Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Este artículo tiene como objetivo explicar la convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. y cómo compilar CNN con la biblioteca TensorFlow Keras. Questo articolo tratterà i seguenti argomenti.
Primero analicemos la neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. convolucional.
Convolucional neuronale rosso (CNN)
Il apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute... es un subconjunto muy importante del aprendizaje automático debido a su alto rendimiento en varios dominios. La convolucional neuronale rossa (CNN) è un potente tipo di apprendimento profondo per l'elaborazione delle immagini che viene spesso utilizzato nella visione artificiale e comprende il riconoscimento di immagini e video insieme a un sistema di raccomandazione e all'elaborazione del linguaggio naturale (PNL).
CNN utiliza un sistema multicapa que consta de la livello di inputIl "livello di input" si riferisce al livello iniziale in un processo di analisi dei dati o nelle architetture di reti neurali. La sua funzione principale è quella di ricevere ed elaborare le informazioni grezze prima che vengano trasformate dagli strati successivi. Nel contesto dell'apprendimento automatico, La corretta configurazione del livello di input è fondamentale per garantire l'efficacia del modello e ottimizzarne le prestazioni in attività specifiche...., il Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati.... y una capa oculta que comprende múltiples capas convolucionales, strati raggruppati, strati completamente connessi. Discuteremo tutti i livelli nella prossima sezione dell'articolo mentre spieghiamo la costruzione della CNN.
Discutiamo la costruzione della CNN utilizzando la libreria Keras insieme a una spiegazione di come funziona la CNN.
edificio della CNN
Useremo il Set di dati di imaging delle cellule della malaria. Questo set di dati è composto da 27,558 imaging microscopico del campione di sangue. Il set di dati è composto da 2 cartelle: cartelle: parassitato e non infetto. Immagini di esempio
un) campione di sangue parassitato
B) Campione di sangue non infetto
Discuteremo della costruzione della CNN insieme alla CNN lavorando su quanto segue 6 Passi:
passo 1: importa le librerie richieste
passo 2: inicializar CNN y agregar una copertina convolutivaIl livello convoluzionale, Fondamentale nelle reti neurali convoluzionali (CNN), Viene utilizzato principalmente per l'elaborazione dei dati con strutture a griglia, come immagini. Questo livello applica filtri che estraggono le caratteristiche rilevanti, come bordi e trame, Consentire al modello di riconoscere modelli complessi. La sua capacità di ridurre la dimensionalità dei dati e di mantenere le informazioni essenziali lo rende uno strumento chiave nelle attività di visione artificiale..
passo 3: operazione di raggruppamento
passo 4: aggiungi due strati convolutivi
passo 5 – Operazione di spianatura
passo 6: livello e livello di output completamente connessi
Queste 6 i passaggi spiegheranno come funziona la CNN, mostrato nella seguente immagine:
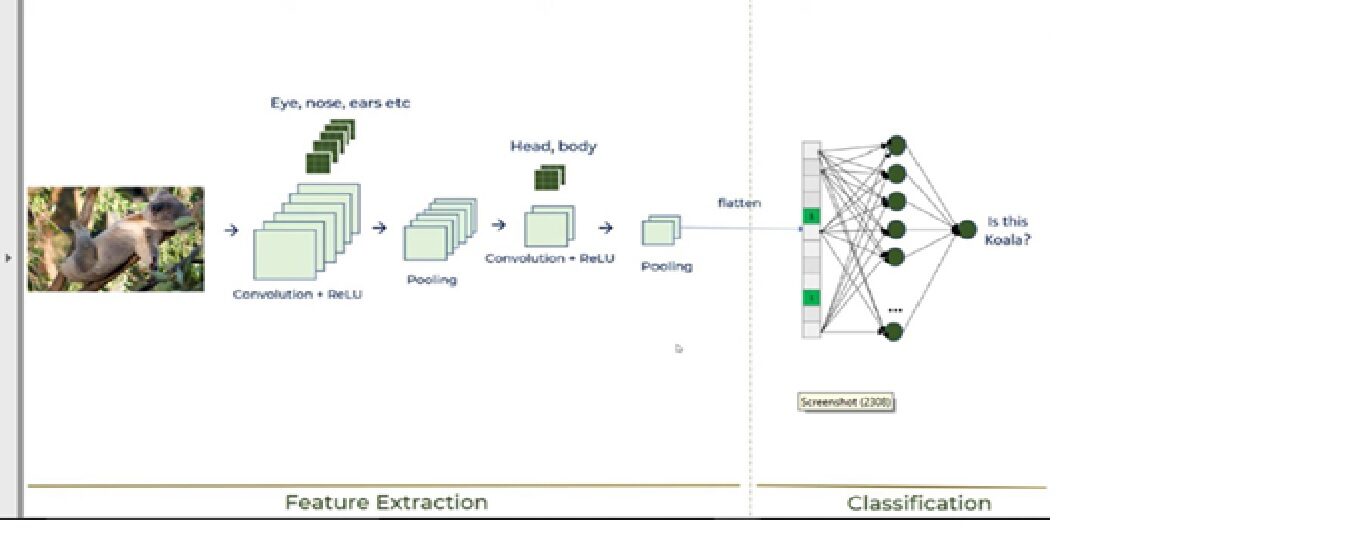
Ora, analizziamo ogni passaggio:
1. Importa le librerie richieste
Per favore, vedere il collegamento sottostante per spiegazioni dettagliate sui moduli Keras.
https://keras.io/getting_started/
Codice Python:
From tensorflow.keras.layers import Input, Lambda, Denso, Appiattire,Conv2D da tensorflow.keras.models import Model da tensorflow.keras.applications.vgg19 import VGG19 da tensorflow.keras.applications.resnet50 import preprocess_input da tensorflow.keras.preprocessing import image da tensorflow.keras.preprocessing.image import ImageDataGenerator,load_img da tensorflow.keras.models import Sequential importa numpy come np da glob import glob importa matplotlib.pyplot come plt da tensorflow.keras.layers import MaxPooling2D
2. Inizializza la CNN e aggiungi un livello convoluzionale
Codice Python:
modello=Sequenziale() modello.aggiungi(Conv2D(filtri=16,kernel_size=2,padding="stesso",attivazione="riprendere",input_shape=(224,224,3)))
Per prima cosa dobbiamo avviare la classe sequenziale poiché ci sono diversi livelli per costruire CNN e tutti devono essere in sequenza. Quindi aggiungiamo il primo livello convoluzionale in cui dobbiamo specificare 5 argomenti. Quindi, Analizziamo ogni argomento e il suo scopo.
· Filtri
Lo scopo principale della convoluzione è trovare le caratteristiche nell'immagine usando un rilevatore di caratteristiche. Dopo, mettili su una mappa delle caratteristiche, che conserva i tratti distintivi delle immagini.
Il rilevatore di caratteristiche, che è noto come filtro, anche inizializzato casualmente e poi, dopo tante iterazioni, viene selezionato il parametro della matrice di filtro che sarà il migliore per separare le immagini. Ad esempio, l'occhio, naso, eccetera. degli animali sarà considerata una caratteristica che viene utilizzata per classificare le immagini utilizzando filtri o rilevatori caratteristici. Qui stiamo usando 16 funzioni.
· Kernel_size
Kernel_size si riferisce alla dimensione dell'array di filtri. Qui stiamo usando una dimensione del filtro di 2 * 2.
· Riempimento
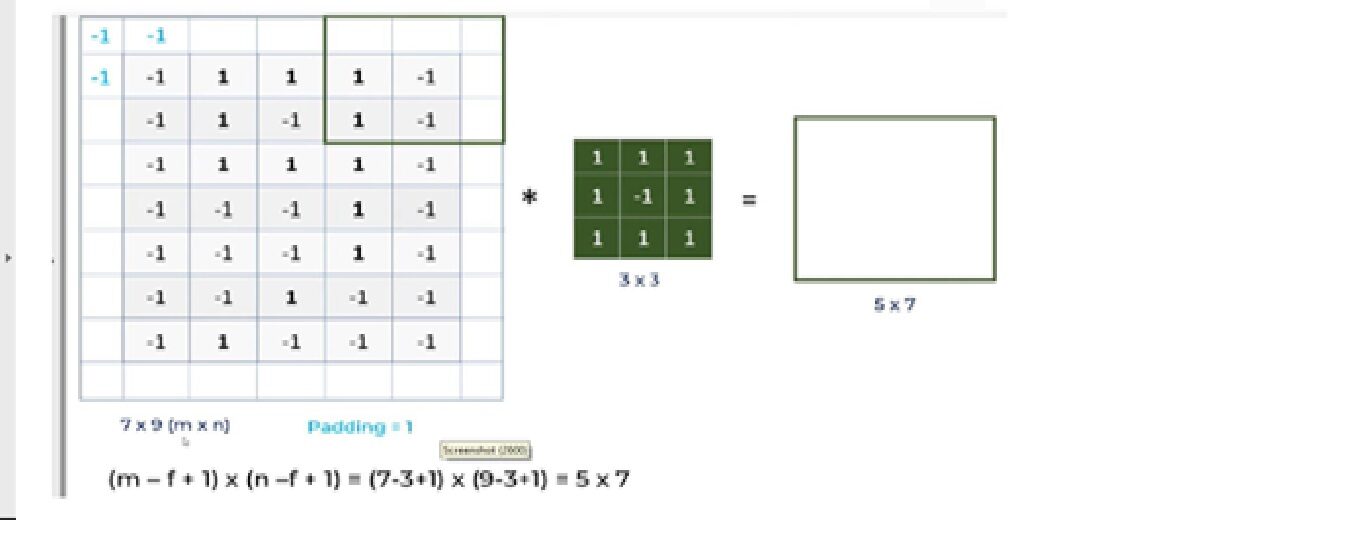
Discutiamo qual è il problema con la CNN e come l'operazione di riempimento risolverà il problema.
un. Per un'immagine in scala di grigi (nxn) e un filtro / nucleo (fxf), le dimensioni dell'immagine risultante da un'operazione di convoluzione è (n – F + 1) X (n – F + 1).
Quindi, ad esempio, un'immagine di 5 * 7 e una dimensione del nucleo del filtro di 3 * 3, il risultato dell'output dopo l'operazione di convoluzione sarebbe una dimensione di 3 * 5. Perciò, l'immagine si restringe ogni volta che viene eseguita l'operazione convoluzionale.
B. Pixel, situato negli angoli, hanno un contributo molto piccolo rispetto ai pixel nel mezzo.
Quindi, per mitigare questi problemi, viene eseguita l'operazione di riempimento. L'imbottitura è un semplice processo di aggiunta di strati con 0 oh -1 alle immagini in ingresso per evitare i problemi sopra menzionati.
Qui stiamo usando Padding = Stessi argomenti, che descrive che le immagini di output hanno le stesse dimensioni delle immagini di input.
· Funzione triggerLa funzione di attivazione è un componente chiave nelle reti neurali, poiché determina l'output di un neurone in base al suo input. Il suo scopo principale è quello di introdurre non linearità nel modello, Consentendo di apprendere modelli complessi nei dati. Ci sono varie funzioni di attivazione, come il sigma, ReLU e tanh, Ognuno con caratteristiche particolari che influiscono sulle prestazioni del modello in diverse applicazioni.... – riprendereLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. Definito come ( F(X) = massimo(0, X) ), ReLU consente ai neuroni di attivarsi solo quando l'input è positivo, che aiuta a mitigare il problema dello sbiadimento del gradiente. È stato dimostrato che il suo utilizzo migliora le prestazioni in varie attività di deep learning, rendendo ReLU un'opzione..
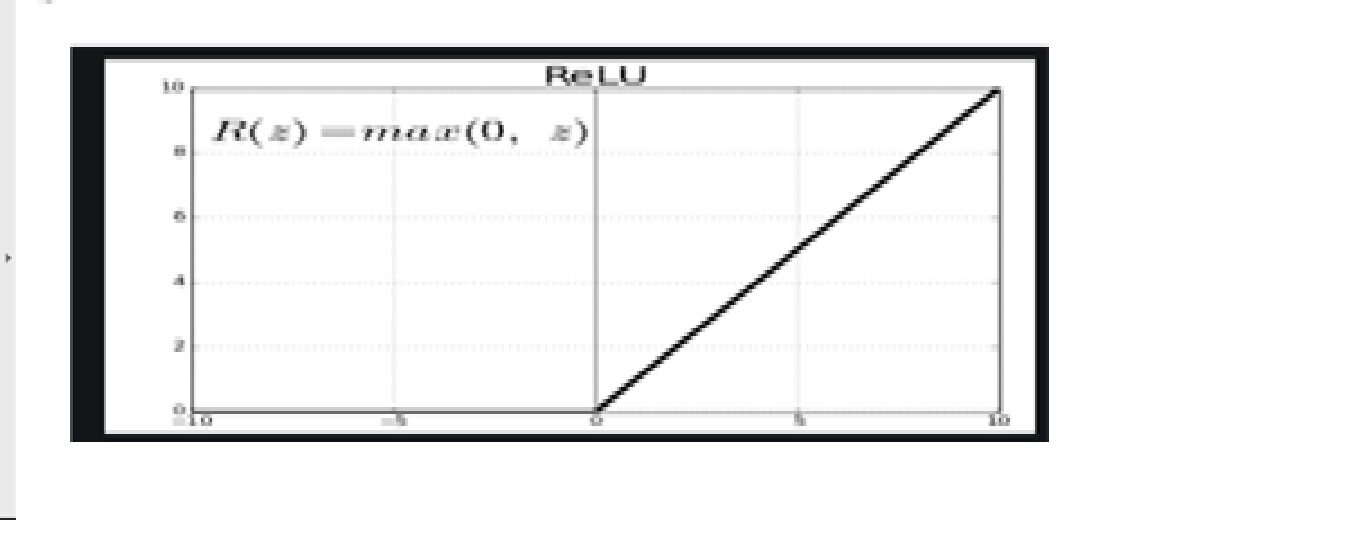
Poiché le immagini non sono lineari, fornire non linearità, il función de activación reluLa funzione di attivazione ReLU (Unità lineare rettificata) È ampiamente utilizzato nelle reti neurali grazie alla sua semplicità ed efficacia. è definito come ( F(X) = massimo(0, X) ), il che significa che produce un output pari a zero per i valori negativi e un incremento lineare per i valori positivi. La sua capacità di mitigare il problema dello sbiadimento del gradiente lo rende una scelta preferita nelle architetture profonde.... se aplica después de la operación convolucional.
Relu significa funzione di attivazione lineare rettificata. La funzione Relu genererà l'input direttamente se è positivo; altrimenti, genererà zero.
· Modulo di input
Questo argomento mostra la dimensione dell'immagine: 224 * 224 * 3. Visto che le immagini in formato RGB sono così, la tercera dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e... de la imagen es 3.
3. Funzionamento della piscina
Codice Python:
modello.aggiungi(MaxPooling2D(pool_size=2))
Dobbiamo applicare l'operazione di raggruppamento dopo aver inizializzato la CNN. Il clustering è un'operazione di downsampling dell'immagine. Il livello di raggruppamento viene utilizzato per ridurre le dimensioni delle mappe di caratteristiche. Perciò, la capa Pooling reduce la cantidad de parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... a aprender y reduce el cálculo en la red neuronal.
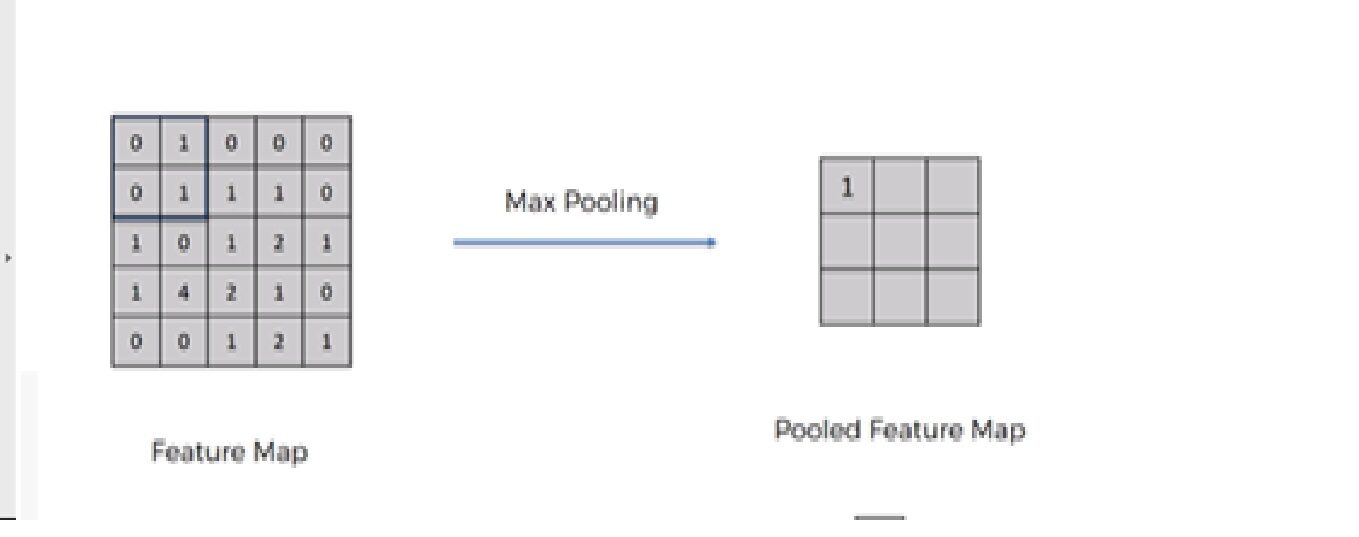
Le operazioni future vengono eseguite su entità di riepilogo create dal livello di raggruppamento. invece di feature localizzate con precisione generate dal livello di convoluzione. Questo porta al modello più robusto a variazioni nell'orientamento della caratteristica nell'immagine..
Ci sono principalmente 3 tipi raggruppamento: –
1. Raggruppamento massimo
2. Raggruppamento medio
3. Raggruppamento globale
4. Aggiungi due livelli convolutivi
Per aggiungere altri due livelli convolutivi, dobbiamo ripetere i passaggi 2 e 3 con una leggera modifica nel numero di filtri.
Codice Python:
modello.aggiungi(Conv2D(filtri=32,kernel_size=2,padding="stesso",attivazione ="riprendere")) modello.aggiungi(MaxPooling2D(pool_size=2)) modello.aggiungi(Conv2D(filtri=64,kernel_size=2,padding="stesso",attivazione="riprendere")) modello.aggiungi(MaxPooling2D(pool_size=2))
Modifichiamo il 2Nord Dakota e 3rd strati convoluzionali con numero di filtro 32 e 64 rispettivamente.
5. Operazione di spianatura
Codice Python:
modello.aggiungi(Appiattire())
L'operazione di appiattimento consiste nel convertire il set di dati in una matrice 1-D per entrare nel livello successivo, che è lo strato completamente connesso.
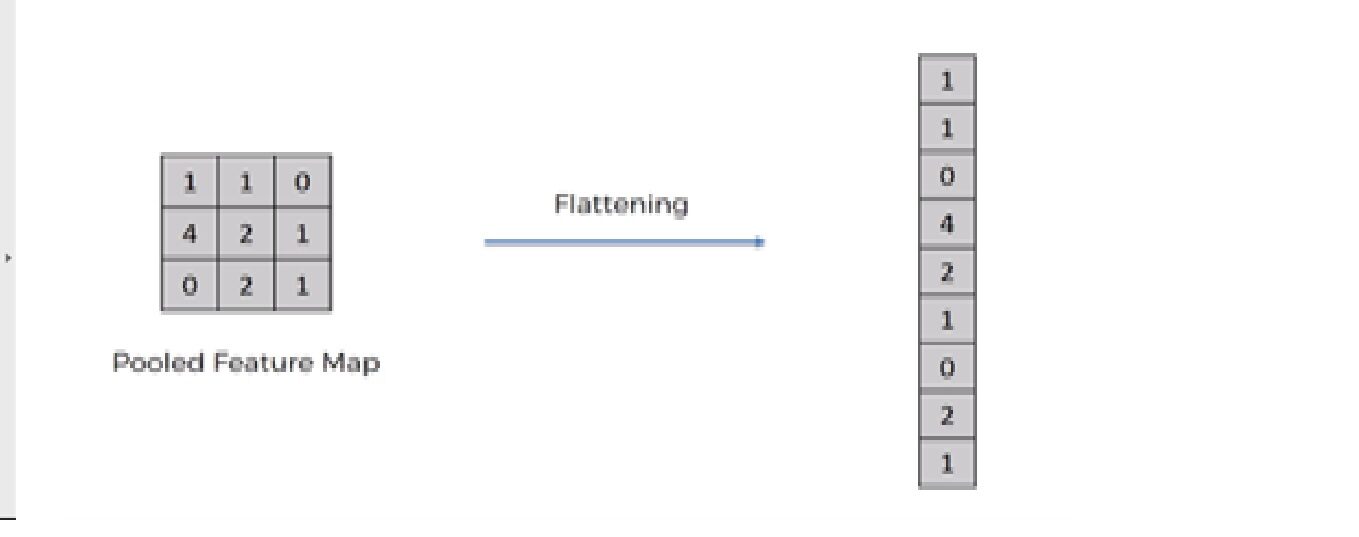
Dopo aver terminato il 3 Passi, ora abbiamo raggruppato la mappa delle caratteristiche. Ora stiamo appiattendo la nostra uscita dopo due passaggi in colonna. Perché abbiamo bisogno di inserire questi dati 1-D in un livello di rete neurale artificiale.
6. Livello completamente connesso e livello di output
L'output dell'operazione di appiattimento funziona come input per la rete neurale. L'obiettivo della rete neurale artificiale rende la rete neurale convoluzionale più avanzata e abbastanza in grado di classificare le immagini.
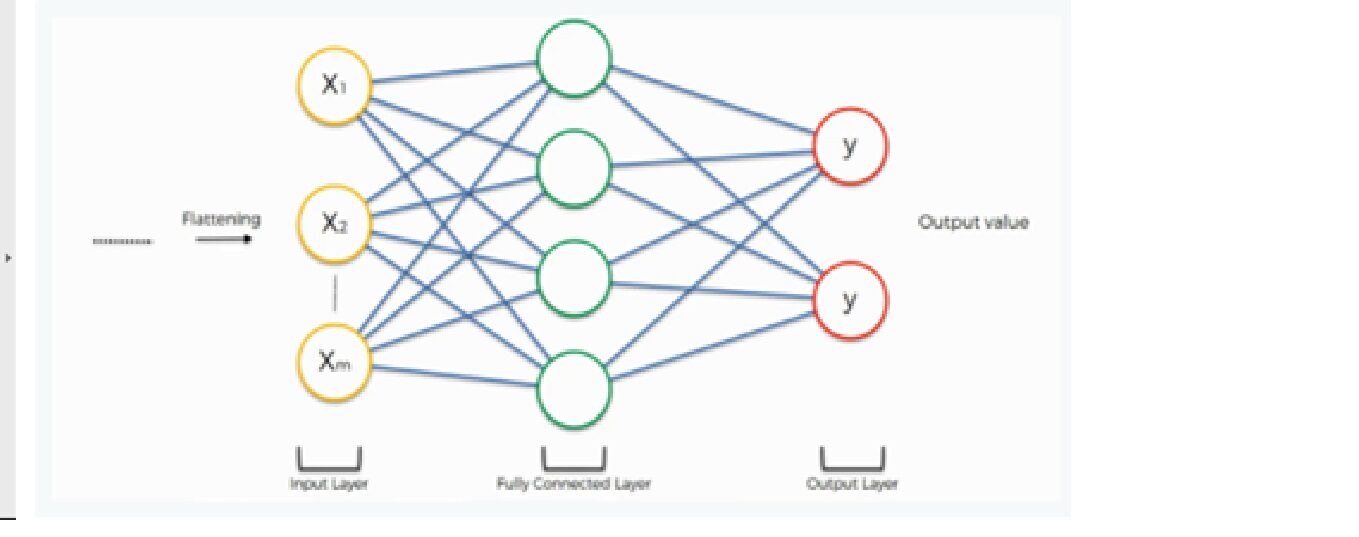
Qui stiamo usando una classe densa dalla libreria Keras per creare un livello completamente connesso e un livello di output.
Codice Python:
modello.aggiungi(Denso(500,attivazione="riprendere")) modello.aggiungi(Denso(2,attivazione="softmax"))
La funzione di abilitazione di softMax viene utilizzata per creare il livello di output. Analizziamo la funzione di attivazione di softmax.
Funzione di attivazione Softmax
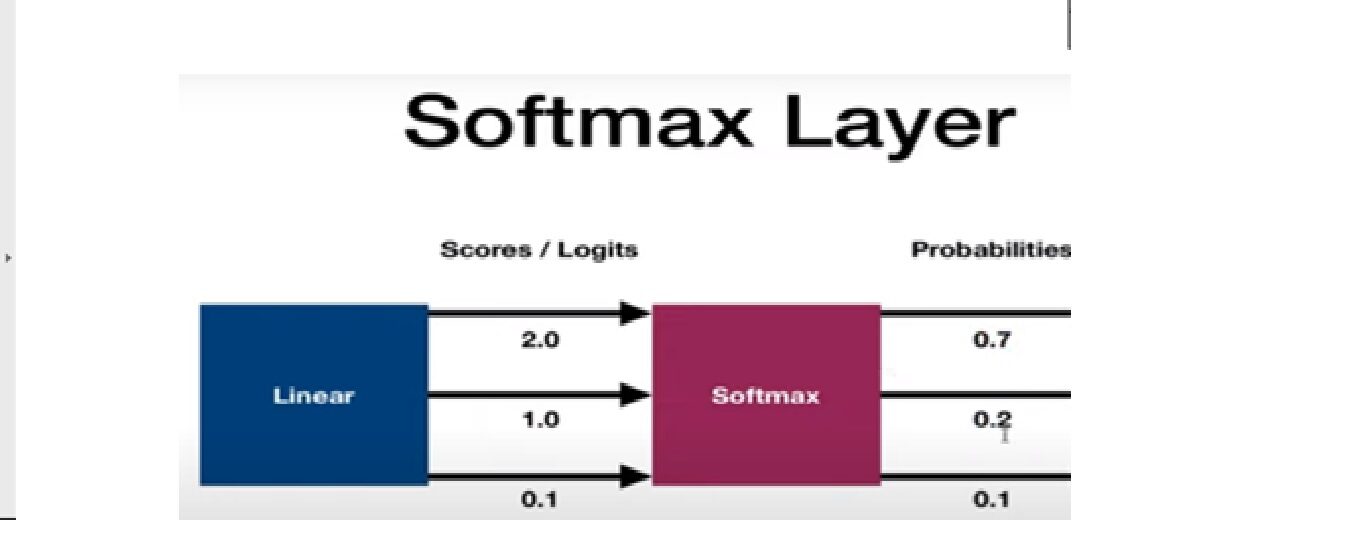
Viene utilizzato come ultima funzione di attivazione di una rete neurale per portare l'output della rete neurale a una distribuzione di probabilità sulle classi di previsione. L'output di Softmax è nelle probabilità di ogni possibile risultato per prevedere la classe. La somma delle probabilità deve essere una per tutte le possibili classi di previsione.
Ora, analicemos el addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... y la evaluación de la red neuronal convolucional. Discuteremo questa sezione in 3 Passi; –
passo 1: compilare il modello CNN
passo 2: adattare il modello al training set
passo 3: valutare il risultato
passo 1: compilare il modello CNN
Riga di codice
modello.compila (perdita = 'categorical_crossentropy', ottimizzatore = 'adam', metriche =['precisione'])
Qui stiamo usando 3 argomenti: –
· Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e...
Stiamo usando il categorical_crossentropy funzione di perdita utilizzata nel compito di classificazione. Questa perdita è un'ottima misura di quanto siano distinguibili due distribuzioni di probabilità discrete l'una dall'altra..
Per favore, Fare riferimento al collegamento sottostante per una descrizione dettagliata dei diversi tipi di funzione di perdita:
· Ottimizzatore
stiamo usando Adam Optimizer utilizzato per aggiornare i pesi della rete neurale e il tasso di apprendimento. Gli ottimizzatori vengono utilizzati per risolvere i problemi di ottimizzazione riducendo al minimo la funzione.
Per favore, vedere il collegamento sottostante per una spiegazione dettagliata dei diversi tipi di ottimizzatore:
· Argomenti metrici
Qui, stiamo usando la precisione come metrica per valutare le prestazioni dell'algoritmo della rete neurale convoluzionale.
passo 2: adattare il modello al training set
Riga di codice:
model.fit_generator(training_set,validation_data=test_set,epoche=50, steps_per_epoch = len(training_set), validation_steps=len(test_set) )
Stiamo adattando il modello CNN al set di dati di allenamento con 50 iterazioni e ogni iterazione ha diversi passaggi per addestrare e valutare i passaggi in base alla durata del test e al set di addestramento.
passo 3: – Valuta il risultato
Confrontiamo la precisione e la funzione di perdita per il set di dati di addestramento e test.
Codice: Grafico delle perdite
plt.trama(r.storia['perdita'], etichetta="perdita del treno")
plt.trama(r.storia['val_loss'], etichetta="perdita di valore")
plt.legend()
plt.mostra()
plt.savefig('LossVal_loss')
Produzione
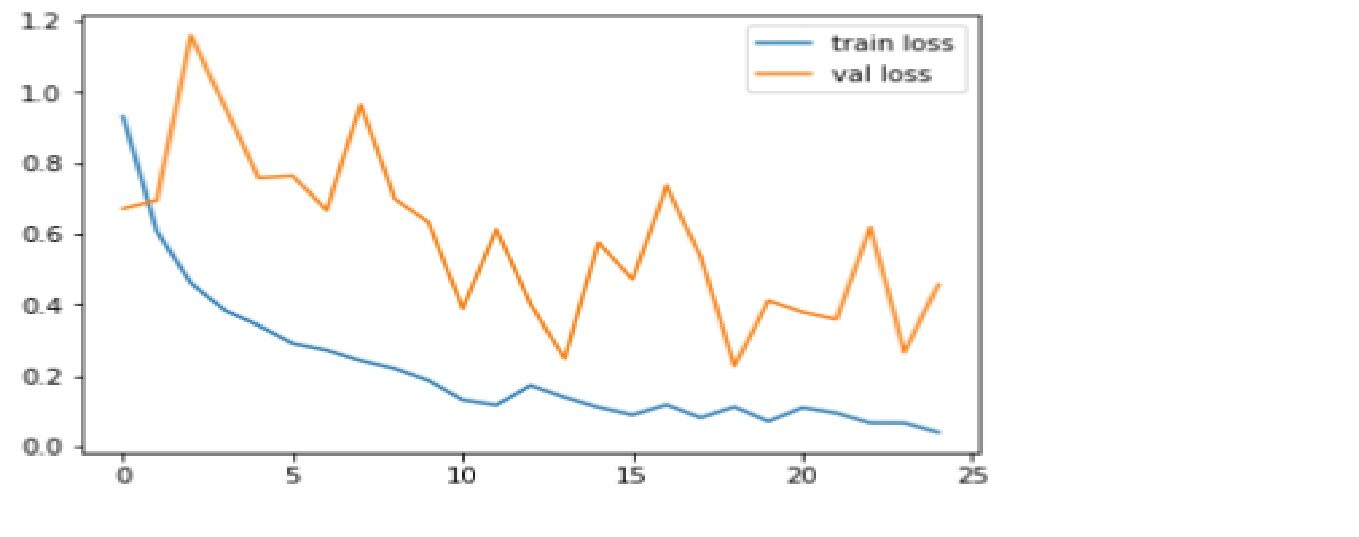
La perdita è la punizione per una cattiva previsione. L'obiettivo è ridurre al minimo la perdita di convalida. Un po' di overfitting è quasi sempre una buona cosa. Tutto ciò che conta, alla fine, è: è la perdita di convalida più bassa possibile.
Codice: Grafico di precisione del grafico
plt.trama(r.storia['precisione'], etichetta="treno acc")
plt.trama(r.storia['val_accuratezza'], etichetta="val acc")
plt.legend()
plt.mostra()
plt.savefig('AccVal_acc')
Produzione
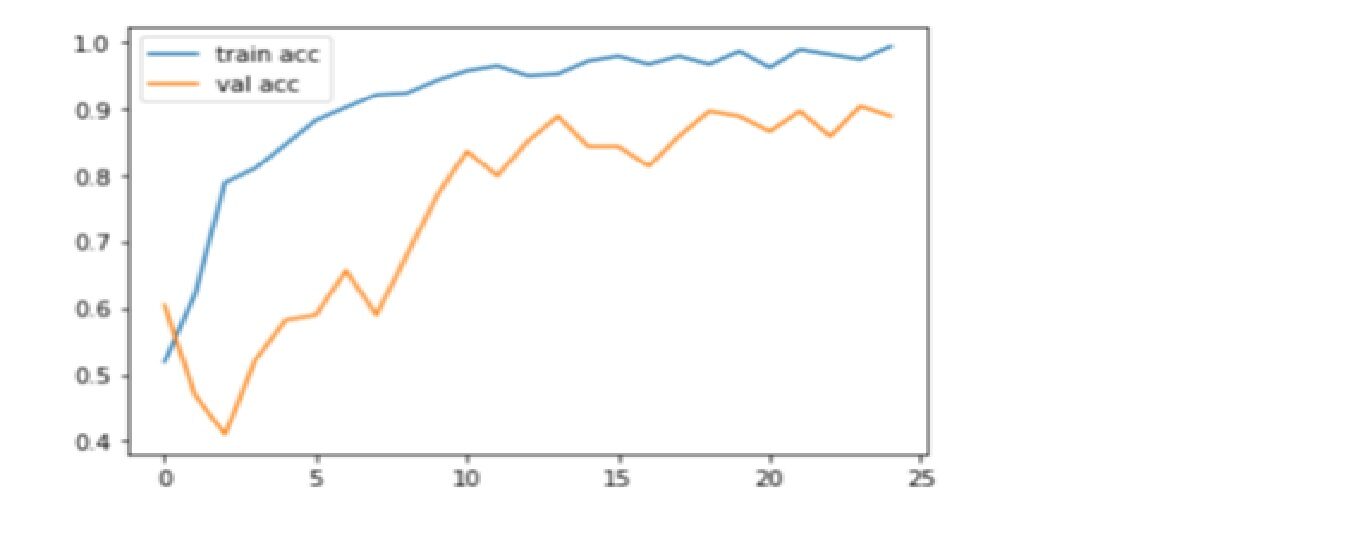
L'accuratezza è una metrica per valutare i modelli di classificazione. Informalmente, la precisione è la frazione di previsioni che il nostro modello ha ottenuto correttamente. Qui, possiamo vedere che la precisione è vicina a 90% nel test di convalida che mostra che un modello CNN sta funzionando bene su metriche di precisione.
Grazie per aver letto! Buon apprendimento profondo!
Riferimenti:
1. https://www.superdatascience.com/
2. https://www.youtube.com/watch?v=H-bcnHE6Mes
A proposito di me :
Soy Jitendra Sharma, stagista in data science presso Nabler, y me dedico a PGDM-Big Data Analytics del Goa Institute of Management. Puoi contattarmi tramite LinkedIn e Github.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





