introduzione
Molto spesso, usiamo la verifica dei dati e la convalida dei dati in modo intercambiabile quando si tratta di qualità dei dati. tuttavia, questi due termini sono diversi. In questo articolo, capiremo la differenza in 4 contesti diversi:
- Verifica e convalida Significato Dizionario
- Differenza tra la verifica dei dati e la convalida dei dati in generale
- Differenza tra verifica e convalida dal punto di vista dello sviluppo software
- Differenza tra la verifica dei dati e la convalida dei dati da una prospettiva di apprendimento automatico
1) Verifica e convalida Significato Dizionario
A bordo 1 spiega il significato del dizionario delle parole verifica e convalida con alcuni esempi.
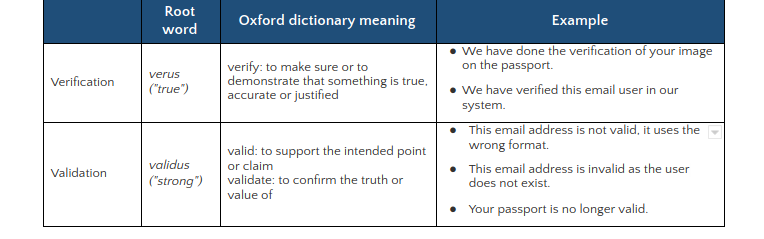
In sintesi, la verifica riguarda la veridicità e la precisione, considerando che la convalida consiste nel supportare la solidità di un punto di vista o l'accuratezza di un'affermazione. La convalida verifica l'accuratezza di una metodologia, mentre la verifica verifica l'esattezza dei risultati.
2) Differenza tra la verifica dei dati e la convalida dei dati in generale
Ora che abbiamo capito il significato letterale delle due parole, esploriamo la differenza tra “verifica dei dati” e “convalida dei dati”.
Verifica dei dati: per assicurarsi che i dati siano accurati.
Convalida dei dati: per assicurarti che i dati siano corretti.
Sviluppiamo con esempi nella Tabella 2.

Tavolo 2: “Verifica dei dati” e “convalida dei dati” esempi
3) Differenza tra verifica e convalida dal punto di vista dello sviluppo software
Dal punto di vista dello sviluppo software,
- La verifica viene eseguita per garantire che il software sia di alta qualità, ben progettato, robusto e senza errori senza entrare nella sua usabilità.
- La convalida viene eseguita per garantire l'usabilità e la capacità del software di soddisfare le esigenze del cliente.
Como se muestra en la Figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... 1, prova di correzione, analisi di robustezza, test unitari, test di integrazione e altri sono tutti dai un'occhiata Passaggi in cui le attività sono orientate alla verifica dei dettagli. L'output del software viene verificato con l'output desiderato. In secondo luogo, ispezione del modello, i test della scatola nera e i test di usabilità sono tutto convalida Passi in cui le attività sono orientate per capire se il software soddisfa i requisiti e le aspettative.
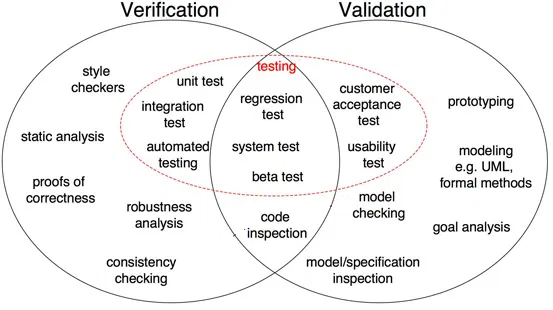
Fig 1: Differenze tra verifica e convalida nello sviluppo del software
4) Differenza tra la verifica dei dati e la convalida dei dati da una prospettiva di apprendimento automatico
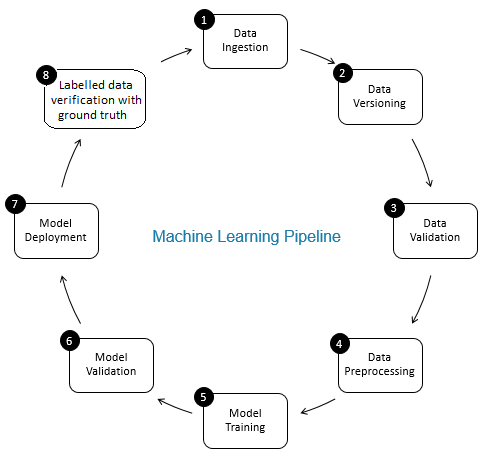
La carta di verifica dei dati nel processo di machine learning è quello di un gatekeeper. Quella garantisce dati accurati e aggiornati col tempo. La verifica dei dati viene eseguita principalmente nella nuova fase di acquisizione dei dati, vale a dire, al passo 8 della pipeline ML, come mostrato in Fig. 2. Esempi di questo passaggio sono l'identificazione di record duplicati e l'esecuzione della deduplicazione, e ripulire la discrepanza nelle informazioni sui clienti in campi come indirizzo o numero di telefono.
D'altra parte, convalida dei dati (al passo 3 della pipeline ML) assicura che i dati incrementali del passo 8 aggiunti ai dati di apprendimento sono di buona qualità e simili (dal punto di vista delle proprietà statistiche) a los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... Esistente. Ad esempio, ciò comprende trova anomalie nei dati rilevandoti differenze tra i dati di allenamento esistenti e i nuovi dati da aggiungere ai dati di allenamento. Altrimenti, eventuali problemi di qualità dei dati / le differenze statistiche nei dati incrementali possono andare perse e l'addestramento gli errori possono accumularsi nel tempo e deteriorare la precisione del modello. Perciò, la convalida dei dati rileva cambiamenti significativi (si ci sono) nei dati di allenamento incrementali in una fase iniziale che aiuta con l'analisi della causa principale.
Autori:
1. Aditya Agarwal: Aditya Aggarwal è Data Science – Responsabile della pratica presso Abzooba Inc. Più di 12 anni di esperienza nella guida degli obiettivi aziendali attraverso soluzioni basate sui dati, Aditya è specializzata in analisi predittiva, apprendimento automatico, business intelligence e strategia aziendale. in una varietà di settori. In qualità di leader della pratica di analisi avanzata presso Abzooba, Aditya guida un team di oltre 50 Professionisti energici della scienza dei dati presso Abzooba che risolvono problemi aziendali interessanti utilizzando l'apprendimento automatico, il apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute..., elaborazione del linguaggio naturale e visione artificiale. Fornisce una leadership di pensiero AI ai clienti per tradurre i loro obiettivi di business in problemi analitici e soluzioni basate sui dati. Sotto la sua guida, varie organizzazioni hanno attività di routine automatizzate, hanno costi operativi ridotti, aumento della produttività del team e miglioramento delle entrate principali e inferiori. Hai creato soluzioni come il motore della maternità surrogata, il motore di raccomandazione dei prezzi, manutenzione predittiva dei sensori IoT e altro. Aditya ha un Bachelor of Technology e un Bachelor of Business Administration presso l'Indian Institute of Technology (IO ESSO), Delhi.
2. Dr. Coniglio Bose: Il dottore. Arnab Bose è Direttore Scientifico di Abzooba, una società di analisi dei dati, e professore a contratto presso l'Università di Chicago, dove insegna machine learning e analisi predittiva, operazioni di apprendimento automatico, análisis de series de tiempo y Forecasting y Health Analytics en el programa de Maestría en Ciencias en AnalisiL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche..... È un veterano del settore dell'analisi predittiva di 20 anni di divertimento nell'utilizzo di dati strutturati e non strutturati per prevedere e influenzare i risultati comportamentali nel settore sanitario, Al dettaglio, finanza e trasporti. Le sue attuali aree di interesse includono la stratificazione del rischio per la salute e la gestione delle malattie croniche mediante l'apprendimento automatico., e la distribuzione in produzione e il monitoraggio dei modelli di apprendimento automatico. Arnab ha pubblicato capitoli di libri e articoli referenziati in numerosi convegni e riviste dell'Istituto degli Ingegneri Elettrici ed Elettronici (IEEE). Ha ricevuto la Best Presentation all'American Control Conference e ha tenuto conferenze sull'analisi dei dati presso università e aziende negli Stati Uniti.. UU., Australia e India. Arnab ha un master e un dottorato. lauree in ingegneria elettrica presso la University of Southern California, e un B.Tech. in ingegneria elettrica presso l'Indian Institute of Technology di Kharagpur, India.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





