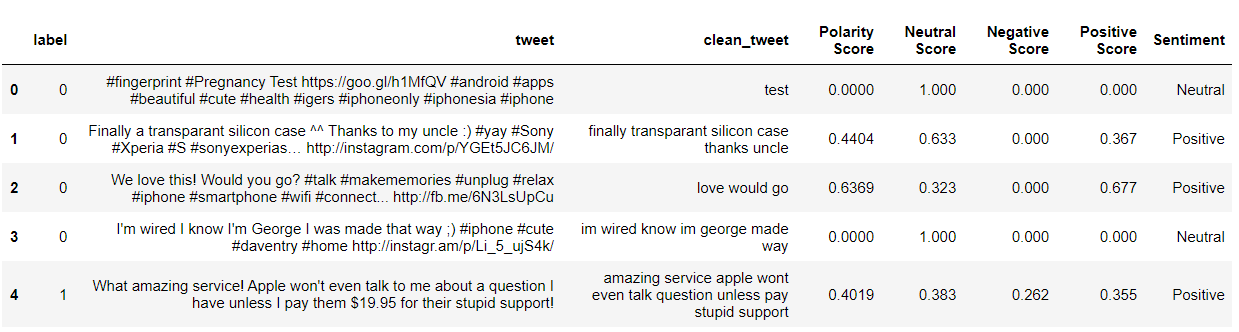
da nltk.sentiment.vader import SentimentIntensityAnalyzer da nltk.sentiment.util import * #Sentiment Analysis SIA = SentimentIntensityAnalyzer() df["clean_tweet"]= df["clean_tweet"].come tipo(str) # Applicazione del modello, Creazione variabile df["Punteggio di polarità"]=df["clean_tweet"].applicare(lambda x:SIA.polarity_scores(X)['composto']) df["Punteggio neutro"]=df["clean_tweet"].applicare(lambda x:SIA.polarity_scores(X)['Nuovo']) df["Punteggio negativo"]=df["clean_tweet"].applicare(lambda x:SIA.polarity_scores(X)['negativo']) df["Punteggio positivo"]=df["clean_tweet"].applicare(lambda x:SIA.polarity_scores(X)['pos']) # Conversione 0 a 1 Punteggio decimale a una variabile categoriale df['Sentimento']='' df.loc[df["Punteggio di polarità"]>0,'Sentimento']='Positivo' df.loc[df["Punteggio di polarità"]==0,'Sentimento']='Neutro' df.loc[df["Punteggio di polarità"]<0,'Sentimento']='Negativo' df[:5]
Classificazione dei tweet in base al sentimento
fig_pie = px.pie(df, nomi="Sentimento", titolo="Classificazione dei Tweet", altezza=250,
foro=0.7, color_discrete_sequence=px.colors.qualitative.T10)
fig_pie.update_traces(textfont=dict(colore="#F F F"))
fig_pie.update_layout(margine=dict(t=80, b=30, l=70, r=40),
plot_bgcolor="#2d3035", paper_bgcolor="#2d3035",
title_font=dict(dimensione = 25, colore="#a5a7ab", famiglia="Lato, sans-serif"),
font=dict(colore="#8a8d93"),
legenda=dict(orientamento="h", yanhor="parte inferiore", y = 1, xancore ="Giusto", x=0.8)
)
conclusione:
Abbiamo visto come pulire i dati di testo quando abbiamo un nome utente Twitter, hashtag, Collegamenti URL, cifre e analisi del sentiment sui dati di testo.
Abbiamo visto come scoprire se il testo contiene collegamenti URL o cifre con l'aiuto di spacy.
Circa l'autore:
Mi puoi connettere?
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





