Panoramica
- La guida passo passo per lo sviluppo deve acquisire le competenze per diventare un data scientist
- Funzionalità come MOOC, Canali YouTube, pagine del blog, siti web della comunità di data science per apprendere varie abilità
- Siti web di comunità di data science come Kaggle, Dati guidati, Analytics Vidhya per un'esperienza pratica con set di dati e
altre utili tecniche di apprendimento automatico
Cos'è la scienza dei dati??
La scienza dei dati riguarda “Utilizzando varie tecniche, algoritmi per l'analisi di grandi quantità di set di dati (sia strutturato che non strutturato), per estrarre informazioni utili sui dati, applicandoli in questo modo in diversi domini commerciali”.
Perché c'è una richiesta di data scientist??
Dati viene generato giorno dopo giorno a un ritmo enorme e per elaborare set di dati così massicci, le grandi aziende sono alla ricerca di validi data scientist per estrarre informazioni preziose da questi set di dati e utilizzarle per varie strategie, modelli e piani di business.
Sommario
- Impara Python
- Impara le statistiche
- Raccolta dati
- Pulizia dei dati
- Conoscenza dell'EDA (analisi esplorativa dei dati)
- Aprendizaje automático y apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute...
- Maggiori informazioni sull'implementazione del modello ML
- Test del mondo reale
- Esplorazione e pratica di set di dati in Kaggle, Analisi Vidhya
- Curiosità analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche....
- Competenze non tecniche

1. Impara Python
Il primo e principale passo verso la scienza dei dati dovrebbe essere un linguaggio di programmazione (vale a dire, Pitone). Python è il linguaggio di programmazione più comune, utilizzato dalla maggior parte dei data scientist, per la sua semplicità, versatilità ed essere pre-equipaggiato con potenti librerie (come NumPy, SciPy e Panda) utile nell'analisi dei dati e in altri aspetti nelle scienze dei dati. Python è un linguaggio open source e supporta varie librerie.
Risorsa:
MOOC: Corso Udacity Python, Coursera Corso Python
Canale Youtube: krish naik, Nozioni di base sul codice
Blog: Analisi Vidhya, Pepite di KD
2. Impara le statistiche

e La scienza dei dati è un linguaggio, allora la statistica è fondamentalmente grammatica. La statistica è fondamentalmente il metodo di analisi e interpretazione di grandi insiemi di dati. Quando si tratta di analisi dei dati e raccolta di informazioni, le statistiche sono notevoli come l'aria per noi. Le statistiche ci aiutano a capire i dettagli nascosti di grandi insiemi di dati
Risorsa:
MOOC: Corso di statistica Coursera
Canale Youtube: krish naik, Nozioni di base sul codice
Blog: Analisi Vidhya, Pepite di KD
3. Raccolta dati
Questo è uno dei passaggi chiave e importanti nel campo della scienza dei dati.. Questa abilità implica la conoscenza di vari strumenti per importare dati da entrambi i sistemi locali., come file CSV, ed estrarre i dati dai siti web, usando bella libreria python di zuppa. La demolizione può anche essere basata su API. La raccolta dei dati può essere gestita con la conoscenza del Query Language o delle pipeline ETL in Python
Risorsa:
MOOC: Raccolta di dati Coursera con Python
4. Pulizia dei dati
Questo è il passaggio in cui trascorri la maggior parte del tuo tempo come data scientist. La pulizia dei dati riguarda il recupero dei dati, adatto per lavoro e analisi, rimuovendo i valori indesiderati, valori mancanti, valori categorici, valori anomali e record inviati in modo errato, dalla forma grezza dei dati.. La pulizia dei dati è molto importante poiché i dati del mondo reale sono disordinati per natura e per raggiungere questo obiettivo con l'aiuto di varie librerie Python (Panda e NumPy) è davvero importante per un aspirante scienziato dei dati.
Risorsa:
Blog: Blog sulla pulizia dei dati Python

5. Conoscenza dell'EDA (analisi esplorativa dei dati)
EDA (analisi esplorativa dei dati) è l'aspetto più importante nel vasto campo della scienza dei dati. Include l'analisi di vari dati, variabili, vari modelli di dati, tendenze ed estrarne informazioni utili con l'ausilio di vari metodi grafici e statistici. L'EDA identifica diversi modelli che l'algoritmo di apprendimento automatico potrebbe non identificare. Include tutta la gestione, analisi e visualizzazione dei dati.
Risorsa:
Comunità di scienza dei dati: Kaggle, Vidhya Analytics
Blog: EDA nel set di dati dell'iride
Canale Youtube: Video EDA in krish naik, Nozioni di base sul codice
MOOC: Corso Coursera su EDA, statistiche, probabilità
6. Apprendimento automatico e deep learning
L'apprendimento automatico è l'abilità primaria richiesta per essere un data scientist. L'apprendimento automatico viene utilizzato per costruire vari modelli predittivi, modelli di classificazione, eccetera., e grandi aziende, Le compagnie, usalo per ottimizzare la loro pianificazione in base alle previsioni. Ad esempio, previsione del prezzo dell'auto
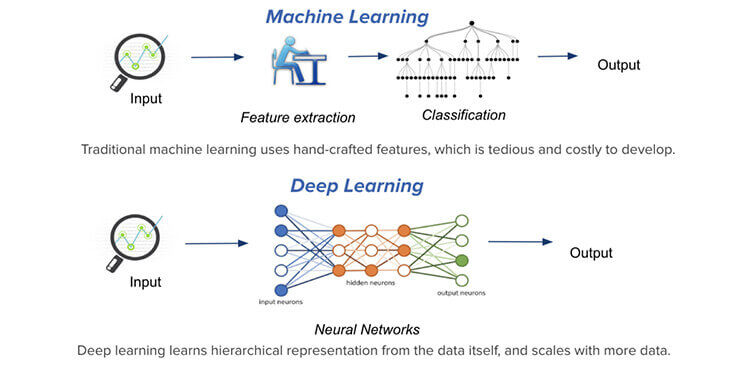
Apprendimento profondo, In secondo luogo, è una versione avanzata di Machine Learning che implementa l'uso della rete neurale, un framework che combina vari algoritmi di apprendimento automatico per risolvere vari compiti, per addestrare i dati. Varias redes neuronales son una ricorrente neuronale rossoReti neurali ricorrenti (RNN) sono un tipo di architettura di rete neurale progettata per elaborare flussi di dati. A differenza delle reti neurali tradizionali, Le RNN utilizzano connessioni interne che consentono di ricordare le informazioni delle voci precedenti. Questo li rende particolarmente utili in attività come l'elaborazione del linguaggio naturale, Traduzione automatica e analisi di serie storiche, dove il contesto e la sequenza sono centrali per il... (RNN) o una convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. (CNN), eccetera.
Ad esempio: riconoscimento facciale
Si intende:
Comunità di scienza dei dati: Kaggle, Vidhya Analytics
Blog: Analisi Vidhya, Pepite di KD
Canale Youtube: video in krish naik, Nozioni di base sul codice
MOOC: Curso de Coursera Machine Learning, Corso di specializzazione in Deep Learning
7. Scopri come implementare il modello ML
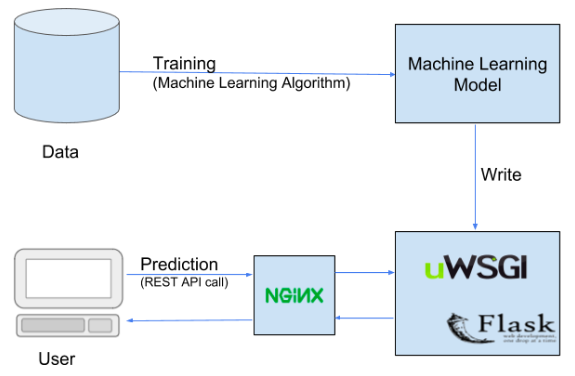
La distribuzione è fondamentalmente il processo di messa a disposizione del modello di machine learning per l'uso da parte degli utenti finali.. Ciò si ottiene integrando il modello con vari ambienti di produzione esistenti., implementando così l'uso pratico del modello ML per varie soluzioni aziendali.
Ci sono molti servizi per implementare il tuo modello ML come Flask, Pythonovunque, MLOps, Microsoft Azure, Google Cloud, Heroku, eccetera.
Si intende:
Canale Youtube: Video di implementazione AA su krish naik, Nozioni di base sul codice
Blog: Analisi Vidhya, Pepite di KD
8. Test del mondo reale
Il test e la convalida del modello di apprendimento automatico dovrebbero essere eseguiti dopo l'implementazione per verificarne l'efficacia e l'accuratezza. Il test è un passo importante nella scienza dei dati per tenere sotto controllo l'efficienza e l'efficacia del modello ML.
Esistono diversi tipi di test come A / B, Test AAB, eccetera.
9. Esplorazione e pratica di set di dati in Kaggle, Analisi Vidhya

Le più grandi comunità di data science al mondo come Kaggle, Analytics Vidhya è molto utile per entrare in contatto con vari set di dati e, così, può essere utilizzato per praticare varie tecniche di analisi dei dati, algoritmi di apprendimento automatico. Anche i concorsi organizzati in queste comunità sono utili per migliorare le competenze di data science., aiutandoci a raggiungere il nostro obiettivo di diventare esperti di data science più velocemente..
10. Curiosità analitica
Il campo della scienza dei dati è un campo che si sta evolvendo a un ritmo più veloce., così, richiede una curiosità innata per esplorare di più sul campo, aggiornando e imparando regolarmente varie abilità e tecniche.
Questa è l'abilità principale che ci aiuterà sempre a mantenere, aggiornare nuove competenze e concetti, impedendoci così di rimanere indietro rispetto a diversi progressi tecnologici nella scienza dei dati.
11. Competenze non tecniche
Non tecnico include il lavoro di squadra, capacità di comunicazione, Gestione dei compiti, comprensione degli affari, eccetera
Lavoro di squadra svolge un ruolo importante nel fornire il risultato alle aziende, aziende in cui operiamo come data scientist.
Abilità comunicative permetterci di esprimere le nostre idee tecniche, concetti a vari funzionari / autorità non tecniche dello Studio.
Compito Gestione comporta una corretta pianificazione e gestione per la consegna della soluzione.
Comprensione / senso degli affari o la comprensione del settore in cui stiamo lavorando è molto importante per varie analisi e soluzioni efficaci per i problemi in quei settori.





